【MySQL数据库】笔试题总结
1.truncate、delete、drop的区别
用法:truncate 表名;delete from 表名 where...;drop table 表名;
区别:
truncate、drop是不可以rollback的,但是delete是可以rollback的;原因是:delete删除是一行一行的删除,会触发触发器,删除可以返回行数,每删除一行会进行一次日志记录,所以可回滚;而truncate删除是删除表的所有数据,通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放,所以不能回滚,可以重置自增字段的计数器;Drop语句将删除表的结构、被依赖的约束(constrain)、触发器 (trigger)、索引(index);依赖于该表的存储过程/函数将保留,但是变为invalid状态。
注意:drop、truncate不能删除有外键约束的表。
2.数据库三范式
- 第一范式(1NF):是指数据库表的每一列都是不可分割,即列不可分。
- 第二范式(2NF):非主属性必须完全依赖主键,不能部分依赖主键,即不能部分依赖。
- 第三范式(3NF):属性不依赖于其它非主属性,即不能传递依赖。
3.数据库事务四大特性ACID
- 原子性:一个事务是一个不可分割的最小工作单元,其操作要么全部成功,要么全部失败。
- 一致性:数据库总是从一个一致性状态转换为另一个一致性状态。所谓一致性状态,就是数据库的所有完整性约束(尤其注意用户定义约束)都被遵守,以银行转账为例,“转账操作必然导致一个账户减少金额,另一个账户增加金额,且这两个账户总金额之和不变”就是一个完整性约束。
- 持久性:一旦事务提交,则其所作的修改就会永久保存到数据库中。
- 隔离性:隔离性用于定义事务之间的相互隔离程度,存在四个隔离级别。

首先需要解释一下几个跟隔离性相关的概念定义:
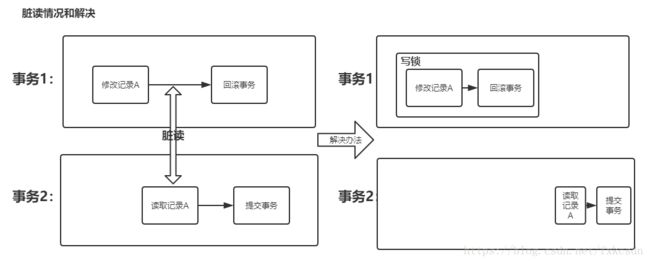
(1)脏读:指事务读到脏数据,所谓脏数据,指的是不正确的数据,例如事务执行过程中修改了某记录,然后回滚,如果其他事务读到了该记录的中间修改值,则为脏读。
(2)不可重复读:事务在执行过程中,多次对同一个已经存在的记录进行读取,各次读取的值不同。读提交隔离级别存在不可重复读的问题,事务1、2并发执行,事务2首先读取记录1,然后事务1修改记录1并提交,事务2继续读取记录1,则事务2两次读取到的值不同。
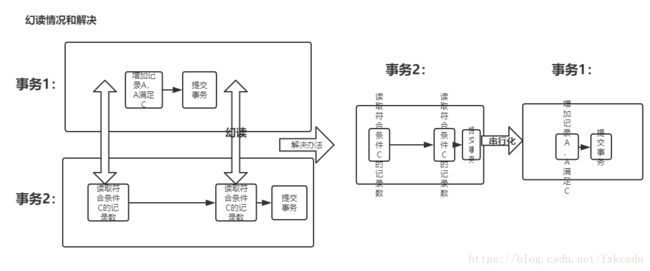
(3)幻读:幻读是指使用某个条件读取一批记录时,可能读到的记录数不同。幻读与脏读、不可重复读的区别在于,脏读、不可重复读都是针对某个确定的已经存在的记录出现的值不要求(读到脏数据或多次读的值不同),而幻读则是多次使用同一个条件查询一批记录,多次读到的记录数不同,也就是说,脏读、不可重复读是由于多个事务并行执行update引起的,而幻读则是由于多个事务并行执行insert引起的(并发delete引起的问题看起来算哪个都行……)。
四个隔离级别
(1)Read Uncommited:读未提交,其含义为多个并发事务,任何一个事务可以读到其他事务尚未提交的修改:
存在脏读、不可重复读、幻读可能性。
(2)Read Commited:读已提交,含义为多个并发事务,任何一个事务只可以读到其他事务已经提交的修改:
解决脏读,存在不可重复读、幻读可能性。
(3)Repeatable Read:可重复读,含义为多个事务并发执行时,任何一个事务反复读取已存在的记录,每次读到的值都是相同的
解决脏读、不可重复读,存在幻读可能性。
(4)Serializable:串行化,含义为所有事务串行执行,因此不存在事务并发执行的情况。
解决脏读、不可重复读、幻读。

多版本并发控制MVCC
上述四个隔离级别中,读未提交隔离性最差,且相对于读已提交,性能并没有多少提升,几乎不会使用;串行化隔离性最好,可是性能太差,也几乎不会使用。一般数据库的默认隔离级别要么是读已提交,要么是可重复读(例如MySQL的InnoDB引擎),要么是读已提交(例如Oracle )。
如果使用行级读锁、写锁来实现读已提交或可重复读,应当是以下的步骤:
1、事务1会修改行1,则会在行1加上写锁,开始事务;
2、事务2为纯读取操作,需要读取行1,试图在行1上加上读锁,由于事务1已加写锁,因此事务2等待直到事务1完成。
3、如果事务2先开始,则事务1也需要等到事务2完成并释放读锁后才可以开始执行。
也即使说,对某行的写操作会阻塞所有对该行的读取操作,对某行的读操作会阻塞所有对该行的写操作,在系统存在读、写并发时,不论系统IO能力有多高,会受限于锁而导致性能低下。
MVCC用于解决这个问题来提高系统性能,MVCC并没有统一的标准,各个数据库实现均采用不同方式来实现MVCC,InnoDB的实现方式如下:
准备工作:
(1)对每行记录增加行标志和删除标志两个字段;
(2)维护一个全局的系统版本号,每开始一个事务(注意select也是事务,读事务),将该系统版本号加1并作为事务的版本号
插入记录的行标志设置为本事务版本号,删除标志为空;
删除记录的删除标志设置为本事务版本号;
修改的处理过程:将原记录的删除版本号修改为本事务版本号;新插入一条记录,包含原记录数据及本次修改,行记录标志设置为本事务版本号,删除标志为空;
读取的处理过程:
仅读取同时满足以下条件的记录行:
(1)行标志小于或等于本事务版本号(等于用于保证能够读取到本事务内提交的增加);
(2)删除标志为空或者大于本事务版本号(不包括等于以保证不会读取到本事务删除的记录);
相当于在读事务开始的时刻点,建立了一个系统的快照,该事务读取的所有数据,均是从快照中读取的,因此满足可重复读的条件,并且可解决幻读的问题,并且也不会读到产生“同样查询条件,事务中第一次读到的记录数大于第二次读到的记录数的问题“(由并发删除引起)
从上可知,使用MVCC后,大部分读都不再需要加读锁,因此读不再阻塞写,写也不再阻塞读。读操作只再受限于系统IO能力。
MySQL中myisam与innodb的区别
- InnoDB支持事务,而MyISAM不支持事务
- InnoDB支持行级锁,而MyISAM支持表级锁
- InnoDB支持MVCC, 而MyISAM不支持
- InnoDB支持外键,而MyISAM不支持
- InnoDB不支持全文索引,而MyISAM支持。
InnoDB提供提交、回滚、崩溃恢复能力的事务安全(ASID)能力,实现并发控制。
MyISAM提供较高的插入和查询记录的效率,主要用于插入和查询。
memory用于临时存放数据,数据量不大并且不需要较高数据安全性。
archive:如果只有插入和查询可以用,支持高并发的插入操作,但本身不是事务安全。
2者select count(*)哪个更快,为什么
MyISAM更快,因为MyISAM内部维护了一个计数器,可以直接调取。
mysql中四个存储引擎
innodb、myisam、memory、archive
MySQL语句总结:
查询语句:select* from 表名;
插入数据:insert into 表名 (clus...) values(values...);
更新语句:update 表名 set clu=value where 条件;
删除语句:delete from 表名 where..;truncate 表名;drop table 表名;
存储过程:存储过程体中可以使用自定义函数(UDF)中使用的复合结构/流程控制/SQL语句/自定义变量等等内容
CREATE procedure sp_add(a int, b int,out c int)
begin
DELETE FROM son WHERE id = a;
end函数定义:
CREATE FUNCTION 函数名称(参数列表)
RETURNS 返回值类型
BEGIN
DELETE FROM son WHERE id = uid;
RETURN (SELECT COUNT(id) FROM son);
END存储过程与函数区别
- 存储过程实现的过程要复杂一些,而函数的针对性较强;
- 存储过程可以有多个返回值,而自定义函数只有一个返回值;
- 存储过程一般独立的来执行,而函数往往是作为其他SQL语句的一部分来使用;
存储过程说白了就是把经常使用的SQL语句或业务逻辑封装起来,预编译保存在数据库中,当需要的时候从数据库中直接调用,省去了编译的过程. 提高了运行速度;同时降低网络数据传输量(你觉得传一堆SQL代码快,还是传一个存储过程名字和几个参数快???),在程序端可以直接调用存储过程,而函数不能独立运行。
外连接分为内连接、左连接、右连接
内连接是根据某个条件连接两个表共有的数据所有字段;
左连接是根据某个条件以及左边的表连接数据,右边的表没数据的话则填null;
右连接是根据某个条件以及右边的表连接数据,左边的表没数据的话则填null;
例如,有两个表学生表student和成绩表grade,如图
学生表 成绩表
成绩表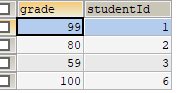
内连接也就是等值连接:SELECT * FROM student , grade WHERE student.`id`=grade.`studentId`;

左连接:SELECT * FROM student LEFT JOIN grade ON student.`id`=grade.`studentId`;
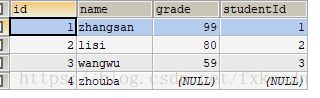
右连接:SELECT * FROM student RIGHT JOIN grade ON student.`id`=grade.`studentId`;
