莫凡Python学习笔记——PyTorch动态神经网络(四)
内容原文:https://morvanzhou.github.io/tutorials/machine-learning/torch/
1、优化器Optimizer 加速神经网络训练
最基础的optimizer是 Stochastic Gradient Descent(SGD),假如红色方块是我们要训练的data,如果用普通的训练方法,就需要重复不断的把整套数据放入神经网络NN训练,这样消耗的计算资源会很大。
但是如果我们将数据大块分成一个个小块,分批放入网络中进行训练,这样虽然不能完整的反应全部数据的情况,但是却大大加快了训练速度,而且其实不会丢失太多准确率,这就是SGD了。

其实PyTorch中有好几个优化器,其实其中SGD算是最训练最慢的,接下来来看下其他几个优化器。

(1)Momentum
大多优化器其实都是在神经网络更新参数的时候动了手脚,从而使得训练速度加快的。Momentum就是这样。
传统参数W的更新是:加上负的学习率*校正值
W += -Learning rate * dx 这样的训练会比较曲折,就好像一个喝醉酒的人摇摇晃晃的回家。
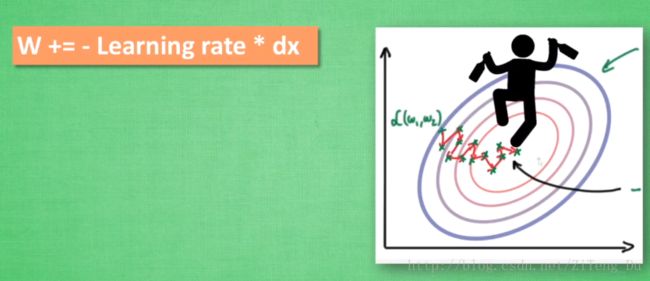
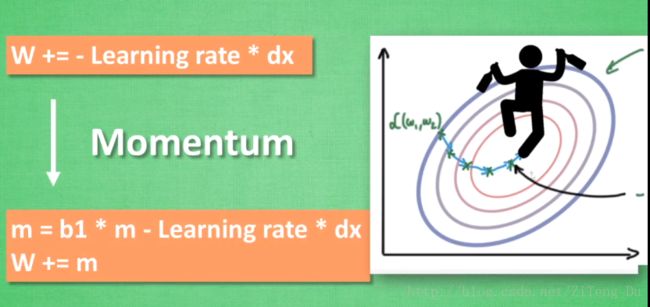
假如我们将这个人放在一个下坡路上,一旦他下一点坡,他就会不自觉的向下坡的方向走,这样他就一直下坡而不会摇晃走弯路了(惯性原则)。这个就是Momentum,它的数学形式是:
m = b1*m -Learning rate * dx
W += m
(2)AdaGrad
这个方法是在学习效率上动手脚,使得每一个参数的更新都会有属于自己独特的学习效率,它的作用和monentum类似。但是他不是让在在下坡路上走,而是给他换一双不好的鞋子,每步路走起来都脚疼,最终强迫他一直直着走(对错误方向的阻力)
他的数学形式见下图

(3)RMSProp
这个方法是Momentum和AdaGrad的结合,即让醉汉走在下坡路上,又给他穿一双不好的鞋子,也就是惯性原则+对错误方向的阻力

但是RMSProp并不是完整的两个融合,少了红线圈住的部分,那么在Adam方法中会进行完整的融合。
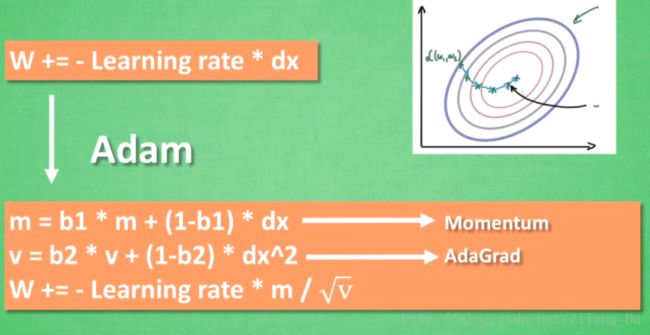
(4)Adam
Adam是对Momentum和AdaGard的完整融合,计算m 时有 momentum 下坡的属性, 计算 v 时有 adagrad 阻力的属性, 然后再更新参数时 把 m 和 V 都考虑进去. 实验证明, 大多数时候, 使用 adam 都能又快又好的达到目标, 迅速收敛. 所以说, 在加速神经网络训练的时候, 一个下坡, 一双破鞋子, 功不可没.
2、下面从代码的角度来看下以上四种的效果:
import torch
from torch.autograd import Variable
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
#hyper parameters
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
#data
x = torch.unsqueeze(torch.linspace(-1,1,1000),dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
#default network
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(1,20)
self.predict = torch.nn.Linear(20,1)
def forward(self,x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
#different nets
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD,net_Momentum,net_RMSprop,net_Adam]
#different oprimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha = 0.9)
opt_Adam =torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[],[],[],[]]
#training ...
for epoch in range(EPOCH):
print(epoch)
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data[0]) # loss recoder
# draw pictrue
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()

可以看出,其中SGD其实是最慢且效果最差的一个了,还是Adam的效果又快又好。
可以注意到,其实,每个优化器都有自己的特有的一些参数,所以我们可以通过设置油优化器的参数来尝试效果的变化,从而选出自己想要的效果。