论文阅读笔记:Tensorflow1.6.0+Keras 2.1.5+Python3.5+Yolov3训练自己的数据集!
| Tensorflow1.6.0+Keras 2.1.5+Python3.5+Yolov3训练自己的数据集! |
文章目录
- 前期准备
- 一. Yolov3简要介绍
- 1.1. Yolov3网络结构图
- 1.2. 9种尺度的先验框
- 1.3. 对象分类softmax改成logistic
- 1.4. 边框预测
- 1.5. 损失函数
- 1.6. 利用官网权重进行检测
- 二. 制作VOC2007格式数据集
- 2.1. 数据集标注
- 2.2. 修改参数文件yolov3.cfg
- 2.3. 修改model_data下的文件
- 三. 模型训练train.py
- 3.1. 代码解读train.py
- 3.2. 补充:冻结网络层
- 3.3. 补充:目标检测之IoU计算方法
- 3.4. 补充:冻结网络层
- 3.5. 补充:1x1卷积操作与全连接
- 四. 对图片进行检测
- 4.1. 修改yolo.py代码
- 4.2. 代码执行过程+结果
- 五. 重要代码注释model.py
- 六. Keras中自定义损失函数的方法
- 6.1. 例子1:自定义loss
- 6.2. 例子2:自定义loss
- 参考文章
前期准备
- 主要参考github代码 :https://github.com/qqwweee/keras-yolo3
- 主要参考CSDN文章1:https://blog.csdn.net/Patrick_Lxc/article/details/80615433
- 主要参考CSDN文章2:使用VOC数据集训练自己的YOLOv3模型(Keras/TensorFlow)
- 主要参考简书中文章3:关于Yolov3的一些细节
- 主要参考简书中文章4:Yolov3 深入理解
- 主要参考简书中文章5:Yolov1深入理解
- 主要参考简书中文章6:YOLOv2 / YOLO9000 深入理解
- 主要参考文章3(赞赞!):keras-Yolov3 源码调试
- 重点内容: 介绍如何制作数据集、修改代码、不加载预权重(可以选择) 从头跑自己的训练数据
- 程序运行环境:
Python 3.5.2; Keras 2.1.5; tensorflow 1.6.0!
一. Yolov3简要介绍
1.1. Yolov3网络结构图
- YOLOV3 Homepage
- Yolov3网络结构图参考作者 yolo系列之yolo v3【深度解析】,并且我再此基础了进行了一些细节性的补充,希望对您有用!
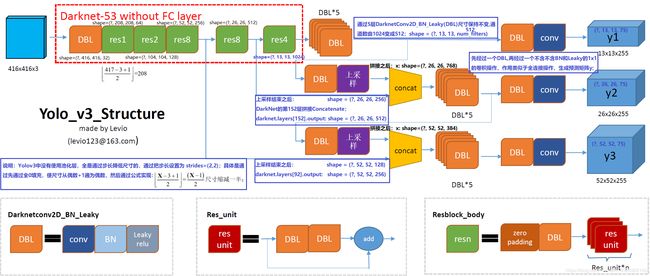
- Yolov3输出了3个不同尺度的feature map, 有什么作用!
- 低层的特征语义信息比较少,但是目标位置信息准确;高层的特征语义信息比较丰富,但是目标位置信息比较粗略。
- 这个借鉴了FPN(feature pyramid networks),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体。这样可以让网络同时学习到深层和浅层的特征,通过叠加浅层特征图相邻特征到不同通道(而非空间位置),类似于Resnet中的identity mapping。这个方法把 26 × 26 × 512 26×26×512 26×26×512 的特征图叠加成 13 × 13 × 2048 13×13×2048 13×13×2048 的特征图,与原生的深层特征图相连接,使模型有了细粒度特征,增加对小目标的识别能力。
- Yolov3采用(类似FPN)上采样(Upsample)和融合做法,融合了3个尺度( 13 × 13 、 26 × 26 和 52 × 52 13×13、26×26和52×52 13×13、26×26和52×52),在多个尺度的融合特征图上分别独立做检测,最终对于小目标的检测效果提升明显。(有些算法采用多尺度特征融合的方式,但是一般是采用融合后的单一特征图做预测,比如Yolov2,FPN不一样的地方在于其预测是在不同特征层进行的!)
- 假设以Pascal voc 为例:Yolov3设定的是每个网格单元预测 3 3 3 个box,所以每个box需要有 ( x , y , w , h , c o n f i d e n c e ) (x, y, w, h, confidence) (x,y,w,h,confidence) 五个基本参数,然后还要有20个类别的概率。所以 3 × ( 5 + 20 ) = 75 3×(5 + 20) = 75 3×(5+20)=75,这个 75 75 75 就是这么来的! (还记得yolo v1的输出张量吗? 7 × 7 × 30 7×7×30 7×7×30,其中 2 × 5 + 20 = 30 2×5+20 = 30 2×5+20=30 识别 20 20 20 类物体,而且每个cell只能预测 2 2 2 个box,和Yolov3比起来就像老人机和iphoneX一样)
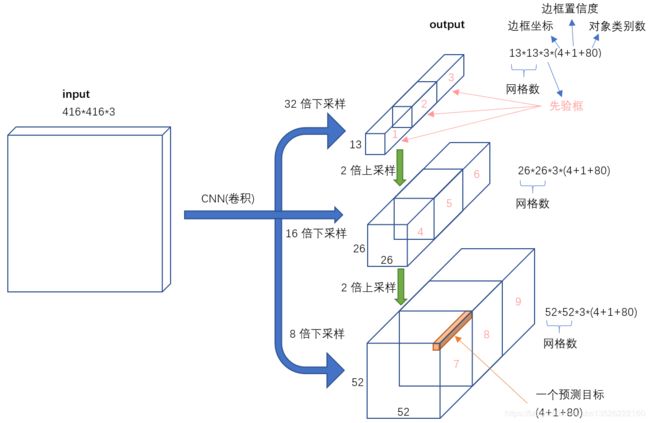
1.2. 9种尺度的先验框
- 随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。Yolov2已经开始采用K-means聚类得到先验框的尺寸,Yolov3延续了这种方法,为每种下采样尺度设定3种先验框,总共聚类出 9 9 9 种尺寸的先验框。在COCO数据集这 9 9 9 个先验框是: ( 10 × 13 ) , ( 16 × 30 ) , ( 33 × 23 ) , ( 30 × 61 ) , ( 62 × 45 ) , ( 59 × 119 ) , ( 116 × 90 ) , ( 156 × 198 ) , ( 373 × 326 ) (10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326) (10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。
- 分配上,在最小的 13 × 13 13×13 13×13 特征图上(有最大的感受野)应用较大的先验框 ( 116 × 90 ) , ( 156 × 198 ) , ( 373 × 326 ) (116×90),(156×198),(373×326) (116×90),(156×198),(373×326),适合检测较大的对象。中等的 26 × 26 26×26 26×26 特征图上(中等感受野)应用中等的先验框 ( 30 × 61 ) , ( 62 × 45 ) , ( 59 × 119 ) (30×61),(62×45),(59×119) (30×61),(62×45),(59×119),适合检测中等大小的对象。较大的 52 × 52 52×52 52×52 特征图上(较小的感受野)应用较小的先验框 ( 10 × 13 ) , ( 16 × 30 ) , ( 33 × 23 ) (10×13),(16×30),(33×23) (10×13),(16×30),(33×23),适合检测较小的对象。

- 具体介绍可以参考作者:YOLOv3 深入理解
1.3. 对象分类softmax改成logistic
- 预测对象类别时不使用softmax,改成使用logistic的输出进行预测。这样能够支持多标签对象(比如一个人有Woman 和 Person两个标签)。
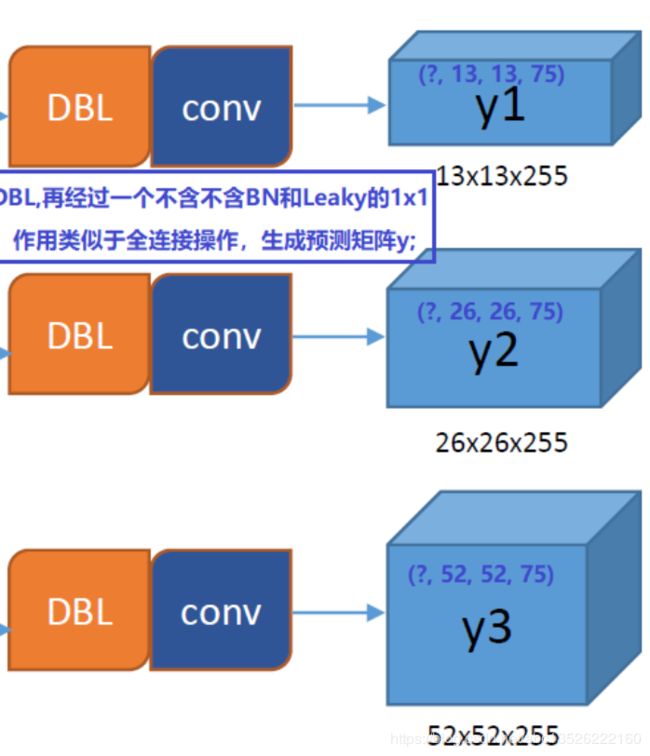
- 不考虑神经网络结构细节的话,总的来说,对于一个输入图像,Yolov3将其映射到 3 3 3 个尺度的输出张量,代表图像各个位置存在各种对象的概率。
- 我们看一下Yolov3共进行了多少个预测。对于一个 416 × 416 416×416 416×416 的输入图像,在每个尺度的特征图的每个网格设置 3 3 3 个先验框,总共有 13 × 13 × 3 + 26 × 26 × 3 + 52 × 52 × 3 = 10647 13×13×3 + 26×26×3 + 52×52×3 = 10647 13×13×3+26×26×3+52×52×3=10647 个预测。每一个预测是一个 ( 4 + 1 + 80 ) = 85 (4+1+80)=85 (4+1+80)=85 维向量,这个 85 85 85 维向量包含边框坐标( 4 4 4 个数值),边框置信度( 1 1 1 个数值),对象类别的概率(对于COCO数据集,有 80 80 80 种对象)。
- 对比一下,Yolov2采用 13 × 13 × 5 = 845 13×13×5 = 845 13×13×5=845 个预测,Yolov3的尝试预测边框数量增加了 10 10 10 多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。

- 图像参考: 如何在PyTorch中从零开始实现YOLO(v3)对象检测器
1.4. 边框预测
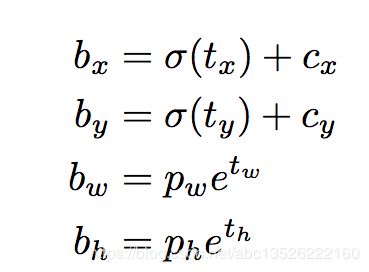
- 其中: b x , b y , b w , b h b_x, b_y, b_w, b_h bx,by,bw,bh 是我们预测的 x , y x,y x,y 中心坐标,宽度和高度; t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th 是网络输出的内容。 c x , c y c_x, c_y cx,cy 是网格的左上角坐标, p w p_w pw 和 p h p_h ph 是盒子的anchor box尺寸
1.5. 损失函数
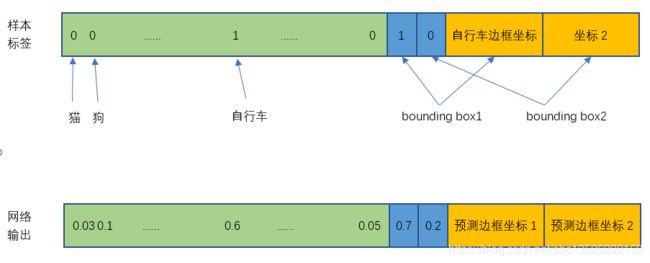
- 这里以Yolov1为例子:损失就是网络实际输出值与样本标签值之间的偏差。举个例子,比如下图中自行车的中心点位于4行3列网格中,所以输出tensor中4行3列位置的30维向量如下图所示。

- YOLO给出的损失函数如下
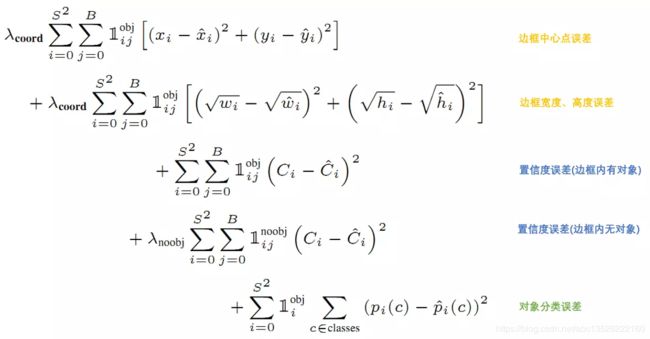
公式中
- a) 1 i o b j 1_i^{obj} 1iobj 意思是网格 i i i 中存在对象。
- b) 1 i j o b j 1_{ij}^{obj} 1ijobj 意思是网格 i i i 的第 j j j 个bounding box中存在对象。
- c) 1 i j n o o b j 1_{ij}^{noobj} 1ijnoobj 意思是网格 i i i 的第 j j j 个bounding box中不存在对象。
总的来说,就是用网络输出与样本标签的各项内容的误差平方和作为一个样本的整体误差。损失函数中的几个项是与输出的30维向量中的内容相对应的。
① 对象分类的误差: 公式第5行,注意 1 i o b j 1_i^{obj} 1iobj 意味着存在对象的网格才计入误差。
② bounding box的位置误差:
- a) 公式第 1 1 1 行和第 2 2 2 行。都带有 1 i j o b j 1_{ij}^{obj} 1ijobj 意味着只有"负责"(IOU比较大)预测的那个bounding box的数据才会计入误差。
- b) 第 2 2 2 行宽度和高度先取了平方根,因为如果直接取差值的话,大的对象对差值的敏感度较低,小的对象对差值的敏感度较高,所以取平方根可以降低这种敏感度的差异,使得较大的对象和较小的对象在尺寸误差上有相似的权重。
- c) 乘以 λ c o o r d \lambda_{coord} λcoord 调节bounding box位置误差的权重(相对分类误差和置信度误差)。Yolo 中 λ c o o r d = 5 \lambda_{coord} = 5 λcoord=5,即调高位置误差的权重。
③ bounding box的置信度误差 公式第3行和第4行。
- a) 第 3 3 3 行是存在对象的bounding box的置信度误差。带有 1 i j o b j 1_{ij}^{obj} 1ijobj 意味着只有"负责"(IOU比较大)预测的那个bounding box的置信度才会计入误差。
- b) 第 4 4 4 行是不存在对象的bounding box的置信度误差。因为不存在对象的bounding box应该老老实实的说"我这里没有对象",也就是输出尽量低的置信度。如果它不恰当的输出较高的置信度,会与真正"负责"该对象预测的那个bounding box产生混淆。其实就像对象分类一样,正确的对象概率最好是 1 1 1,所有其它对象的概率最好是 0 0 0。
- c) 第 4 4 4 行会乘以 λ n o o b j \lambda_{noobj} λnoobj 调节不存在对象的bounding box的置信度的权重(相对其它误差)。Yolo 中设置 λ n o o b j = 0.5 \lambda_{noobj} = 0.5 λnoobj=0.5,即调低不存在对象的bounding box的置信度误差的权重。
1.6. 利用官网权重进行检测
yolov3.weights和yolov3-tiny.weights官网权重文件下载
wget https://pjreddie.com/media/files/yolov3.weights
wget https://pjreddie.com/media/files/yolov3-tiny.weights
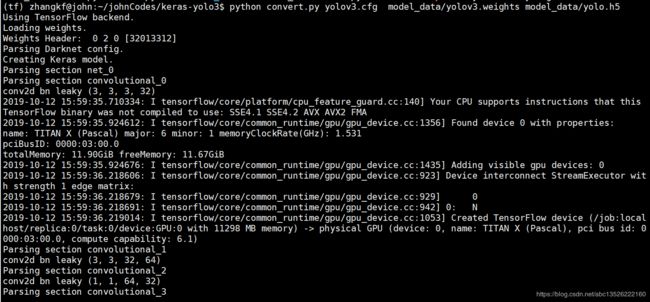
- 转换权重文件, 执行代码中的下面命令
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
- 会在
model_data文件夹中生成一个yolo.h5文件,注意这个权重文件要留着,后面可能会用上;
- 打开
yolo_video.py,其用法如下:
usage: yolo_video.py [-h] [--model MODEL] [--anchors ANCHORS]
[--classes CLASSES] [--gpu_num GPU_NUM] [--image]
[--input] [--output]
positional arguments:
--input Video input path
--output Video output path
optional arguments:
-h, --help show this help message and exit
--model MODEL path to model weight file, default model_data/yolo.h5
--anchors ANCHORS path to anchor definitions, default
model_data/yolo_anchors.txt
--classes CLASSES path to class definitions, default
model_data/coco_classes.txt
--gpu_num GPU_NUM Number of GPU to use, default 1
--image Image detection mode, will ignore all positional arguments
- 这里以识别一个张图片为例子
python yolo_video.py --image
# 会提示输入图片的路径;输入要探测的图片路径就可以啦。
二. 制作VOC2007格式数据集
2.1. 数据集标注
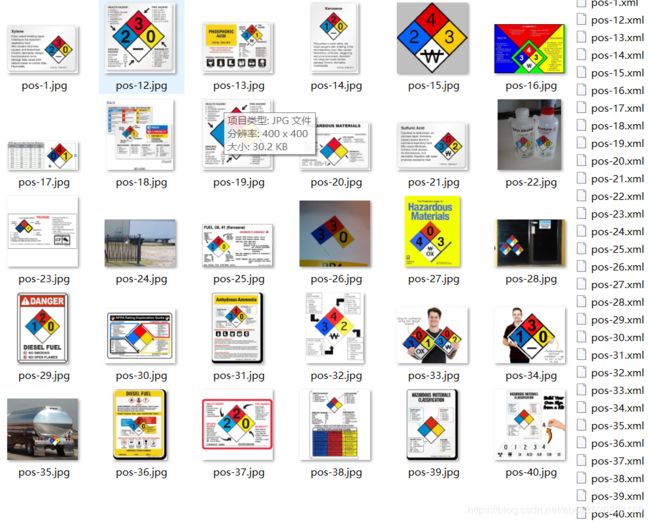
- 首先这里简要说明,自己简单的标注了40张图片,具体的方法参考我之前的博客:DL笔记:PascalVOC 数据集介绍+数据集标注工具!最终原图片和标记产生的xml文件如下,只有一个类别;使用的工具
LabelImg:链接:提取码:85y8
- 把
VOCdevkit所有文件夹里面的东西删除,保留所有文件夹的名字,如下图(左):

-
把刚才的40张图片都复制到
JPEGImages里面,如上图(右): -
把刚才标注生成的
.xml文件放到Annotations目录下面; -
接下来把
.xml文件解析成.txt文件,在VOC2007目录下建个文件test.py,内容如下:
import os
import random
trainval_percent = 0.9 # 整个数据集中,作为训练验证集的比例数
train_percent = 0.9 # 训练验证集中用于训练的数据的比例,根据实际情况修改
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath) # 得到整个注释文件的文件名
num = len(total_xml) # 文件个数
list = range(num) # 0到num
tv = int(num * trainval_percent) # 训练验证文件的个数
tr = int(tv * train_percent) # 训练文件的个数
trainval = random.sample(list, tv) # 从0到num中随机选取tv个
train = random.sample(trainval, tr) # 从trainval中随机选取tr个
ftrainval = open('ImageSets/Main/trainval.txt', 'w') #写模式打开trainval.txt,下同
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list: # 遍历文件
name = total_xml[i][:-4] + '\n' # 取不带格式的文件名
if i in trainval: # 分别写入不同的文件下
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close() # 关闭文件
ftrain.close()
fval.close()
ftest.close()
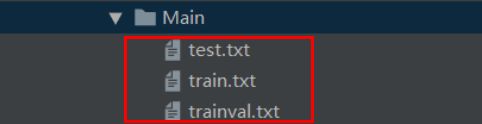
- 执行上述代码完成,会生成如下的4个文件;
VOC2007数据集制作完成,但是yolov3并不直接用这个数据集; 需要运行voc_annotation.py生成yolov3所需的train.txt,val.txt,test.txt;根据自己的数据,相应的调整代码;
"""
把xml文件转换为txt
1.得到train.txt 、val.txt 、test.txt
1.1 打开 VOCdevkit/VOC2012/ImageSets/Main/train.txt 读取为列表 ["2008_000008","2008_000019", ...]
1.2 将path/to/VOCdevkit/VOC2012/JPEGImages/2008_000008.jpg 写入 2012_train.txt 2012_val.txt
在这三个文件夹中分别得到对应数据集的绝对路径
2.得到标注文件
2.1 打开图片对应的原始标注文件 VOCdevkit/VOC2012/Annotations/2008_000008.xml
2.2 转换为yolo 的数据格式
2.3 写入VOCdevkit/VOC2012/labels/2008_000008.xml中
"""
import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["box"] # 自己要训练的类名字;
def convert_annotation(year, image_id, list_file):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for year, image_set in sets:
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
- 运行之后,会在主目录下多生成三个
.txt文件,如图所示:

2.2. 修改参数文件yolov3.cfg
- 注意: 如果我们从头开始训练自己网络的话,这个文件不需要修改;这个文件的目的就是用来转换官网下载的
.weights文件用,详见readme!
1. Make sure you have run `python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5`
2. The file model_data/yolo_weights.h5 is used to load pretrained weights.
- 直接打开
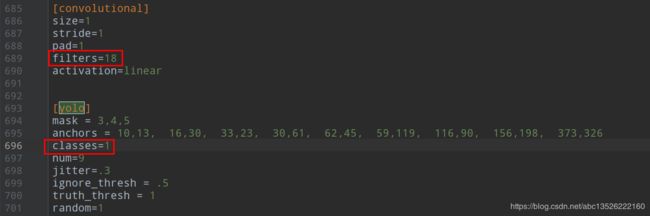
yolo3.cfg,搜索yolo,总共会搜出三个含有yolo的地方;其中如下需要修改计算的:
# 记得3处都要修改的!!!!!!
1. filters:3 * (5+len(classes)) = 18;
2. classes: len(classes) = 1, 这个是你要训练的类的数量
3. random =1 : 原来是1,显存小改为0,关闭多尺度训练,有博客说打开的话会精确一些
2.3. 修改model_data下的文件
- 修改
model_data下的文件,放入你的类别,coco,voc这两个文件都需要修改。修改如下:
三. 模型训练train.py
yolov3代码原作者在train.py做了两件事情:- 会加载预先对
coco数据集已经训练完成的yolov3权重文件 - 冻结了开始到最后倒数第
N层(源代码为N=-2) - 但是如果你想训练的东西,
coco数据集里的voc数据集里没有,所以建议从头开始训练,对train.py做了一下修改,直接复制替换原文件就可以了,细节大家自己看吧,直接运行,loss达到10几的时候效果就可以了
3.1. 代码解读train.py
train.py,这里可以直接替换原来的文件!
"""
"""
Retrain the YOLO model for your own dataset.
@devinzhang
在train.py中主要就是构建yolov3的训练模型,这里作者使用自定义loss的方式进行模型训练并没有,在loss时输入y_true, y_pred
YOLO v3采用(类似FPN)上采样(Upsample)和融合做法,融合了3个尺度(13*13、26*26和52*52)
多个尺度的融合特征图上分别独立做检测,最终对于小目标的检测效果提升明显
"""
import numpy as np
import tensorflow as tf
import keras.backend as K
from keras.layers import Input, Lambda
from keras.models import Model
from keras.optimizers import Adam
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss
from yolo3.utils import get_random_data
def _main():
############################# 设置GPU资源 ############################################################################
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 几块GPU训练 “0,1”
from keras import backend as K
# 当allow_growth设置为True时,分配器将不会指定所有的GPU内存,而是根据需求增长
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # 动态申请显存
# config.gpu_options.per_process_gpu_memory_fraction = 0.4 # 占用40%显存
sess = tf.Session(config=config)
K.set_session(sess) # 程序运行完毕,关闭Session
####################################################################################################################
annotation_path = '2007_train.txt' # 训练数据
log_dir = 'logs/000/' # 保存的日志文件夹
classes_path = 'model_data/voc_classes.txt' # 类别信息
anchors_path = 'model_data/yolo_anchors.txt' # anchors
class_names = get_classes(classes_path) # 类别列表
num_classes = len(class_names) # 类别数
anchors = get_anchors(anchors_path) # anchors列表
input_shape = (416,416) # 32的倍数,输入图像
pretrained_path = 'logs/000/ep200-loss20.860-val_loss24.638.h5' # 加载保存好的模型路径
####################################################################################################################
is_tiny_version = len(anchors)==6 # 默认设定,yolo-tiny
if is_tiny_version:
model = create_tiny_model(input_shape, anchors, num_classes, freeze_body=2, weights_path=pretrained_path)
else:
# 创建需要训练的模型; 可以设置预训练的路径看下面的函数
# freeze_body:冻结模式,1或2。其中,1是冻结DarkNet53网络中的层,2是只保留最后3个1x1的卷积层,其余层全部冻结;
model = create_model(input_shape, anchors, num_classes, freeze_body=2, weights_path=pretrained_path)
####################################################################################################################
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + "ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5",
monitor='val_loss', save_weights_only=True,
save_best_only=True, period=100) # 只存储weights
# reduce_lr:当评价指标不在提升时,减少学习率,每次减少10%,当验证损失值,持续3次未减少时,则终止训练。
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1)
# early_stopping:当验证集损失值,连续增加小于0时,持续10个epoch,则终止训练。
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
val_split = 0.1 # 训练和验证的比例
with open(annotation_path) as f:
lines = f.readlines()
np.random.seed(47)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines)*val_split) # 验证集数量
num_train = len(lines) - num_val # 训练集数量
# Train with frozen layers first, to get a stable loss.
# Adjust num epochs to your dataset. This step is enough to obtain a not bad model.
"""
把目标当成一个输入,构成多输入模型,把loss写成一个层,作为最后的输出,搭建模型的时候,就只需要将模型的output定义为loss,
而compile的时候,直接将loss设置为y_pred(因为模型的输出就是loss,所以y_pred就是loss),无视y_true,训练的时候,
y_true随便扔一个符合形状的数组进去就行了。
"""
####################################################################################################################
# 第1阶段,冻结部分网络,只训练底层权重:
# 优化器使用常见的Adam;
if True:
model.compile(optimizer=Adam(lr=1e-3),
loss={'yolo_loss': lambda y_true, y_pred: y_pred}) # 使用定制的 yolo_loss Lambda层损失函数
batch_size = 8 # batch尺寸
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
# 在训练中,模型调用fit_generator方法,按批次创建数据,输入模型,进行训练。其中,数据生成器wrapper是data_generator_wrapper,
# 用于验证数据格式,最终调用data_generator
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train // batch_size),
validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val // batch_size),
epochs=0,
initial_epoch=0,
callbacks=[logging, checkpoint])
# 存储最终的权重,再训练过程中,通过回调存储
model.save_weights(log_dir + 'trained_weights_stage_1.h5')
####################################################################################################################
# Unfreeze and continue training, to fine-tune.
# Train longer if the result is not good.
# 第2阶段,使用第1阶段已训练完成的网络权重,继续训练:
# 损失函数,直接使用模型的输出y_pred,忽略真值y_true;
# 将全部的权重都设置为可训练,而在第1阶段中,则是冻结部分权重;
# 优化器,仍是Adam,只是学习率有所下降,从1e-3 减少至1e-4;
# 损失函数,仍是只使用y_pred,忽略y_true。
if True: # 全部训练
for i in range(len(model.layers)):
model.layers[i].trainable = True
learning_rate = 1e-4
model.compile(optimizer=Adam(lr=learning_rate),
loss={'yolo_loss': lambda y_true, y_pred: y_pred}) # recompile to apply the change
print('Unfreeze all of the layers,','lr: ', learning_rate)
batch_size = 8 # note that more GPU memory is required after unfreezing the body
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=500,
initial_epoch=0,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
# 至此,在第2阶段训练完成之后,输出的网络权重,就是最终的模型权重。
model.save_weights(log_dir + 'trained_weights_final.h5')
####################################################################################################################
def get_classes(classes_path):
# 输入类别文件,读取文件中所有的类别,生成list
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
# 获取所有的anchors的长和宽
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def create_model(input_shape, anchors, num_classes, load_pretrained=False, freeze_body=False, weights_path='model_data/yolo_weights.h5'):
"""
input_shape:图片尺寸;
anchors:9个anchor box;
num_classes:类别数;
freeze_body:冻结模式,1是冻结DarkNet53的层,2是冻结全部,只保留最后3层;
weights_path:预训练模型的权重。
下面这个可以用来加载预训练模型: 'model_data/yolo_weights.h5'
"""
'''create the training model'''
K.clear_session() # 清除session
h, w = input_shape # 尺寸
image_input = Input(shape=(w, h, 3)) # 图片输入格式
num_anchors = len(anchors) # anchor数量
####################################################################################################################
# YOLO的三种尺度,每个尺度的anchor数,类别数+边框4个+置信度1
# 真值y_true,真值即Ground Truth, 通过循环,创建3个Input层的列表,作为y_true。y_true的张量结构,如下:
# y_true = [shape = (?, 13, 13, 3, 25),
# shape = (?, 26, 26, 3, 25),
# shape = (?, 52, 52, 3, 25)]
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], num_anchors//3, num_classes+5)) for l in range(3)]
# 其中,在真值y_true中,第1位是输入的样本数,第2~3位是特征图的尺寸,如13x13,第4位是每个图中的anchor数,
# 第5位是:类别(n)+4个框值(xywh)+框的置信度(是否含有物体)。
model_body = yolo_body(image_input, num_anchors//3, num_classes) # model
# 其中:model_body.output = [shape=(?, 13, 13, 75), shape=(?, 26, 26, 75), shape=(?, 52, 52, 75)]
# 其中:model_body.input = Tensor("input_1:0", shape=(?, 416, 416, 3), dtype=float32)
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
####################################################################################################################
if load_pretrained: # 加载预训练模型
model_body.load_weights(weights_path, by_name=True) # 加载参数,跳过错误 最后一个参数删除了, skip_mismatch=True
print('Load weights {}.'.format(weights_path))
# 选择冻结模式:模式1是冻结185层, 模式2是保留最底部3层,其余全部冻结。整个模型共有252层;将所冻结的层,设置为不可训练,trainable=False;
# 其中,185层是DarkNet53网络的层数,而最底部3层是3个1x1的卷积层,用于预测最终结果。185层是DarkNet53网络的最后一个残差单元,
# 其输入和输出如下:input: [(None, 13, 13, 1024), (None, 13, 13, 1024)]; output: (None, 13, 13, 1024)
# 最底部3个1x1的卷积层,将3个特征矩阵转换为3个预测矩阵,其格式如下:
# 1: (None, 13, 13, 1024) -> (None, 13, 13, 18)
# 2: (None, 26, 26, 512) -> (None, 26, 26, 18)
# 3: (None, 52, 52, 256) -> (None, 52, 52, 18)
if freeze_body:
# Freeze darknet53 body or freeze all but 3 output layers.
num = (185, len(model_body.layers) - 3)[freeze_body - 1]
for i in range(num):
model_body.layers[i].trainable = False # 将其他层的训练关闭
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
# 构建模型的损失层model_loss; Lambda是Keras的自定义层, 输入为model_body.output和y_true,输出output_shape是(1,),即一个损失值;
# 自定义Lambda层的名字name为yolo_loss;ignore_thresh用于在物体置信度损失中过滤IoU较小的框;
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes,
'ignore_thresh': 0.5})(model_body.output + y_true)
# y_true = [shape = (?, 13, 13, 3, 25),
# shape = (?, 26, 26, 3, 25),
# shape = (?, 52, 52, 3, 25)]
# 构建完整的算法模型,步骤如下:
# 1. 模型的输入层:model_body的输入和真值y_true;
# 2. 模型的输出层:自定义的model_loss层,其输出是一个损失值(None,1);
# 3. 保存模型的网络图plot_model和打印网络结构model.summary;
model = Model(inputs=[model_body.input] + y_true, outputs=model_loss)
# 其中:model_body.input是任意(?)个(416,416,3)的图片
# model.summary() # 打印网络结构
return model
def create_tiny_model(input_shape, anchors, num_classes, load_pretrained=True, freeze_body=2, weights_path='model_data/tiny_yolo_weights.h5'):
'''create the training model, for Tiny YOLOv3'''
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h//{0:32, 1:16}[l], w//{0:32, 1:16}[l], num_anchors//2, num_classes+5)) for l in range(2)]
model_body = tiny_yolo_body(image_input, num_anchors//2, num_classes)
print('Create Tiny YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print('Load weights {}.'.format(weights_path))
if freeze_body in [1, 2]:
# Freeze the darknet body or freeze all but 2 output layers.
num = (20, len(model_body.layers)-2)[freeze_body-1]
for i in range(num): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes,
'ignore_thresh': 0.7})(model_body.output + y_true)
model = Model(inputs=[model_body.input] + y_true, outputs=model_loss) # 模型,inputs和outputs
return model
def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes):
'''data generator for fit_generator
annotation_lines: 所有的图片名称
batch_size:每批图片的大小
input_shape: 图片的输入尺寸
anchors: 大小
num_classes: 类别数
'''
n = len(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
if i==0:
# 随机排列图片顺序
np.random.shuffle(annotation_lines)
# image_data: (16, 416, 416, 3)
# box_data: (16, 20, 5) # 每个图片最多含有20个框
image, box = get_random_data(annotation_lines[i], input_shape, random=True)
#获取真实的数据根据输入的尺寸对原始数据进行缩放处理得到input_shape大小的数据图片,
# 随机进行图片的翻转,标记数据数据也根据比例改变
image_data.append(image)
box_data.append(box)
i = (i + 1) % n
image_data = np.array(image_data)
box_data = np.array(box_data)
# y_true是3个预测特征的列表
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes) # 真值
# y_true的第0和1位是中心点xy,范围是(0~13/26/52),第2和3位是宽高wh,范围是0~1,
# 第4位是置信度1或0,第5~n位是类别为1其余为0。
# [(16, 13, 13, 3, 6), (16, 26, 26, 3, 6), (16, 52, 52, 3, 6)]
yield [image_data] + y_true, np.zeros(batch_size)
def data_generator_wrap(annotation_lines, batch_size, input_shape, anchors, num_classes):
"""
用于条件检查
"""
n = len(annotation_lines) # 标注图片的行数
if n==0 or batch_size<=0:
return None
return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes)
if __name__ == '__main__':
_main()
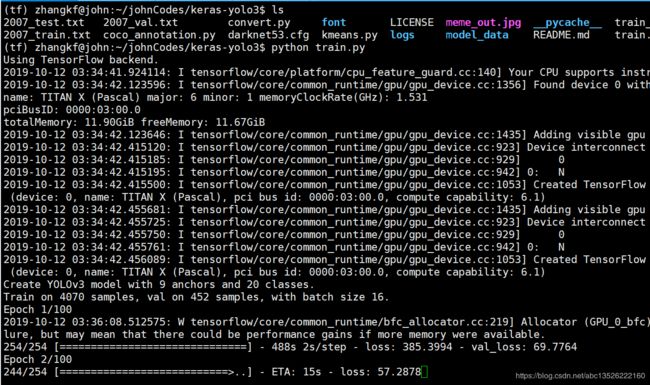
- 训练过程截图:
3.2. 补充:冻结网络层
-
在微调中,需要确定冻结的层数和可训练的层数,主要取决于,数据集相似度和新数据集的大小。原则上,相似度越高,则固定的层数越多;新数据集越大,不考虑训练时间的成本,则可训练更多的层数。然后可能也要考虑数据集本身的类别间差异度,但上面说的规则基本上还是成立的。
-
例如,在图片分类的网络中,底层一般是颜色、轮廓、纹理等基础结构,显然大部分问题都由这些相同的基础结构组成,所以可以冻结这些层。层数越高,所具有泛化性越高,例如这些层会包含对鞋子、裙子和眼睛等,具体语义信息,比较敏感的神经元。 所以,对于新的数据集,就需要训练这些较高的层。同时,比如一个高层神经元对车的轮胎较为敏感,不等于输入其它图像,就无法激活,因而,普通问题甚至可以只训练最后全连接层。
-
在Keras中,通过设置每层的trainable参数,即可控制是否冻结该层,如:
model_body.layers[i].trainable = False
3.3. 补充:目标检测之IoU计算方法
- 首先下面的内容摘自作者黑暗星球 目标检测之 IoU,表示感谢!
- IoU 的全称为交并比(Intersection over Union),通过这个名称我们大概可以猜到 IoU 的计算方法。IoU 计算的是 “预测的边框” 和 “真实的边框” 的交集和并集的比值。
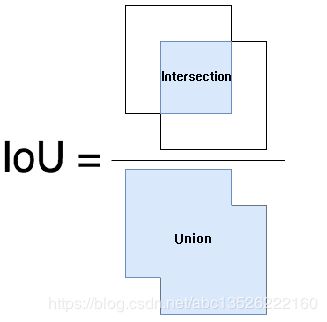
-
开始计算之前,我们首先进行分析下交集和并集到底应该怎么计算:我们首先需要计算交集,然后并集通过两个边框的面积的和减去交集部分即为并集,因此 IoU 的计算的难点在于交集的计算。
-
为了计算交集,你脑子里首先想到的方法应该是:考虑两个边框的相对位置,然后按照相对位置(左上,左下,右上,右下,包含,互不相交)分情况讨论,来计算交集。

- 上图就是你的直觉,这样想没有错。但计算一个交集,就要分多种情况讨论,要是程序真的按照这逻辑编写就太搞笑了。因此对这个问题进行进一步地研究显得十分有必要。
- 让我们重新思考一下两个框交集的计算。两个框交集的计算的实质是两个集合交集的计算,因此我们可以将两个框的交集的计算简化为:

-
通过简化,我们可以清晰地看到,交集计算的关键是交集上下界点(图中蓝点)的计算。我们假设集合 A \mathrm A A 为 [ x 1 , x 2 ] \left[ x_{1}, x_{2}\right] [x1,x2],集合 B \mathrm B B 为 [ y 1 , y 2 ] \left[ y_{1}, y_{2}\right] [y1,y2],然后我们来求 A B \mathrm A \mathrm B AB 交集的上下界限。
-
交集计算的逻辑如下:
-
1. 交集下界 z 1 : max ( x 1 , y 1 ) \mathrm z_{1}: \max \left(x_{1}, y_{1}\right) z1:max(x1,y1)
-
2. 交集上界 z 2 : min ( x 2 , y 2 ) \mathrm z_{2}: \min \left(x_{2}, y_{2}\right) z2:min(x2,y2)
-
3. 如果 z 2 − z 1 \mathrm z_{2}-\mathrm z_{1} z2−z1 小于 0 0 0,则说明集合 A \mathrm A A 和集合 B \mathrm B B 没有交集。
-
下面使用Python来实现两个一维集合的 IoU 的计算:
def iou(set_a, set_b):
''' 一维 iou 的计算 '''
x1, x2 = set_a # 元素为:(left, right)
y1, y2 = set_b # 元素为:(left, right)
low = max(x1, y1)
high = min(x2, y2)
# intersection 交集计算
if high - low < 0:
inter = 0
else:
inter = high - low
# union 并集计算
union = (x2 - x1) + (y2 - y1) - inter
# iou inter / union
iou = inter / union
return iou
- 上面,我们计算了两个一维集合的 IOU,将上面的程序进行扩展,即可得到两个框IOU计算的程序。
def iou(box1, box2):
'''
两个框(二维)的 iou 计算; 注意:边框以左上为原点
box:[top, left, bottom, right] 左上角坐标,和右下角坐标!
'''
# box1: [box1[0], box1[1], box1[2], box1[3]]
# box2: [box2[0], box2[1], box2[2], box2[3]]
# 第一步:水平方向上面:box1水平方向区间::(box1[0], box1[2]) box2水平区间:(box2[0], box2[2])
max1_left = max(box1[0], box2[0])
min1_right = min(box1[2], box2[2])
in_h = min1_right - max1_left
# 第二步:垂直方向上面:box1垂直方向区间::(box1[1], box1[3]) box2垂直方向区间:(box2[1], box2[3])
max2_left = max(box1[1], box2[1])
min2_right = min(box1[3], box2[3])
in_w = min2_right - max2_left
if in_h < 0 or in_w < 0:
inter = 0
else:
inter = in_h * in_w
union = (box1[2] - box1[0]) * (box1[3] - box1[1]) + (box2[2] - box2[0]) * (box2[3] - box2[1]) - inter
# 计算IOU的值!
iou = inter / union
return iou
3.4. 补充:冻结网络层
-
在微调中,需要确定冻结的层数和可训练的层数,主要取决于,数据集相似度和新数据集的大小。原则上,相似度越高,则固定的层数越多;新数据集越大,不考虑训练时间的成本,则可训练更多的层数。然后可能也要考虑数据集本身的类别间差异度,但上面说的规则基本上还是成立的。
-
例如,在图片分类的网络中,底层一般是颜色、轮廓、纹理等基础结构,显然大部分问题都由这些相同的基础结构组成,所以可以冻结这些层。 层数越高,所具有泛化性越高,例如这些层会包含对鞋子、裙子和眼睛等,具体语义信息,比较敏感的神经元。所以,对于新的数据集,就需要训练这些较高的层。同时,比如一个高层神经元对车的轮胎较为敏感,不等于输入其它图像,就无法激活,因而,普通问题甚至可以只训练最后全连接层。
-
在Keras中,通过设置每层的
trainable参数,即可控制是否冻结该层,如:model_body.layers[i].trainable = False
3.5. 补充:1x1卷积操作与全连接
- 1 × 1 1×1 1×1 的卷积层和全连接层都可以作为最后一层的预测输出,两者之间略有不同。
第1点: 1 × 1 1×1 1×1 的卷积层,比全连接层,更为灵活;
- 1 × 1 1×1 1×1 的卷积层,可以不考虑输入的通道数,输出固定通道数的特征矩阵;
- 全连接层(Dense),输入和输出都是固定的,在设计网络时,固定就不能修改;
第2点:例如:输入 ( 13 , 13 , 1024 ) (13,13,1024) (13,13,1024),输出为 ( 13 , 13 , 18 ) (13,13,18) (13,13,18),则两种操作:
- 1 × 1 1×1 1×1 的卷积层,参数较少,只需与输出通道匹配的参数,如 13 × 13 × 1 × 1 × 18 13×13×1×1×18 13×13×1×1×18 个参数;
- 全连接层,参数较多,需要与输入和输出都匹配的参数,如 13 × 13 × 1028 × 18 13×13×1028×18 13×13×1028×18个参数;
最后: 1 × 1 1×1 1×1 卷积操作的优点!
- 这个就比较好理解了, 1 × 1 1×1 1×1 的卷积核虽小,但也是卷积核,加 1 1 1 层卷积,网络深度自然会增加。我们知道,卷积后生成图片的尺寸受卷积核的大小和跨度影响,但如果卷积核是 1 × 1 1×1 1×1 ,跨度也是 1 1 1,那么生成后的图像大小就并没有变化。但通常一个卷积过程包括一个激活函数,比如 Sigmoid 和 Relu。所以,在输入不发生尺寸的变化下,却引入了更多的非线性,这将增强神经网络的表达能力。
四. 对图片进行检测
4.1. 修改yolo.py代码
yolo.py中需要修改的地方
"model_path": 'logs/000/trained_weights_final.h5', ############## 训练的模型保存文件;
"anchors_path": 'model_data/yolo_anchors.txt', ############## anchors
"classes_path": 'model_data/voc_classes.txt', ############## 类别
4.2. 代码执行过程+结果
- 执行检测如下:
(tf) zhangkf@john:~/johnCodes/keras-yolo3$ python yolo_video.py --image
Using TensorFlow backend.
Image detection mode
name: TITAN X (Pascal) major: 6 minor: 1 memoryClockRate(GHz): 1.531
pciBusID: 0000:03:00.0
totalMemory: 11.90GiB freeMemory: 11.67GiB
name: TITAN X (Pascal), pci bus id: 0000:03:00.0, compute capability: 6.1)
logs/000/trained_weights_final.h5 model, anchors, and classes loaded.
Input image filename:/home/zhangkf/johnCodes/keras-yolo3/VOCdevkit/VOC2007/JPEGImages/pos-219.jpg
(416, 416, 3)
Found 2 boxes for img
box 0.81 (454, 366) (468, 392)
box 0.91 (540, 440) (553, 465)
0.08477453794330359
Input image filename:/home/zhangkf/johnCodes/keras-yolo3/VOCdevkit/VOC2007/JPEGImages/pos-212.jpg
(416, 416, 3)
Found 3 boxes for img
box 0.70 (227, 225) (250, 278)
box 0.96 (494, 377) (513, 409)
box 0.98 (416, 431) (435, 469)
0.09012221498414874
- 检测结果分别如下:
五. 重要代码注释model.py
- 网络结构实现代码在
model.py文件,本人加上了一些自己理解的注释,个人认为对网络结构理解特别重要!
""" YOLO_v3 Model Defined in Keras. """
from functools import wraps
import numpy as np
import tensorflow as tf
from keras import backend as K
from keras.layers import Conv2D, Add, ZeroPadding2D, UpSampling2D, Concatenate, MaxPooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.regularizers import l2
from yolo3.utils import compose
"""
Python中@wraps它是一个装饰器,它修饰函数Conv2D,这样当你调用Conv2D函数的时候,其实会调用DarknetConv2D函数,
这样你可以做一些额外的处理,然后再调用真正的Conv2D;
其中:一个是设置核函数的正则项,采用l2正则,一个是padding,之前说了,这个是用来填补数据的边缘区域。再设置好之后,
这些参数放入darknet_conv_kwargs传给Conv2D
"""
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
"""Wrapper to set Darknet parameters for Convolution2D.
普通的卷积网络,带正则化,当步长为2时进行下采样
"""
# 将核权重矩阵的正则化,使用L2正则化,参数是5e-4,即操作w参数;
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
# Padding,一般使用same模式,只有当步长为(2,2)时,使用valid模式。避免在降采样中,引入无用的边界信息;
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
def DarknetConv2D_BN_Leaky(*args, **kwargs):
"""Darknet Convolution2D followed by BatchNormalization and LeakyReLU."""
# 没有偏置,带正则项
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(DarknetConv2D(*args, **no_bias_kwargs), BatchNormalization(), LeakyReLU(alpha=0.1))
def resblock_body(x, num_filters, num_blocks):
'''A series of resblocks starting with a downsampling Convolution2D'''
# 使用残差块, 1 + 2 * num_filters 为总的卷积层数
# Darknet uses left and top padding instead of 'same' mode
# ZeroPadding2D:填充x的边界为0,由(?, 416, 416, 32)转换为(?, 417, 417, 32)。因为下一步卷积操作的步长为2,所以图的边长需要是奇数;
x = ZeroPadding2D(((1,0),(1,0)))(x)
# DarknetConv2D_BN_Leaky:DarkNet的2维卷积操作,核是(3, 3),步长是(2, 2),注意,这会导致特征尺寸变小,
# 由(?, 417, 417, 32)转换为(?, 208, 208, 64)。由于num_filters是64,所以产生64个通道。
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
# compose:输出预测图y,功能是组合函数,先执行1x1的卷积操作,再执行3x3的卷积操作,
# filter先降低2倍后恢复,最后与输入相同,都是64;
y = compose(DarknetConv2D_BN_Leaky(num_filters//2, (1,1)),
DarknetConv2D_BN_Leaky(num_filters, (3,3)))(x)
# x = Add()([x, y]):残差操作,将x的值与y的值相加。残差操作可以避免,在网络较深时所产生的梯度弥散问题。
x = Add()([x,y])
return x
def darknet_body(x):
'''Darknent body having 52 Convolution2D layers
在darknet_body中,Darknet网络含有5组重复的resblock_body单元,即:
'''
# darknet的主体网络52层卷积网络
# darknet_body的输出格式是(?, 13, 13, 1024)。
x = DarknetConv2D_BN_Leaky(32, (3,3))(x)
x = resblock_body(x, 64, 1)
x = resblock_body(x, 128, 2)
x = resblock_body(x, 256, 8)
x = resblock_body(x, 512, 8)
# Tensor("add_23/add:0", shape=(?, 13, 13, 1024), dtype=float32)
# Darknet模型的输入是(?, 416, 416, 3),输出是(?, 13, 13, 1024)。
x = resblock_body(x, 1024, 4)
return x # 输出是(?, 13, 13, 1024)。
def make_last_layers(x, num_filters, out_filters):
'''6 Conv2D_BN_Leaky layers followed by a Conv2D_linear layer
在YOLO v3网络中,输出3个不同尺度的检测图,用于检测不同大小的物体。调用3次make_last_layers,产生3个检测图,即y1、y2和y3。
'''
# 最后检测头部,无降采采样操作
# 第1步,x执行多组1x1的卷积操作和3x3的卷积操作,filter先扩大再恢复,
# 最后与输入的filter保持不变,仍为512,则x由(?, 13, 13, 1024)转变为(?, 13, 13, num_filters);num_filters=512
x = compose(DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)))(x)
# x先执行3x3的卷积操作,再执行不含BN和Leaky的1x1的卷积操作,作用类似于全连接操作,生成预测矩阵y;
y = compose(DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D(out_filters, (1,1)))(x)
return x, y
def yolo_body(inputs, num_anchors, num_classes):
"""Create YOLO_V3 model CNN body in Keras."""
# yolov3的三个检测输出部分
# Darknet网络的输入是图片数据集inputs,即(?, 416, 416, 3),
# 第1个部分,输出维度是13x13。darknet.output:DarkNet网络的输出,即(?, 13, 13, 1024);
darknet = Model(inputs, darknet_body(inputs))
# 第1个make_last_layers方法,输出的x是(?, 13, 13, 512),输出的y1是(?, 13, 13, 75)。
# 由于模型只有20个检测类别,因而y的第4个维度是75,即3*(20+5)=75。
x, y1 = make_last_layers(darknet.output, 512, num_anchors*(num_classes+5)) # x是(?, 13, 13, 512); y1是(?, 13, 13, 75)
# 第2个部分,输出维度是26x26;上采样! 通过DarknetConv2D_BN_Leaky卷积,将x由512的通道数,转换为256的通道数;
# 通过2倍上采样UpSampling2D,将x由13x13的结构,转换为26x26的结构;
x = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(x) # x: shape=(?, 26, 26, 256)
# 将x与DarkNet的第152层拼接Concatenate; darknet.layers[152].output: (?, 26, 26, 512)
"""
# 在拼接之后,输出的x的格式是(?, 26, 26, 768)。
这样做的目的是:将Darknet最底层的高级抽象信息darknet.output,经过若干次转换之后,除了输出给第1个检测部分,
还被用于第2个检测部分,经过上采样,与Darknet骨干中,倒数第2次降维的数据拼接,共同作为第2个检测部分的输入。
底层抽象特征含有全局信息,中层抽象特征含有局部信息,这样拼接,两者兼顾,用于检测较小的物体。
"""
x = Concatenate()([x,darknet.layers[152].output]) # x: shape=(?, 26, 26, 768)。
# 最终,第2个make_last_layers方法,输出的x是(?, 26, 26, 256),输出的y2是(?, 26, 26, 75)。
x, y2 = make_last_layers(x, 256, num_anchors*(num_classes+5))
# 第3个部分,输出维度是52x52,与第2个部分类似上采样
x = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[92].output])
x, y3 = make_last_layers(x, 128, num_anchors*(num_classes+5))
# 13x13, 26x26, 52x52
# [y1, y2, y3]的结构如下:
# Tensor("conv2d_59/BiasAdd:0", shape=(?, 13, 13, 75), dtype=float32)
# Tensor("conv2d_67/BiasAdd:0", shape=(?, 26, 26, 75), dtype=float32)
# Tensor("conv2d_75/BiasAdd:0", shape=(?, 52, 52, 75), dtype=float32)
return Model(inputs, [y1,y2,y3])
def tiny_yolo_body(inputs, num_anchors, num_classes):
'''Create Tiny YOLO_v3 model CNN body in keras.'''
x1 = compose(
DarknetConv2D_BN_Leaky(16, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(32, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(64, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(128, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(256, (3,3)))(inputs)
x2 = compose(
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(512, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(1,1), padding='same'),
DarknetConv2D_BN_Leaky(1024, (3,3)),
DarknetConv2D_BN_Leaky(256, (1,1)))(x1)
y1 = compose(
DarknetConv2D_BN_Leaky(512, (3,3)),
DarknetConv2D(num_anchors*(num_classes+5), (1,1)))(x2)
x2 = compose(
DarknetConv2D_BN_Leaky(128, (1,1)),
UpSampling2D(2))(x2)
y2 = compose(
Concatenate(),
DarknetConv2D_BN_Leaky(256, (3,3)),
DarknetConv2D(num_anchors*(num_classes+5), (1,1)))([x2,x1])
return Model(inputs, [y1,y2])
def yolo_head(feats, anchors, num_classes, input_shape, calc_loss=False):
"""Convert final layer features to bounding box parameters."""
# feats的后处理函数,feats就是yolo_outputs,把输出转换到inputs的坐标系
num_anchors = len(anchors)
# Reshape to batch, height, width, num_anchors, box_params.
anchors_tensor = K.reshape(K.constant(anchors), [1, 1, 1, num_anchors, 2])
grid_shape = K.shape(feats)[1:3] # height, width
grid_y = K.tile(K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]),
[1, grid_shape[1], 1, 1])
grid_x = K.tile(K.reshape(K.arange(0, stop=grid_shape[1]), [1, -1, 1, 1]),
[grid_shape[0], 1, 1, 1])
grid = K.concatenate([grid_x, grid_y])
grid = K.cast(grid, K.dtype(feats))
feats = K.reshape(
feats, [-1, grid_shape[0], grid_shape[1], num_anchors, num_classes + 5])
# Adjust preditions to each spatial grid point and anchor size.
# 把结果转化到每个格子中,坐标为图片的坐标系的0-1,类别预测也为0-1
box_xy = (K.sigmoid(feats[..., :2]) + grid) / K.cast(grid_shape[::-1], K.dtype(feats))
box_wh = K.exp(feats[..., 2:4]) * anchors_tensor / K.cast(input_shape[::-1], K.dtype(feats))
box_confidence = K.sigmoid(feats[..., 4:5])
box_class_probs = K.sigmoid(feats[..., 5:])
if calc_loss == True:
return grid, feats, box_xy, box_wh
return box_xy, box_wh, box_confidence, box_class_probs
def yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape):
'''Get corrected boxes'''
# 把预测的图片转换到原始图片的大小
box_yx = box_xy[..., ::-1]
box_hw = box_wh[..., ::-1]
input_shape = K.cast(input_shape, K.dtype(box_yx))
image_shape = K.cast(image_shape, K.dtype(box_yx))
new_shape = K.round(image_shape * K.min(input_shape/image_shape))
offset = (input_shape-new_shape)/2./input_shape
scale = input_shape/new_shape
box_yx = (box_yx - offset) * scale
box_hw *= scale
box_mins = box_yx - (box_hw / 2.)
box_maxes = box_yx + (box_hw / 2.)
boxes = K.concatenate([
box_mins[..., 0:1], # y_min
box_mins[..., 1:2], # x_min
box_maxes[..., 0:1], # y_max
box_maxes[..., 1:2] # x_max
])
# Scale boxes back to original image shape.
boxes *= K.concatenate([image_shape, image_shape])
return boxes
def yolo_boxes_and_scores(feats, anchors, num_classes, input_shape, image_shape):
'''Process Conv layer output'''
# 对yolo的输出进行后处理,输出合适原始图片的box和scores
box_xy, box_wh, box_confidence, box_class_probs = yolo_head(feats,
anchors, num_classes, input_shape)
boxes = yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape)
boxes = K.reshape(boxes, [-1, 4])
box_scores = box_confidence * box_class_probs
box_scores = K.reshape(box_scores, [-1, num_classes])
return boxes, box_scores
def yolo_eval(yolo_outputs, anchors, num_classes, image_shape, max_boxes=20, score_threshold=.6, iou_threshold=.5):
"""Evaluate YOLO model on given input and return filtered boxes."""
# 使用yolo模型进行图片的检测,进行坐标转化,和nms处理,和
num_layers = len(yolo_outputs)
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]] # default setting
input_shape = K.shape(yolo_outputs[0])[1:3] * 32
boxes = []
box_scores = []
for l in range(num_layers):
_boxes, _box_scores = yolo_boxes_and_scores(yolo_outputs[l],
anchors[anchor_mask[l]], num_classes, input_shape, image_shape)
boxes.append(_boxes)
box_scores.append(_box_scores)
boxes = K.concatenate(boxes, axis=0)
box_scores = K.concatenate(box_scores, axis=0)
mask = box_scores >= score_threshold
max_boxes_tensor = K.constant(max_boxes, dtype='int32')
boxes_ = []
scores_ = []
classes_ = []
for c in range(num_classes):
# TODO: use keras backend instead of tf.
# 进行nms处理
class_boxes = tf.boolean_mask(boxes, mask[:, c])
class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c])
nms_index = tf.image.non_max_suppression(
class_boxes, class_box_scores, max_boxes_tensor, iou_threshold=iou_threshold)
class_boxes = K.gather(class_boxes, nms_index)
class_box_scores = K.gather(class_box_scores, nms_index)
classes = K.ones_like(class_box_scores, 'int32') * c
boxes_.append(class_boxes)
scores_.append(class_box_scores)
classes_.append(classes)
boxes_ = K.concatenate(boxes_, axis=0)
scores_ = K.concatenate(scores_, axis=0)
classes_ = K.concatenate(classes_, axis=0)
return boxes_, scores_, classes_
def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
'''Preprocess true boxes to training input format
y_true的第0和1位是中心点xy,范围是(0~13/26/52),第2和3位是宽高wh,范围是0~1,
第4位是置信度1或0,第5~n位是类别为1其余为0。
Parameters
----------
true_boxes: array, shape=(m, T, 5)
Absolute x_min, y_min, x_max, y_max, class_id relative to input_shape.
input_shape: array-like, hw, multiples of 32
anchors: array, shape=(N, 2), wh
num_classes: integer
Returns
-------
y_true: list of array, shape like yolo_outputs, xywh are reletive value
'''
assert (true_boxes[..., 4]<num_classes).all(), 'class id must be less than num_classes'
num_layers = len(anchors)//3 # default setting
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]]
true_boxes = np.array(true_boxes, dtype='float32')
input_shape = np.array(input_shape, dtype='int32')
boxes_xy = (true_boxes[..., 0:2] + true_boxes[..., 2:4]) // 2
boxes_wh = true_boxes[..., 2:4] - true_boxes[..., 0:2]
true_boxes[..., 0:2] = boxes_xy/input_shape[::-1]
true_boxes[..., 2:4] = boxes_wh/input_shape[::-1]
m = true_boxes.shape[0]
grid_shapes = [input_shape//{0:32, 1:16, 2:8}[l] for l in range(num_layers)]
y_true = [np.zeros((m,grid_shapes[l][0],grid_shapes[l][1],len(anchor_mask[l]),5+num_classes),
dtype='float32') for l in range(num_layers)]
# Expand dim to apply broadcasting.
anchors = np.expand_dims(anchors, 0)
anchor_maxes = anchors / 2.
anchor_mins = -anchor_maxes
valid_mask = boxes_wh[..., 0]>0
for b in range(m):
# Discard zero rows.
wh = boxes_wh[b, valid_mask[b]]
if len(wh)==0: continue
# Expand dim to apply broadcasting.
wh = np.expand_dims(wh, -2)
box_maxes = wh / 2.
box_mins = -box_maxes
intersect_mins = np.maximum(box_mins, anchor_mins)
intersect_maxes = np.minimum(box_maxes, anchor_maxes)
intersect_wh = np.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
box_area = wh[..., 0] * wh[..., 1]
anchor_area = anchors[..., 0] * anchors[..., 1]
iou = intersect_area / (box_area + anchor_area - intersect_area)
# Find best anchor for each true box
best_anchor = np.argmax(iou, axis=-1)
for t, n in enumerate(best_anchor):
for l in range(num_layers):
if n in anchor_mask[l]:
i = np.floor(true_boxes[b,t,0]*grid_shapes[l][1]).astype('int32')
j = np.floor(true_boxes[b,t,1]*grid_shapes[l][0]).astype('int32')
k = anchor_mask[l].index(n)
c = true_boxes[b,t, 4].astype('int32')
y_true[l][b, j, i, k, 0:4] = true_boxes[b,t, 0:4]
y_true[l][b, j, i, k, 4] = 1
y_true[l][b, j, i, k, 5+c] = 1
return y_true
def box_iou(b1, b2):
'''
Parameters
----------
b1: tensor, shape=(i1,...,iN, 4), xywh
b2: tensor, shape=(j, 4), xywh
Return iou tensor
-------
iou: tensor, shape=(i1,...,iN, j)
'''
# Expand dim to apply broadcasting.
b1 = K.expand_dims(b1, -2)
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# Expand dim to apply broadcasting.
b2 = K.expand_dims(b2, 0)
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
intersect_mins = K.maximum(b1_mins, b2_mins)
intersect_maxes = K.minimum(b1_maxes, b2_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
iou = intersect_area / (b1_area + b2_area - intersect_area)
return iou
def yolo_loss(args, anchors, num_classes, ignore_thresh=.5, print_loss=False):
'''Return yolo_loss tensor
Parameters
----------
yolo_outputs: list of tensor, the output of yolo_body or tiny_yolo_body
y_true: list of array, the output of preprocess_true_boxes
anchors: array, shape=(N, 2), wh
num_classes: integer
ignore_thresh: float, the iou threshold whether to ignore object confidence loss
Returns
-------
loss: tensor, shape=(1,)
'''
# 构建loss
num_layers = len(anchors)//3 # default setting num_layers = 3
# 分类args: 前3个是yolo_outputs预测值,后3个是y_true真值;
yolo_outputs = args[:num_layers] # yolo_outputs: [(?, 13, 13, 75), (?, 26, 26, 75), (?, 52, 52, 75)]
y_true = args[num_layers:] # yolo_true : [(?, 13, 13, 75), (?, 26, 26, 75), (?, 52, 52, 75)]
# anchor_mask:anchor box的索引数组,3个1组倒序排序,678对应13x13,345对应26x26,123对应52x52;即[[6, 7, 8], [3, 4, 5], [0, 1, 2]];
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]]
# a1 = yolo_outputs[0] # shape: (?, 13, 13, 75)
# a2 = K.shape(yolo_outputs[0]) # shape: (4,)
# a3 = K.shape(yolo_outputs[0])[1:3] # shape: (2,) backend.shape()返回张量或变量的符号shape内容应该是(13,13)的shape
# 第1个预测矩阵yolo_outputs[0]的结构(shape)的第1~2位,即(?, 13, 13, 18)中的(13, 13)。再x32,
# 就是YOLO网络的输入尺寸,即(416, 416),因为在网络中,含有5个步长为(2, 2)的卷积操作,降维32=5^2倍;
input_shape = K.cast(K.shape(yolo_outputs[0])[1:3] * 32, K.dtype(y_true[0]))
# grid_shapes:与input_shape类似,K.shape()[1:3],以列表的形式,选择3个尺寸的预测图维度,即[(13, 13), (26, 26), (52, 52)];
grid_shapes = [K.cast(K.shape(yolo_outputs[l])[1:3], K.dtype(y_true[0])) for l in range(num_layers)]
loss = 0
m = K.shape(yolo_outputs[0])[0] # m: 第1个预测图的结构的第1位,即K.shape()[0],输入模型的图片总量,即批次数batchsize;
mf = K.cast(m, K.dtype(yolo_outputs[0])) # mf: m的float类型,即K.cast(m, K.dtype())
# 在计算损失值时,循环计算每1层的损失值,累加到一起,即
for l in range(num_layers):
# 获取物体置信度object_mask,最后1个维度的第4位,第0~3位是框,第4位是物体置信度;
object_mask = y_true[l][..., 4:5]
# 类别置信度true_class_probs,最后1个维度的第5位开始;这里我用的数据集是:VOC2007,因此这里是20;
true_class_probs = y_true[l][..., 5:]
# 网格grid:结构是(13, 13, 1, 2),数值为0~12的全遍历二元组
# 预测值raw_pred:经过reshape变换,将anchors分离,结构是(?, 13, 13, 3, 25)
# pred_xy和pred_wh归一化的起始点xy和宽高wh,xy的结构是(?, 13, 13, 3, 2),wh的结构是(?, 13, 13, 3, 2);
grid, raw_pred, pred_xy, pred_wh = yolo_head(yolo_outputs[l],
anchors[anchor_mask[l]], num_classes, input_shape, calc_loss=True)
# 结构是(13, 13, 3, 4)
pred_box = K.concatenate([pred_xy, pred_wh])
# Darknet raw box to calculate loss.
raw_true_xy = y_true[l][..., :2]*grid_shapes[l][::-1] - grid
raw_true_wh = K.log(y_true[l][..., 2:4] / anchors[anchor_mask[l]] * input_shape[::-1])
raw_true_wh = K.switch(object_mask, raw_true_wh, K.zeros_like(raw_true_wh)) # avoid log(0)=-inf
box_loss_scale = 2 - y_true[l][...,2:3]*y_true[l][...,3:4]
# Find ignore mask, iterate over each of batch.
ignore_mask = tf.TensorArray(K.dtype(y_true[0]), size=1, dynamic_size=True)
object_mask_bool = K.cast(object_mask, 'bool')
def loop_body(b, ignore_mask):
true_box = tf.boolean_mask(y_true[l][b,...,0:4], object_mask_bool[b,...,0])
iou = box_iou(pred_box[b], true_box)
best_iou = K.max(iou, axis=-1)
ignore_mask = ignore_mask.write(b, K.cast(best_iou<ignore_thresh, K.dtype(true_box)))
return b+1, ignore_mask
_, ignore_mask = K.control_flow_ops.while_loop(lambda b,*args: b<m, loop_body, [0, ignore_mask])
ignore_mask = ignore_mask.stack()
ignore_mask = K.expand_dims(ignore_mask, -1)
# K.binary_crossentropy is helpful to avoid exp overflow.
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[...,0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh-raw_pred[...,2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True)+ \
(1-object_mask) * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True) * ignore_mask
################################################ 分类loss值 #####################################################
# tf.keras.backend.binary_crossentropy(
# target, # target:与output具有相同shape的张量。
# output, # output:一个张量
# from_logits=False) 输出张量和目标张量之间的二进制交叉熵。
aaa = true_class_probs # shape (?, 13, 13, 3, 20) 真实类标签20
aaa_ele = aaa[:, 0, 0, 0, :] # 20个类标签
label_one_hot = tf.one_hot(tf.cast(aaa_ele, dtype=tf.int32), 20)
bbb = raw_pred # shape (?, ?, ?, 3, 25)
ccc = raw_pred[..., 5:] # shape (?, ?, ?, 3, 20) 预测类标签20
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[...,5:], from_logits=True)
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
if print_loss:
loss = tf.Print(loss, [loss, xy_loss, wh_loss, confidence_loss, class_loss, K.sum(ignore_mask)], message='loss: ')
return loss
六. Keras中自定义损失函数的方法
-
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
-
Keras作为一个深度学习库,非常适合新手。在做神经网络时,它自带了许多常用的目标函数,优化方法等等,基本能满足新手学习时的一些需求。具体包含 目标函数 和 优化方法。但它也支持用户自定义目标函数,下边介绍一种最简单的自定义目标函数的方法。
-
要实现自定义目标函数,自然想到先看下Keras中的目标函数是怎么定义的。查下源码发现在Keras/objectives.py中,Keras定义了一系列的目标函数。
def mean_squared_error(y_true, y_pred): # 均方差mse
return K.mean(K.square(y_pred - y_true), axis=-1)
def mean_absolute_error(y_true, y_pred): # mae
return K.mean(K.abs(y_pred - y_true), axis=-1)
def mean_absolute_percentage_error(y_true, y_pred): # mape
diff = K.abs((y_true - y_pred) / K.clip(K.abs(y_true), K.epsilon(), np.inf))
return 100. * K.mean(diff, axis=-1)
def mean_squared_logarithmic_error(y_true, y_pred):
first_log = K.log(K.clip(y_pred, K.epsilon(), np.inf) + 1.)
second_log = K.log(K.clip(y_true, K.epsilon(), np.inf) + 1.)
return K.mean(K.square(first_log - second_log), axis=-1)
def squared_hinge(y_true, y_pred): # 平方的hinge loss
return K.mean(K.square(K.maximum(1. - y_true * y_pred, 0.)), axis=-1)
def hinge(y_true, y_pred): # hinge loss
return K.mean(K.maximum(1. - y_true * y_pred, 0.), axis=-1)
def categorical_crossentropy(y_true, y_pred):
'''Expects a binary class matrix instead of a vector of scalar classes.
# 亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如(nb_samples, nb_classes)的二值序列
########################################################################################
# 注意: 当使用"categorical_crossentropy"作为目标函数时,标签应该为多类模式,即one-hot编码的向量,而不是单个数值.
可以使用工具中的to_categorical函数完成该转换.示例如下:
from keras.utils.np_utils import to_categorical
categorical_labels = to_categorical(int_labels, num_classes=None)
'''
return K.categorical_crossentropy(y_pred, y_true)
def sparse_categorical_crossentropy(y_true, y_pred):
'''expects an array of integer classes.
Note: labels shape must have the same number of dimensions as output shape.
If you get a shape error, add a length-1 dimension to labels.
# 如上,但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你可能需要在标签数据上增加一个维度:
np.expand_dims(y,-1)
'''
return K.sparse_categorical_crossentropy(y_pred, y_true)
def binary_crossentropy(y_true, y_pred):
'''
亦称作对数损失,logloss)
'''
return K.mean(K.binary_crossentropy(y_pred, y_true), axis=-1)
def kullback_leibler_divergence(y_true, y_pred):
y_true = K.clip(y_true, K.epsilon(), 1)
y_pred = K.clip(y_pred, K.epsilon(), 1)
return K.sum(y_true * K.log(y_true / y_pred), axis=-1)
def poisson(y_true, y_pred):
return K.mean(y_pred - y_true * K.log(y_pred + K.epsilon()), axis=-1)
def cosine_proximity(y_true, y_pred):
y_true = K.l2_normalize(y_true, axis=-1)
y_pred = K.l2_normalize(y_pred, axis=-1)
return -K.mean(y_true * y_pred, axis=-1)
- 看到源码后,事情就简单多了,我们只要仿照这源码的定义形式,来定义自己的loss就可以了。
6.1. 例子1:自定义loss
- 例子1:我们定义一个loss为预测值与真实值的差,则可写为:
def my_koss(y_true,y_pred):
return K.mean((y_pred-y_true),axis=-1)
- 然后,将这段代码放到你的模型中编译,例如
def my_loss(y_true,y_pred):
return K.mean((y_pred-y_true),axis = -1)
model.compile(loss=my_loss, optimizer='SGD', metrics=['accuracy'])
- 有一点需要注意,Keras作为一个高级封装库,它的底层(后端)可以支持theano或者tensorflow,在使用上边代码时,首先要导入这一句,这样你自定义的loss函数就可以起作用了。
from keras import backend as K
6.2. 例子2:自定义loss
-
例子2:我们做分类问题时,经常用的就是softmax输出,然后用交叉熵作为loss。然而这种做法也有不少缺点,其中之一就是分类太自信,哪怕输入噪音,分类的结果也几乎是非1即0,这通常会导致过拟合的风险,还会使得我们在实际应用中没法很好地确定置信区间、设置阈值。因此很多时候我们也会想办法使得分类别太自信,而修改loss也是手段之一。
-
如果不修改loss,我们就是使用交叉熵去拟合一个one hot的分布。交叉熵的公式是
S ( q ∣ p ) = − ∑ i q i log p i S(q | p)=-\sum_{i} q_{i} \log p_{i} S(q∣p)=−i∑qilogpi -
其中 p i p_{i} pi 是预测的分布,而 q i q_{i} qi 是真实的分布,比如输出为 [ z 1 , z 2 , z 3 ] [z_1,z_2,z_3] [z1,z2,z3],真实值(目标) 为 [ 1 , 0 , 0 ] [1,0,0] [1,0,0],那么
l o s s = − log ( e z 1 / Z ) , Z = e z 1 + e z 2 + e z 3 loss = -\log \Big(e^{z_1}/Z\Big),\, Z=e^{z_1}+e^{z_2}+e^{z_3} loss=−log(ez1/Z),Z=ez1+ez2+ez3 -
只要 z 1 z_1 z1 已经是 [ z 1 , z 2 , z 3 ] [z_1,z_2,z_3] [z1,z2,z3] 的最大值,那么我们总可以 “变本加厉” —通过增大训练参数,使得 z 1 , z 2 , z 3 z_1,z_2,z_3 z1,z2,z3增加足够大的比例(等价地,即增大向量 [ z 1 , z 2 , z 3 ] [z_1,z_2,z_3] [z1,z2,z3] 的模长),从而 z 1 / Z {z_1}/Z z1/Z 足够接近 1 1 1(等价地,loss足够接近0)。这就是通常softmax过于自信的来源:只要盲目增大模长,就可以降低loss,训练器肯定是很乐意了,这代价太低了。为了使得分类不至于太自信,一个方案就是不要单纯地去拟合one hot分布,分一点力气去拟合一下均匀分布,即改为新loss:
l o s s = − ( 1 − ε ) log ( e z 1 / Z ) − ε ∑ i = 1 n 1 3 log ( e z i / Z ) , Z = e z 1 + e z 2 + e z 3 loss = -(1-\varepsilon)\log \Big(e^{z_1}/Z\Big)-\varepsilon\sum_{i=1}^n \frac{1}{3}\log \Big(e^{z_i}/Z\Big),\, Z=e^{z_1}+e^{z_2}+e^{z_3} loss=−(1−ε)log(ez1/Z)−εi=1∑n31log(ezi/Z),Z=ez1+ez2+ez3
- 这样,盲目地增大比例使得 z 1 / Z {z_1}/Z z1/Z 接近于 1 1 1,就不再是最优解了,从而可以缓解softmax过于自信的情况,不少情况下,这种策略还可以增加测试准确率(防止过拟合)。
- 那么,在Keras中应该怎么写呢?其实挺简单的:
from keras.layers import Input,Embedding,LSTM,Dense
from keras.models import Model
from keras import backend as K
word_size = 128
nb_features = 10000
nb_classes = 10
encode_size = 64
input = Input(shape=(None,))
embedded = Embedding(nb_features,word_size)(input)
encoder = LSTM(encode_size)(embedded)
predict = Dense(nb_classes, activation='softmax')(encoder)
# 自定义loss函数模块
def mycrossentropy(y_true, y_pred, e=0.1):
loss1 = K.categorical_crossentropy(y_true, y_pred)
loss2 = K.categorical_crossentropy(K.ones_like(y_pred)/nb_classes, y_pred)
return (1-e)*loss1 + e*loss2
model = Model(inputs=input, outputs=predict)
model.compile(optimizer='adam', loss=mycrossentropy)
- 也就是自定义一个输入为y_pred,y_true的loss函数,放进模型compile即可。这里的mycrossentropy,第一项就是普通的交叉熵,第二项中,先通过K.ones_like(y_pred)/nb_classes构造了一个均匀分布(均匀分布介绍! ),然后算y_pred与均匀分布的交叉熵。 就这么简单~
参考文章
- Keras中自定义目标函数(损失函数)的简单方法
- Keras中自定义复杂的loss函数-好的介绍!