随机梯度下降

随机梯度下降法(Stochastic gradient descent, SGD),该算法是神经网络中用于的训练模型的一种常用算法。为了便于说明该算法,我们需要从感知机讲起。不想看基础知识的可以直接拉到文中最后面看吧。
感知机
可以把感知机想象成中学物理学过的简单的串联、并联电路,

由图我们再看一下感知机的公式,很简单的
y = 0 (当 w1*x1+w2*x2 <= θ)
y = 1 (当 w1*x1+w2*x2 > θ)x1和x2是我们输入值,w1和w2是权重值。两条路的乘积和如果小于一个θ(阈值或界限),y1的输出为0,大于θ则输出1。再细说一下这个就是计算机硬件电路中涉及到的“与门”。我们有了与门和非门,我们就可以设计出各种各样的电路门。
# 代码实现
def AND(x1, x2):
w1, w2, θ = 0.5, 0.5, 0.7
tmp = x1*w1 + x2*w2
if tmp <= theta:
return 0
elif tmp > theta:
return 1我们我们把神经网络中每个神经元节点看成一个上面的感知机(实际中没有怎么简单的),也就说每个节点都是一个电路门,基本单位就是与门或非门。我们可以通过与门和非门设计出硬件电路中所有的电路,那么我们神经网络算法也可以通过若干个神经元节点模拟出现实世界中任何数学模型。理论上是这么说的。

其实在上面的两个输入的感知机中,y1的θ阈值其实是有计算公式的,不是人为一开始设定的。这个计算公式我们称之为激活函数。
激活函数
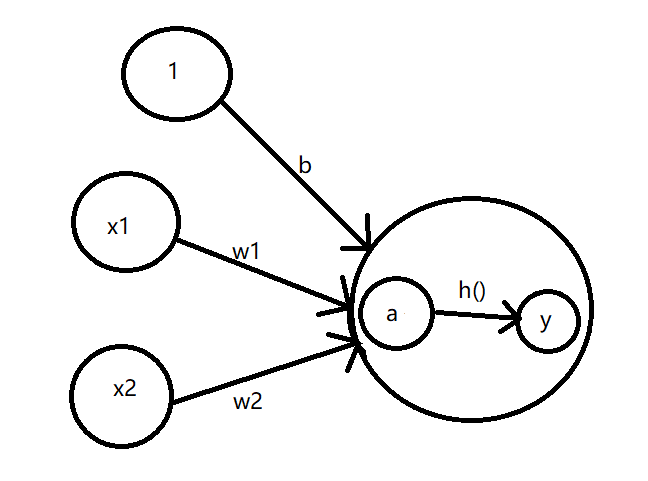
我们把上面两个输入的感知机的图完善一下,添加一个偏置量叫做b,把y1节点的内部放大,得到上面这张图。还记得上面讲到的阈值θ吧,一开说成一个界限值是为了方便理解,现在这里不再是了。我们是通过函数公式计算得到输出为0还是为1。
看图解释一下,a是w1*x1+w2*x2+1*b的值,通过函数h()计算得到y值作为最后的输出。这里多出来的b就是我们在学习神经网络中的偏置参数。看到这里应该没有什么难度,都比较好理解。那我们接着往下看。
刚才现身的函数h()是把输入信号的总和(a)转换为输出信号,我们一般称这种函数为激活函数。激活函数的作用在于决定如何来激活输入信号的总和。现在我们已经大概对激活函数有个认识了吧。我们先把上面那个h()公式写一下。
h(a) = 0 (当 w1*x1+w2*x2+1*b<=0)
h(a) = 1 (当 w1*x1+w2*x2+1*b>0)这里的b可正可负,谁也不知道。在这个小节点我们可以设置,但是实际中我们搭建的几十层神经网络时,每一层的节点数又依据输入数据维度以及计算规则等不确定的数目。换句话说数目庞大我们不能一一设定,都是一开始通过高斯分布的随机数进行初始化。
上面的h()是一种常见的激活函数,叫做阶跃函数。简单代码实现如下:
def step_function(x):
if x > 0:
return 1
return 0下图是阶跃函数的函数坐标图:

常见的激活函数还有sigmoid函数,简单代码实现如下:
import math
def sigm_function(x):
return 1/(1 + math.e**(-x))下图是两个激活函数的坐标图对比:

两种激活函数比较:
首先两者都是非线性函数,从宏观上看图形是相似的,但是在放大细看的时候,都应该能看出两者的差异。相比阶跃函数的突然性,sigmoid函数的平滑性对神经网络的学习具有重要意义。
其他激活函数还有恒等函数以及线性函数中的ReLU函数,softmax函数等等这几种常见。
# 恒等函数
def identity_function(x):
return x
# ReLU函数
def relu(x):
return max(0, x)
# softmax函数
import math
def softmax(a1,a2):
exp_a1 = math.e**a1
exp_a2 = math.e**a2
sum_exp = exp_a1 + exp_a2
y = exp_a1 / sum_exp
return y
softmax信号图
上面函数的代码实现都是针对一两个的输入值计算,遇到一个矩阵数据存入很多数据时则会失效。因此需要学习使用numpy库,以及简单的线性代数知识的矩阵加减乘除等知识点即可。这里就不过多的解释了。
输出层的激活函数选取:遇到回归问题可以采用恒等函数,二元分类函数可以使用sigmoid函数,多元分类则使用softmax函数。
看了半天也没涉及到随机梯度下降算法,感觉答非所问呀。随机梯度下降是神经网络的训练模型的一种算法,学习它之前我们有必要了解一下神经网络才知道为什么要用这种算法去训练模型。学东西我们要知其然,更要知其所以然。
损失函数
神经网络的学习是训练模型的过程,而训练模型的过程则是修改参数的过程。修改哪些参数?就是修改前面那张完善的感知机信号图中的权重w和偏置量b。前面说过神经网络在训练的时候,这些参数都是通过高斯分布去随机初始化,为什么不初始化为0大家可以自行百度查找一下具体原因,可能不太好理解。
首先是自己搭建好神经网络层数,然后接着开始初始化参数。输入训练集数据,经过权重偏置量的计算以及激活函数等得到结果。这是神经网络的第一次尝试,然后拿输出结果和实际值(标签)做比较得到误差值。然后把所有第一次跑过的数据预测结果和实际结果做除法得到我们模型的准确率。
我们可以把上面过程想象成一场考试,老师绞尽脑汁出题目然后把试卷发给学生测试,这个过程中老师在设计题目就相当于搭建神经网络模型;我们考试过程中去计算题目答案是训练过程;等老师把试卷发下来然后讲试卷,讲到自己写的错题和答案时对应上面的误差值;我们试卷得分就是准确率。
我们的考试得分就可以当作损失函数的一种变相的解释(损失函数和准确率不一样)。损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。我们给损失函数加个符号之后,我们就能把这个概念理解为多大程度上拟合,感觉数值越大越好(过拟合不行)。
损失函数和准确率的概念不要搞乱了,为什么需要损失函数可以参考这篇文章损失函数也有多种常见的函数。例如:均方误差、交叉熵误差。
均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和。

# 均方误差实现
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)然后是交叉熵误差的公式和代码:

# 交叉熵误差实现
def cross_entropy_error(y, t):
delta = 1e-7 # 防止y=0时计算报错
return -np.sum(t * np.log(y + delta))现在提一下“随机梯度下降”中的“随机”两个字是怎么来的,接着向下看。
mini-batch学习
mini-batch学习,mini就是迷你的意思,batch是批量的意思。记得前面说过理论上神经网络可以模拟出任何数学模型吗,理论上可以,但是实际中我们都是很接近那个模型,越想要接近那个模型,就越需要大量大量的训练数据做支撑。但是我们现在硬件设备处理能力跟不上数据量的需求上升的时候,我们就使用mini-batch学习方法。
记得中学数学学过的随机抽查吗?在大街上做调研的时候我们不是选取该地区所有人做样本,而是选取一小部分做样本当作对象进行调研访问。我们把训练集切割成多个小数据集(mini数据集),然后我们随机选取多个mini数据集拿去训练我们的神经网络。用一小部分数据去代表全体数据。虽然有误差,但是可以很大程度降低训练过程的成本。
随机梯度下降的随机就是随机选取mini数据集做代表去训练模型。batch是批处理,我们的数据不在是一个一个的输入,而是多维度的输入值。前面提到过要学习numpy和线性代数的矩阵操作就是在这里要用到的。
接着我们再说一下梯度下降。
梯度下降
损失函数告诉了我们模型此时有多差,但是却没有告诉我们该怎么去处理,无法进行下一步的优化,这时候我们就需要梯度来帮助我们指明方向。
先理清一下思路,由于我们初始化的参数构建出来的模型准确率达不到我们要求。因此我们就要是调整刚开始初始化的那些参数(权重w和偏置b),使其得到我们需要的最优参数,进而我们就能够得到非常好的模型,最后理想的准确率自然而然的就到手了。
现在我们出现的问题是什么?是初始化参数构建的模型不行,太差劲了。我们怎么知道的,是准确率告诉我们的,但是我们反向传播概念,我们会在下面介绍。我们可以反推,但是怎么反推呢?
这时候我们就需要梯度,损失函数的梯度来告诉我们去寻找损失函数最小的值,这样我们就能让数据和模型的拟合程度高。梯度是大学的高数上面的知识,了解梯度就需要先知道导数和微分以及偏导数。不要被高数吓到了,我们这里简单介绍一下,很容易理解的。
导数
导数表示某种变量的瞬间变化量,公式和代码如下:
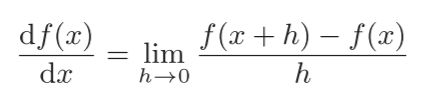
# 导数实现示例
def numerical_diff(f, x):
h = 10e-50
return (f(x+h) - f(x)) / h代码实现中我们不可能做到h=0,因为除0会报错,h过小又会导致编程语言出现精度问题,因此代码和实际存在一定误差。这里我突然想起了初三物理课的时候,我们写实验结果的时候都会先写一句,“在误差允许的范围内。。。”,误差在可接受范围就行了。
数值微分
微分公式是类似上面导数的公式,只是后面变了。
导数后缀:[f(x+h)-f(x)] / h
微分后缀:[f(x+h)-f(x-h)] / (2*h)# 数值微分实现
def numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x+h) - f(x-h)) / (2*h)如下图所示,我们利用微小的差分求导数的过程称为数值微分。

偏导数和梯度
偏导数就是有多个变量函数的导数,会求多元函数的偏导数之后,我们就自然会求解多元函数的梯度,也就是我们损失函数的梯度。求偏导数就是对每个变量单独分开就单数,然后进行加减,下面举个简单的例子,
f = x1^2 + x2^2
偏导数:f' = 2*x1 + 2*x2而梯度像

这样的由全部变量的偏导数汇总而成的向量称为梯度,梯度是矢量。
# 梯度计算实现
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和x形状相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h)的计算
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h)的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad因为梯度是矢量,所以有方向。而它的方向就是该点处的函数值降低的方向。严格地讲,梯度指示的方向是各点处的函数值减小最多的方向。在实际中的复杂的函数,梯度指示的方向基本上都不是函数值最小值的方向。但我们可以沿着它的方向能够最大限度地减小函数的值。因此在寻找函数的最小值的任务中,要以梯度的信息为线索来决定前进的方向。
在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,沿着新梯度方向前进, 如此反复,不断地沿梯度方向前进。通过不断地沿梯度方向前进, 逐渐减小函数值的过程就是梯度法。
梯度方包括梯度下降法和梯度上升法,求最大值就是上升法,但是我们把求最大值的方法前面加个负号就相当于求最小值,也就是梯度下降法。
随机梯度下降 = 随机 + 梯度下降。
到这里为止我们已经介绍了神经网络的节点,我们其实可以自由组合去构建各类电路节点来搭建自己的神经网络。权重w和偏置b是一开始随机初始化的,把mini训练集第一次过一下模型然后通过损失函数知道模型的好坏以及下一步该怎么走。
那下一步走的过程会是什么样呢?下一节会介绍神经网络的反向传播的过程,学习率以及如何具体的修改我们一开始初始化的参数。

绿海龟
绿海龟:海龟科海龟属的一种龟。亦称海龟,是各种海龟中体形较大的一种,其成龟背甲直线长度可达90到120厘米,体重可达100千克以上。因其体内脂富含主要食物,即海草的叶绿素而得名。它的腹甲为白色或黄白色,背甲则从赤棕含有亮丽的大花斑到墨色不等。识别法为背甲中央为五盾,左右列各为四盾,眼睛上方具鳞片一对。
绿海龟和其他海龟一样,除了上岸产卵外,终其一生都在大洋中渡过。它广泛分布于热带及亚热带海域,并产卵于温度达25℃以上的沙滩。为草食性动物,是海龟里唯一摄食较多海藻的种类。觅食区多为海草丰富的浅水区。幼龟偏肉食性,长大后变为杂食。一生中大多的时间都在海中生活,但演化过程中仍然保留了部分祖先的生活方式,所以必须回到陆地上产卵,繁育后代,形成了一种较独特的生活习性。广泛分布于太平洋、印度洋及大西洋温水水域。
保护级别:
EN——濒危物种。