XLNet原理介绍
1. 引言
前面介绍了ELMo、BERT、CSE等语言模型,这些语言模型在很多下游NLP任务上都取得了不错的成绩,根据他们的目标函数和模型的结构,可以大致将这些模型分为两大类,即自回归模型(autoregressive,AR)和自编码模型(autoencoding,AE)。对于给定的一个文本序列 x = ( x 1 , ⋯ , x T ) \mathbf{x}=\left(x_{1}, \cdots, x_{T}\right) x=(x1,⋯,xT),AR模型主要是通过每个token的前文或后文进行预测,最后将每个时间步的概率进行连乘作为模型的目标函数,即 p ( x ) = ∏ t = 1 T p ( x t ∣ x < t ) p(\mathbf{x})=\prod_{t=1}^{T} p\left(x_{t} | \mathbf{x}_{<t}\right) p(x)=∏t=1Tp(xt∣x<t)或者 p ( x ) = ∏ t = T 1 p ( x t ∣ x > t ) p(\mathbf{x})=\prod_{t=T}^{1} p\left(x_{t} | \mathbf{x}>t\right) p(x)=∏t=T1p(xt∣x>t),比如ELMo模型、CSE模型、Transformer XL模型等。而AE模型则通过对原句子进行破坏,并希望通过模型来对原句子进行重建,比如BERT模型,通过随机选择15%的tokens进行mask,然后希望模型将这部分被mask掉的token重新预测出来。
对于这两种类型的模型,其实都有各自的优缺点,AR模型由于只考虑单向的文本信息,忽略了很多文本任务需要综合双向的上下文信息的事实。而AE模型虽然考虑了双向的上下文信息,但是由于在预训练时,对预测词汇替换为[MASK],而[MASK]这个特殊词汇在下游NLP任务中是不会真实存在的,因此,会导致预训练和fine-tuning阶段存在差异。另一方面,BERT假设被预测的词汇之间是独立的,这明显有悖于语言的长依赖特性。
因此,为了克服AR模型和AE模型的缺点,2019年CMU和谷歌大脑提出了一个新的语言模型,即XLNet,该模型通过引入随机排序的思想,充分发挥了AR模型和AE模型的优点。
- 论文地址:《XLNet: Generalized Autoregressive Pretraining for Language Understanding》
2. XLNet原理介绍
2.1 Permutation Language Modeling
XLNet通过随机排序的思想,来解决AR模型无法引入双向文本信息的缺点,对于一个长度为 T T T的序列 x x x,其排列的方式有 T ! T ! T!种,因此,当模型从不同的排序中进行学习时,将可以学到双向的文本信息。令 Z T \mathcal{Z}_{T} ZT表示长度为 T T T的序列的所有排列方式的集合, z t z_{t} zt、 z < t \mathbf{z}<t z<t表示排列 z ∈ Z T \mathbf{z} \in \mathcal{Z}_{T} z∈ZT的第 t t t个元素和前 t − 1 t-1 t−1个元素。则此时XLNet的目标函数表达如下:
max θ E z ∼ Z T [ ∑ t = 1 T log p θ ( x z t ∣ x z < t ) ] \max _{\theta} \quad \mathbb{E}_{\mathbf{z} \sim \mathcal{Z}_{T}}\left[\sum_{t=1}^{T} \log p_{\theta}\left(x_{z_{t}} | \mathbf{x}_{\mathbf{z}<t}\right)\right] θmaxEz∼ZT[t=1∑Tlogpθ(xzt∣xz<t)]
需要注意的是,此时的随机排序只是对序列中每个位置的序号进行随机排序,排序后,每个词汇前面的词汇都可以用于预测其概率,这里前面的词汇可能来自于原句子中当前词汇前面的词汇,也可能来自其后面的词汇,因此,相当于看到了双向的序列信息。
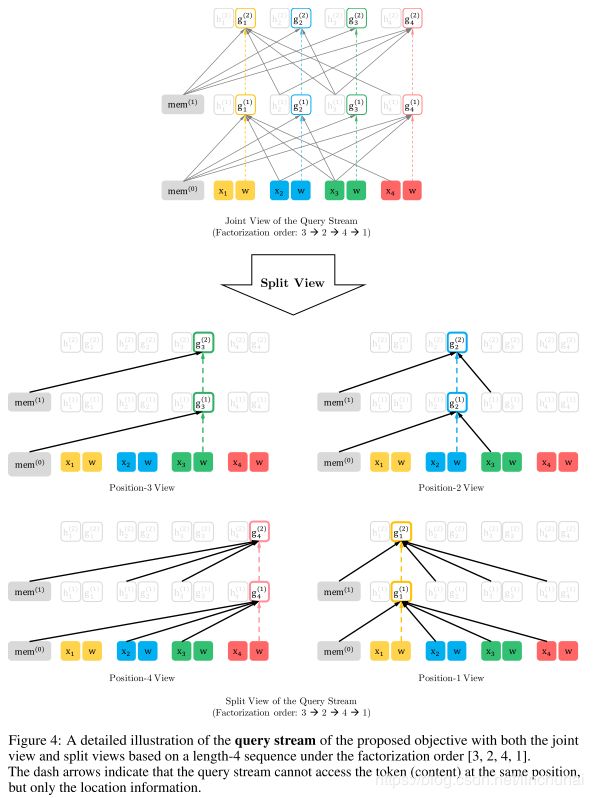
如下图所示,假设对于原始的顺序[1,2,3,4],随机排列后变成[3,2,4,1],则此时在计算3的概率时,是看不到[2,4,1]的信息的,但是在预测2时,则可以看到3的信息,在实际的计算中,通过mask的技巧来表现这种随机排列的顺序。

2.2 Two-Stream Self-Attention
但是,如果只是通过随机排序,然后利用Transformer进行训练,则会出现一个目标模糊的问题。可以来看一个例子,假设我们现在要计算第 t t t个位置的概率 p θ ( X z t ∣ x z < t ) p_{\theta}\left(X_{z_{t}} | \mathbf{x}_{\mathbf{z}<t}\right) pθ(Xzt∣xz<t),其表达式如下:
p θ ( X z t = x ∣ x z < t ) = exp ( e ( x ) ⊤ h θ ( x z < t ) ) ∑ x ′ exp ( e ( x ′ ) ⊤ h θ ( x z < t ) ) p_{\theta}\left(X_{z_{t}}=\right.\left.x | \mathbf{x}_{\mathbf{z}<t}\right)=\frac{\exp \left(e(x)^{\top} h_{\theta}\left(\mathbf{x}_{\mathbf{z}}<t\right)\right)}{\sum_{x^{\prime}} \exp \left(e\left(x^{\prime}\right)^{\top} h_{\theta}\left(\mathbf{x}_{\mathbf{z}}<t\right)\right)} pθ(Xzt=x∣xz<t)=∑x′exp(e(x′)⊤hθ(xz<t))exp(e(x)⊤hθ(xz<t))
其中, h θ ( x z < t ) h_{\theta}\left(\mathbf{x}_{\mathbf{z}_{<} t}\right) hθ(xz<t)表示Transformer计算得到的 X Z < t \mathbf{X}_{\mathbf{Z}<t} XZ<t隐藏向量, e ( x ) e(x) e(x)表示词汇的embedding向量,此时, h θ ( x z < t ) h_{\theta}\left(\mathbf{x}_{\mathbf{z}_{<} t}\right) hθ(xz<t)包含的是前面 t − 1 t-1 t−1个位置的序列信息,与要预测的 t t t位置独立,假设此时有两个不同的排序 z ( 1 ) \mathbf{z}^{(1)} z(1)和 z ( 2 ) \mathbf{z}^{(2)} z(2),满足以下的关系:
z < t ( 1 ) = z < t ( 2 ) = z < t but z t ( 1 ) = i ≠ j = z t ( 2 ) \mathbf{z}_{<t}^{(1)}=\mathbf{z}_{<t}^{(2)}=\mathbf{z}_{<t} \quad \text { but } \quad z_{t}^{(1)}=i \neq j=z_{t}^{(2)} z<t(1)=z<t(2)=z<t but zt(1)=i̸=j=zt(2)
也就是说两个排序前 t − 1 t-1 t−1个位置完全一样,但是第 t t t个位置不一样,那么,此时对 t t t时刻计算概率分布时,有:
p θ ( X i = x ∣ x z < t ) ⎵ z t ( 1 ) = i , z < t ( 1 ) = z < t = p θ ( X j = x ∣ x z < t ) ⎵ z t ( 1 ) = j , z < t ( 2 ) = z < t = exp ( e ( x ) ⊤ h ( x z < t ) ) ∑ x ′ exp ( e ( x ′ ) ⊤ h ( x z < t ) ) \underbrace{p_{\theta}\left(X_{i}=x | \mathbf{x}_{\mathbf{z}<t}\right)}_{z_{t}^{(1)}=i, \mathbf{z}_{<t}^{(1)}=\mathbf{z}<t}=\underbrace{p_{\theta}\left(X_{j}=x | \mathbf{x}_{\mathbf{z}<t}\right)}_{z_{t}^{(1)}=j, \mathbf{z}_{<t}^{(2)}=\mathbf{z}<t}=\frac{\exp \left(e(x)^{\top} h\left(\mathbf{x}_{\mathbf{z}<t}\right)\right)}{\sum_{x^{\prime}} \exp \left(e\left(x^{\prime}\right)^{\top} h\left(\mathbf{x}_{\mathbf{z}<t}\right)\right)} zt(1)=i,z<t(1)=z<t pθ(Xi=x∣xz<t)=zt(1)=j,z<t(2)=z<t pθ(Xj=x∣xz<t)=∑x′exp(e(x′)⊤h(xz<t))exp(e(x)⊤h(xz<t))
即原本序列中第 i i i和第 j j j个位置此时预测出来的结果会完全一致,这就会导致模型的目标变得模糊不清,没法收敛,为了克服这个问题,应该让目标函数也包含 t t t时刻的位置信息,因此,可以将目标函数改为如下:
p θ ( X z t = x ∣ x z < t ) = exp ( e ( x ) ⊤ g θ ( x z < t , z t ) ) ∑ x ′ exp ( e ( x ′ ) ⊤ g θ ( x z < t , z t ) ) p_{\theta}\left(X_{z_{t}}=x | \mathbf{x}_{z_{<t}}\right)=\frac{\exp \left(e(x)^{\top} g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right)\right)}{\sum_{x^{\prime}} \exp \left(e\left(x^{\prime}\right)^{\top} g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right)\right)} pθ(Xzt=x∣xz<t)=∑x′exp(e(x′)⊤gθ(xz<t,zt))exp(e(x)⊤gθ(xz<t,zt))
其中, g θ ( x z < t , z t ) g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right) gθ(xz<t,zt)是一种新的计算,引入了 z t z_{t} zt作为输入。
但是, g θ ( x z < t , z t ) g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right) gθ(xz<t,zt)具体应该怎么计算呢?当我们预测 x z t x_{z_{t}} xzt时, g θ ( x z < t , z t ) g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right) gθ(xz<t,zt)应该包含位置 z t z_{t} zt的信息,但是不能包含 x z t x_{z_{t}} xzt的内容信息,当预测 x z j x_{z_{j}} xzj,其中 j > t j>t j>t时,此时 g θ ( x z < t , z t ) g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right) gθ(xz<t,zt)可以包含 x z t x_{z_{t}} xzt的内容信息。为了解决这个问题,作者在Transformer的每个位置采用了两个隐藏向量来表示,即Two-Stream Self-Attention。具体如下:
- content representation h θ ( x z ≤ t ) h_{\theta}\left(\mathbf{x}_{\mathbf{z}_{ \leq} t}\right) hθ(xz≤t):简写为 h z t h_{z_{t}} hzt,这个隐藏向量的计算方式与原先Transformer的隐藏向量的计算方式一致,不仅包含了上下文信息,也包含了词汇 x x t x_{x_{t}} xxt本身的内容信息。
- query representation g θ ( x z < t , z t ) g_{\theta}\left(\mathbf{x}_{\mathbf{z}<t}, z_{t}\right) gθ(xz<t,zt):简写为 g z t g_{z_{t}} gzt,这个隐藏向量的计算则只包含了上下文信息 x z < t \mathbf{x}_{\mathbf{z}<t} xz<t和位置信息 z t z_{t} zt,但是不包含 x x t x_{x_{t}} xxt本身的内容信息。
在计算时,对于query stream的第一层,采用可训练的参数进行初始化,即 g i ( 0 ) = w g_{i}^{(0)}=w gi(0)=w,对于content stream的第一层,则直接采用embedding进行初始化,即 h i ( 0 ) = e ( x i ) h_{i}^{(0)}=e\left(x_{i}\right) hi(0)=e(xi),对于每一层注意力的计算,两个stream的计算方式分别如下:

其中,Q,K,V同Transformer中的query、key、value,作者在实际训练时采用的是Transformer XL的结构。需要注意的是,这里两个stream其实参数都是共享的,只是两者的输入和mask稍微不一致,其实content stream本质只是其一个辅助计算作用,为了便于计算而已。在最后计算概率时,用最后一层的 g z t ( M ) g_{z_{t}}^{(M)} gzt(M)进行计算。

2.3 Partial Prediction
在实际的训练过程中,由于随机排列的原因,模型的收敛速度会非常慢,因此,为了提高模型预训练的速度,作者采用了局部预测的方法,即将目标序列随机选取一个切分点 c c c切分为两段,分别为 z ≤ c z_{≤c} z≤c(non-target subsequence)和 z > c z_{>c} z>c(target subsequence),然后只对target subsequence计算目标函数:
max θ E z ∼ Z T [ log p θ ( x z > c ∣ x z ≤ c ) ] = E z ∼ Z T [ ∑ t = c + 1 ∣ z ∣ log p θ ( x z t ∣ x z < t ) ] \max _{\theta} \quad \mathbb{E}_{\mathbf{z} \sim \mathcal{Z}_{T}}\left[\log p_{\theta}\left(\mathbf{x}_{\mathbf{z}_{>c}} | \mathbf{x}_{\mathbf{z}_{ \leq c}}\right)\right]=\mathbb{E}_{\mathbf{z} \sim \mathcal{Z}_{T}}\left[\sum_{t=c+1}^{|\mathbf{z}|} \log p_{\theta}\left(x_{z_{t}} | \mathbf{x}_{\mathbf{z}<t}\right)\right] θmaxEz∼ZT[logpθ(xz>c∣xz≤c)]=Ez∼ZT⎣⎡t=c+1∑∣z∣logpθ(xzt∣xz<t)⎦⎤
也就是说只选取1 / K / K /K的词汇进行局部预测,其中 ∣ z ∣ / ( ∣ z ∣ − c ) ≈ K |\mathbf{z}| /(|\mathbf{z}|-c) \approx K ∣z∣/(∣z∣−c)≈K,对于non-target subsequence,则只需计算其content stream即可,这样可以节省计算和存储。
2.4 Transformer-XL
由于XLNet的结构采用的Transformer XL,所以对于双流注意力的实际计算与Transformer还是有一些不同,之所以选择Transformer XL这种恶心的结构,主要原因还是因为Transformer XL就是作者们提出来的。不失一般性,假设一个长句 s s s可以切分为两个子句 x ~ = s 1 : T \tilde{\mathbf{x}}=\mathbf{s}_{1 : T} x~=s1:T, x = s T + 1 : 2 T \mathbf{x}=\mathbf{s}_{T+1 : 2 T} x=sT+1:2T, z ~ \tilde{\mathbf{z}} z~和 z z z分别表示 [ 1 ⋯ T ] [1 \cdots T] [1⋯T]和 [ T + 1 ⋯ 2 T ] [T+1 \cdots 2 T] [T+1⋯2T]的一种排序,基于排序 z ~ \tilde{\mathbf{z}} z~,我们可以获得一个子句每一层 m m m的content representations h ~ ( m ) \tilde{\mathbf{h}}^{(m)} h~(m),将其传递给下一个子句,则下一个子句的content representations的计算如下:
h z t ( m ) ← Attention ( Q = h z t ( m − 1 ) , K V = [ h ~ ( m − 1 ) , h z ≤ t ( m − 1 ) ] ; θ ) h_{z_{t}}^{(m)} \leftarrow \text { Attention }\left(\mathrm{Q}=h_{z_{t}}^{(m-1)}, \mathrm{KV}=\left[\tilde{\mathbf{h}}^{(m-1)}, \mathbf{h}_{\mathbf{z}_{ \leq t}}^{(m-1)}\right] ; \theta\right) hzt(m)← Attention (Q=hzt(m−1),KV=[h~(m−1),hz≤t(m−1)];θ)
具体的计算过程如下图所示:

query stream的计算也类似,具体的计算过程如下:
2.5 Relative Segment Encodings
由于很多下游NLP任务中都包含了多个句子的情况,比如问答任务,因此,XLNet也同BERT一样引入了Segment Encodings。在训练过程中,随机选择两个句子仅拼接,拼接的形式如下[A, SEP, B, SEP, CLS],然后作为模型的输入,两个句子可能是上下文的关系,也可能完全不是上下文的关系,不过只有属于上下文关系时,上一个句子的各层的输出才能流入到下一个句子的计算中,作者在实验中也尝试像BERT一样在目标函数中加入next sentence预测,但是发现并没有什么效果,所以在XLNet-Large中直接取消了这个操作。
由于作者采用的是Transformer XL的结构,因此,在Segment Encoding时,也同样采用了相对Segment Encoding的方法,即给定一对 i , j i,j i,j,在原来注意力的计算基础上,添加下面一项:
a i j = ( q i + b ) ⊤ s i j a_{i j}=\left(\mathbf{q}_{i}+\mathbf{b}\right)^{\top} \mathbf{s}_{i j} aij=(qi+b)⊤sij
其中, q i q_i qi表示query vector, b b b是一个可训练的向量,s_{i,j}也是来自于两个可训练的向量 s + s_{+} s+和 s − s_{-} s−,当 i , j i,j i,j来自于同一个segment时,则 s i j = s + \mathbf{s}_{i j}=\mathbf{s}_{+} sij=s+,否则, s i j = s − \mathbf{s}_{i j}=\mathbf{s}_{-} sij=s−
3. 总结
以上就是XLNet的介绍,整体来看是非常恶心的,因此在Transformer XL的机构上引入了随机排列和双流注意力机制,因此,使得整个模型变得非常复杂。但是也正是因为XLNet充分发挥了BERT和AR模型的优点,因此导致其性能必定超越BERT,成为刷榜的新神器。总结一下:
- XLNet利用随机排列的思想,使得模型可以考虑文本序列的双向信息,因此,比普遍的AR模型要更强。
- XLNet的目标函数采用的AR模型的目标函数,因此,不需要像BERT那样采用MASK字符,因此,避免了预训练和训练阶段的模型差异,也剔除了被MASK词汇之间互相独立的强假设。