为什么AI工程师要懂一点架构?
为什么AI工程师要懂一点架构?
AI 时代,我们总说做科研的 AI 科学家、研究员、算法工程师离产业应用太远,这其中的一个含义是说,搞机器学习算法的人,有时候会因为缺乏架构(Infrastructure)方面的知识、能力而难以将一个好的算法落地。我们招的算法工程师里,也有同学说,我发的顶会 paper 一级棒,或者我做 Kaggle 竞赛一级棒,拿了不少第一名的,不懂架构就不懂呗,我做出一流算法,自然有其他工程师帮我上线、运行、维护的。
鉴于此,我给创新工场暑期深度学习训练营 DeeCamp (ps:这个训练营太火了,只招生 36 名,总共有 1000 多计算机专业同学报名,同学们来自 CMU、北大、清华、交大等最好的大学)设计培训课程时,就刻意把第一节课安排为《AI 基础架构:从大数据到深度学习》,后续才给大家讲《TensorFlow 实战》、《自然语言处理》、《机器视觉》、《无人驾驶实战》等框架和算法方向的课。
为什么我要说,AI 工程师都要懂一点架构呢?大概有四个原因吧:
原因一:算法实现 ≠ 问题解决
学生、研究员、科学家关心的大多是学术和实验性问题,但进入产业界,工程师关心的就是具体的业务问题。简单来说,AI 工程师扮演的角色是一个问题的解决者,你的最重要任务是在实际环境中、有资源限制的条件下,用最有效的方法解决问题。只给出结果特别好的算法,是远远不够的。
比如一些算法做得特别好,得过 ACM 奖项或者 Kaggle 前几名的学生到了产业界,会惊奇地发现,原来自己的动手能力还差得这么远。做深度学习的,不会装显卡驱动,不会修复 CUDA 安装错误;搞机器视觉的,没能力对网上爬来的大规模训练图片、视频做预处理或者格式转换;精通自然语言处理的,不知道该怎么把自己的语言模型集成在手机聊天 APP 里供大家试用……
当然可以说,做算法的专注做算法,其他做架构、应用的帮算法工程师做封装、发布和维护工作。但这里的问题不仅仅是分工这么简单,如果算法工程师完全不懂架构,其实,他根本上就很难在一个团队里协同工作,很难理解架构、应用层面对自己的算法所提出的需求。
原因二:问题解决 ≠ 现场问题解决
有的算法工程师疏于考虑自己的算法在实际环境中的部署和维护问题,这个是很让人头疼的一件事。面向 C 端用户的解决方案,部署的时候要考虑 serving 系统的架构,考虑自己算法所占用的资源、运行的效率、如何升级等实际问题;面向 B 端用户的解决方案要考虑的因素就更多,因为客户的现场环境,哪怕是客户的私有云环境,都会对你的解决方案有具体的接口、格式、操作系统、依赖关系等需求。
有人用 Python 3 做了算法,没法在客户的 Python 2 的环境中做测试;有人的算法只支持特定格式的数据输入,到了客户现场,还得手忙脚乱地写数据格式转换器、适配器;有人做了支持实时更新、自动迭代的机器学习模型,放到客户现场,却发现实时接收 feature 的接口与逻辑,跟客户内部的大数据流程根本不相容……
部署和维护工程师会负责这些麻烦事,但算法工程师如果完全不懂得或不考虑这些逻辑,那只会让团队内部合作越来越累。
原因三:工程师需要最快、最好、最有可扩展性地解决问题
AI 工程师的首要目的是解决问题,而不是显摆算法有多先进。很多情况下,AI 工程师起码要了解一个算法跑在实际环境中的时候,有哪些可能影响算法效率、可用性、可扩展性的因素。
比如做机器视觉的都应该了解,一个包含大量小图片(比如每个图片 4KB,一共 1000 万张图片)的数据集,用传统文件形式放在硬盘上是个怎样的麻烦事,有哪些更高效的可替代存储方案。做深度学习的有时候也必须了解 CPU 和 GPU 的连接关系,CPU/GPU 缓存和内存的调度方式,等等,否则多半会在系统性能上碰钉子。
扩展性是另一个大问题,用 AI 算法解决一个具体问题是一回事,用 AI 算法实现一个可扩展的解决方案是另一回事。要解决未来可能出现的一大类相似问题,或者把问题的边界扩展到更大的数据量、更多的应用领域,这就要求 AI 工程师具备最基本的架构知识,在设计算法时,照顾到架构方面的需求了。
原因四:架构知识,是工程师进行高效团队协作的共同语言
AI 工程师的确可以在工作时专注于算法,但不能不懂点儿架构,否则,你跟其他工程师该如何协同工作呢?
别人在 Hadoop 里搭好了 MapReduce 流程,你在其中用 AI 算法解决了一个具体步骤的数据处理问题(比如做了一次 entity 抽取),这时其他工程师里让你在算法内部输出一个他们需要监控的 counter——不懂 MapReduce 的话,你总得先去翻查、理解什么是 counter 吧。这个例子是芝麻大点儿的小事,但小麻烦是会日积月累,慢慢成为团队协作的障碍的。往大一点儿说,系统内部到底该用 protocol buffers 还是该用 JSON 来交换数据,到底该用 RPC 还是该用 message queue 来通信,这些决定,AI 工程师真的都逆来顺受、不发表意见了?
Google 的逆天架构能力是 Google AI 科技强大的重要原因
这个不用多解释,大家都知道。几个现成的例子:
(1)在前 AI 时代,做出 MapReduce 等大神级架构的 Jeff Dean(其实严格说,应该是以 Jeff Dean 为代表的 Google 基础架构团队),也是现在 AI 时代里的大神级架构 TensorFlow 的开发者。
(2)在 Google 做无人驾驶这类前沿 AI 研发,工程师的幸福感要比其他厂的工程师高至少一个数量级。比如做无人驾驶的团队,轻易就可以用已有的大数据架构,管理超海量的 raw data,也可以很简单的在现有架构上用几千台、上万台机器快速完成一个代码更新在所有已收集的路况数据上的回归测试。离开这些基础架构的支持,Google 这几年向 AI 的全面转型哪会有这么快。
课件分享:AI 基础架构——从大数据到深度学习
下面是我给创新工场暑期深度学习训练营 DeeCamp 讲的时长两小时的内部培训课程《AI 基础架构:从大数据到深度学习》的全部课件。全部讲解内容过于细致、冗长,这里就不分享了。对每页课件,我在下面只做一个简单的文字概括。
注:以下这个课件的讲解思路主要是用 Google 的架构发展经验,对大数据到机器学习再到近年来的深度学习相关的典型系统架构,做一个原理和发展方向上的梳理。因为时间关系,这个课件和讲解比较偏重 offline 的大数据和机器学习流程,对 online serving 的架构讨论较少——这当然不代表 online serving 不重要,只是必须有所取舍而已。

这个 slides 是最近三四年的时间里,逐渐更新、逐渐补充形成的。最早是英文讲的,所以后续补充的内容就都是英文的(英文水平有限,错漏难免)。

如何认识 AI 基础架构的问题,直到现在,还是一个见仁见智的领域。这里提的,主要是个人的理解和经验,不代表任何学术流派或主流观点。
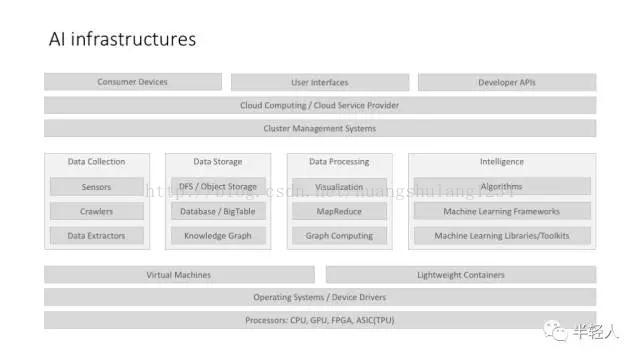
上面这个图,不是说所有 AI 系统/应用都有这样的 full stack,而是说,当我们考虑 AI 基础架构的时候,我们应该考虑哪些因素。而且,更重要的一点,上面这个架构图,是把大数据架构,和机器学习架构结合在一起来讨论的。
架构图的上层,比较强调云服务的架构,这个主要是因为,目前的 AI 应用有很大一部分是面向 B 端用户的,这里涉及到私有云的部署、企业云的部署等云计算相关方案。
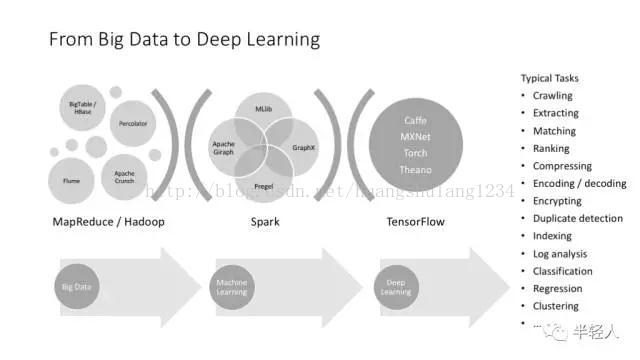
上面这个图把机器学习和深度学习并列,这在概念上不太好,因为深度学习是机器学习的一部分,但从实践上讲,又只好这样,因为深度学习已经枝繁叶茂,不得不单提出来介绍了。

先从虚拟化讲起,这个是大数据、AI 甚至所有架构的基础(当然不是说所有应用都需要虚拟化,而是说虚拟化目前已经太普遍了)。
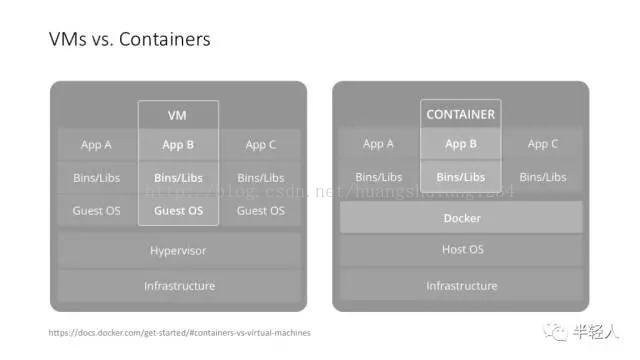
这个是 Docker 自己画的 VM vs. Container 的图。我跟 DeeCamp 学员讲这一页的时候,是先从 Linux 的 chroot 命令开始讲起的,然后才讲到轻量级的 container 和重量级的 VM,讲到应用隔离、接口隔离、系统隔离、资源隔离等概念。
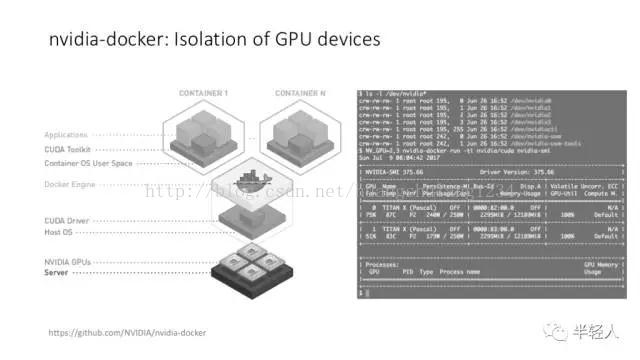
给 DeeCamp 学员展示了一下 docker(严格说是 nvidia-docker)在管理 GPU 资源上的灵活度,在搭建、运行和维护 TensorFlow 环境时为什么比裸的系统方便。
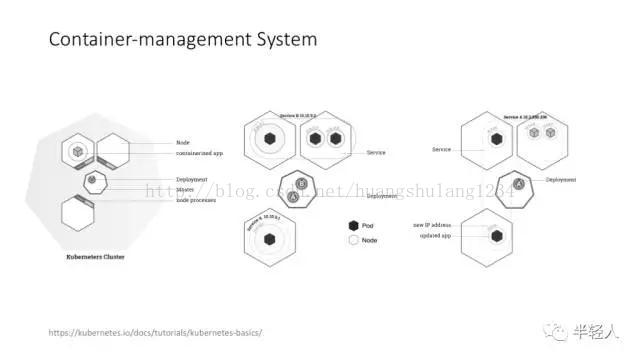
严格说,Kubernetes 现在的应用远没有 Docker 那么普及,但很多做机器学习、深度学习的公司,包括创业公司,都比较需要类似的 container-management system,需要自动化的集群管理、任务管理和资源调度。Kubernetes 的设计理念其实代表了 Google 在容器管理、集群管理、任务管理方面的整体思路,特别推荐这个讲背景的文章:http://queue.acm.org/detail.cfm?id=2898444

讲大数据架构,我基本上会从 Google 的三架马车(MapReduce、GFS、Bigtable)讲起,尽管这三架马车现在看来都是“老”技术了,但理解这三架马车背后的设计理念,是更好理解所有“现代”架构的一个基础。

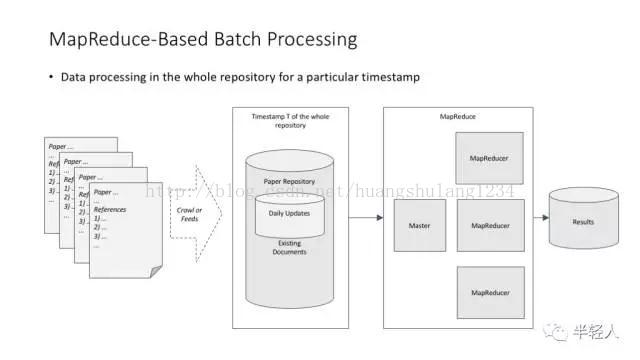
讲 MapReduce 理念特别常用的一个例子,论文引用计数(正向计数和反向计数)问题。

统计一篇论文有多少参考文献,这个超级简单的计算问题在分布式环境中带来两个思考:(1)可以在不用考虑结果一致性的情况下做简单的分布式处理;(2)可以非常快地用增量方式处理数据。
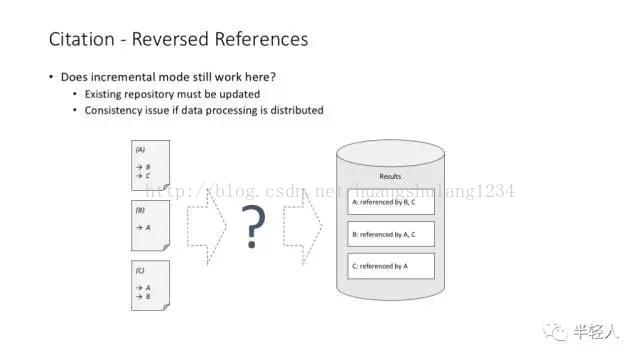
但是,当我们统计一篇文献被多少篇论文引用的时候,这个事情就不那么简单了。这主要带来了一个分布式任务中常见的数据访问一致性问题(我们说的当然不是单线程环境如何解决这个问题啦)。

很久以前我们是用关系型数据库来解决数据访问一致性的问题的,关系型数据库提供的 Transaction 机制在分布式环境中,可以很方便地满足 ACID(Atomicity, Consistency, Isolation, Durability) 的要求。但是,关系型数据库明显不适合解决大规模数据的分布式计算问题。
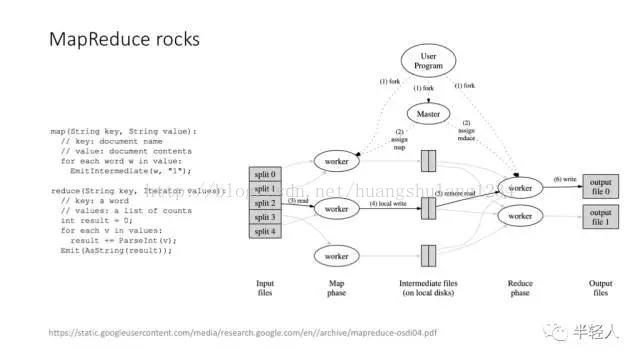
Google 的 MapReduce 解决这个问题的思路非常巧妙,是计算机架构设计历史上绝对的经典案例:MapReduce 把一个可能带来 ACID 困扰的事务计算问题,拆解成 Map 和 Reduce 两个计算阶段,每个单独的计算阶段,都特别适合做分布式处理,而且特别适合做大规模的分布式处理。
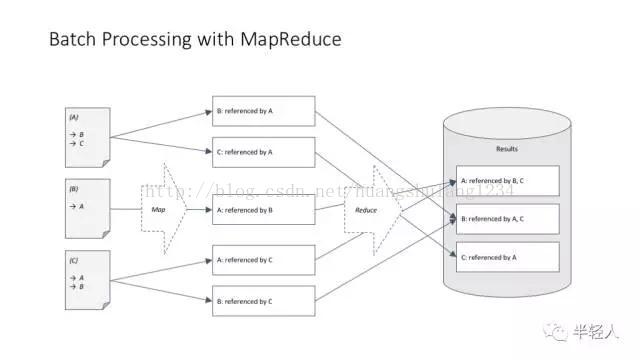
MapReduce 解决引用计数问题的基本框架。
MapReduce 在完美解决分布式计算的同时,其实也带来了一个不大不小的副作用:MapReduce 最适合对数据进行批量处理,而不是那么适合对数据进行增量处理。比如早期 Google 在维护网页索引这件事上,就必须批量处理网页数据,这必然造成一次批量处理的耗时较长。Google 早期的解决方案是把网页按更新频度分成不同的库,每个库使用不同的批量处理周期。

用 MapReduce 带来的另一个问题是,常见的系统性问题,往往是由一大堆 MapReduce 操作链接而成的,这种链接关系往往形成了复杂的工作流,整个工作流的运行周期长,管理维护成本高,关键路径上的一个任务失败就有可能要求整个工作流重新启动。不过这也是 Google 内部大数据处理的典型流程、常见场景。

Flume 是简化 MapReduce 复杂流程开发、管理和维护的一个好东东。

Apache 有开源版本的 Flume 实现。Flume 把复杂的 Mapper、Reducer 等底层操作,抽象成上层的、比较纯粹的数据模型的操作。PCollection、PTable 这种抽象层,还有基于这些抽象层的相关操作,是大数据处理流程进化道路上的重要一步(在这个角度上,Flume 的思想与 TensorFlow 对于 tensor 以及 tensor 数据流的封装,有异曲同工的地方)。
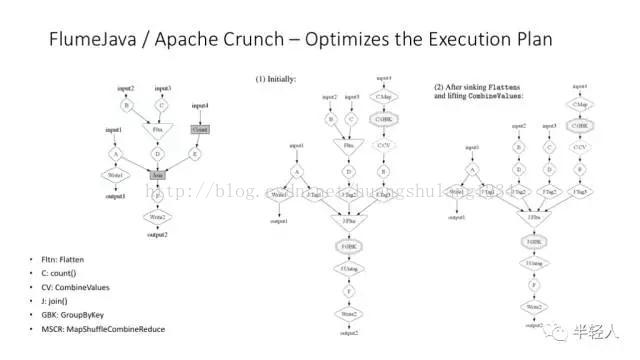
Flume 更重要的功能是可以对 MapReduce 工作流程进行运行时的优化。
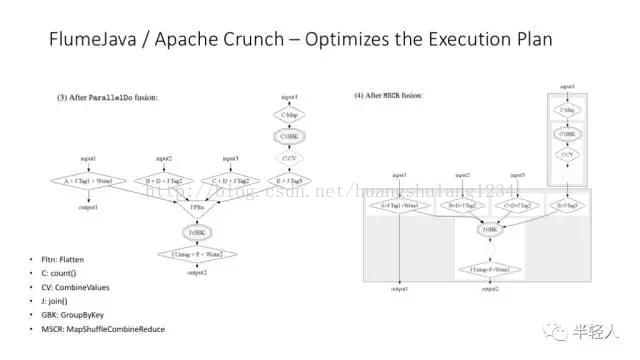
更多关于 Flume 运行时优化的解释图。

Flume 并没有改变 MapReduce 最适合于批处理任务的本质。那么,有没有适合大规模数据增量(甚至实时)处理的基础架构呢?
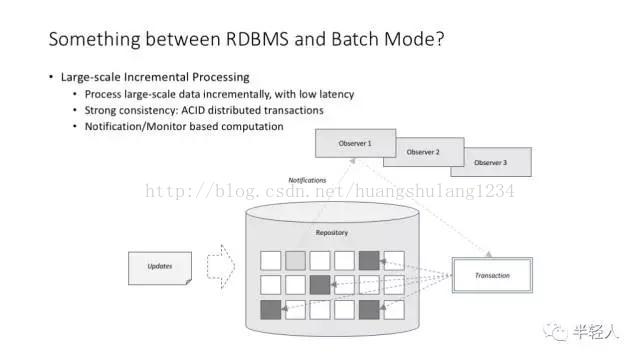
谈到大规模数据增量(甚至实时)处理,我们谈的其实是一个兼具关系型数据库的 transaction 机制,以及 MapReduce 的可扩展性的东西。这样的东西有不同的设计思路,其中一种架构设计思路叫 notification/monitor 模式。
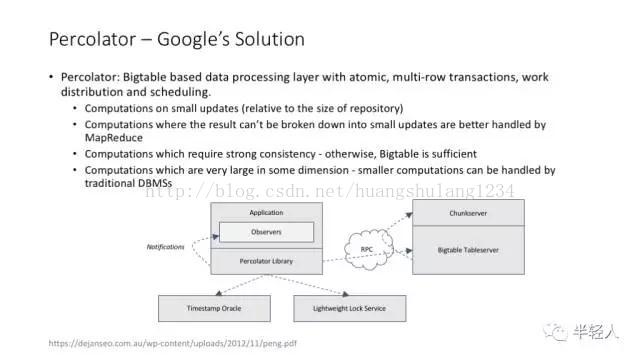
Google percolator 的论文给出了 notification/monitor 模式的一种实现方案。这个方案基于Bigtable,实际上就是在 Bigtable 超靠谱的可扩展性的基础上,增加了一种非常巧妙实现的跨记录的 transaction 机制。

percolator 支持类似关系型数据库的 transaction,可以保证同时发生的分布式任务在数据访问和结果产出时的一致性。
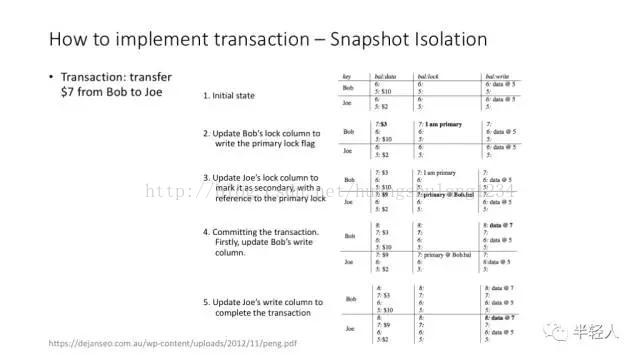
percolator 实现 transaction 的方法:(1)使用 timestamp 隔离不同时间点的操作;(2)使用 write、lock 列实现 transaction 中的锁功能。详细的介绍可以参考 percolator 的 paper。
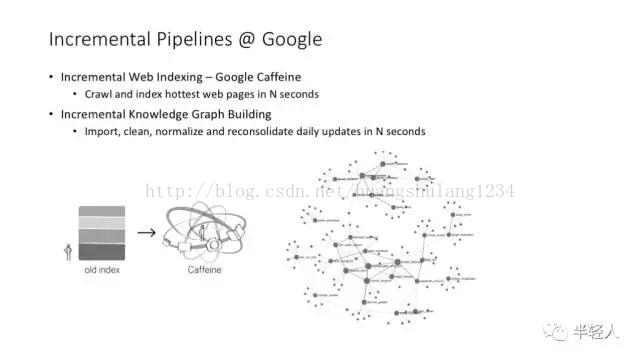
Google 的网页索引流程、Google Knowledge Graph 的创建与更新流程,都已经完成了增量化处理的改造,与以前的批处理系统相比,可以达到非常快(甚至近乎实时)的更新速度。——这个事情发生在几年以前,目前 Google 还在持续对这样的大数据流程进行改造,各种新的大数据处理技术还在不停出现。

大数据流程建立了之后,很自然地就会出现机器学习的需求,需要适应机器学习的系统架构。

MapReduce 这种适合批处理流程的系统,通常并不适合于许多复杂的机器学习任务,比如用 MapReduce 来做图的算法,特别是需要多次迭代的算法,就特别耗时、费力。
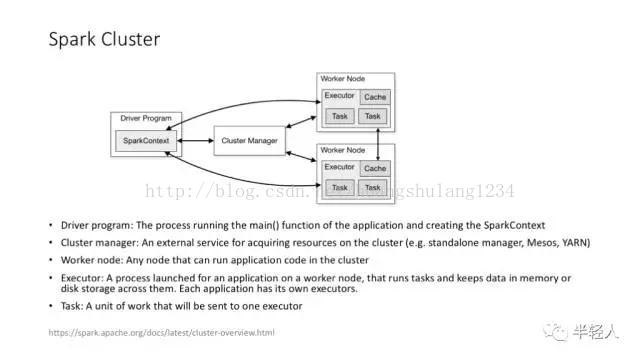
Spark 以及 Spark MLlib 给机器学习提供了更好用的支持框架。Spark 的优势在于支持对 RDD 的高效、多次访问,这几乎是给那些需要多次迭代的机器学习算法量身定做的。
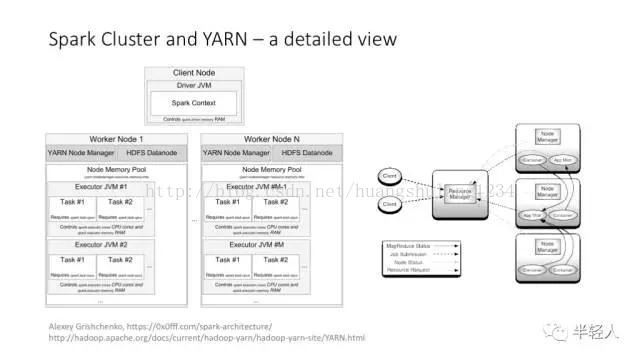
Spark 的集群架构,和 YARN 的集成等。

Google Pregel 的 paper 给出了一种高效完成图计算的思路。
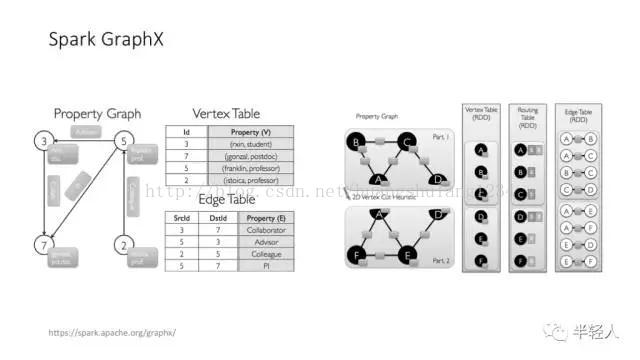
Spark GraphX 也是图计算的好用架构。

深度学习的分布式架构,其实是与大数据的分布式架构一脉相承的。——其实在 Google,Jeff Dean 和他的架构团队,在设计 TensorFlow 的架构时,就在大量使用以往在 MapReduce、Bigtable、Flume 等的实现中积累的经验。
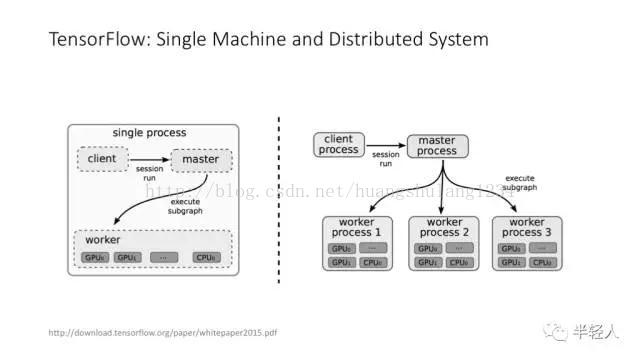
TensorFlow 经典论文中对 TensorFlow 架构的讲解。
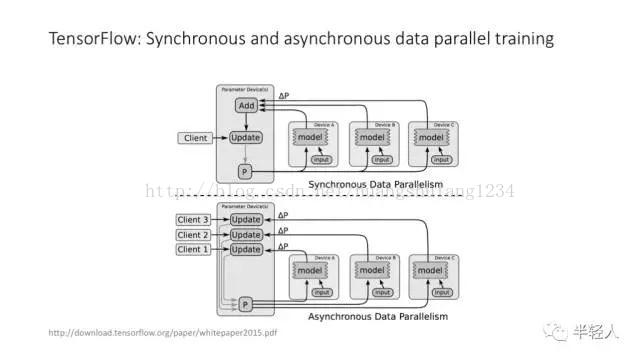
TensorFlow 中的同步训练和异步训练。
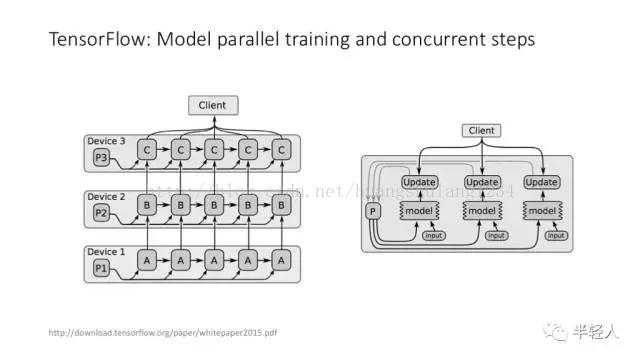
TensorFlow 中的不同的并行策略。

可视化是个与架构有点儿关系,但更像一个 feature 的领域。对机器学习特别是深度学习算法的可视化,未来会变得越来越重要。
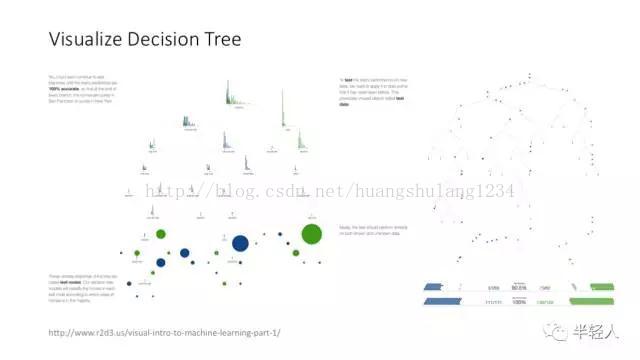
这个对决策树算法进行可视化的网站,非常好玩。
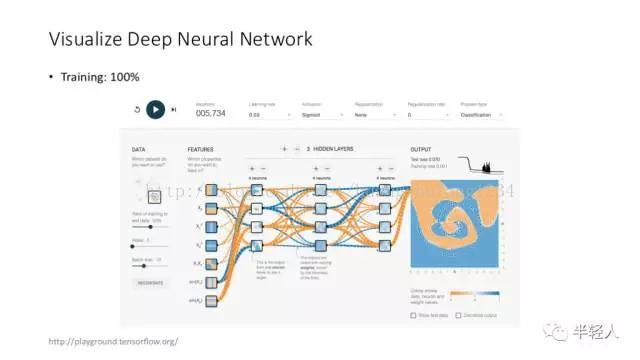
TensorFlow 自己提供的可视化工具,也非常有意思(当然,上图应用属于玩具性质,不是真正意义上,将用户自己的模型可视化的工具)。

有关架构的几篇极其经典的 paper 在这里了。
出处:https://mp.weixin.qq.com/s/s8jythpLcCfcSEYXgQpKpA
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
-END-