Feature Extractors(特征提取)——Spark ML-2.3.0
这是Spark-2.3.0版本的例子
1. TF-IDF(词频-逆向文档频率)
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
import org.apache.spark.sql.SparkSession
object Tfld_feature {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Tfld_feature")
.getOrCreate()
val sentenceData = spark.createDataFrame(Seq(
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
)).toDF("label", "sentence")
// 使用Tokenizer()将每个句子分成单词
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsData = tokenizer.transform(sentenceData)
//HashingTF将美好局的单词转化成哈希特征向量
val hasingTF = new HashingTF()
.setInputCol("words").setOutputCol("rawFeatures")
.setNumFeatures(20)
val featurizedData = hasingTF.transform(wordsData)
// IDF()重新缩放特征向量
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
rescaledData.select("label", "features").take(3).foreach(println)
spark.stop()
}
}
run ----> Edit Configuration ----> VM options 改为:-Dspark.master=local,最后运行结果为:
[0.0,(20,[0,5,9,17],[0.6931471805599453,0.6931471805599453,0.28768207245178085,1.3862943611198906])]
[0.0,(20,[2,7,9,13,15],[0.6931471805599453,0.6931471805599453,0.8630462173553426,0.28768207245178085,0.28768207245178085])]
[1.0,(20,[4,6,13,15,18],[0.6931471805599453,0.6931471805599453,0.28768207245178085,0.28768207245178085,0.6931471805599453])]
2. Word2Vec
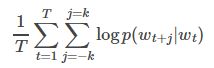
k为训练窗口的大小
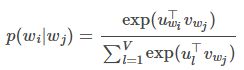
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
object Word2_Vec {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Word2Vec example").getOrCreate()
val documentDF = spark.createDataFrame(
Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)
).toDF("text")
val word2Vec = new Word2Vec()
.setInputCol("text").setOutputCol("result")
.setVectorSize(3).setMinCount(0)
val model = word2Vec.fit(documentDF)
val result = model.transform(documentDF)
result.collect().foreach{ case Row(text: Seq[_], features: Vector) =>
println(s"Text: [${text.mkString(", ")}] => \nVector: $features\n")
}
spark.stop()
}
}
run ----> Edit Configuration ----> VM options 改为:-Dspark.master=local,最后运行结果为:
Text: [Hi, I, heard, about, Spark] =>
Vector: [-0.028139343485236168,0.04554025698453188,-0.013317196490243079]
Text: [I, wish, Java, could, use, case, classes] =>
Vector: [0.06872416580361979,-0.02604914902310286,0.02165239889706884]
Text: [Logistic, regression, models, are, neat] =>
Vector: [0.023467857390642166,0.027799883112311366,0.0331136979162693]3. CountVectorizer
CountVectorizer和CountVectorizerModel将文本文档集合转换为标记数的向量。 当先验词典不可用时,CountVectorizer可以用作估计器来提取词汇表,并生成CountVectorizerModel。 该模型通过词汇生成文档的稀疏表示,然后可以将其传递给其他算法,如LDA。
在拟合过程中,CountVectorizer将选择通过语料库按术语频率排序的top前几vocabSize词。 可选参数minDF:包含在词汇表中的文档的最小数量(或小于1.0)来影响拟合过程。 二进制切换参数控制输出向量:如果设置为true,则所有非零计数都设置为1.对于模拟二进制而不是整数的离散概率模型,这是非常有用的。
参考: http://cwiki.apachecn.org/pages/viewpage.action?pageId=5505205
http://dblab.xmu.edu.cn/blog/1261-2/
http://spark.apache.org/docs/2.1.0/mllib-feature-extraction.html
http://dblab.xmu.edu.cn/blog/1452-2/