几种推荐搜索场景下的用户Embedding策略
所谓Embedding策略,就是用一个向量来描述一个实体的思想,这种思想用向量来描述实体信息,不仅仅包含了实体本身的属性信息,同时还包含了实体之间的关联信息,以及实体和最终目标任务之间的关联信息。
这种方法最早其实是运用在NLP领域—词向量就是很好的例子,但是随着深度学习在其他各个领域(尤其是搜索/推荐/广告)的应用,衍生出了各种各样的变种,目前成为了深度学习应用到各个领域之中的标准方法。下面就来讲解几篇使用Embedding策略在各种任务场景中提取用户信息的paper。
今天讲解的第一篇paper是2015年在WWW会议上发表的论文《Modeling User Activities on the Web using Paragraph Vector》。这个paragraph vector就是NLP领域中的一个模型,他相对于把这个模型拿过来应用到了Web 领域,用来提取的是用户的Embedding信息,整个问题场景描述如下:
用户在浏览网页的时候会留下来一系列的行为,比方说网页浏览,搜索问题,点击广告等,设用户 i i i留下的 T T T个行为表示为 ( a i , 1 , a i , 2 . . . . , a i , T i ) (a_{i,1},a_{i,2}....,a_{i,T_i}) (ai,1,ai,2....,ai,Ti)。我们希望根据所有的用户行为数据,生成表征每一个用户的向量,使具有相同行为序列的用户被映射到相似的向量空间之中。
该论文借鉴了skip-gram 的思想,公式如下:
p ( a i , t ∣ a i , t − 1 , . . . a i , t − s , u i ) = e x p ( w a i , t . v T ) / ∑ a ∈ A e x p ( w a . v I ) p(a_{i,t}|a_{i,t-1},...a_{i,t-s},u_i)=exp(w_{a_{i,t}}.v_{T})/\sum_{a \in A}exp(w_{a}.v_I) p(ai,t∣ai,t−1,...ai,t−s,ui)=exp(wai,t.vT)/∑a∈Aexp(wa.vI)
其中 v I = C o n c a t ( a i , t − 1 , . . . a i , t − s , u i ) v_{I}=Concat(a_{i,t-1},...a_{i,t-s},u_i) vI=Concat(ai,t−1,...ai,t−s,ui)。由于采用该方式会导致计算量过大,故会采用负采样技术,最终的优化的损失函数如下:
L = l o g σ ( w a , i , t , v I ) + k ∗ E a n [ l o g σ ( − w a n v I ) ] L=log \sigma (w_{a,{i,t}},v_I)+k*E_{a_n}[log \sigma(-w_{a_n}v_I)] L=logσ(wa,i,t,vI)+k∗Ean[logσ(−wanvI)]
最终采用的是AdaGrad进行模型的训练,最终就能得到表征每个用户属性的向量 u i u_i ui,该向量可以运用在很多后续的任务之中。
今天讲解的第二篇paper是2015年发表的论文《Metadata Embeddings for User and Item Cold-start Recommendations》。其实这篇paper本身的模型非常简单就是对经典的FM做了小小的改动,但是其用到的思想是非常有启发意义的。FM在描述实体交互上采用了向量内积的方式,即使用向量来描述实体属性,使用向量的内积操作来表达实体之间的特征交互。但是对于一些冷启动的场景下确是不太适合,比方说有些用户或者item是新加入的,对于他们的Embedding就很难生成了。这里作者巧妙的提出了feature Embedding的概念,即用户的Embedding是由其对应的feature Embedding相加得到的,对于商品的Embedding来说也是相同的处理思想,如下述公式所示:
q u = ∑ j ∈ f u e j U q_u=\sum_{j \in f_u}e_j^U qu=∑j∈fuejU
p i = ∑ j ∈ f i e j I p_i=\sum_{j \in f_i}e_j^I pi=∑j∈fiejI
今天讲解的第三篇paper是2018年在KDD会议上发表的论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb》,这是Airbnb针对其名宿租赁场景提出的一个模型,目标是对user和host listing进行Embedding,从而完成host listing的相似度匹配工作。
从本质上来说,这篇paper提出的几个idea都是对skip-gram模型进行微小的修改,从而适配Airbnb适用的目标场景。
listing Embedding
首先我来介绍一下listing Embedding的应用场景,假设集合 S S S包含了N个用户的click session行为信息,每一个click session S = ( l 1 , l 2 , . . . l M ) S=(l_1,l_2,...l_M) S=(l1,l2,...lM)其实是由 M M M个listing id组成的。由于每一个用户点击行为会非常多,这些listing id的长度会很长,为了分段这些记录,使用30min为间隔进行分段,即同一个用户两个click行为之间的间隔在30min以上的就认为是2个session。
从描述中不难看出,每一个session就相当于一个句子,每一个listing 就相对于句子中的每一个词语,直接套用原始的skip-gram就可以生成每一个listing的Embedding形式的向量,skit-gram + negative sampling公式如下:
L = − ∑ ( l , c ) ∈ D p l o g 1 1 + e − v c v l − ∑ ( l , c ) ∈ D n l o g 1 1 + e v c v l L=-\sum_{(l,c)\in D_p} log \frac{1}{1+e^{-v_cv_l}}-\sum_{(l,c)\in D_n} log \frac{1}{1+e^{v_cv_l}} L=−∑(l,c)∈Dplog1+e−vcvl1−∑(l,c)∈Dnlog1+evcvl1
当然这是最基本的模型,如果只有这个,这篇paper是不会被kdd录用的。接下来,作者通过进一步分析每一个session,他发现所有的session可以分为2中类型:1 成功转化的session,即在一系列的click行为之后,以成功的预订行为作为session的结尾;2 浏览性的session,即在一系列的click行为之后,并没有以成功的预订行为结束的session。作者通过这一点,对原始的skip-gram模型进行了修改,主要针对的是那些成功转换的session,如下图所示:
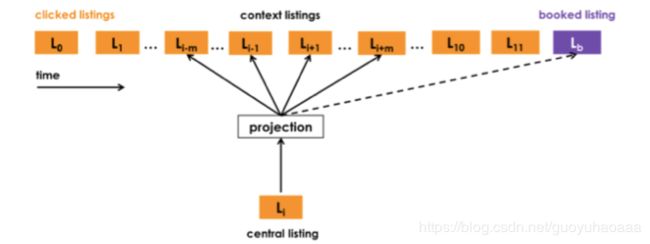
即把每一个session中成功预订的listing作为整个session中所有其他listing的context,整个损失函数如下所示:
L = − ∑ ( l , c ) ∈ D p l o g 1 1 + e − v c v l − ∑ ( l , c ) ∈ D n l o g 1 1 + e v c v l − ∑ l o g 1 1 + e v l b v l L=-\sum_{(l,c)\in D_p} log \frac{1}{1+e^{-v_cv_l}}-\sum_{(l,c)\in D_n} log \frac{1}{1+e^{v_cv_l}}-\sum log \frac{1}{1+e^{v_{l_b}v_l}} L=−∑(l,c)∈Dplog1+e−vcvl1−∑(l,c)∈Dnlog1+evcvl1−∑log1+evlbvl1
user-type 和 listing-type Embedding
这里不是针对每一个user进行Embedding处理,而是针对每一类人进行Embedding,这种方式对于样本的sparse现象和提高模型的general性有着很好的帮助。至于具体如何根据合理正确地针对user和listing划分出合适的类别,这就和具体目标的业务场景息息相关(即和用户画像关系密切)。接下来,作者在skip-gram模型框架下一次性的生成user-type Embedding和listing-type Embedding两种方式,如下图所示
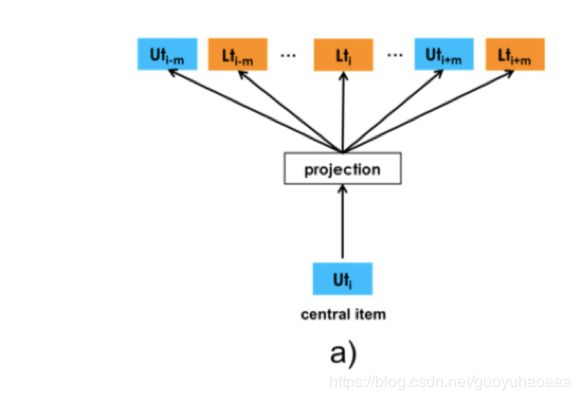
即把上部分中的 S = ( l 1 , l 2 , . . . l M ) S=(l_1,l_2,...l_M) S=(l1,l2,...lM)扩展成tuple的形式即 S = ( ( l 1 , u 1 ) , ( l 2 , u 2 ) , . . . ( l M , u M ) ) S=((l_1,u_1),(l_2,u_2),...(l_M,u_M)) S=((l1,u1),(l2,u2),...(lM,uM)),假设当前的context 是 u i u_i ui,那么它的上下文除了窗口内的其他用户Embedding还有其他的listing Embedding;同时如果当前的context是 l i l_i li,是一样的方式。最后作者还做了一些改动,因为在Airbnb的具体业务场景下,当用户选择了预订一个民宿之后,民宿的host是有权力拒绝的(可能该用户的个人资料不完备),如果拒绝的话,这个listing将作为一个负样本加入到上述的损失函数之中。
今天讲解的第四篇paper是2018年在KDD会议上发表的论文《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》,这是淘宝用在首页推荐场景下使用的模型。这里不得不讲一下淘宝的推荐策略,当一个用户访问淘宝的网站时,整个电商系统都发生了什么:1 根据访问用户id从后台数据库调出其在最近一段时间内(一般2周)的所有淘宝网访问购买点击记录;2 首先根据一个弱的算法从所有的商品总集中筛选出一个范围相对较小的商品集合,这个弱的算法也叫做匹配算法;3 根据一个性能较好的分类模型对范围较小的商品集合中的商品按照用户点击率的大小进行排序,并提取较高点击率的商品推荐给用户,这个强的算法也叫做排序算法;4 记录用户的点击行为,作为以后的训练标注数据。
在该篇论文中作者提出的模型就是作用在匹配算法阶段,针对每一个item即商品生成一个Embedding,用来计算item之间的相似度,从而找出历史上和用户交互过的相似商品作为匹配算法生成的候选集合,接下来再交给排序算法使用。这篇文章使用了graph Embedding方法中的Deep Walk算法作为基础对目标商品进行建模。
既然是基于Graph Embedding的,那就肯定要有图,那么淘宝用的图是如何构造出来的呢?其实淘宝拥有的只是一系列用户点击商品的id序列,如下图所示:
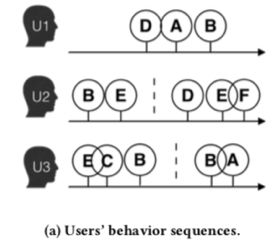
作者认为每一个被点击的商品就是图中的每一个点,任意两个相邻被点击的商品,比方说对于用户 u 1 u_1 u1来说就是D和A,A和B来说他们之间就会有一条边,同时每一条边都是包含权值的,点的权值就是两个点的共现次数,最终形成的Graph如下图所示:
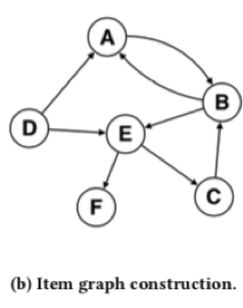
接着在下图中使用随机游走算法生成一系列的商品序列,如下所示:

然后运用skip-gram算法生成每个商品的Embedding的向量表征形式。
如果仅仅是这样,这篇paper是无法发kdd的,该篇paper文章也提出了feature Embedding的概念,也是为了应对cold start的问题,在paper中作者称这些信息为side information,那么Graph中每一个节点的Embedding形式变为:
H v = 1 n + 1 ∑ s = 0 n W v s H_v=\frac{1}{n+1}\sum_{s=0}^nW_v^s Hv=n+11∑s=0nWvs
其中 W v 0 W_v^0 Wv0表示原始的item的向量形式, W v 1 . . W v n W_v^1..W_v^n Wv1..Wvn则代表item对应的feature的向量形式。显然,直接加权求平均的方式是不太合理的,因为对于不同种类的item来说,其对应的feature的重要性程度也是不一样的,如果直接求平均,就会损失这部分信息,故作者又引入了权值矩阵 A ∈ R ∣ V ∣ ∗ ( n + 1 ) A \in R^{|V|*(n+1)} A∈R∣V∣∗(n+1),也就是说每一个item对应的每一个feature的重要性都是不一样的,这个权值矩阵作为模型参数的一部分,随着模型一起训练,那么在这种情况下,Graph中的每一个节点的Embedding形式则变为:
H v = ∑ j = 0 n e a v j W v j / ∑ j = 0 n e a v j H_v=\sum_{j=0}^n e^{a_v^j}W_v^j/\sum_{j=0}^ne^{a_v^j} Hv=∑j=0neavjWvj/∑j=0neavj
从上述几篇paper可以发现,feature Embedding确实是一个比较好的解决cold start的方法,以后这个思想可以好好借鉴一下。