卷积神经网络做图像风格迁移的项目代码笔记
代码参考自:https://github.com/ckmarkoh/neuralart_tensorflow
算法来源 CVPR 2016 的文章 “Image Style Transfer Using Convolutional Neural Networks”。
主要是利用一个已经在ImageNet 上训练好的卷积神经网络 VGG-19。
再重新用VGG-19网络训练变量 随机噪声图像x(实际上它在该网络里是输入变量),算是一种巧妙的迁移学习。
算法框架如下:
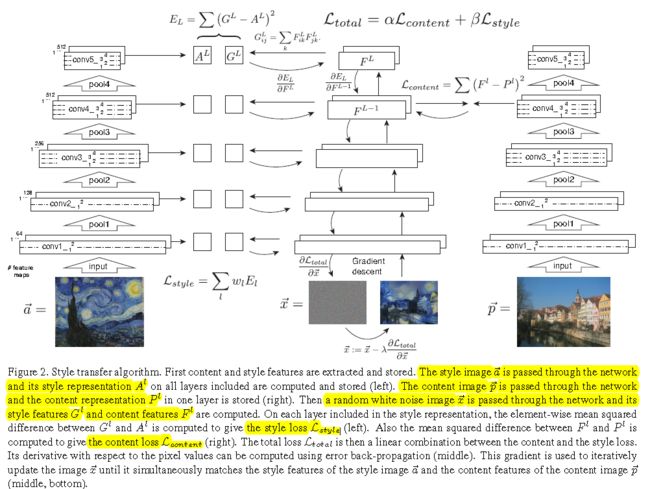
算法代码如下:
'''
## NeuralArt
Implementation of [A Neural Algorithm of Artistic Style](http://arxiv.org/abs/1508.06576) by Tensorflow.
## Requirements
- [Tensorflow](http://www.tensorflow.org/)
- [VGG 19 model](https://drive.google.com/file/d/0B8QJdgMvQDrVU2cyZjFKU1RrLUU/view?usp=sharing)
'''
import tensorflow as tf
import numpy as np
import scipy.io
import scipy.misc
import os
IMAGE_W = 800
IMAGE_H = 600
CONTENT_IMG = './images/Taipei101.jpg'
STYLE_IMG = './images/StarryNight.jpg'
OUTOUT_DIR = './results'
OUTPUT_IMG = 'results.png'
VGG_MODEL = 'imagenet-vgg-verydeep-19.mat'
# 随机噪声与内容图像的比例
INI_NOISE_RATIO = 0.7
# 内容图像和风格图像的权重
CONTENT_STRENGTH = 1
STYLE_STRENGTH = 500
ITERATION = 5000
CONTENT_LAYERS =[('conv4_2',1.)]
STYLE_LAYERS=[('conv1_1',1.),('conv2_1',1.),('conv3_1',1.),('conv4_1',1.),('conv5_1',1.)]
MEAN_VALUES = np.array([123, 117, 104]).reshape((1,1,1,3))
def build_net(n_type, n_in, n_wb=None):
if n_type == 'conv':
return tf.nn.relu(tf.nn.conv2d(n_in, n_wb[0], strides=[1, 1, 1, 1], padding='SAME')+ n_wb[1])
elif n_type == 'pool':
return tf.nn.avg_pool(n_in, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def get_weight_bias(vgg_layers, i,):
weights = vgg_layers[i][0][0][0][0][0]
weights = tf.constant(weights)
bias = vgg_layers[i][0][0][0][0][1]
bias = tf.constant(np.reshape(bias, (bias.size)))
return weights, bias
def build_vgg19(path):
net = {}
vgg_rawnet = scipy.io.loadmat(path)
vgg_layers = vgg_rawnet['layers'][0]
net['input'] = tf.Variable(np.zeros((1, IMAGE_H, IMAGE_W, 3)).astype('float32'))
net['conv1_1'] = build_net('conv',net['input'],get_weight_bias(vgg_layers,0))
net['conv1_2'] = build_net('conv',net['conv1_1'],get_weight_bias(vgg_layers,2))
net['pool1'] = build_net('pool',net['conv1_2'])
net['conv2_1'] = build_net('conv',net['pool1'],get_weight_bias(vgg_layers,5))
net['conv2_2'] = build_net('conv',net['conv2_1'],get_weight_bias(vgg_layers,7))
net['pool2'] = build_net('pool',net['conv2_2'])
net['conv3_1'] = build_net('conv',net['pool2'],get_weight_bias(vgg_layers,10))
net['conv3_2'] = build_net('conv',net['conv3_1'],get_weight_bias(vgg_layers,12))
net['conv3_3'] = build_net('conv',net['conv3_2'],get_weight_bias(vgg_layers,14))
net['conv3_4'] = build_net('conv',net['conv3_3'],get_weight_bias(vgg_layers,16))
net['pool3'] = build_net('pool',net['conv3_4'])
net['conv4_1'] = build_net('conv',net['pool3'],get_weight_bias(vgg_layers,19))
net['conv4_2'] = build_net('conv',net['conv4_1'],get_weight_bias(vgg_layers,21))
net['conv4_3'] = build_net('conv',net['conv4_2'],get_weight_bias(vgg_layers,23))
net['conv4_4'] = build_net('conv',net['conv4_3'],get_weight_bias(vgg_layers,25))
net['pool4'] = build_net('pool',net['conv4_4'])
net['conv5_1'] = build_net('conv',net['pool4'],get_weight_bias(vgg_layers,28))
net['conv5_2'] = build_net('conv',net['conv5_1'],get_weight_bias(vgg_layers,30))
net['conv5_3'] = build_net('conv',net['conv5_2'],get_weight_bias(vgg_layers,32))
net['conv5_4'] = build_net('conv',net['conv5_3'],get_weight_bias(vgg_layers,34))
net['pool5'] = build_net('pool',net['conv5_4'])
return net
# (普通图像p的feature maps集合P, 随机噪声图像x的feature maps集合F)
def build_content_loss(p, x):
print(type(p),np.shape(p)) # net['conv4_2']-- (1, 75, 100, 512)
print(type(x),np.shape(x)) # net['conv4_2']-- (1, 75, 100, 512)
M = p.shape[1]*p.shape[2]
N = p.shape[3]
loss = (1./(2* N**0.5 * M**0.5 )) * tf.reduce_sum(tf.pow((x - p),2))
return loss
# (风格图像a的feature maps集合A, 随机噪声图像x的feature maps集合G)
def build_style_loss(a, x):
def _gram_matrix(x, area, depth):
x1 = tf.reshape(x,(area,depth))
g = tf.matmul(tf.transpose(x1), x1)
return g
def _gram_matrix_val(x, area, depth):
x1 = x.reshape(area,depth)
g = np.dot(x1.T, x1)
return g
M = a.shape[1]*a.shape[2]
N = a.shape[3]
G = _gram_matrix(x, M, N)
A = _gram_matrix_val(a, M, N)
loss = (1./(4 * N**2 * M**2)) * tf.reduce_sum(tf.pow((G - A),2))
return loss
# 读写图像的函数定义,使用scipy.misc库
def read_image(path):
image = scipy.misc.imread(path)
image = scipy.misc.imresize(image,(IMAGE_H,IMAGE_W))
image = image[np.newaxis,:,:,:]
image = image - MEAN_VALUES
return image
def write_image(path, image):
image = image + MEAN_VALUES
image = image[0]
image = np.clip(image, 0, 255).astype('uint8')
scipy.misc.imsave(path, image)
def main():
net = build_vgg19(VGG_MODEL)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
noise_img = np.random.uniform(-20, 20, (1, IMAGE_H, IMAGE_W, 3)).astype('float32')
content_img = read_image(CONTENT_IMG)
style_img = read_image(STYLE_IMG)
### 注意这里写法:----------------------------------------------------------------
## build_content_loss()的第一个参数由content_img获得;第二个参数由噪声图像x计算而得,x在迭代中更新
sess.run([net['input'].assign(content_img)])
cost_content = sum(map(lambda lay: lay[1]*build_content_loss(sess.run(net[lay[0]]), net[lay[0]]), CONTENT_LAYERS))
## build_style_loss()的第一个参数由style_img获得;STYLE_LAYERS包含5层,权重自定义,这里lay[1]都是1
sess.run([net['input'].assign(style_img)])
cost_style = sum(map(lambda lay: lay[1]*build_style_loss(sess.run(net[lay[0]]), net[lay[0]]), STYLE_LAYERS))
cost_total = cost_content + STYLE_STRENGTH * cost_style
optimizer = tf.train.AdamOptimizer(2.0)
train = optimizer.minimize(cost_total)
sess.run(tf.global_variables_initializer())
sess.run(net['input'].assign( INI_NOISE_RATIO * noise_img + (1.-INI_NOISE_RATIO) * content_img))
### -------------------------------------------------------------------------------
if not os.path.exists(OUTOUT_DIR):
os.mkdir(OUTOUT_DIR)
for i in range(ITERATION):
# net['input']是一个tf变量由于tf.Variable()从而每次迭代更新;而vgg19中的weights和bias都是tf常量不会被更新
sess.run(train)
if i%100 ==0:
result_img = sess.run(net['input'])
print(sess.run(cost_total))
write_image(os.path.join(OUTOUT_DIR, '%s.png' % (str(i).zfill(4))), result_img)
if __name__ == '__main__':
main()

2000次迭代后已经变化不大了
最终效果图(5000次迭代结果)
content image:

style image:

mixed image: