在开发过程中,我们经常会遇到一些需要异步定期执行的批处理任务。比如夜里低峰时段的备份、统计,或者是每周、每月对数据库表进行整理,这时就需要通过使用定时任务管理器来辅助我们完成这些任务的定时触发。常见的定时任务管理器多分为三类,分别是:
①操作系统(OS)级别的定时任务管理器,例如linux的crontab、windows自带的计划任务。OS级不用专门开启监听器,占用系统资源较少,而且操作简便,是定时任务首选的实现方式,但是但是当任务数量非常大,而且任务与任务之间有因果关系、先后顺序、竞争条件的话,OS级别的定时任务管理器就很难满足需求了;
②编程语言自带的定时任务管理器,例如Java的timer和TimeTask。但是这些API提供的接口功能简单,往往不能满足用户定时任务设置需要,所以在项目开发过程中很少使用;
③第三方专门开发的定时任务管理组件,例如Java的quartz,python的celery等。这些组件往往既可以单独部署,也可以与当前的项目集成在一起统一部署管理,关键是他们有着强大的功能,能够满足我们对定时任务管理的各种需求,所以这些第三方组件往往在项目中应用广泛。本次我就重点讲一下quartz的配置实用。
一、了解quartz的体系结构
Quartz对任务调度的领域问题进行了高度的抽象,提出了调度器、作业任务和触发器这3个核心的概念,并在org.quartz通过接口和类对重要的这些核心概念进行描述:
①Job:是一个接口,只有一个方法void execute(JobExecutionContext context),开发者实现该接口定义运行任务,JobExecutionContext类提供了调度上下文的各种信息。Job运行时的信息保存在JobDataMap实例中;
②JobDetail:Quartz在每次执行Job时,都重新创建一个Job实例,但是它不直接接受一个Job的实例,相反它接收一个Job实现类,以便运行时通过newInstance()的反射机制实例化Job。因此需要通过一个类来描述Job的实现类及其它相关的静态信息,如Job名字、描述、关联监听器等信息,JobDetail承担了这一角色。
通过该类的构造函数可以更具体地了解它的功用:JobDetail(java.lang.String name, java.lang.String group, java.lang.Class jobClass),该构造函数要求指定Job的实现类,以及任务在Scheduler中的组名和Job名称;
③Trigger:是一个类,描述触发Job执行的时间触发规则。主要有SimpleTrigger和CronTrigger这两个子类。当仅需触发一次或者以固定时间间隔周期执行,SimpleTrigger是最适合的选择;而CronTrigger则可以通过Cron表达式定义出各种复杂时间规则的调度方案:如每早晨9:00执行,周一、周三、周五下午5:00执行等;
④Scheduler:代表一个Quartz的独立运行容器,Trigger和JobDetail可以注册到Scheduler中,两者在Scheduler中拥有各自的组及名称,组及名称是Scheduler查找定位容器中某一对象的依据,Trigger的组及名称必须唯一,JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的)。Scheduler定义了多个接口方法,允许外部通过组及名称访问和控制容器中Trigger和JobDetail。
Scheduler可以将Trigger绑定到某一JobDetail中,这样当Trigger触发时,对应的Job就被执行。一个Job可以对应多个Trigger,但一个Trigger只能对应一个Job。可以通过SchedulerFactory创建一个Scheduler实例。Scheduler拥有一个SchedulerContext,它类似于ServletContext,保存着Scheduler上下文信息,Job和Trigger都可以访问SchedulerContext内的信息。SchedulerContext内部通过一个Map,以键值对的方式维护这些上下文数据,SchedulerContext为保存和获取数据提供了多个put()和getXxx()的方法。可以通过Scheduler# getContext()获取对应的SchedulerContext实例;
⑤ThreadPool:Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率。
二、示例代码
1、作业任务
通过实现 org.quartz.job 接口,可以使 Java 类变成可执行的。下面的例子就提供了 Quartz 作业的一个示例。这个类用一条非常简单的输出语句覆盖了 execute(JobExecutionContext context) 方法。这个方法可以包含我们想要执行的任何代码。
import java.util.Date;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class SimpleQuartzJob implements Job {
public SimpleQuartzJob() {}
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.println("In SimpleQuartzJob - executing its JOB at "
+ new Date() + " by " + context.getTrigger().getName());
}
}
请注意,execute 方法接受一个 JobExecutionContext 对象作为参数。这个对象提供了作业实例的运行时上下文。特别地,它提供了对调度器和触发器的访问,这两者协作来启动作业以及作业的 JobDetail 对象的执行。Quartz 通过把作业的状态放在 JobDetail 对象中并让 JobDetail 构造函数启动一个作业的实例,分离了作业的执行和作业周围的状态。JobDetail 对象储存作业的侦听器、群组、数据映射、描述以及作业的其他属性。
2、简单触发器
触发器可以实现对任务执行的调度。Quartz 提供了几种不同的触发器,复杂程度各不相同。下面的例子中的 SimpleTrigger 展示了触发器的基础:
package com.cyou.quartz;
import java.util.Date;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.SchedulerFactory;
import org.quartz.SimpleTrigger;
import org.quartz.impl.StdSchedulerFactory;
public class SimpleTriggerTest {
public static void main(String[] args) throws SchedulerException {
//初始化一个Schedule工厂
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
//通过schedule工厂类获得一个Scheduler类
Scheduler scheduler = schedulerFactory.getScheduler();
//通过设置job name, job group, and executable job class初始化一个JobDetail
JobDetail jobDetail = new JobDetail("jobDetail-s1","jobDetailGroup-s1", SimpleQuartzJob.class);
//设置触发器名称和触发器所属的组名初始化一个触发器
SimpleTrigger simpleTrigger = new SimpleTrigger("simpleTrigger","triggerGroup1");
//获取当前时间,初始化触发器的开始日期
long ctime = System.currentTimeMillis();
simpleTrigger.setStartTime(new Date(ctime));
//设置触发器触发运行的时间间隔(10 seconds here)
simpleTrigger.setRepeatInterval(10000);
//设置触发器触发运行的次数,这里设置运行100,完成后推出
simpleTrigger.setRepeatCount(100);
/**
* set the ending time of this job.
* We set it for 60 seconds from its startup time here
* Even if we set its repeat count to 10,
* this will stop its process after 6 repeats as it gets it endtime by then.
* **/
// simpleTrigger.setEndTime(new Date(ctime + 60000L));
//设置触发器的优先级,模式为5
// simpleTrigger.setPriority(10);
//交给调度器调度运行JobDetail和Trigger
scheduler.scheduleJob(jobDetail, simpleTrigger);
//启动调度器
scheduler.start();
}
}
开始时实例化一个
SchedulerFactory,获得此调度器。就像前面讨论过的,创建
JobDetail 对象时,它的构造函数要接受一个
Job 作为参数。顾名思义,
SimpleTrigger 实例相当原始。在创建对象之后,设置几个基本属性以立即调度任务,然后每 10 秒重复一次,直到作业被执行100次。
还有其他许多方式可以操纵
SimpleTrigger。除了指定重复次数和重复间隔,还可以指定作业在特定日历时间执行,只需给定执行的最长时间或者优先级。执行的最长时间可以覆盖指定的重复次数,从而确保作业的运行不会超过最长时间。
3、定时触发器
CronTrigger 支持比 SimpleTrigger 更具体的调度,而且也不是很复杂。基于 cron 表达式,CronTrigger 支持类似日历的重复间隔,而不是单一的时间间隔 —— 这相对 SimpleTrigger 而言是一大改进。
import org.quartz.CronExpression;
import org.quartz.CronTrigger;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.SchedulerFactory;
import org.quartz.impl.StdSchedulerFactory;
public class CronTriggerTest {
public static void main(String[] args) throws SchedulerException{
//初始化一个Schedule工厂
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
//通过schedule工厂类获得一个Scheduler类
Scheduler scheduler = schedulerFactory.getScheduler();
//通过设置job name, job group, and executable job class初始化一个JobDetail
JobDetail jobDetail =
new JobDetail("jobDetail2", "jobDetailGroup2", SimpleQuartzJob.class);
//设置触发器名称和触发器所属的组名初始化一个定时触发器
CronTrigger cronTrigger = new CronTrigger("cronTrigger", "triggerGroup2");
try {
//设置定时器的触发规则
CronExpression cexp = new CronExpression("0/5 * * * * ?");
//注册这个定时规则到定时触发器中
cronTrigger.setCronExpression(cexp);
} catch (Exception e) {
e.printStackTrace();
}
//交给调度器调度运行JobDetail和Trigger
scheduler.scheduleJob(jobDetail, cronTrigger);
//启动调度器
scheduler.start();
}
}
备注:①Quartz使用类似于Linux下的Cron表达式定义时间规则,Cron表达式由6或7个由空格分隔的时间字段组成,如下:
| 位置 |
时间域名 |
允许值 |
允许的特殊字符 |
| 1 |
秒 |
0-59 |
, - * / |
| 2 |
分钟 |
0-59 |
, - * / |
| 3 |
小时 |
0-23 |
, - * / |
| 4 |
日期 |
1-31 |
, - * ? / L W C |
| 5 |
月份 |
1-12 |
, - * / |
| 6 |
星期 |
1-7 |
, - * ? / L C # |
| 7 |
年(可选) |
空值1970-2099 |
, - * / |
②Cron 触发器利用一系列特殊字符,如下所示:
- 反斜线(/)字符表示增量值。例如,在秒字段中“5/15”代表从第 5 秒开始,每 15 秒一次。
- 问号(?)字符和字母 L 字符只有在月内日期和周内日期字段中可用。问号表示这个字段不包含具体值。所以,如果指定月内日期,可以在周内日期字段中插入“?”,表示周内日期值无关紧要。字母 L 字符是 last 的缩写。放在月内日期字段中,表示安排在当月最后一天执行。在周内日期字段中,如果“L”单独存在,就等于“7”,否则代表当月内周内日期的最后一个实例。所以“0L”表示安排在当月的最后一个星期日执行。
- 在月内日期字段中的字母(W)字符把执行安排在最靠近指定值的工作日。把“1W”放在月内日期字段中,表示把执行安排在当月的第一个工作日内。
- 井号(#)字符为给定月份指定具体的工作日实例。把“MON#2”放在周内日期字段中,表示把任务安排在当月的第二个星期一。
- 星号(*)字符是通配字符,表示该字段可以接受任何可能的值。
三、任务调度信息存储
在默认情况下Quartz将任务调度的运行信息保存在内存中,这种方法提供了最佳的性能,因为内存中数据访问最快。不足之处是缺乏数据的持久性,当程序路途停止或系统崩溃时,所有运行的信息都会丢失。
比如我们希望安排一个执行100次的任务,如果执行到50次时系统崩溃了,系统重启时任务的执行计数器将从0开始。在大多数实际的应用中,我们往往并不需要保存任务调度的现场数据,因为很少需要规划一个指定执行次数的任务。
对于仅执行一次的任务来说,其执行条件信息本身应该是已经持久化的业务数据(如锁定到期解锁任务,解锁的时间应该是业务数据),当执行完成后,条件信息也会相应改变。当然调度现场信息不仅仅是记录运行次数,还包括调度规则、JobDataMap中的数据等等。
如果确实需要持久化任务调度信息,Quartz允许你通过调整其属性文件,将这些信息保存到数据库中。使用数据库保存任务调度信息后,即使系统崩溃后重新启动,任务的调度信息将得到恢复。如前面所说的例子,执行50次崩溃后重新运行,计数器将从51开始计数。使用了数据库保存信息的任务称为持久化任务。
四、通过配置文件调整任务调度信息的保存策略
其实Quartz JAR文件的org.quartz包下就包含了一个quartz.properties属性配置文件并提供了默认设置。如果需要调整默认配置,可以在类路径下建立一个新的quartz.properties,它将自动被Quartz加载并覆盖默认的设置。
1、先来了解一下Quartz的默认属性配置文件,默认配置如下:
①集群的配置,这里不使用集群
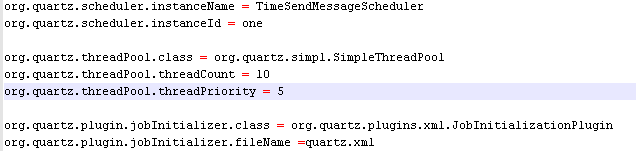
org.quartz.scheduler.instanceName = DefaultQuartzScheduler
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
②配置调度器的线程池
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 10
org.quartz.threadPool.threadPriority = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
③配置任务调度现场数据保存机制
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
Quartz的属性配置文件主要包括三方面的信息:
1)集群信息;
2)调度器线程池;
3)任务调度现场数据的保存。
如果任务数目很大时,可以通过增大线程池的大小得到更好的性能。默认情况下,Quartz采用org.quartz.simpl.RAMJobStore保存任务的现场数据,顾名思义,信息保存在RAM内存中,我们可以通过以下设置将任务调度现场数据保存到数据库中。
2、使用数据库保存任务调度现场数据配置如下:
…
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.tablePrefix = QRTZ_①数据表前缀
org.quartz.jobStore.dataSource = qzDS②数据源名称
③定义数据源的具体属性
org.quartz.dataSource.qzDS.driver = oracle.jdbc.driver.OracleDriver
org.quartz.dataSource.qzDS.URL = jdbc:oracle:thin:@localhost:1521:ora9i
org.quartz.dataSource.qzDS.user = stamen
org.quartz.dataSource.qzDS.password = abc
org.quartz.dataSource.qzDS.maxConnections = 10
要将任务调度数据保存到数据库中,就必须使用org.quartz.impl.jdbcjobstore.JobStoreTX代替原来的org.quartz.simpl.RAMJobStore并提供相应的数据库配置信息。首先①处指定了Quartz数据库表的前缀,在②处定义了一个数据源,在③处具体定义这个数据源的连接信息。
你必须事先在相应的数据库中创建Quartz的数据表(共8张),在Quartz的完整发布包的docs/dbTables目录下拥有对应不同数据库的SQL脚本。
3、查询数据库中的运行信息
任务的现场保存对于上层的Quartz程序来说是完全透明的,我们在src目录下编写一个代码(如上所示将状态保存在数据库中的quartz.properties文件后),重新运行简单触发器代码或定时触发器代码程序,在数据库表中将可以看到对应的持久化信息。当调度程序运行过程中途停止后,任务调度的现场数据将记录在数据表中,在系统重启时就可以在此基础上继续进行任务的调度。
①实例代码JDBCJobStoreRunner:从数据库中恢复任务的调度
import org.quartz.Scheduler;
import org.quartz.SchedulerFactory;
import org.quartz.SimpleTrigger;
import org.quartz.Trigger;
import org.quartz.impl.StdSchedulerFactory;
public class JDBCJobStoreRunner {
public static void main(String args[]) {
try {
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
// ①获取调度器中所有的触发器组
String[] triggerGroups = scheduler.getTriggerGroupNames();
// ②重新恢复在triggerGroup1组中,名为simpleTrigger触发器的运行
for (int i = 0; i < triggerGroups.length; i++) {
String[] triggers = scheduler.getTriggerNames(triggerGroups[i]);
for (int j = 0; j < triggers.length; j++) {
Trigger tg = scheduler.getTrigger(triggers[j],triggerGroups[i]);
// ②-1:根据名称判断
if (tg instanceof SimpleTrigger && tg.getFullName().equals("triggerGroup1.simpleTrigger")) {
// ②-2:恢复运行
scheduler.rescheduleJob(triggers[j], triggerGroups[i],tg);
}
}
}
scheduler.start();
} catch (Exception e) {
e.printStackTrace();
}
}
}
②运行 JDBCJobStore
在第一次运行示例时,触发器在数据库中初始化。图 1 显示了数据库在触发器初始化之后但尚未击发之前的情况。所以,基于【简单触发器】中的 setRepeatCount() 方法,将 REPEAT_COUNT 设为 100,而 TIMES_TRIGGERED 是 0。在应用程序运行一段时间之后,应用程序停止。
图 1. 使用 JDBCJobStore 时数据库中的数据(运行前)

图 2 显示了数据库在应用程序停止后的情况。在这个图中,TIMES_TRIGGERED 被设为 19,表示作业运行的次数。
图 2. 同一数据在 19 次迭代之后

当再次启动应用程序时,REPEAT_COUNT 被更新。这在图 3 中很明显。在图 3 中可以看到 REPEAT_COUNT 被更新为 81,所以新的 REPEAT_COUNT 等于前面的 REPEAT_COUNT 值减去前面的 TIMES_TRIGGERED 值。而且,在图 3 中还看到新的 TIMES_TRIGGERED 值是 7,表示作业从应用程序重新启动以来,又触发了 7 次。
图 3. 第 2 次运行 7 次迭代之后的数据

当再次停止应用程序之后,REPEAT_COUNT 值再次更新。如图 4 所示,应用程序已经停止,还没有重新启动。同样,REPEAT_COUNT 值更新成前一个 REPEAT_COUNT 值减去前一个 TIMES_TRIGGERED 值。
图 4. 再次运行触发器之前的初始数据

五、与Java Web集成--通过web.xml配置启动quartz
①在web.xml配置,采用servlet启动quartz(还支持Listener 方式)

②配置quartz的配置文件:quartz.properties
③配置quartz.xml,设置需要运行的job

④编写发送任务,参见作业任务SimpleQuartzJob