Caffe MNIST 手写数字识别(全面流程)
目录
1.下载MNIST数据集
2.生成MNIST图片训练、验证、测试数据集
3.制作LMDB数据库文件
4.准备LeNet-5网络结构定义模型.prototxt文件
5.准备模型求解配置文件_solver.prototxt
6.开始训练并生成日志文件
7.训练日志画图(可视化一些训练数据)plot_training_log.py
7.2日志解析成txt文件(若干数据字段可供画图)parse_log.py
8.模型测试和评估(用于选取较优模型)
8.1.测试模型准确率
8.2评估模型性能
9.手写数字识别(模型部署)
10.数据增强再训练
10.1训练数据增加方法
10.2 接着上次训练状态再训练
10.3在训练的时候实时增加数据的方法:第三方实时扰动的Caffe层
11.caffe-augmentation
Realtime data augmentation
How to use
环境:
OS:Ubuntu 18.04LTS
caffe环境
1.下载MNIST数据集
这里使用Bengio组封装好的MNIST数据集
(题外话:Bengio:Yoshua Bengio:孤军奋战的AI学者和他的乌托邦情怀)
在控制台下输入:
wget http://deeplearning.net/data/mnist/mnist.pkl.gz在当前文件夹下得到mnist.pkl.gz压缩文件。
2.生成MNIST图片训练、验证、测试数据集
mnist.pkl.gz这个压缩包中就是mnist数据集的 训练集train、验证集validate、测试集test采用pickle导出的文件被压缩为gzip格式,所以采用python中的gzip模块当成文件就可以读取。其中每个数据集是一个元组,第一个元素存储的是手写数字的图片:长度为28*28=728的一维浮点型号numpy数组,这个数组就算单一通道的灰度图像,归一化后的,最大值1代表白色,最小值0 代表黑色;元组的第二个元素代表的是图片的对于数字标签,是一个一维的整型numpy数组,按照下标位置对应图片中的数字。
知道了以上数据结构信息,就可以使用Python脚本完成数据->图片的转换:
执行以下convert_mnist.py 脚本:(这个脚本在当前文件夹下创建一个mnist文件夹,然后在mnist文件夹下创建3个子文件夹:train、val、test;分别用来表示对应生存的训练、验证、测试数据集的图片;
train下有5万图像、val和test文件下分别有1万幅图像。
# Load the dataset, 从压缩文件读取MNIST数据集:
print('Loading data from mnist.pkl.gz ...')
with gzip.open('mnist.pkl.gz', 'rb') as f:
train_set, valid_set, test_set = pickle.load(f)
#在当前路径下生成mnist文件夹
imgs_dir = 'mnist'
os.system('mkdir -p {}'.format(imgs_dir))
#datasets是个字典 键-值对 dataname-dataset 对
datasets = {'train': train_set, 'val': valid_set, 'test': test_set}
for dataname, dataset in datasets.items():
print('Converting {} dataset ...'.format(dataname))
data_dir = os.sep.join([imgs_dir, dataname]) #字符串拼接
os.system('mkdir -p {}'.format(data_dir)) #生成对应的文件夹
# i代表数据的序号,用zip()函数读取对应的位置的图片和标签
for i, (img, label) in enumerate(zip(*dataset)):
filename = '{:0>6d}_{}.jpg'.format(i, label)
filepath = os.sep.join([data_dir, filename])
img = img.reshape((28, 28)) #将一维数组还原成二维数组
#用pyplot保存可以自动归一化生成像素值在[0,255]之间的灰度图
pyplot.imsave(filepath, img, cmap='gray')
if (i+1) % 10000 == 0:
print('{} images converted!'.format(i+1))
图片的命令规则:第一个地段是6位数字是图片的序号_第二个字段是该图的标签.jpg
3.制作LMDB数据库文件
使用Caffe提高的工具:convert_imageset命令:
先看看该命令的帮助说明:
在控制台执行以下命令:
/home/yang/caffe/build/tools/convert_imageset -help得到一些说明,提取关键说明:
convert_imageset: Convert a set of images to the leveldb/lmdb
format used as input for Caffe.
Usage:
convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
The ImageNet dataset for the training demo is at
http://www.image-net.org/download-images
...
Flags from tools/convert_imageset.cpp:
-backend (The backend {lmdb, leveldb} for storing the result) type: string
default: "lmdb"
-check_size (When this option is on, check that all the datum have the same
size) type: bool default: false
-encode_type (Optional: What type should we encode the image as
('png','jpg',...).) type: string default: ""
-encoded (When this option is on, the encoded image will be save in datum)
type: bool default: false
-gray (When this option is on, treat images as grayscale ones) type: bool
default: false
-resize_height (Height images are resized to) type: int32 default: 0
-resize_width (Width images are resized to) type: int32 default: 0
-shuffle (Randomly shuffle the order of images and their labels) type: bool
default: false
该命令需要一个图片路径和标签的列表文件.txt;该文件的每一行是一幅图片的全路径 标签
比如:train.txt 局部如下:
mnist/train/033247_5.jpg 5
mnist/train/025404_9.jpg 9
mnist/train/026385_8.jpg 8
mnist/train/013058_5.jpg 5
mnist/train/006524_5.jpg 5
...
我们需要将第2步骤生成的train、val、test文件夹下的所有图像的路径和标签生存三个train.txt、val.txt、test.txt文件:
执行如下的三条命令,分类生成train.txt;val.txt;test.txt文件
python gen_caffe_imglist.py mnist/train train.txt
python gen_caffe_imglist.py mnist/val val.txt
python gen_caffe_imglist.py mnist/test test.txt其中gen_caffe_imglist.py脚本如下:传入的第一个参数是包含图片的文件路径(相对路径)第二个参数是 生存的.txt文件名(路径)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Mon Dec 3 18:35:55 2018
@author: yang
"""
import os
import sys
input_path = sys.argv[1].rstrip(os.sep)
output_path = sys.argv[2]
filenames = os.listdir(input_path)
with open(output_path, 'w') as f:
for filename in filenames:
filepath = os.sep.join([input_path, filename])
label = filename[:filename.rfind('.')].split('_')[1]
line = '{} {}\n'.format(filepath, label)
f.write(line)
f.close()
这样就生存了三个数据集图片文件列表和对应的标签了,下面就可以调用caffe提供的convert_imageset命令实现转换了:
/home/yang/caffe/build/tools/convert_imageset ./ train.txt train_lmdb --gray --shuffle
/home/yang/caffe/build/tools/convert_imageset ./ val.txt val_lmdb --gray --shuffle
/home/yang/caffe/build/tools/convert_imageset ./ test.txt test_lmdb --gray --shuffle然后就在当前文件夹下生成了3个LMDB文件夹了:train_lmdb;val_lmdb;test_lmdb;
4.准备LeNet-5网络结构定义模型.prototxt文件
lenet_train_val.prototxt 这个文件是用来训练模型用的;内容稍微区别于发布文件lenet.prototxt;
lenet_train_val.prototxt内容如下:(注意需要修改开头的输入数据lmdb文件的路径)
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mean_value: 128
scale: 0.00390625
}
data_param {
source: "train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mean_value: 128
scale: 0.00390625
}
data_param {
source: "val_lmdb"
batch_size: 100
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}5.准备模型求解配置文件_solver.prototxt
lenet_solver.prototxt内容如下:
注意修改net定义文件的路径(这里是相对路径就是文件名)net: "lenet_train_val.prototxt"
和存储训练迭代中间结果的快照文件夹:snapshot_prefix: "snapshot" ,先在当前文件夹下创建一个快照文件夹snapshot
# The train/validate net protocol buffer definition
net: "lenet_train_val.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 36000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "snapshot"
# solver mode: CPU or GPU
solver_mode: GPU6.开始训练并生成日志文件
首先在当前文件夹下创建一个存储日志的文件夹:trainLog文件夹
然后执行以下命令:
train命令需要带 网络模型定义文件lenet_solver.prototxt
其他参数可以通过-help 查看一下
/home/yang/caffe/build/tools/caffe train -solver lenet_solver.prototxt -gpu 0 -log_dir ./trainLog训练结束在快照文件夹下生成了不同迭代次数的求解状态文件*.solverstate和网络模型参数文件:*.caffemodel
7.训练日志画图(可视化一些训练数据)plot_training_log.py
caffe提供了可视化log的工具:
python /home/yang/caffe/tools/extra/plot_training_log.py
执行如下命令查看帮助:
python /home/yang/caffe/tools/extra/plot_training_log.py -help
yang@yang-System-Product-Name:~/caffe/data/mnist_Bengio/trainLog$ python /home/yang/caffe/tools/extra/plot_training_log.py -help
This script mainly serves as the basis of your customizations.
Customization is a must.
You can copy, paste, edit them in whatever way you want.
Be warned that the fields in the training log may change in the future.
You had better check the data files and change the mapping from field name to
field index in create_field_index before designing your own plots.
Usage:
./plot_training_log.py chart_type[0-7] /where/to/save.png /path/to/first.log ...
Notes:
1. Supporting multiple logs.
2. Log file name must end with the lower-cased ".log".
Supported chart types:
0: Test accuracy vs. Iters
1: Test accuracy vs. Seconds
2: Test loss vs. Iters
3: Test loss vs. Seconds
4: Train learning rate vs. Iters
5: Train learning rate vs. Seconds
6: Train loss vs. Iters
7: Train loss vs. Seconds
Caffe提供了可视化log的工具:在/home/yang/caffe/tools/extra 下面的polt_training_log.py.example 文件
把这个文件复制一份并命名为polt_training_log.py ,就可以用这个python脚本来画图:
这个脚本的输入参数类型是:需要画什么图、生成的图片存储路径与文件名、训练得到log文件路径
支持画8中图:
0:测试准确率 vs. 迭代次数
1:测试准确率 vs. 训练时间(秒)
2:测试loss vs. 迭代次数
3:测试loss vs. 训练时间
4:学习率lr vs. 迭代次数
5:学习率lr vs. 训练时间
6:训练loss vs.迭代次数
7: 训练loss vs.训练时间
在控制台执行如下命令:生成以上8幅图;
python /home/yang/caffe/tools/extra/plot_training_log.py 0 test_acc_vs_iters.png caffeLeNetTrain20181203.log
python /home/yang/caffe/tools/extra/plot_training_log.py 1 test_acc_vs_time.png caffeLeNetTrain20181203.log
python /home/yang/caffe/tools/extra/plot_training_log.py 2 test_loss_vs_iters.png caffeLeNetTrain20181203.log
python /home/yang/caffe/tools/extra/plot_training_log.py 3 test_loss_vs_time.png caffeLeNetTrain20181203.log
python /home/yang/caffe/tools/extra/plot_training_log.py 4 lr_vs_iters.png caffeLeNetTrain20181203.log
python /home/yang/caffe/tools/extra/plot_training_log.py 5 lr_vs_time.png caffeLeNetTrain20181203.log
python /home/yang/caffe/tools/extra/plot_training_log.py 6 train_loss_vs_iters.png caffeLeNetTrain20181203.log
python /home/yang/caffe/tools/extra/plot_training_log.py 7 train_loss_vs_time.png caffeLeNetTrain20181203.log如下是train的准确率-迭代次数图:

7.2日志解析成txt文件(若干数据字段可供画图)parse_log.py
yang@yang-System-Product-Name:~/caffe/data/mnist_Bengio/trainLog$ python /home/yang/caffe/tools/extra/parse_log.py -h
usage: parse_log.py [-h] [--verbose] [--delimiter DELIMITER]
logfile_path output_dir
Parse a Caffe training log into two CSV files containing training and testing
information
positional arguments:
logfile_path Path to log file
output_dir Directory in which to place output CSV files
optional arguments:
-h, --help show this help message and exit
--verbose Print some extra info (e.g., output filenames)
--delimiter DELIMITER
Column delimiter in output files (default: ',')
2.parse_log.py文件的作用就是:将你的日志文件分解成两个txt(csv)文本文件。
终端输入如下命令
python ./tools/extra/parse_log.py ./examples/myfile/a.log ./examples/myfile/
便会在myfile/目录下产生a.log.train 和a.log.test的文件,根据这两个文件你可以使用matplotlib库画出你想要的图像。
/home/yang/caffe/tools/extra/parse_log.py caffeLeNetTrain20181203.log ./
下面的指令解析caffeLeNetTrain20181203.log 并在当前文件夹./下生成 两个.txt文件:caffeLeNetTrain20181203.log.train;caffeLeNetTrain20181203.log.test
这两个文本文件包含这些字段:NumIters,Seconds,LearningRate,accuracy,loss
根据这两个文件你可以使用matplotlib库画出你想要的图像。
下面是训练日志解析文件局部:caffeLeNetTrain20181203.log.train:
NumIters,Seconds,LearningRate,loss
0.0,0.155351,0.01,2.33102
100.0,0.482773,0.01,0.167176
200.0,0.806851,0.00992565,0.1556
300.0,1.1295,0.00985258,0.0575197
400.0,1.460222,0.00978075,0.0952922
500.0,1.897946,0.00971013,0.0684174
600.0,2.216532,0.00964069,0.0514046下面是测试文件解析局部:caffeLeNetTrain20181203.log.test
NumIters,Seconds,LearningRate,accuracy,loss
0.0,0.129343,0.00971013,0.0919,2.33742
500.0,1.895023,0.00971013,0.976,0.0833776
1000.0,3.602925,0.00937411,0.9794,0.0671232
1500.0,5.299409,0.00906403,0.9853,0.0522081
2000.0,6.99157,0.00877687,0.9856,0.0475213
2500.0,8.691082,0.00851008,0.9859,0.0473052利用Python的 pandas 和 matplotlib 可以画出以上字段的各个字段的曲线:
import pandas as pd
import matplotlib.pyplot as plt
如下是画出训练和验证(测试)的loss-NumIters迭代次数 曲线图:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 4 10:53:28 2018
@author: yang
"""
import pandas as pd
import matplotlib.pyplot as plt
train_log = pd.read_csv("caffeLeNetTrain20181203.log.train")
test_log = pd.read_csv("caffeLeNetTrain20181203.log.test")
_, ax1 = plt.subplots()
ax1.set_title("train loss and test loss")
ax1.plot(train_log["NumIters"], train_log["loss"], alpha=0.5)
ax1.plot(test_log["NumIters"], test_log["loss"], 'g')
ax1.set_xlabel('iteration')
ax1.set_ylabel('train loss')
plt.legend(loc='upper left')
ax2 = ax1.twinx()
#ax2.plot(test_log["NumIters"], test_log["LearningRate"], 'r')
#ax2.plot(test_log["NumIters"], test_log["LearningRate"], 'm')
#ax2.set_ylabel('test LearningRate')
#plt.legend(loc='upper right')
plt.show()
print('Done.') 
8.模型测试和评估(用于选取较优模型)
8.1.测试模型准确率
训练好后,就需要对模型进行测试和评估
其实在训练过程中,每迭代500此,就已经在val_mldb上对模型进行了准确率的评估了;
不过MNIST除了验证集还有测试集,对于模型的选择,以测试集合为准进行评估(泛化能力)
对lenet_train_val.ptototxt 文件的头部数据层部分稍作修改,删去TRAIN层,将TEST层的数据源路径改为test_lmdb文件路径:
lenet_test.prototxt:
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mean_value: 128
scale: 0.00390625
}
data_param {
source: "test_lmdb"
batch_size: 100
backend: LMDB
}
}
...下面执行caffe的测试命令:并生成日志文件:
/home/yang/caffe/build/tools/caffe test -model lenet_test.prototxt -weights ./snapshot/lenet_solver_iter_5000.caffemodel -gpu 0 -iterations 100 -log_dir ./testLog
test命令参数说明:
-model 指定测试网络定义文件lenet_test.prototxt
-weights 指定一个迭代次数下生成的权重文件lenet_solver_iter_5000.caffemodel(这个需要在所以这些权重文件下选取最优的一个)
-gpu 0 :使用0号GPU
-iterations 100
-iterations参数与 lenet_solver.prototxt文件下的 test_iter参赛类似:
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100要遍历所有的待测试图像1万张
需要满足:-iterations * batch_size=10,000
batch_size是lenet_test.prototxt 中的测试数据层中指定的批处理的大小参数。
然后,在testLog文件夹下得到caffe.INFO的终端命令行输出记录 和
caffe.yang-System-Product-Name.yang.log.INFO.20181204-095911.3660 是测试日志文件;
caffe.INFO是终端屏幕输出;
终端部分输出如下(关注最后的Loss和accuracy):
...
I1204 09:59:16.654608 3660 caffe.cpp:281] Running for 100 iterations.
I1204 09:59:16.670982 3660 caffe.cpp:304] Batch 0, accuracy = 0.98
I1204 09:59:16.671051 3660 caffe.cpp:304] Batch 0, loss = 0.0443168
I1204 09:59:16.672643 3660 caffe.cpp:304] Batch 1, accuracy = 1
I1204 09:59:16.672709 3660 caffe.cpp:304] Batch 1, loss = 0.0175841
I1204 09:59:16.674376 3660 caffe.cpp:304] Batch 2, accuracy = 0.99
I1204 09:59:16.674437 3660 caffe.cpp:304] Batch 2, loss = 0.0308315
...
I1204 09:59:16.795164 3671 data_layer.cpp:73] Restarting data prefetching from start.
I1204 09:59:16.795873 3660 caffe.cpp:304] Batch 97, accuracy = 0.98
I1204 09:59:16.795882 3660 caffe.cpp:304] Batch 97, loss = 0.0427303
I1204 09:59:16.797765 3660 caffe.cpp:304] Batch 98, accuracy = 0.97
I1204 09:59:16.797775 3660 caffe.cpp:304] Batch 98, loss = 0.107767
I1204 09:59:16.798722 3660 caffe.cpp:304] Batch 99, accuracy = 0.99
I1204 09:59:16.798730 3660 caffe.cpp:304] Batch 99, loss = 0.0540964
I1204 09:59:16.798734 3660 caffe.cpp:309] Loss: 0.0391683
I1204 09:59:16.798739 3660 caffe.cpp:321] accuracy = 0.9879
I1204 09:59:16.798746 3660 caffe.cpp:321] loss = 0.0391683 (* 1 = 0.0391683 loss)可以看出程序对每一个Batch的准确率都进行了计算,最后得到了一个总的准确率;
当训练生成的存档模型不是很多的时候,可以对照验证数据Loss 小,accuracy高的区域,手动人工选取一个最优的模型;
如是模型存档快照比较多,可以利用测试数据集进行挑选模型,写脚本来遍历所有的模型,得到一个Loss小,accuracy高的模型;
一般而言,当数据多时,测试集合的loss最小和accuracy最高的 模型就越有可能是同一个,如果不是同一个,通常选取loss最小的模型泛化能力会好一些;
其实,训练集、验证集、测试集都只是对真是数据分布情况的采样,
从大数据量挑选的模型比从小数据量更有信心而已了;
下面在训练日志文件夹下 利用 7.2节中的parse_log.py解析训练日志caffe.yang-System-Product-Name.yang.log.INFO.20181203-184414.8457文件得到的 验证集合(TEST)的csv文件:
利用如下Python脚本画出: val_loss-iterNums val_accuracy-iterNums 画在一张图中:
val_loss_val_accuracy.py 如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 4 10:53:28 2018
@author: yang
"""
import pandas as pd
import matplotlib.pyplot as plt
val_log = pd.read_csv("caffeLeNetTrain20181203.log.test") #验证数据集
_, ax1 = plt.subplots()
ax1.set_title("val loss and val accuracy")
ax1.plot(val_log["NumIters"], val_log["loss"], 'g')
ax1.set_xlabel('iterations')
ax1.set_ylabel('val loss')
plt.legend(loc='center left')
ax2 = ax1.twinx()
ax2.plot(val_log["NumIters"], val_log["accuracy"], 'm')
ax2.set_ylabel('val accuracy')
plt.legend(loc='center right')
plt.show()
print('Done.')得到:val_loss_val_accuracy_vs_iterNums1.png

随着迭代次数的增加,模型在验证集上的loss下降,accuracy上升;所以可以选择35000次的模型进行部署;
我们这里在测试集上测试一下35000次迭代生成的模型快照,与上面的5000次迭代生成的模型快照作对比。
在终端输入:
/home/yang/caffe/build/tools/caffe test -model lenet_test.prototxt -weights ./snapshot/lenet_solver_iter_35000.caffemodel -gpu 0 -iterations 100 -log_dir ./testLog查看输出的最后三行:
I1204 14:58:12.377961 6560 caffe.cpp:309] Loss: 0.0267361
I1204 14:58:12.377966 6560 caffe.cpp:321] accuracy = 0.9904
I1204 14:58:12.377972 6560 caffe.cpp:321] loss = 0.0267361 (* 1 = 0.0267361 loss)
发现Loss 和accuracy确实比5000次迭代的更优了!
8.2评估模型性能
评估模型性能主要是时间和空间占用情况,即评估模型的一次前向传播所需要的运行时间和内存占用情况:
Caffe支持此评估,使用Caffe提供的工具:
/home/yang/caffe/build/tools/caffe time 命令
只要有模型网络描述文件.prototxt就可以:
在Caffe主目录 examples/mnist/下得到 lenet.prototxt文件,然后执行如下命令:
/home/yang/caffe/build/tools/caffe time -model lenet.prototxt -gpu 0部分输出如下:
yang@yang-System-Product-Name:~/caffe/data/mnist_Bengio$ /home/yang/caffe/build/tools/caffe time -model lenet.prototxt -gpu 0
/home/yang/caffe/build/tools/caffe: /home/yang/anaconda2/lib/libtiff.so.5: no version information available (required by /usr/local/lib/libopencv_imgcodecs.so.3.4)
I1204 15:12:33.080821 6687 caffe.cpp:339] Use GPU with device ID 0
I1204 15:12:33.266084 6687 net.cpp:53] Initializing net from parameters:
...
I1204 15:12:33.266204 6687 layer_factory.hpp:77] Creating layer data
I1204 15:12:33.266217 6687 net.cpp:86] Creating Layer data
I1204 15:12:33.266227 6687 net.cpp:382] data -> data
I1204 15:12:33.275761 6687 net.cpp:124] Setting up data
I1204 15:12:33.275779 6687 net.cpp:131] Top shape: 64 1 28 28 (50176)
I1204 15:12:33.275794 6687 net.cpp:139] Memory required for data: 200704
I1204 15:12:33.275801 6687 layer_factory.hpp:77] Creating layer conv1
I1204 15:12:33.275822 6687 net.cpp:86] Creating Layer conv1
I1204 15:12:33.275828 6687 net.cpp:408] conv1 <- data
I1204 15:12:33.275837 6687 net.cpp:382] conv1 -> conv1
I1204 15:12:33.680294 6687 net.cpp:124] Setting up conv1
I1204 15:12:33.680315 6687 net.cpp:131] Top shape: 64 20 24 24 (737280)
I1204 15:12:33.680322 6687 net.cpp:139] Memory required for data: 3149824
...
I1204 15:12:33.685878 6687 net.cpp:244] This network produces output prob
I1204 15:12:33.685887 6687 net.cpp:257] Network initialization done.
I1204 15:12:33.685910 6687 caffe.cpp:351] Performing Forward
I1204 15:12:33.703292 6687 caffe.cpp:356] Initial loss: 0
I1204 15:12:33.703311 6687 caffe.cpp:357] Performing Backward
I1204 15:12:33.703316 6687 caffe.cpp:365] *** Benchmark begins ***
I1204 15:12:33.703320 6687 caffe.cpp:366] Testing for 50 iterations.
I1204 15:12:33.705480 6687 caffe.cpp:394] Iteration: 1 forward-backward time: 2.14998 ms.
I1204 15:12:33.707129 6687 caffe.cpp:394] Iteration: 2 forward-backward time: 1.63258 ms.
I1204 15:12:33.709730 6687 caffe.cpp:394] Iteration: 3 forward-backward time: 2.58979 ms.
...
I1204 15:12:33.783918 6687 caffe.cpp:397] Average time per layer:
I1204 15:12:33.783921 6687 caffe.cpp:400] data forward: 0.0011584 ms.
I1204 15:12:33.783926 6687 caffe.cpp:403] data backward: 0.00117824 ms.
I1204 15:12:33.783929 6687 caffe.cpp:400] conv1 forward: 0.449037 ms.
I1204 15:12:33.783933 6687 caffe.cpp:403] conv1 backward: 0.251798 ms.
I1204 15:12:33.783936 6687 caffe.cpp:400] pool1 forward: 0.0626419 ms.
I1204 15:12:33.783941 6687 caffe.cpp:403] pool1 backward: 0.00116608 ms.
I1204 15:12:33.783943 6687 caffe.cpp:400] conv2 forward: 0.194311 ms.
I1204 15:12:33.783947 6687 caffe.cpp:403] conv2 backward: 0.190176 ms.
I1204 15:12:33.783965 6687 caffe.cpp:400] pool2 forward: 0.0201024 ms.
I1204 15:12:33.783969 6687 caffe.cpp:403] pool2 backward: 0.00117952 ms.
I1204 15:12:33.783972 6687 caffe.cpp:400] ip1 forward: 0.0706387 ms.
I1204 15:12:33.783977 6687 caffe.cpp:403] ip1 backward: 0.0717856 ms.
I1204 15:12:33.783980 6687 caffe.cpp:400] relu1 forward: 0.00906752 ms.
I1204 15:12:33.783984 6687 caffe.cpp:403] relu1 backward: 0.0011584 ms.
I1204 15:12:33.783988 6687 caffe.cpp:400] ip2 forward: 0.0247597 ms.
I1204 15:12:33.783993 6687 caffe.cpp:403] ip2 backward: 0.0221478 ms.
I1204 15:12:33.783996 6687 caffe.cpp:400] prob forward: 0.0119437 ms.
I1204 15:12:33.784000 6687 caffe.cpp:403] prob backward: 0.00113536 ms.
I1204 15:12:33.784006 6687 caffe.cpp:408] Average Forward pass: 0.938644 ms.
I1204 15:12:33.784010 6687 caffe.cpp:410] Average Backward pass: 0.637078 ms.
I1204 15:12:33.784014 6687 caffe.cpp:412] Average Forward-Backward: 1.61356 ms.
I1204 15:12:33.784021 6687 caffe.cpp:414] Total Time: 80.678 ms.
I1204 15:12:33.784029 6687 caffe.cpp:415] *** Benchmark ends ***
我的电脑的GPU是NVIDIA GeForce GTX 960 2G显存的,执行一次Lenet的前向传播,平均时间不到1ms
Average Forward pass: 0.938644 ms.
再来测试一下CPU下运行的时间:去掉以上命令中的 -gpu 0参数
输入:
/home/yang/caffe/build/tools/caffe time -model lenet.prototxt
结尾输出:
I1204 15:18:10.153908 6768 caffe.cpp:397] Average time per layer:
I1204 15:18:10.153916 6768 caffe.cpp:400] data forward: 0.00064 ms.
I1204 15:18:10.153939 6768 caffe.cpp:403] data backward: 0.0009 ms.
I1204 15:18:10.153951 6768 caffe.cpp:400] conv1 forward: 2.21126 ms.
I1204 15:18:10.153965 6768 caffe.cpp:403] conv1 backward: 3.18376 ms.
I1204 15:18:10.153981 6768 caffe.cpp:400] pool1 forward: 2.59676 ms.
I1204 15:18:10.153996 6768 caffe.cpp:403] pool1 backward: 0.0006 ms.
I1204 15:18:10.154012 6768 caffe.cpp:400] conv2 forward: 6.02428 ms.
I1204 15:18:10.154027 6768 caffe.cpp:403] conv2 backward: 4.72778 ms.
I1204 15:18:10.154043 6768 caffe.cpp:400] pool2 forward: 1.6211 ms.
I1204 15:18:10.154058 6768 caffe.cpp:403] pool2 backward: 0.00072 ms.
I1204 15:18:10.154073 6768 caffe.cpp:400] ip1 forward: 0.3852 ms.
I1204 15:18:10.154086 6768 caffe.cpp:403] ip1 backward: 0.2337 ms.
I1204 15:18:10.154150 6768 caffe.cpp:400] relu1 forward: 0.04076 ms.
I1204 15:18:10.154165 6768 caffe.cpp:403] relu1 backward: 0.0005 ms.
I1204 15:18:10.154181 6768 caffe.cpp:400] ip2 forward: 0.03236 ms.
I1204 15:18:10.154196 6768 caffe.cpp:403] ip2 backward: 0.01712 ms.
I1204 15:18:10.154213 6768 caffe.cpp:400] prob forward: 0.04284 ms.
I1204 15:18:10.154230 6768 caffe.cpp:403] prob backward: 0.02084 ms.
I1204 15:18:10.154249 6768 caffe.cpp:408] Average Forward pass: 12.9634 ms.
I1204 15:18:10.154259 6768 caffe.cpp:410] Average Backward pass: 8.19254 ms.
I1204 15:18:10.154268 6768 caffe.cpp:412] Average Forward-Backward: 21.2 ms.
I1204 15:18:10.154278 6768 caffe.cpp:414] Total Time: 1060 ms.
I1204 15:18:10.154287 6768 caffe.cpp:415] *** Benchmark ends ***
本台计算机的CPU是Intel® Core™ i7-6700K CPU @ 4.00GHz × 8 ,Caffe的基本线性代数子库使用的是OpenBLAS
平均一次前向传播需要 12.96ms的时间,远远比GPU的运算时间慢;
9.手写数字识别(模型部署)
有了训练好的模型,我们就可以用来识别手写数字了,这里测试用的是test数据集的图片和之前生成的test.txt文件列表:
下面是用来完成以上任务的recognize_digit.py
recognize_digit.py如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 4 15:29:44 2018
@author: yang
"""
import sys
sys.path.append('/home/yang/caffe/python')
import numpy as np
import cv2
import caffe
MEAN = 128
SCALE = 0.00390625
imglist = sys.argv[1] #第一个参数输入test.txt 文件路径
caffe.set_mode_gpu()
caffe.set_device(0)
net = caffe.Net('lenet.prototxt', './snapshot/lenet_solver_iter_36000.caffemodel', caffe.TEST)
net.blobs['data'].reshape(1, 1, 28, 28)
with open(imglist, 'r') as f:
line = f.readline()
while line:
imgpath, label = line.split()
line = f.readline()
image = cv2.imread(imgpath, cv2.IMREAD_GRAYSCALE).astype(np.float) - MEAN
image *= SCALE
net.blobs['data'].data[...] = image
output = net.forward()
pred_label = np.argmax(output['prob'][0])
print('Predicted digit for {} is {}'.format(imgpath, pred_label))
在终端执行:因为1万张图片太多,所以将屏幕的标准输出重定向lenet_model_test.txt文件:
test.txt 参数是 测试数据集的文件路径 和标签的列表
python recognize_digit.py test.txt >& lenet_model_test.txt如下是部分预测输出结果:
Predicted digit for mnist/test/005120_2.jpg is 2
Predicted digit for mnist/test/006110_1.jpg is 1
Predicted digit for mnist/test/004019_6.jpg is 6
Predicted digit for mnist/test/009045_7.jpg is 7
Predicted digit for mnist/test/004194_4.jpg is 4
Predicted digit for mnist/test/006253_7.jpg is 7
Predicted digit for mnist/test/000188_0.jpg is 0
Predicted digit for mnist/test/001068_8.jpg is 8
Predicted digit for mnist/test/007297_8.jpg is 8
Predicted digit for mnist/test/000003_0.jpg is 0
Predicted digit for mnist/test/009837_7.jpg is 7
Predicted digit for mnist/test/000093_3.jpg is 3
10.数据增强再训练
训练数据的增加参考:https://github.com/frombeijingwithlove/dlcv_for_beginners/tree/master/chap6/data_augmentation
这里因为Mnist是灰度图,所以我们就使用平移和旋转来增加数据:
10.1训练数据增加方法
在工作路径文件夹下将以上链接的run_augmentation.py 和 image_augmentation.py 下载下来:
run_augmentation.py如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 4 16:00:27 2018
@author: yang
"""
import os
import argparse
import random
import math
from multiprocessing import Process, cpu_count
import cv2
import image_augmentation as ia
def parse_args():
parser = argparse.ArgumentParser(
description='A Simple Image Data Augmentation Tool',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('input_dir',
help='Directory containing images')
parser.add_argument('output_dir',
help='Directory for augmented images')
parser.add_argument('num',
help='Number of images to be augmented',
type=int)
parser.add_argument('--num_procs',
help='Number of processes for paralleled augmentation',
type=int, default=cpu_count())
parser.add_argument('--p_mirror',
help='Ratio to mirror an image',
type=float, default=0.5)
parser.add_argument('--p_crop',
help='Ratio to randomly crop an image',
type=float, default=1.0)
parser.add_argument('--crop_size',
help='The ratio of cropped image size to original image size, in area',
type=float, default=0.8)
parser.add_argument('--crop_hw_vari',
help='Variation of h/w ratio',
type=float, default=0.1)
parser.add_argument('--p_rotate',
help='Ratio to randomly rotate an image',
type=float, default=1.0)
parser.add_argument('--p_rotate_crop',
help='Ratio to crop out the empty part in a rotated image',
type=float, default=1.0)
parser.add_argument('--rotate_angle_vari',
help='Variation range of rotate angle',
type=float, default=10.0)
parser.add_argument('--p_hsv',
help='Ratio to randomly change gamma of an image',
type=float, default=1.0)
parser.add_argument('--hue_vari',
help='Variation of hue',
type=int, default=10)
parser.add_argument('--sat_vari',
help='Variation of saturation',
type=float, default=0.1)
parser.add_argument('--val_vari',
help='Variation of value',
type=float, default=0.1)
parser.add_argument('--p_gamma',
help='Ratio to randomly change gamma of an image',
type=float, default=1.0)
parser.add_argument('--gamma_vari',
help='Variation of gamma',
type=float, default=2.0)
args = parser.parse_args()
args.input_dir = args.input_dir.rstrip('/')
args.output_dir = args.output_dir.rstrip('/')
return args
def generate_image_list(args):
filenames = os.listdir(args.input_dir)
num_imgs = len(filenames)
num_ave_aug = int(math.floor(args.num/num_imgs))
rem = args.num - num_ave_aug*num_imgs
lucky_seq = [True]*rem + [False]*(num_imgs-rem)
random.shuffle(lucky_seq)
img_list = [
(os.sep.join([args.input_dir, filename]), num_ave_aug+1 if lucky else num_ave_aug)
for filename, lucky in zip(filenames, lucky_seq)
]
random.shuffle(img_list) # in case the file size are not uniformly distributed
length = float(num_imgs) / float(args.num_procs)
indices = [int(round(i * length)) for i in range(args.num_procs + 1)]
return [img_list[indices[i]:indices[i + 1]] for i in range(args.num_procs)]
def augment_images(filelist, args):
for filepath, n in filelist:
img = cv2.imread(filepath)
filename = filepath.split(os.sep)[-1]
dot_pos = filename.rfind('.')
imgname = filename[:dot_pos]
ext = filename[dot_pos:]
print('Augmenting {} ...'.format(filename))
for i in range(n):
img_varied = img.copy()
varied_imgname = '{}_{:0>3d}_'.format(imgname, i)
if random.random() < args.p_mirror:
img_varied = cv2.flip(img_varied, 1)
varied_imgname += 'm'
if random.random() < args.p_crop:
img_varied = ia.random_crop(
img_varied,
args.crop_size,
args.crop_hw_vari)
varied_imgname += 'c'
if random.random() < args.p_rotate:
img_varied = ia.random_rotate(
img_varied,
args.rotate_angle_vari,
args.p_rotate_crop)
varied_imgname += 'r'
if random.random() < args.p_hsv:
img_varied = ia.random_hsv_transform(
img_varied,
args.hue_vari,
args.sat_vari,
args.val_vari)
varied_imgname += 'h'
if random.random() < args.p_gamma:
img_varied = ia.random_gamma_transform(
img_varied,
args.gamma_vari)
varied_imgname += 'g'
output_filepath = os.sep.join([
args.output_dir,
'{}{}'.format(varied_imgname, ext)])
cv2.imwrite(output_filepath, img_varied)
def main():
args = parse_args()
params_str = str(args)[10:-1]
if not os.path.exists(args.output_dir):
os.mkdir(args.output_dir)
print('Starting image data augmentation for {}\n'
'with\n{}\n'.format(args.input_dir, params_str))
sublists = generate_image_list(args)
processes = [Process(target=augment_images, args=(x, args, )) for x in sublists]
for p in processes:
p.start()
for p in processes:
p.join()
print('\nDone!')
if __name__ == '__main__':
main()image_augmentation.py 如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 4 15:59:29 2018
@author: yang
"""
import numpy as np
import cv2
crop_image = lambda img, x0, y0, w, h: img[y0:y0+h, x0:x0+w]
def random_crop(img, area_ratio, hw_vari):
h, w = img.shape[:2]
hw_delta = np.random.uniform(-hw_vari, hw_vari)
hw_mult = 1 + hw_delta
w_crop = int(round(w*np.sqrt(area_ratio*hw_mult)))
if w_crop > w - 2:
w_crop = w - 2
h_crop = int(round(h*np.sqrt(area_ratio/hw_mult)))
if h_crop > h - 2:
h_crop = h - 2
x0 = np.random.randint(0, w-w_crop-1)
y0 = np.random.randint(0, h-h_crop-1)
return crop_image(img, x0, y0, w_crop, h_crop)
def rotate_image(img, angle, crop):
h, w = img.shape[:2]
angle %= 360
M_rotate = cv2.getRotationMatrix2D((w/2, h/2), angle, 1)
img_rotated = cv2.warpAffine(img, M_rotate, (w, h))
if crop:
angle_crop = angle % 180
if angle_crop > 90:
angle_crop = 180 - angle_crop
theta = angle_crop * np.pi / 180.0
hw_ratio = float(h) / float(w)
tan_theta = np.tan(theta)
numerator = np.cos(theta) + np.sin(theta) * tan_theta
r = hw_ratio if h > w else 1 / hw_ratio
denominator = r * tan_theta + 1
crop_mult = numerator / denominator
w_crop = int(round(crop_mult*w))
h_crop = int(round(crop_mult*h))
x0 = int((w-w_crop)/2)
y0 = int((h-h_crop)/2)
img_rotated = crop_image(img_rotated, x0, y0, w_crop, h_crop)
return img_rotated
def random_rotate(img, angle_vari, p_crop):
angle = np.random.uniform(-angle_vari, angle_vari)
crop = False if np.random.random() > p_crop else True
return rotate_image(img, angle, crop)
def hsv_transform(img, hue_delta, sat_mult, val_mult):
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV).astype(np.float)
img_hsv[:, :, 0] = (img_hsv[:, :, 0] + hue_delta) % 180
img_hsv[:, :, 1] *= sat_mult
img_hsv[:, :, 2] *= val_mult
img_hsv[img_hsv > 255] = 255
return cv2.cvtColor(np.round(img_hsv).astype(np.uint8), cv2.COLOR_HSV2BGR)
def random_hsv_transform(img, hue_vari, sat_vari, val_vari):
hue_delta = np.random.randint(-hue_vari, hue_vari)
sat_mult = 1 + np.random.uniform(-sat_vari, sat_vari)
val_mult = 1 + np.random.uniform(-val_vari, val_vari)
return hsv_transform(img, hue_delta, sat_mult, val_mult)
def gamma_transform(img, gamma):
gamma_table = [np.power(x / 255.0, gamma) * 255.0 for x in range(256)]
gamma_table = np.round(np.array(gamma_table)).astype(np.uint8)
return cv2.LUT(img, gamma_table)
def random_gamma_transform(img, gamma_vari):
log_gamma_vari = np.log(gamma_vari)
alpha = np.random.uniform(-log_gamma_vari, log_gamma_vari)
gamma = np.exp(alpha)
return gamma_transform(img, gamma)
我们使用上面两个Python脚本文件,来增强 minst/train 文件夹下的5W万张图,生存25万张图,与之前的5万合并的到30万张图,即将数据集增加为原来的6倍!
关闭除了旋转和平移以外的一切选项:旋转范围设为正负15度:
在终端输入如下命令:
python run_augmentation.py mnist/train/ mnist/augmented 250000 --rotate_angle=15 --p_mirror=0 --p_hsv=0 --p_gamma=0这样会在mnist/augmented/ 文件夹下生成25万张增加平移和旋转绕动后的图,并且这些图的命名规则也与gen_caffe_imglist.py的解析规则一致,接下来生存这些图的文件和标签列表文件:
python gen_caffe_imglist.py mnist/augmented augmented.txt然后将训练集和新增加的集的文件与标签文件列表合并成:train_aug.txt:
cat train.txt augmented.txt > train_aug.txt然后为这个文件train_aug.txt单独建立一个lmdb文件夹:
因为扰动后的图片分辨率不一定是28*28了,所以必须在这个使用 --resize_widrh=28 和 --resize_height=28 ,把输入lmdb的图像尺寸固定为28*28;另外使用--shuffle将输入顺序大散;
/home/yang/caffe/build/tools/convert_imageset ./ train_aug.txt train_aug_lmdb --resize_width=28 --resize_height=28 --gray --shuffle然后将lenet_train_val.prototxt 复制一份 命名为lenet_train_val_aug.prototxt;
将lenet_train_val_aug.prototxt的输入训练数据层的数据原lmdb文件路径改为:
source: "train_aug_lmdb"
然后在工作文件夹下再创建 snapshot_aug文件夹,和一个train_aug_Log 存储日志信息的文件夹;
然后再复制一份lenet_solver.prototxt文件,命名为lenet_aug_solver.prototxt文件:
修该lenet_aug_solver.prototxt 文件的
net 参数为:net: "lenet_train_val_aug.prototxt"
snapshot参数为:snapshot_prefix: "snapshot_aug"
然后就可以开始训练了:训练日志输出到train_aug_Log文件夹下:
/home/yang/caffe/build/tools/caffe train -solver lenet_aug_solver.prototxt -gpu 0 -log_dir ./train_aug_Log最后几行的输出:
I1204 17:12:28.571137 5109 solver.cpp:414] Test net output #0: accuracy = 0.9911
I1204 17:12:28.571157 5109 solver.cpp:414] Test net output #1: loss = 0.0319057 (* 1 = 0.0319057 loss)
然后到train_aug_Log文件夹下将log文件的名字修改为mnist_train_with_augmentation.log;
没有增强数据前的训练日志在 trainLog文件夹下的mnist_train.log;
然后使用Caffe的plot_training_log.py 工具 画出这两次训练的一些对比图:
python /home/yang/caffe/tools/extra/plot_training_log.py
下面的指令画这两次训练的验证集的 accu vs iters图:
python /home/yang/caffe/tools/extra/plot_training_log.py 0 test_acc_vs_iters.png trainLog/mnist_train.log train_aug_Log/mnist_train_with_augmentation.log 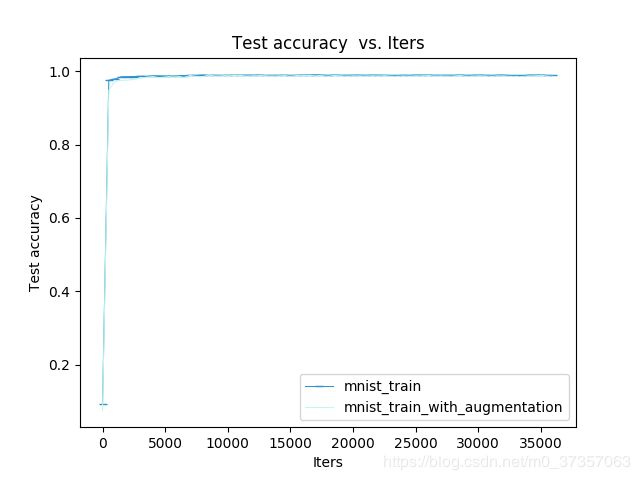
下面的指令画出这两次训练的在验证集合上的 loss vs iters 图;
python /home/yang/caffe/tools/extra/plot_training_log.py 2 test_loss_vs_iters.png trainLog/mnist_train.log train_aug_Log/mnist_train_with_augmentation.log 
10.2 接着上次训练状态再训练
原来的训练数据只有5万张,每个batch大小为50的情况下,迭代1000次就是一代(epoch);
增加后的数据量为30万张图,(50*6000=30W)迭代6000次才是一代,迭代到了36000次也才6代;
如果希望接着36000次迭代的状态继续训练,训练到20代,即最大迭代次数为120000
120000/6000=20(epooch)
将lenet_aug_solver.prototxt文件的 最大迭代次数:
max_iter: 36000
改为:max_iter: 120000
然后执行如下命令,就能接着36000次的训练状态继续训练:
python /home/yang/caffe/tools/caffe train -solver lenet_aug_solver.prototxt -snapshot_aug lenet_aug_solver_iter_36000.solverstate -gpu 0
/home/yang/caffe/build/tools/caffe train -solver lenet_aug_solver.prototxt -snapshot snapshot_aug/lenet_aug_solver_iter_36000.solverstate -gpu 0 -log_dir ./train_aug_Log训练输出局部:
I1204 18:44:26.388453 6406 solver.cpp:414] Test net output #0: accuracy = 0.9911
I1204 18:44:26.388473 6406 solver.cpp:414] Test net output #1: loss = 0.0305995 (* 1 = 0.0305995 loss)
I1204 18:44:26.388478 6406 solver.cpp:332] Optimization Done.
I1204 18:44:26.388481 6406 caffe.cpp:250] Optimization Done.
下面画一下accuracy-iterNums:
python /home/yang/caffe/tools/extra/plot_training_log.py 0 test_acc_vs_iters_120000.png train_aug_Log/mnist_train_augmentation_iter_120000.log
loss-iterNums:
python /home/yang/caffe/tools/extra/plot_training_log.py 2 test_loss_vs_iters_120000.png train_aug_Log/mnist_train_augmentation_iter_120000.log
10.3在训练的时候实时增加数据的方法:第三方实时扰动的Caffe层
注意:这样直接在原始样本的基础上做扰动来增加数据只是数据增加的一种方式之一,并不是最好的方案,因为增加的数据量有限,并且还要占用额外的硬盘存储空间;
最好的方式是在训练的时候对数据进行实时的扰动,这样等效于无限多的随即扰动。
Caffe的数据层已经自带了最基础的扰动方式:随即裁剪和镜像;
Github上有一些开源的第三方实现 实时扰动的Caffe层,会包含各种常见的数据扰动方式,在github上搜索:caffe augmentation:
比如:
https://github.com/kevinlin311tw/caffe-augmentation
11.caffe-augmentation
Caffe with real-time data augmentation
Data augmentation is a simple yet effective way to enrich training data. However, we don't want to re-create a dataset (such as ImageNet) with more than millions of images every time when we change our augmentation strategy. To address this problem, this project provides real-time training data augmentation. During training, caffe will augment training data with random combination of different geometric transformations (scaling, rotation, cropping), image variations (blur, sharping, JPEG compression), and lighting adjustments.
Realtime data augmentation
Realtime data augmentation is implemented within the ImageData layer. We provide several augmentations as below:
- Geometric transform: random flipping, cropping, resizing, rotation
- Smooth filtering
- JPEG compression
- Contrast & brightness adjustment
How to use
You could specify your network prototxt as:
layer {
name: "data"
type: "ImageData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "/home/your/imagenet_mean.binaryproto"
contrast_adjustment: true
smooth_filtering: true
jpeg_compression: true
rotation_angle_interval: 30
display: true
}
image_data_param {
source: "/home/your/image/list.txt"
batch_size: 32
shuffle: true
new_height: 256
new_width: 256
}
}
You could also find a toy example at /examples/SSDH/train_val.prototxt
Note: ImageData Layer is currently not supported in TEST mode
Caffe MNIST手写数字识别 训练_验证 测试 模型测试评估与选择 数据增强
参考:
https://github.com/frombeijingwithlove/dlcv_for_beginners