SSD 中的数据增强
原文链接: http://www.telesens.co/2018/06/28/data-augmentation-in-ssd/
文章目录
- 一、简介
- 二、数据增强整体流程
- 三、像素内容变换(Photometric Distortions)
- 1、Random Brightness
- 2、Random Contrast, Hue, Saturation
- 3、RandomLightingNoise
- 四、空间几何变换(Geometric Distortions)
- 1、RandomExpand
- 2、RandomCrop
- 3、RandomMirror
- 五、pytorch 代码实现
- 六、caffe 代码实现
- 七、参考资料
一、简介
- 数据增强对于提高各种尺度(尤其是小目标)的检测精度尤其重要(主要通过 RandomExpand、RandomCrop 以及 Resize 实现),根据 SSD 论文,数据增强使得检测的 mAP 提升了
8.8%,所以很有必要详细了解下作者做了哪些数据增强。- Note: Ground truth box is
rescaled accordingly(bw/width*300, bh/height*300)


二、数据增强整体流程
SSD 中的数据增强顺序如下(其中第 2 和 3 步以 0.5 的概率实施)
- 数据类型和坐标转换
- ConvertFromInts(
np.float32)- ToAbsoluteCoords(
bbox coordinates *width and *height accordingly),为下面的几何变换做准备- 像素内容变换(Photometric Distortions)
- 随机改变图像亮度(Random Brightness)
- 随机改变对比度、色度、饱和度(Random Contrast, Hue, Saturation)
- 随机改变颜色通道(RandomLightingNoise)
- 空间几何变换(Geometric Distortions)
- 随机扩展(RandomExpand)
- 随机裁剪(RandomCrop)
- 随机镜像(RandomMirror)
- 坐标转换、缩放及减均值
- ToPercentCoords(
bbox coordinates /width and /height accordingly),因为几何变换后图像尺寸改变了- Resize(
300*300)- SubtractMeans(
104, 117, 123)- caffe 代码实现如下

三、像素内容变换(Photometric Distortions)
1、Random Brightness
- 通过随机
增加或减小图像中每个像素的值(-32, 32)来改变图像的亮度,代码实现如下:class RandomBrightness(object): def __init__(self, delta=32): assert delta >= 0.0 assert delta <= 255.0 self.delta = delta def __call__(self, image, boxes=None, labels=None): # 只能取 0 或 1,所以是 0.5 的概率 if random.randint(2): delta = random.uniform(-self.delta, self.delta) image += delta return image, boxes, labels - 效果图如下(保存图片时会自动截断)

2、Random Contrast, Hue, Saturation
- Random Contrast
- 通过对
图像中每个像素的值乘以一个系数(0.5, 1.5)来改变对比度(在 BGR 颜色空间做) - 感觉这样是增大或者减小最亮点和最暗点的差值而不是比值
- 通过对
- Random Hue, Saturation
- 首先,将图像从 BGR 颜色空间转到 HSV 颜色空间
- 其次,对
增加或减小图像的 H 通道值(-18, 18)来改变色度 - 然后,通过对
图像的 S 通道乘以一个系数(0.5, 1.5)来改变饱和度 - 最后,将图像从 HSV 颜色空间转到 BGR 颜色空间
- Note: 可以先调整对比度,在调整色度和饱和度;也可以先调整色度和饱和度再调整对比度,代码实现如下:
class PhotometricDistort(object): def __init__(self): self.pd = [ RandomContrast(), ConvertColor(transform='HSV'), RandomSaturation(), RandomHue(), ConvertColor(current='HSV', transform='BGR'), RandomContrast() ] self.rand_brightness = RandomBrightness() self.rand_light_noise = RandomLightingNoise() def __call__(self, image, boxes, labels): im = image.copy() im, boxes, labels = self.rand_brightness(im, boxes, labels) if random.randint(2): distort = Compose(self.pd[:-1]) else: distort = Compose(self.pd[1:]) im, boxes, labels = distort(im, boxes, labels) return self.rand_light_noise(im, boxes, labels) # random color channel swap - 效果图如下(保存图片时会自动截断)

3、RandomLightingNoise
- 通过随机
指定 channel 维度的顺序来改变图像的颜色通道,代码实现如下:# random color channel swap class RandomLightingNoise(object): def __init__(self): self.perms = ((0, 1, 2), (0, 2, 1), (1, 0, 2), (1, 2, 0), (2, 0, 1), (2, 1, 0)) def __call__(self, image, boxes=None, labels=None): if random.randint(2): swap = self.perms[random.randint(len(self.perms))] image = image[:, :, swap] return image, boxes, labels - 效果图如下

四、空间几何变换(Geometric Distortions)
1、RandomExpand
- 通过 随机扩展(
1~4)并缩放后(zoom in) ,大尺度 object 可以变成小尺度 object(主要增加小尺度 object 的多样性,Resize 后变小 ),从而提升小尺度 object 的检测效果


2、RandomCrop
- 通过 随机裁剪并缩放后(
zoom out) ,可以增加不同尺度的 object(主要增加大尺度 object 的多样性,Resize 后变大),从而提升网络对目标尺度的鲁棒性 - 随机裁剪的分类、限制条件及坐标调整
- 裁剪分类:
- 原图(对应上文第二节 prototxt 中的第 1 个
batch_sampler) - 裁剪的 patch 和任意 object bbox 的交并比大于
0.1 or 0.3 or 0.5 or 0.7 or 0.9且 object bbox 的中点在 patch 中(对应上文第二节 prototxt 中的第 2 个batch_sampler + emit_constraint) - 随机裁剪一个 patch 且 object bbox 的中点在 patch 中(对应上文第二节 prototxt 中的第 3 个
batch_sampler)
- 原图(对应上文第二节 prototxt 中的第 1 个
- 限制条件:
- object bbox 的中点在 patch 中 (对应上文第二节 prototxt 中
transform_param中的emit_constraint) - patch 的宽和高的大小至少为原图的
0.3倍,宽高比在0.5~2之间(对应上文第二节 prototxt 中batch_sampler中的scale 和 aspect_ratio)
- object bbox 的中点在 patch 中 (对应上文第二节 prototxt 中
- 坐标调整:
- 首先,裁剪后的 gt boxes 和 gt labels 通过
mask取出 - 然后,裁剪后的 gt boxes 的坐标要和裁剪 patch 的左上和右下坐标进行逐元素比一下(防止越界),gt boxes 的
左上坐标取两者中的较大者,gt boxes 的右下坐标取两者中的较小者 - 最后,还要
减去 patch 的左上坐标得到裁剪后 patch 的 gt boxes 坐标
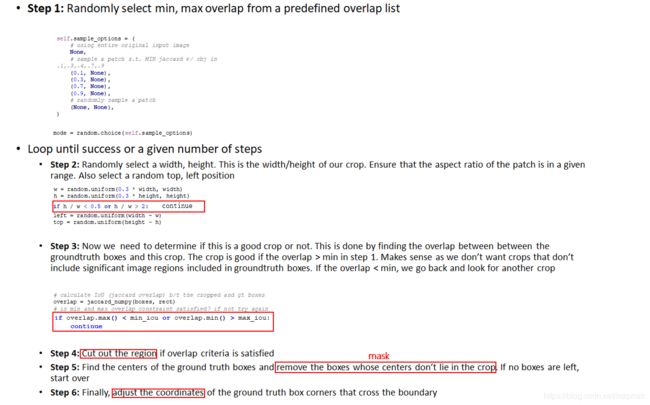

- 首先,裁剪后的 gt boxes 和 gt labels 通过
- 裁剪分类:
3、RandomMirror
- 随机进行水平镜像操作,增加样本角度的多样性,水平镜像后 y 坐标不变,x 变为 w-x:
- 原图右(2)上坐标对应变为镜像图左(0)上坐标
- 原图左(0)下坐标对应变为镜像图坐标右(2)下坐标
boxes[:, 0::2] = width - boxes[:, 2::-2] # 水平镜像只有 x 改变,步长为 -2

五、pytorch 代码实现
import torch
from torchvision import transforms
import cv2
import numpy as np
import types
from numpy import random
def intersect(box_a, box_b):
max_xy = np.minimum(box_a[:, 2:], box_b[2:])
min_xy = np.maximum(box_a[:, :2], box_b[:2])
inter = np.clip((max_xy - min_xy), a_min=0, a_max=np.inf)
return inter[:, 0] * inter[:, 1]
def jaccard_numpy(box_a, box_b):
"""Compute the jaccard overlap of two sets of boxes. The jaccard overlap
is simply the intersection over union of two boxes.
E.g.:
A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
Args:
box_a: Multiple bounding boxes, Shape: [num_boxes,4]
box_b: Single bounding box, Shape: [4]
Return:
jaccard overlap: Shape: [box_a.shape[0], box_a.shape[1]]
"""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2] - box_a[:, 0]) *
(box_a[:, 3] - box_a[:, 1])) # [A,B]
area_b = ((box_b[2] - box_b[0]) *
(box_b[3] - box_b[1])) # [A,B]
union = area_a + area_b - inter
return inter / union # [A,B]
class Compose(object):
"""Composes several augmentations together.
Args:
transforms (List[Transform]): list of transforms to compose.
Example:
>>> augmentations.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])
"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, img, boxes=None, labels=None):
for t in self.transforms:
img, boxes, labels = t(img, boxes, labels)
return img, boxes, labels
class Lambda(object):
"""Applies a lambda as a transform."""
def __init__(self, lambd):
assert isinstance(lambd, types.LambdaType)
self.lambd = lambd
def __call__(self, img, boxes=None, labels=None):
return self.lambd(img, boxes, labels)
class ConvertFromInts(object):
def __call__(self, image, boxes=None, labels=None):
return image.astype(np.float32), boxes, labels
class SubtractMeans(object):
def __init__(self, mean):
self.mean = np.array(mean, dtype=np.float32)
def __call__(self, image, boxes=None, labels=None):
image = image.astype(np.float32)
image -= self.mean
return image.astype(np.float32), boxes, labels
class ToAbsoluteCoords(object):
def __call__(self, image, boxes=None, labels=None):
height, width, channels = image.shape
boxes[:, 0] *= width
boxes[:, 2] *= width
boxes[:, 1] *= height
boxes[:, 3] *= height
return image, boxes, labels
class ToPercentCoords(object):
def __call__(self, image, boxes=None, labels=None):
height, width, channels = image.shape
boxes[:, 0] /= width
boxes[:, 2] /= width
boxes[:, 1] /= height
boxes[:, 3] /= height
return image, boxes, labels
class Resize(object):
def __init__(self, size=300):
self.size = size
def __call__(self, image, boxes=None, labels=None):
image = cv2.resize(image, (self.size,
self.size))
return image, boxes, labels
class RandomSaturation(object):
def __init__(self, lower=0.5, upper=1.5):
self.lower = lower
self.upper = upper
assert self.upper >= self.lower, "contrast upper must be >= lower."
assert self.lower >= 0, "contrast lower must be non-negative."
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
image[:, :, 1] *= random.uniform(self.lower, self.upper)
return image, boxes, labels
class RandomHue(object):
def __init__(self, delta=18.0):
assert 0.0 <= delta <= 360.0
self.delta = delta
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
image[:, :, 0] += random.uniform(-self.delta, self.delta)
image[:, :, 0][image[:, :, 0] > 360.0] -= 360.0
image[:, :, 0][image[:, :, 0] < 0.0] += 360.0
return image, boxes, labels
class RandomLightingNoise(object):
def __init__(self):
self.perms = ((0, 1, 2), (0, 2, 1),
(1, 0, 2), (1, 2, 0),
(2, 0, 1), (2, 1, 0))
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
swap = self.perms[random.randint(len(self.perms))]
image = image[:, :, swap]
return image, boxes, labels
class ConvertColor(object):
def __init__(self, current='BGR', transform='HSV'):
self.transform = transform
self.current = current
def __call__(self, image, boxes=None, labels=None):
if self.current == 'BGR' and self.transform == 'HSV':
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
elif self.current == 'HSV' and self.transform == 'BGR':
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
else:
raise NotImplementedError
return image, boxes, labels
class RandomContrast(object):
def __init__(self, lower=0.5, upper=1.5):
self.lower = lower
self.upper = upper
assert self.upper >= self.lower, "contrast upper must be >= lower."
assert self.lower >= 0, "contrast lower must be non-negative."
# expects float image
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
alpha = random.uniform(self.lower, self.upper)
image *= alpha
return image, boxes, labels
class RandomBrightness(object):
def __init__(self, delta=32):
assert delta >= 0.0
assert delta <= 255.0
self.delta = delta
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
delta = random.uniform(-self.delta, self.delta)
image += delta
return image, boxes, labels
class ToCV2Image(object):
def __call__(self, tensor, boxes=None, labels=None):
return tensor.cpu().numpy().astype(np.float32).transpose((1, 2, 0)), boxes, labels
class ToTensor(object):
def __call__(self, cvimage, boxes=None, labels=None):
return torch.from_numpy(cvimage.astype(np.float32)).permute(2, 0, 1), boxes, labels
class RandomSampleCrop(object):
"""Crop
Arguments:
img (Image): the image being input during training
boxes (Tensor): the original bounding boxes in pt form
labels (Tensor): the class labels for each bbox
mode (float tuple): the min and max jaccard overlaps
Return:
(img, boxes, classes)
img (Image): the cropped image
boxes (Tensor): the adjusted bounding boxes in pt form
labels (Tensor): the class labels for each bbox
"""
def __init__(self):
self.sample_options = (
# using entire original input image
None,
# sample a patch s.t. MIN jaccard w/ obj in .1,.3,.5,.7,.9
(0.1, None),
(0.3, None),
(0.5, None),
(0.7, None),
(0.9, None),
# randomly sample a patch
(None, None),
)
def __call__(self, image, boxes=None, labels=None):
height, width, _ = image.shape
while True:
# randomly choose a mode
mode = random.choice(self.sample_options)
if mode is None:
return image, boxes, labels
min_iou, max_iou = mode
if min_iou is None:
min_iou = float('-inf')
if max_iou is None:
max_iou = float('inf')
# max trails (50)
for _ in range(50):
current_image = image
w = random.uniform(0.3 * width, width)
h = random.uniform(0.3 * height, height)
# aspect ratio constraint b/t .5 & 2
if h / w < 0.5 or h / w > 2:
continue
left = random.uniform(width - w)
top = random.uniform(height - h)
# convert to integer rect x1,y1,x2,y2
rect = np.array([int(left), int(top), int(left + w), int(top + h)])
# calculate IoU (jaccard overlap) b/t the cropped and gt boxes
overlap = jaccard_numpy(boxes, rect)
# is min and max overlap constraint satisfied? if not try again
# modified by manzp
if overlap.max() < min_iou or overlap.min() > max_iou:
continue
# cut the crop from the image
current_image = current_image[rect[1]:rect[3], rect[0]:rect[2],
:]
# keep overlap with gt box IF center in sampled patch
centers = (boxes[:, :2] + boxes[:, 2:]) / 2.0
# mask in all gt boxes that above and to the left of centers
m1 = (rect[0] < centers[:, 0]) * (rect[1] < centers[:, 1])
# mask in all gt boxes that under and to the right of centers
m2 = (rect[2] > centers[:, 0]) * (rect[3] > centers[:, 1])
# mask in that both m1 and m2 are true
mask = m1 * m2
# have any valid boxes? try again if not
if not mask.any():
continue
# take only matching gt boxes
current_boxes = boxes[mask, :].copy()
# take only matching gt labels
current_labels = labels[mask]
# should we use the box left and top corner or the crop's
current_boxes[:, :2] = np.maximum(current_boxes[:, :2],
rect[:2])
# adjust to crop (by substracting crop's left,top)
current_boxes[:, :2] -= rect[:2]
current_boxes[:, 2:] = np.minimum(current_boxes[:, 2:],
rect[2:])
# adjust to crop (by substracting crop's left,top)
current_boxes[:, 2:] -= rect[:2]
return current_image, current_boxes, current_labels
class Expand(object):
def __init__(self, mean):
self.mean = mean
def __call__(self, image, boxes, labels):
if random.randint(2):
return image, boxes, labels
height, width, depth = image.shape
ratio = random.uniform(1, 4)
left = random.uniform(0, width * ratio - width)
top = random.uniform(0, height * ratio - height)
expand_image = np.zeros(
(int(height * ratio), int(width * ratio), depth),
dtype=image.dtype)
expand_image[:, :, :] = self.mean
expand_image[int(top):int(top + height),
int(left):int(left + width)] = image
image = expand_image
boxes = boxes.copy()
boxes[:, :2] += (int(left), int(top))
boxes[:, 2:] += (int(left), int(top))
return image, boxes, labels
class RandomMirror(object):
def __call__(self, image, boxes, classes):
_, width, _ = image.shape
if random.randint(2):
image = image[:, ::-1]
boxes = boxes.copy()
boxes[:, 0::2] = width - boxes[:, 2::-2]
return image, boxes, classes
class PhotometricDistort(object):
def __init__(self):
self.pd = [
RandomContrast(),
ConvertColor(transform='HSV'),
RandomSaturation(),
RandomHue(),
ConvertColor(current='HSV', transform='BGR'),
RandomContrast()
]
self.rand_brightness = RandomBrightness()
self.rand_light_noise = RandomLightingNoise()
def __call__(self, image, boxes, labels):
im = image.copy()
im, boxes, labels = self.rand_brightness(im, boxes, labels)
if random.randint(2):
distort = Compose(self.pd[:-1])
else:
distort = Compose(self.pd[1:])
im, boxes, labels = distort(im, boxes, labels)
return self.rand_light_noise(im, boxes, labels)
class SSDAugmentation(object):
def __init__(self, size=300, mean=(104, 117, 123)):
self.mean = mean
self.size = size
self.augment = Compose([
ConvertFromInts(),
ToAbsoluteCoords(),
PhotometricDistort(),
Expand(self.mean),
RandomSampleCrop(),
RandomMirror(),
ToPercentCoords(),
Resize(self.size),
SubtractMeans(self.mean)
])
def __call__(self, img, boxes, labels):
return self.augment(img, boxes, labels)
六、caffe 代码实现
name: "VGG_VOC0712Plus_SSD_300x300_train"
layer {
name: "data"
type: "AnnotatedData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
mean_value: 104
mean_value: 117
mean_value: 123
resize_param {
prob: 1
resize_mode: WARP # WARP:放大或缩小以适应(width, height)
height: 300 # 还有 FIT_SMALL_SIZE 和 FIT_LARGE_SIZE_AND_PAD 这两种缩放模式
width: 300
interp_mode: LINEAR # 插值模式同 OpenCV(每次随机选一种)
interp_mode: AREA
interp_mode: NEAREST
interp_mode: CUBIC
interp_mode: LANCZOS4
}
emit_constraint {
emit_type: CENTER # batch sampler 的额外限制条件
}
distort_param {
brightness_prob: 0.5
brightness_delta: 32
contrast_prob: 0.5
contrast_lower: 0.5
contrast_upper: 1.5
hue_prob: 0.5
hue_delta: 18
saturation_prob: 0.5
saturation_lower: 0.5
saturation_upper: 1.5
random_order_prob: 0.0
}
expand_param {
prob: 0.5
max_expand_ratio: 4.0
}
}
data_param {
source: "examples/VOC0712Plus/VOC0712Plus_trainval_lmdb"
batch_size: 8
backend: LMDB
}
annotated_data_param {
batch_sampler {
max_sample: 1
max_trials: 1 # use_original_image = 1 [default = true];
}
batch_sampler {
sampler {
min_scale: 0.3 # sampled bbox h,w 最小缩放比例
max_scale: 1.0 # Maximum scale of the sampled bbox.
min_aspect_ratio: 0.5 # sampled bbox 长宽比 w/h
max_aspect_ratio: 2.0 # Maximum aspect ratio of the sampled bbox.
}
sample_constraint {
min_jaccard_overlap: 0.1 # sampled bbox 和所有 gt boxes IoU 的最小值
}
max_sample: 1 # sample 多少个 bbox
max_trials: 50 # 最大尝试次数
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.3
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.5
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.7
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.9
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
max_jaccard_overlap: 1.0
}
max_sample: 1
max_trials: 50
}
# 要和 xml 中的 name 对应
label_map_file: "data/VOC0712Plus/labelmap_voc.prototxt"
}
}
# labelmap_voc.prototxt 部分示例
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "aeroplane"
label: 1
display_name: "aeroplane"
}
item {
name: "bicycle"
label: 2
display_name: "bicycle"
}
七、参考资料
1、https://github.com/amdegroot/ssd.pytorch/
2、http://www.telesens.co/2018/06/28/data-augmentation-in-ssd