基于相似学习的目标跟踪方法
目录
- SiamFC:ECCV2016
- SINT:CVPR2016
- CFNet:CVPR2017
- DSiam:ICCV2017
- EAST: ICCV2017
- SA-Siam:CVPR2018
- SiamRPN:CVPR2018
- SINT++:CVPR2018
- RASNet:CVPR2018
- DaSiamRPN:ECCV2018
- StructSiam:ECCV2018
- Siam-tri:ECCV2018
- 各模型实验结果对比
目前目标跟踪方法主要分为两大类:1.相关滤波,2.深度学习。在对两种方法进行了一定的了解后,虽然说现在深度学习、AI有很大的“泡沫”,且相关滤波与深度学习结合可以得到很好的跟踪效果,但是我还是以深度学习为主去研究目标跟踪(- -||)。而基于孪生网络的目标跟踪方法现在几乎可以自成一派,在此进行一下总结,整理知识,启迪自己。
SiamFC:ECCV2016
文章链接
鼻祖一样的文章,模型的结构如图所示。
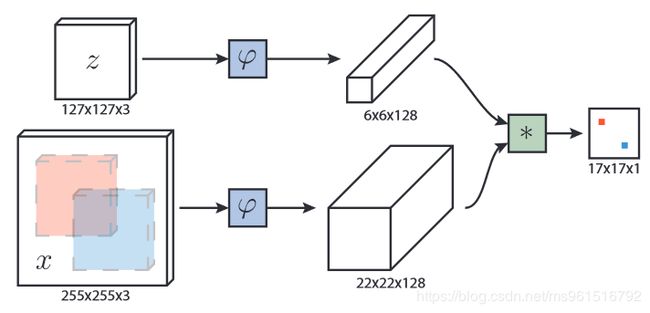
特征提取部分使用AlexNet的结构:

损失函数使用logistics,训练集使用ILSVRC2015。
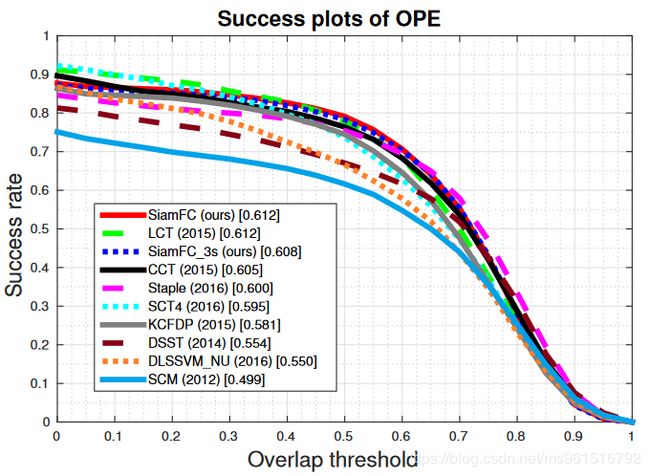
实验结果如下图所示:
1.OTB-2013
2.VOT-2014
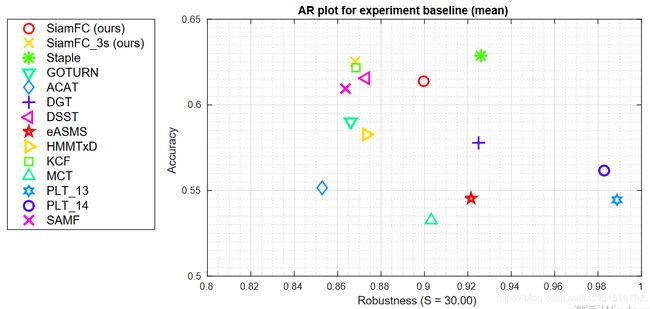 3.VOT-2015
3.VOT-2015

SINT:CVPR2016
文章链接
作为和SiamFC同一年发表的基于相似学习的论文,当然要对比一下啦(这篇论文的发表时间比Siamese-fc早)。模型结构如图所示(吐槽一下配色):
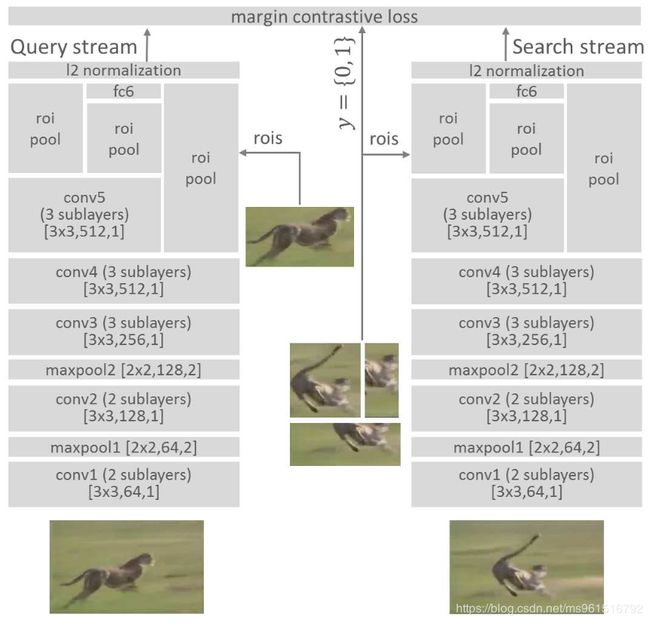 那么本文和SiamFC的区别在于哪呢?
那么本文和SiamFC的区别在于哪呢?
1.网络结构不同。在SiamFC中使用的是AlexNet作为特征提取网络,而本文是作者自己设计的特征提取网络,同时加入了ROI pooling层。本文中提到,跟踪问题作为一个定位问题,不应使用过多的max pooling,过多的max pooling会导致定位不准确。但是max pooling的优势在于对于输入的局部形变具有不变性,也不能弃之不用,故设计为两个max pooling层。
2.损失函数不同。SiamFC中使用logistics作为损失函数,本文中使用如下的损失函数:
L ( x j , x k , y j k ) = 1 2 y j k D 2 + 1 2 ( 1 − y j k ) m a x ( 0 , ε − D 2 ) L(x_j,x_k,y_{jk})=\frac{1}{2}y_{jk}D^2+\frac{1}{2}(1-y_{jk})\ max(0,\varepsilon-D^2) L(xj,xk,yjk)=21yjkD2+21(1−yjk) max(0,ε−D2)
D = ∣ ∣ f ( x j ) − f ( x k ) ∣ ∣ 2 D=||f(x_j)-f(x_k)||_2 D=∣∣f(xj)−f(xk)∣∣2
3.训练数据集不同。SiamFC中使用ILSVRC2015,SINT中使用ALOV。
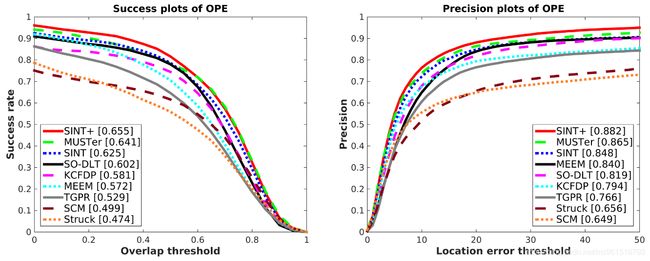
实验结果
1.OTB-2013
CFNet:CVPR2017
文章链接
模型结构如图所示:
 本模型与SiamFC的区别在于:
本模型与SiamFC的区别在于:
在SiamFC中分数使用下式计算:
s c o r e s = f ( x ) ∗ f ( z ) score_{s}=f(x)*f(z) scores=f(x)∗f(z)
在CFNet中分数使用下式计算:
s c o r e c = s ⋅ w ( f ( x ) ) ∗ f ( z ) + b score_{c}=s·w(f(x))*f(z)+b scorec=s⋅w(f(x))∗f(z)+b
这里 s s s代表尺度参数, w w w代表CF操作, b b b则是偏置项。
实验结果:
DSiam:ICCV2017
文章链接
模型的整体结构如图:
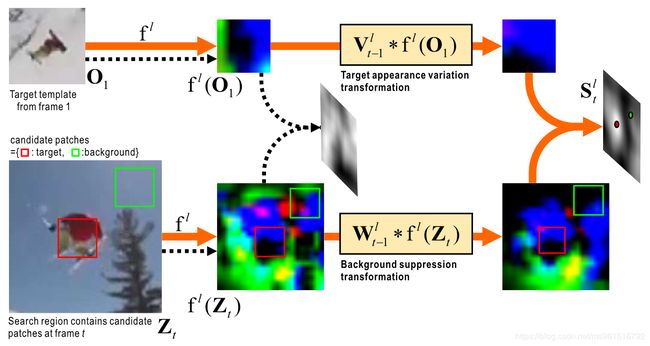
本文针对SiamFC模型进行改进,从上图中我们可以看出,首先,作者添加了两个模块:①. V V V,②. W W W,其中 V V V被称作“target appearance variation transformation”,用于使模板桢相对于当前帧的前些帧变得平滑。 W W W被称作“background suppression transformation”,目的是在当前帧的特征图中“高亮”目标,抑制背景信息。则本模型中的分数通过下式计算:
s c o r e t l = ( V t − 1 l ⋆ f l ( x ) ) ∗ ( W t − 1 l ⋆ f l ( z ) ) score_{t}^{l}=(V_{t-1}^{l}\star f^{l}(x))*(W_{t-1}^{l}\star f^{l}(z)) scoretl=(Vt−1l⋆fl(x))∗(Wt−1l⋆fl(z))
公式中的 ⋆ \star ⋆代表循环卷积操作, l l l代表层, t t t代表帧。 V V V和 W W W都使用正则线性回归进行训练,并且在跟踪过程中在线更新,参考下图可以更容易理解。更具体的可以参考我的另一篇博客。

作者的另一个创新点在于提出了一个自适应聚合各个层的特征的方法(elementwise multi-layer fusion),实质上是训练一个矩阵 γ \gamma γ,矩阵中的数值代表不同特征图的不同位置的权重,则模型最终得到的分数如下:
s c o r e t = ∑ l ∈ L γ l ⊙ s c o r e t l score_t=\sum_{l\in L}\gamma^l \odot score_t^l scoret=l∈L∑γl⊙scoretl
∑ l ∈ L γ l = 1 m s × n s \sum_{l\in L}\gamma^l=1_{m_s\times n_s} l∈L∑γl=1ms×ns
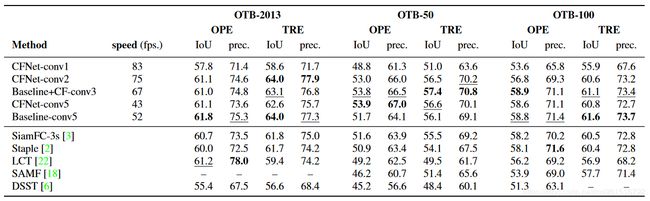
训练数据集使用ILSVRC2015,模型的实验结果如下:
1.OTB-2013

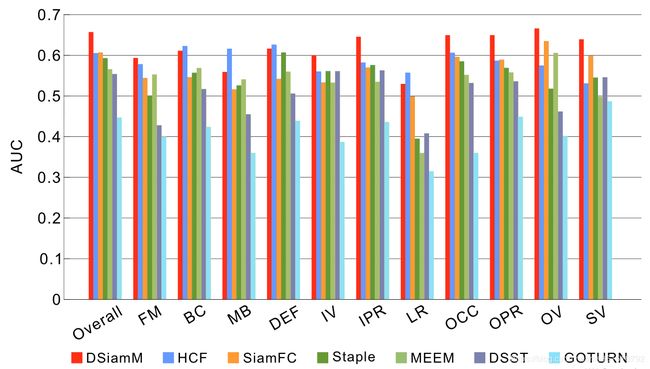
2.VOT-2015

EAST: ICCV2017
文章链接
模型结构如下图所示。
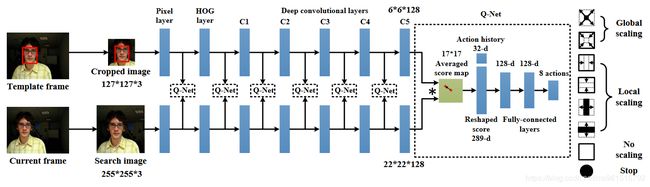
本文与SiamFC的区别在于设计了一个Q-Net,用于“早停”。在SiamFC中,所有帧都用conv5的特征去检测,EAST的出发点是(外观相似或不运动的)简单帧用简单特征如像素边缘就可以定位,(经历较大外观变化的)复杂帧才需要不变性更强的深度特征进行定位。
如何判读使用当前层特征得到的检测结果是否足够好(是否要使用下一层特征),作者提出了使用强化学习的策略。
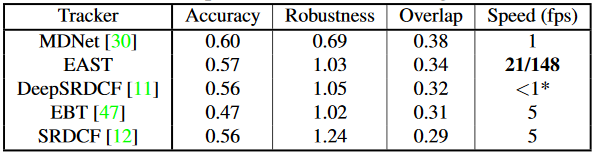
训练数据集使用ILSVRC2015,实验结果如下:
1.OTB-50
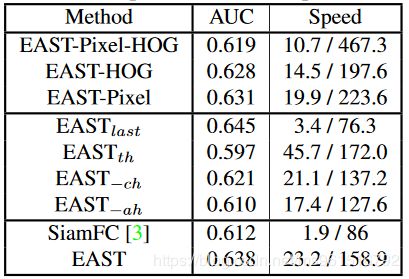
 2.OTB-100
2.OTB-100

3.VOT-2015
SA-Siam:CVPR2018
文章链接
模型的整体结构如图所示:
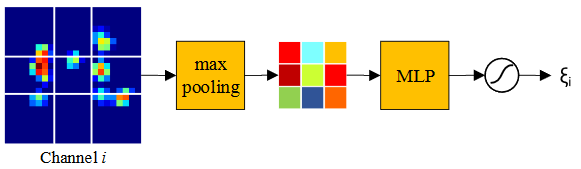
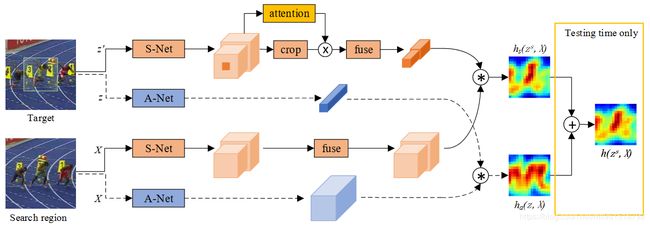 本文的创新点在于提出了一个结合Semantic features(语义特征)和Appearance features(表征特征)的模型,其实类似于一个双路模型,为了保持这两种特征的异质性,这两路特征要分别训练,训练语义特征的网络叫做S-Net,训练表征特征的网络叫做A-Net。作者还在S-Net中加入了一个chanel attention机制,如下图所示。
本文的创新点在于提出了一个结合Semantic features(语义特征)和Appearance features(表征特征)的模型,其实类似于一个双路模型,为了保持这两种特征的异质性,这两路特征要分别训练,训练语义特征的网络叫做S-Net,训练表征特征的网络叫做A-Net。作者还在S-Net中加入了一个chanel attention机制,如下图所示。
本文的训练数据集使用ILSVRC2015,实验结果如下:
1.OTB
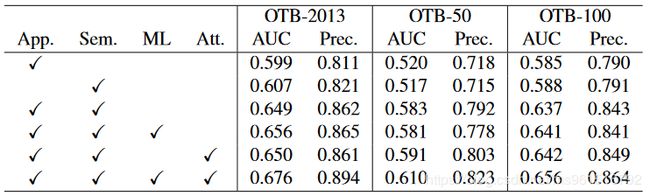
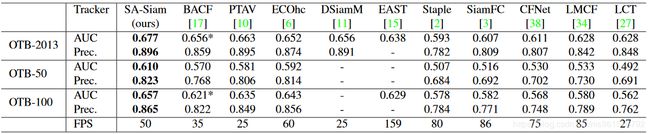
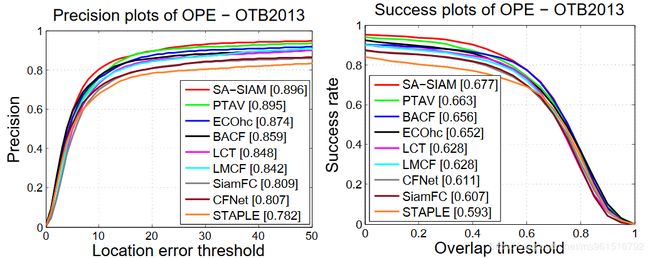
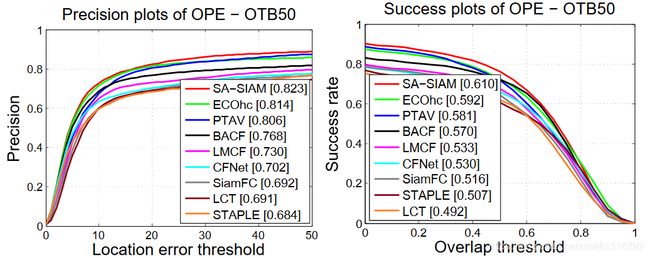
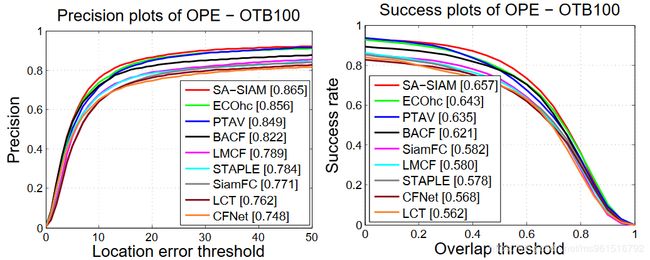
2.VOT-2015
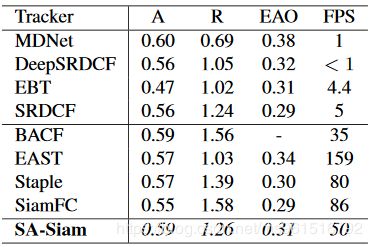
3.VOT-2016

4.VOT-2017

SiamRPN:CVPR2018
文章链接
模型的整体结构如图所示:
 本文的创新点在于,将Siamese Network与RPN结合。模型的上支用于分类(二分类:前景or背景),下支用于回归出目标的位置。
本文的创新点在于,将Siamese Network与RPN结合。模型的上支用于分类(二分类:前景or背景),下支用于回归出目标的位置。

在跟踪的过程中,我觉得有一个亮点。模型通过第一帧信息预测出一个权重,用于后续帧中的跟踪。这样可以使模型针对不同的视频序列得到不同的侧重,相当于一个简化了的在线学习。
本文的训练集采用ILSVRC2015和Youtube-BB,实验结果如下:
1.OTB-2015
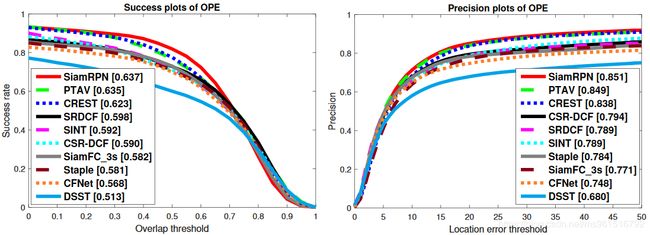 2.VOT-2015
2.VOT-2015
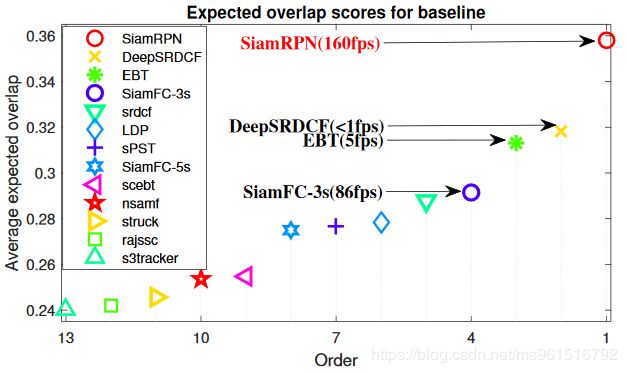

3.VOT-2016
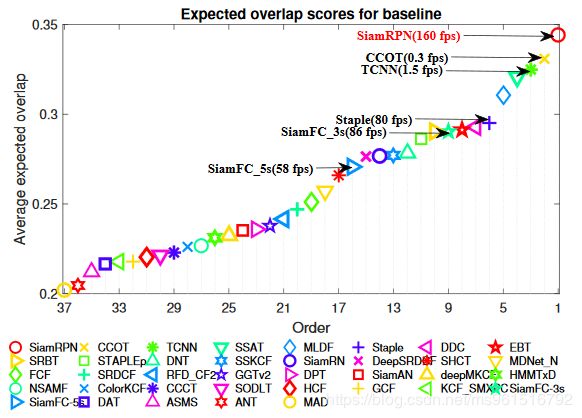
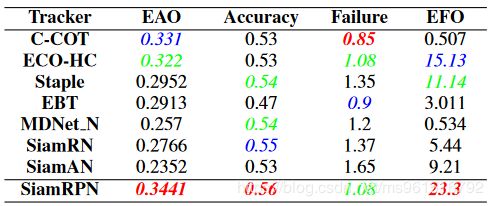

4.VOT-2017

SINT++:CVPR2018
文章链接
模型的整体结构如图所示:

本文在SINT的基础上进行改进,加入了VAE和强化学习。
首先,使用VAE来生成positive sample,如上图中右下角。 然后,使用HPTN网络将得到的positive sample变得更加hard,即:添加遮挡。那么问题就来了,(1).我们要遮挡目标物体中的哪部分?(2).用哪部分去遮挡(1)中的部分?
这两个问题有一个共性,就是要locate one image region。locate的过程可以视为一个MDP(马尔科夫决策过程),MDP问题可以使用强化学习知识来解决。state就是当前得到的特征图,可选择的action如下图:

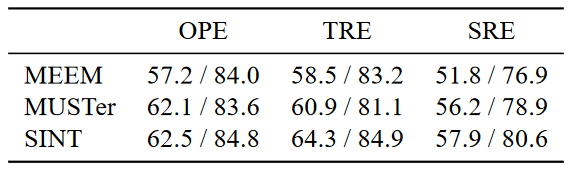
模型的训练数据是一直变化的。作者在对OTB数据集进行评估时,使用VOT数据集进行训练,在对VOT数据集进行评估时,使用VOT中不进行评测的数据和ILSVRC2015数据集进行训练。
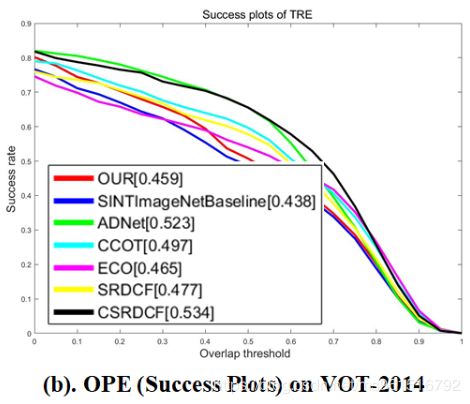
模型的实验结果如下:
1.OTB-50(OTB-2013)
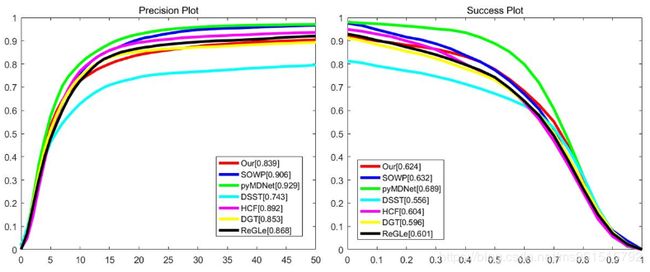
2.OTB-100(OTB-2015)
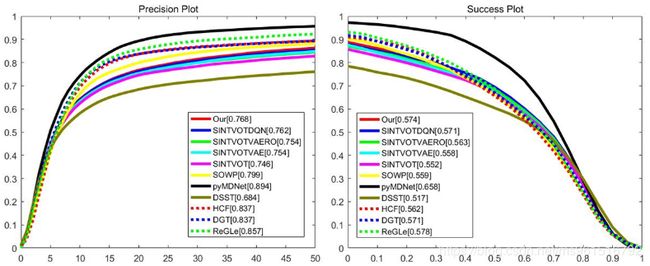
3.VOT-2014(到底是OPE还是TRE?)
RASNet:CVPR2018
文章链接
模型的整体结构如图所示:
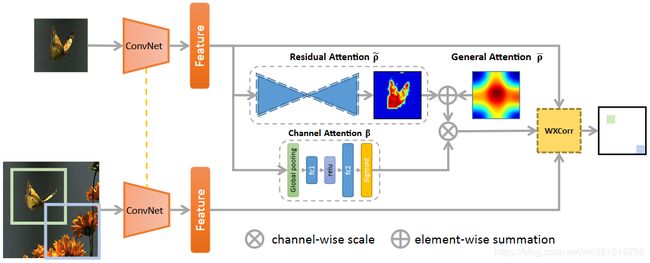
本文的创新在于在SiamFC中加入了三种注意力机制,作者将这三种注意力统称为“full attention”。
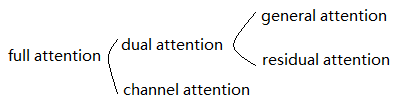
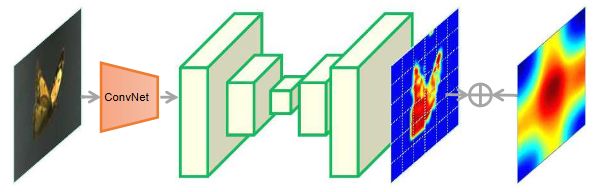
其中,general attention负责编码所有训练样本的共性;residual attention负责学习每种不同的跟踪物体之间的差异性;channel attention负责使模型适应于不同的contexts。
本文训练集使用ILSVRC2015,实验结果如下:
1.OTB
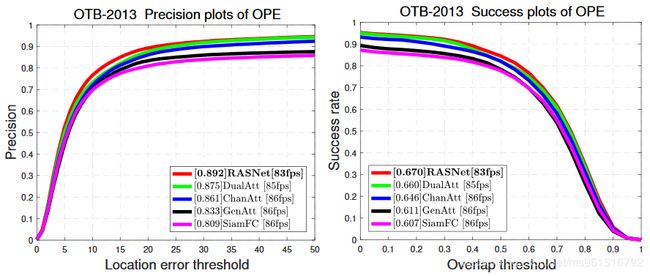
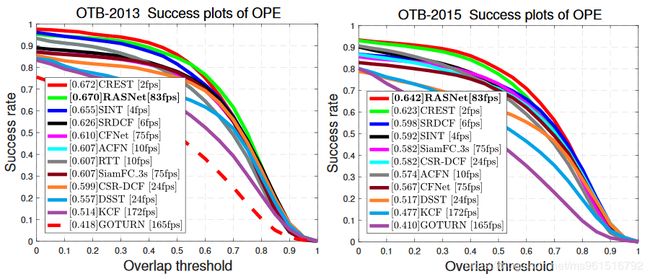 2.VOT-2015
2.VOT-2015
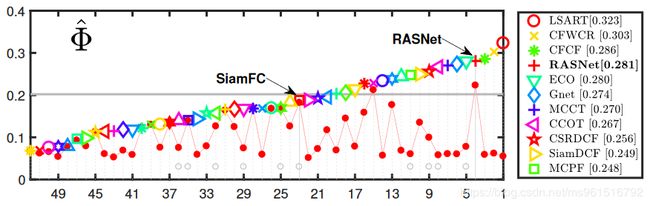
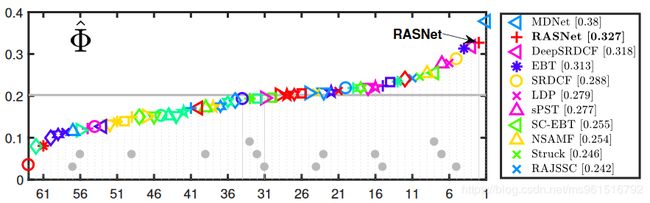 3.VOT-2017
3.VOT-2017
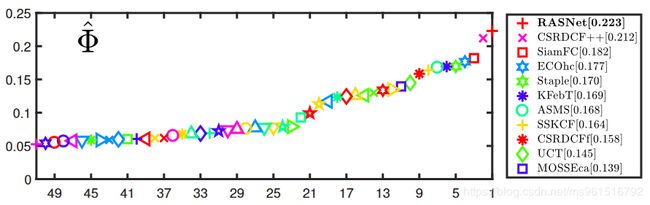
DaSiamRPN:ECCV2018
文章链接
本文首先分析了已有的相似学习模型的缺点:
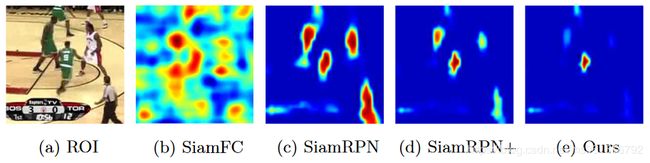 如上图所示,是几个模型对ROI提取出的特征图。论文中提到,造成这种现象的原因是,在目标周围的背景信息中,非语义背景(即真正的“背景”信息,如地板、天空等)占据了主要部分,语义背景(背景中的人、狗等实体,我是这么理解的)占据了极少一部分。这种不平衡的分布使得模型趋向于去学习到一个区分前景(目标+语义背景)和背景(非语义背景)的模型,而不是学习一个实例级别的表示方法。为了处理这个问题,作者在训练集中添加了三类样本对,提高模型的学习效果,具体如下。
如上图所示,是几个模型对ROI提取出的特征图。论文中提到,造成这种现象的原因是,在目标周围的背景信息中,非语义背景(即真正的“背景”信息,如地板、天空等)占据了主要部分,语义背景(背景中的人、狗等实体,我是这么理解的)占据了极少一部分。这种不平衡的分布使得模型趋向于去学习到一个区分前景(目标+语义背景)和背景(非语义背景)的模型,而不是学习一个实例级别的表示方法。为了处理这个问题,作者在训练集中添加了三类样本对,提高模型的学习效果,具体如下。
 文中还提到了一种新的选择最优bbox的标准,就是当前位置 p k p_{k} pk和模板 z z z计算相似度之后,减去当前位置与search region中其他位置的相似度的加权和。
文中还提到了一种新的选择最优bbox的标准,就是当前位置 p k p_{k} pk和模板 z z z计算相似度之后,减去当前位置与search region中其他位置的相似度的加权和。
本文的最后一个创新点是,当模型跟踪失败的时候,模型采取一种“局部-全局”增大search region的策略去重新跟踪目标。至于如何使用score判断是否失败,文中没有详细的描述。
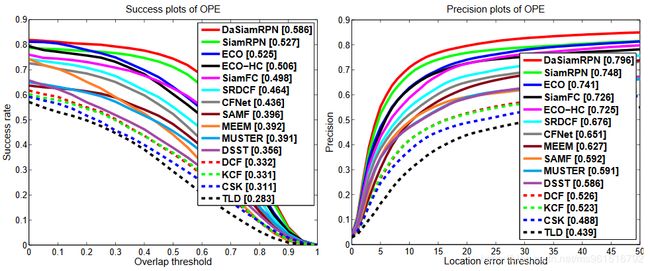
本文的训练数据使用ILSVRC2015、Youtube-BB、ImageNet Detection和COCO,实验结果如下:
1.OTB-2015
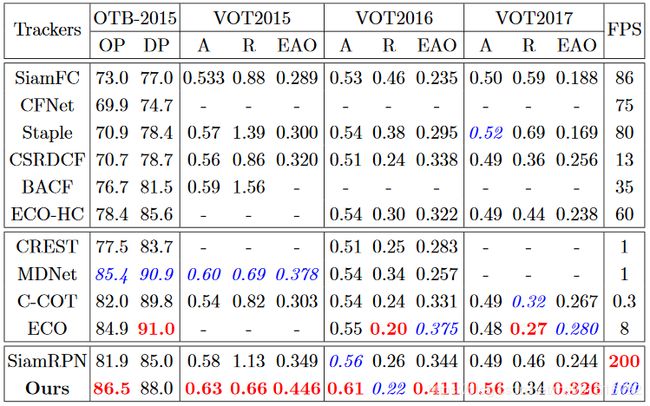 2.VOT-2016
2.VOT-2016
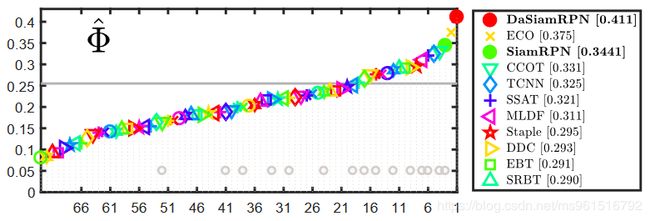 3.VOT-2017
3.VOT-2017
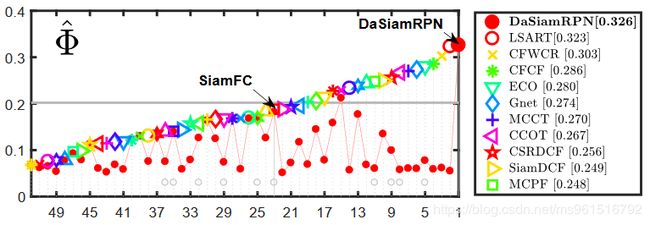 4.UVA20L
4.UVA20L
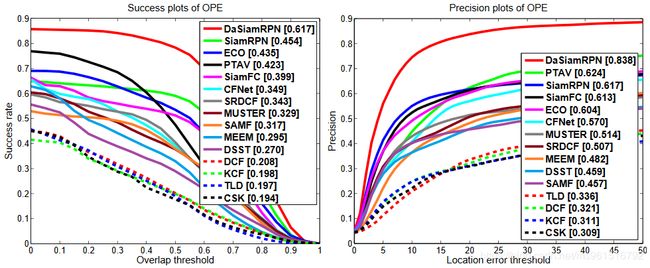 5.UVA123
5.UVA123
StructSiam:ECCV2018
文章链接
本文的模型结构如下图所示:
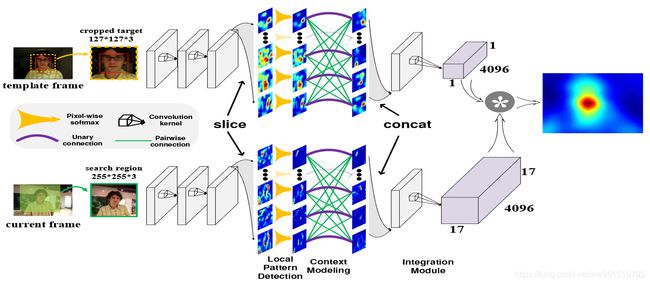 本文的改进我觉得十分新颖:“每张特征图学习跟踪目标的一个局部结构”,模板经过卷积后得到 1 × 1 × 4096 1\times 1\times 4096 1×1×4096大小的特征图,每张特征图代表该物体的一个属性(特征),基于此特征图做相似计算。
本文的改进我觉得十分新颖:“每张特征图学习跟踪目标的一个局部结构”,模板经过卷积后得到 1 × 1 × 4096 1\times 1\times 4096 1×1×4096大小的特征图,每张特征图代表该物体的一个属性(特征),基于此特征图做相似计算。
从上图来看,我们可以知道,文中主要有三个新增加的部分,分别是“Local Pattern Detection”、“Context Modeling”和“Integration Module”。
“Local Pattern Detection"部分是通过两个卷积层( 11 × 11 11\times 11 11×11和 5 × 5 5\times 5 5×5)实现的,输出的每张特征图代表一个局部特征。
“Context Modeling”部分通过“消息传递”机制实现,使用的是CRF(条件随机场)。作用是压制背景噪声、加强特征。
“Integration Module”部分通过 6 × 6 6\times 6 6×6卷积核实现,将模板帧的特征图由 6 × 6 × 4096 6\times 6\times 4096 6×6×4096变为 1 × 1 × 4096 1\times 1\times 4096 1×1×4096(其实就是变成了一个向量,向量中的每个值代表该物体的一个属性,和全局均值池化类似)。
由于要学习部分特征,作者选择使用ILSVRC2014和ALOV作为训练数据集,模型的实验结果如下所示:
1.OTB-2013
87.4% 0.638 45FPS
2.OTB-2015
85.1% 0.621 45FPS
3.VOT-2016


Siam-tri:ECCV2018
文章链接
模型结构如下图所示:
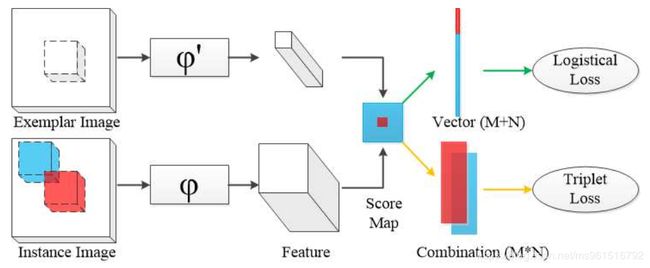
本模型与SiamFC的区别在于:提出了一种不同于SiamFC的损失函数。
在SiamFC中的损失函数如下:
L l ( Y , V ) = ∑ x i ∈ X w i l o g ( 1 + e − y i ⋅ v i ) L_l(Y,V)=\sum_{x_i \in X}w_ilog(1+e^{-y_i \centerdot v_i}) Ll(Y,V)=xi∈X∑wilog(1+e−yi⋅vi)
作者说,这个损失函数不够好,因为它只考虑了每个instance(啥是instance?比如模板经过特征提取后得到6×6的特征图 f e f_e fe,搜索区域经过特征提取后得到22×22的特征图 f s f_s fs,我们使用6×6的特征图当做卷积核在22×22的特征图上进行卷积得到17×17的分数矩阵,则在卷积的过程中 f s f_s fs中的每一个6×6区域在原图上的对应区域就是一个instance,而对应“+1”标签的称为positive instance,“-1”标签的称为negative instance)是否足够正确,而忽略了positive instance和negative instance之间的关系。
文中提出使用下式的损失函数:
L t ( V p , V n ) = − 1 / ( M N ) ∑ i M ∑ j N l o g p r o b ( v p i , v n j ) L_t(V_p,V_n)=-1/(MN)\sum_{i}^{M}\sum_{j}^{N}log\ prob(vp_i,vn_j) Lt(Vp,Vn)=−1/(MN)i∑Mj∑Nlog prob(vpi,vnj)
p r o b ( v p i , v n j ) = e v p i / ( e v p i + e v n j ) prob(vp_i,vn_j)=e^{vp_i}/(e^{vp_i}+e^{vn_j}) prob(vpi,vnj)=evpi/(evpi+evnj)
作者还通过梯度计算公式对比了两种损失函数(以下为两种损失函数的梯度中不同的部分,并不是全部的梯度公式):
∂ T l ∂ v p = − 1 2 ( 1 + e v p ) , ∂ T l ∂ v n = 1 2 ( 1 + e − v n ) \frac{\partial T_l}{\partial vp}=-\frac{1}{2(1+e^{vp})},\ \ \ \ \frac{\partial T_l}{\partial vn}=\frac{1}{2(1+e^{-vn})} ∂vp∂Tl=−2(1+evp)1, ∂vn∂Tl=2(1+e−vn)1
∂ T t ∂ v p = − 1 1 + e v p − v n , ∂ T t ∂ v n = 1 1 + e v p − v n \frac{\partial T_t}{\partial vp}=-\frac{1}{1+e^{vp-vn}},\ \ \ \ \frac{\partial T_t}{\partial vn}=\frac{1}{1+e^{vp-vn}} ∂vp∂Tt=−1+evp−vn1, ∂vn∂Tt=1+evp−vn1
从中我们可以看出本文中的损失函数在计算positive instance和negative instance的梯度时,都能考虑到两种不同的instance的联系,这样利于得到更好的跟踪模型。
文章的训练数据集采用ILSVRC2015,实验结果如下所示。
1.OTB-2013

2.OTB-其他
 3.VOT-2017
3.VOT-2017

各模型实验结果对比
| 发表源 | OTB2013 | OTB2015 | TB50 | FPS | 是否实时 | 训练数据集 | |
|---|---|---|---|---|---|---|---|
| SiamFC3s | ECCV2016 | 0.608 | 0.582 | 0.516 | 86 | √ | ILSVRC2015 |
| SiamFC5s | ECCV2016 | 0.612 | - - - | - - - | 58 | √ | ILSVRC2015 |
| SINT | CVPR2016 | 0.635 | 0.592 | - - - | 4 | × | ALOV |
| CFNet | CVPR2017 | 0.610 | 0.589 | 0.538 | 75 | √ | ILSVRC2015 |
| DSiam | ICCV2017 | 0.656 | - - - | - - - | 25 | √ | ILSVRC2015 |
| EAST | ICCV2017 | 0.638 | - - - | - - - | 83 | √ | ILSVRC2015 |
| 2 SA-Siam | CVPR2018 | 0.677 | 0.657 | 0.610 | 50 | √ | ILSVRC2015 |
| SiamRPN | CVPR2018 | - - - | 0.637 | - - - | 200 | √ | ILSVRC2015 Youtube-BB |
| SINT++ | CVPR2018 | 0.624 | 0.574 | - - - | - - - | - - - | ILSVRC2015 VOT2013 VOT2014 VOT2016 |
| 3 RASNet | CVPR2018 | 0.670 | 0.642 | - - - | 83 | √ | ILSVRC2015 |
| 1 DaSiamRPN | ECCV2018 | >ECO | >ECO | >ECO | 160 | √ | ILSVRC2015 Youtube-BB ImageNet Detection COCO |
| StructSiam | ECCV2018 | 0.638 | 0.621 | - - - | 45 | √ | ILSVRC2014 ALOV |
| SiamFC3s-tri | ECCV2018 | 0.615 | 0.590 | 0.531 | 86 | √ | ILSVRC2015 |
| ↓目前超强的模型↓ | |||||||
| ECO | CVPR2017 | 0.709 | 0.691 | 0.643 | 6 | × | - - - |
| MDNet | CVPR2016 | 0.708 | 0.678 | 0.645 | 1 | × | - - - |