【目标跟踪】相机运动补偿
文章目录
- 一、前言
- 二、简介
- 三、改进思路
-
- 3.1、状态定义
- 3.2、相机运动补偿
- 3.3、iou和ReID融合
- 3.4、改进总结
- 四、相机运动补偿
一、前言
- 目前 MOT (Multiple Object Tracking) 最有效的方法仍然是 Tracking-by-detection。
- 今天给大家分享一篇论文 BoT-SORT。论文地址 ,论文声称很牛*,各种屠榜,今天我们就来一探究竟。
- 主要是分享论文提出的改进点以及分享在自己的算法中如何去运用。
二、简介
Tracking-by-detection 成为 MOT 任务中最有效的范式。Tracking-by-detection 包含一个步骤检测步骤,然后是一个跟踪步骤。跟踪步骤通常由2个主要部分组成:
(1)运动模型和状态估计,用于预测后续帧中轨迹的边界框。卡尔曼滤波器 (KF) 是此任务的主流选择。
(2)将新帧检测与当前轨迹集相关联。对于步骤2:有2种主要的方法用于处理关联任务:
- 目标的定位,主要是预测轨迹边界框和检测边界框之间的 IoU。(SORT)
- 目标的外观模型和解决 Re-ID 任务。(DeepSORT)
在许多复杂的场景中,预测边界框的正确位置可能会由于相机运动而失败,这导致2个相关边界框之间的重叠率低,最终导致跟踪器性能低下。
作者通过采用传统的图像配准来估计相机运动,通过适当地校正卡尔曼滤波器来克服这个问题。这里将此称为相机运动补偿(CMC)。
三、改进思路
3.1、状态定义
x, y, w, h = box.centerX, box.centerY, box.width, box.height
(1) SORT,状态向量被选择为7元组:

s = w * h, r = h / w
(2) DeepSORT,状态向量被选择为8元组:
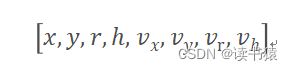
随着镜头移动或者物体与相机的相对运动,物体的长宽比也是会发生变化的。
(3) BoT-SORt 状态向量:
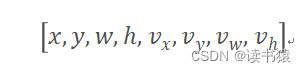
作者通过实验发现,直接估计边界框的宽度和高度会可以得到更好的性能。
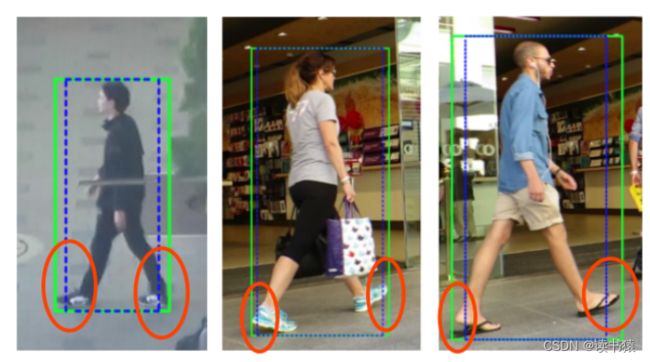
蓝色框 DeepSORT 绿色框 BoT-SORT
且Q、R设置为与当前状态有关。具体设置如下图:
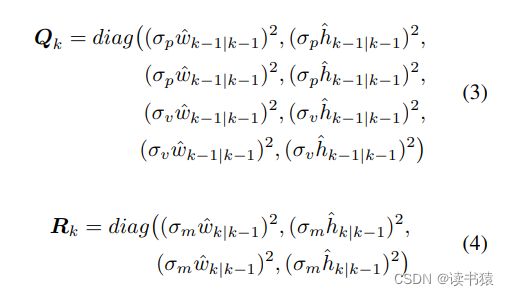
3.2、相机运动补偿
这个是我们的重点,针对这一点如何实现,包括如何在我们自己代码运用,我下一节单独拿来分析。
Tracking-by-detection严重依赖 预测框predictBox与检测框detectBox的重叠程度(如 IOU)。在自动驾驶领域中,相机是动态的,图像平面的边界框位置可能会发生显著变化。就算在相机固定的情况下,跟踪器也可能因振动或漂移引起的运动而受到影响。

这部分使用opencv中的全局运动估计(GMC)技术来表示背景运动。 首先提取图像关键点,再利用稀疏光流进行基于平移的局部异常点抑制的特征跟踪。然后使用 RANSAC 计算放射变换矩阵,再将预测的边界框从 k-1 帧坐标变换到其下一阵第k帧的坐标。上图表现出的效果看起来也很不错。
变换矩阵的平移部分仅影响边界框的中心位置,而另一部分影响所有状态向量和噪声矩阵。M ∈ R2×2 是包含仿射矩阵 a 的尺度和旋转部分的矩阵,并且 T 包含平移部分。 简单理解 M∈R2×2 为二维旋转矩阵,T为平移矩阵。由于我们前面状态定义为:
所以所有的状态都需要旋转操作,平移只需要对中心点(x,y)平移即可。如何在预测后的状态量中再旋转平移拿到最终状态量,用最终状态量进行匹配操作。
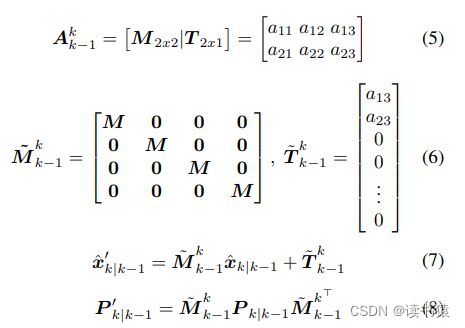
如果看不懂,把公式写出这样大家应该就明白了

关于 M 怎么求? 我下面一节会提供一个简单的思路和代码,大家可以参考下。
在经过上述式子更新过后,我们可以得到计算相机运动补偿后的目标状态与增益,此时把相应的 X,P 进行卡尔曼滤波的更新步骤。
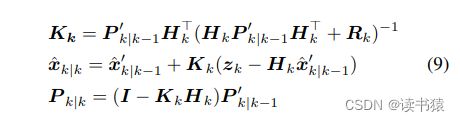
3.3、iou和ReID融合
这部分是论文新提出的方法,也是可圈可点的地方。不过由于实时性太差,并不是适用实际场景,所以不是我们今天分析的重点。
为了提取 Re-ID 特征,采用了 FastReID 库中 BoT 之上的更强的 baseline——SBS(2020年提出)+ ResNeSt50 作为骨干网络。
更新外观状态:
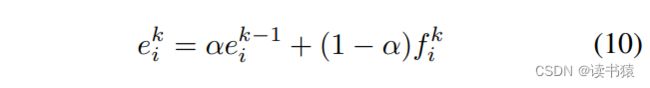
由于外观特征很容易受到拥挤、遮挡和模糊目标的扰动破坏,作者仅使用高置信度的框。对于轨迹外观状态e与新检测嵌入特征 f 的关联,采用余弦相似性度量。α=0.9 是动量项。外观成本 Aa 和运动成本 Am 计算成本矩阵 C。其中权重因子 λ 通常设置为 0.98 。

作者开发了一种将运动和外观信息相结合的新方法,即IoU距离矩阵和余弦距离矩阵。首先,根据 IoU 的得分,低余弦相似性或遥远的候选者被拒绝。然后,使用矩阵的每个元素中的最小值作为我们的成本矩阵 C 的最终值。IoU-ReID 融合管道可以公式化如下:
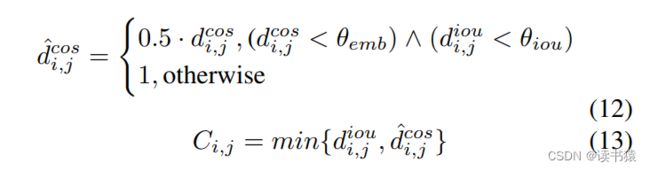
3.4、改进总结
我们结合流程图,回顾以上三点改进:

- 步骤 1 的提升并不明显。可以说步骤 1 的状态也是为了步骤 2 服务的。
- 步骤 2 对跟踪器分数的提升较大。实际测试发现步骤 2 的提升是很大的,尤其是对突然发生抖动场景(如车子过减速带,急刹车等)。
- 步骤 3 加入RE-ID之后速度非常慢,达不到实时检测跟踪。
四、相机运动补偿
整体思路如下:
- 计算图片背景特征点角点检测
- 上一帧与当前帧光流匹配
- 根据特征点计算旋转平移
之前博主有分享过一篇光流跟踪博客 【目标跟踪】光流跟踪(python、c++代码)。
那篇博客思路与这里有点像素, 不过那篇博客是对每个检测的目标框进行光流估计,而且没有考虑旋转。
我们这里是对背景进行光流估计,补偿所有的检测框。
根据论文思路,博主自己写了一个 demo。
import numpy as np
import cv2
import os
img_dir = "F:\\image_raw\\"
n_frames = len(os.listdir(img_dir))
w, h = 1920, 1080
num = 1
prev = cv2.imread(img_dir + "{}.jpg".format(num))
prev_gray = cv2.cvtColor(prev, cv2.COLOR_BGR2GRAY)
color = np.random.randint(0, 255, (20000, 3))
for i in range(n_frames - 2):
curr_path = img_dir + "{}.jpg".format(i + 2)
curr = cv2.imread(curr_path)
drawImg = curr.copy()
mask = np.zeros_like(drawImg)
prev_pts = cv2.goodFeaturesToTrack(prev_gray, maxCorners=200, qualityLevel=0.01, minDistance=30, blockSize=3)
curr_gray = cv2.cvtColor(curr, cv2.COLOR_BGR2GRAY)
curr_pts, status, err = cv2.calcOpticalFlowPyrLK(prev_gray, curr_gray, prev_pts, None)
idx = np.where(status == 1)[0]
prev_pts = prev_pts[idx]
curr_pts = curr_pts[idx]
m, _ = cv2.estimateAffinePartial2D(prev_pts, curr_pts)
prev_gray = cv2.cvtColor(curr, cv2.COLOR_BGR2GRAY)
for i, (new, old) in enumerate(zip(prev_pts, curr_pts)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv2.line(mask, (int(a), int(b)), (int(c), int(d)), color[i].tolist(), 2)
drawImg = cv2.circle(drawImg, (int(a), int(b)), 4, color[i].tolist(), -1)
showImg = cv2.add(drawImg, mask)
cv2.imshow("show", showImg)
cv2.waitKey(100)
代码中的 m 就是我们的旋转平移矩阵。选取特征点时尽量选择背景,不要选择动态目标,可以通过检测简单过滤。

有了 m 我们可以对 kalman 中的预测状态进行再修正后,进行匹配。
整体的效果非常不错,尤其是在颠簸的道路行驶时,基本碾压其他算法。
论文公布的效果对比图:

如有疑问,欢迎大家交流!