第二章:Tensorflow 2.0 手写全连接MNIST数据集(理论+实战)
理论部分
1,什么是MNIST数据集?
相信大家入门机器学习时,都会从网上下载MNIST的demo进行入门学习,所以少奶奶相信大家对MNIST数据集再熟悉不过了,在少奶奶看来,MNIST数据集是由60k的训练样本和10k的测试样本构成的简单数据集,每一个样本宽高为28x28,都是由0~255像素构成的单通道图片,在神经网络中,我们通常用以下的tensor进行表示:
[b , w, h, c] = [64, 28 , 28, 1]
其中,b代表着参与训练时一共有多少张图片(这也是我们通常说的batch),w和h代表着当前图片的宽和高,c代表着图片的通道数(由于MNIST为黑白图片,所以C=1)。那么[64, 28, 28, 1]代表着,每一次参与训练的图片张数有64张,每一张图片的宽高分别为28x28,每一张图片的通道数为1。
备注:在下述讲解中,b=1。
2,构建全连接输入
当我们把训练数据输入全连接神经网络时,需要先对数据进行预处理,即把一张[28 ,28 ,1]的图片打平成[28 * 28]的一维数据
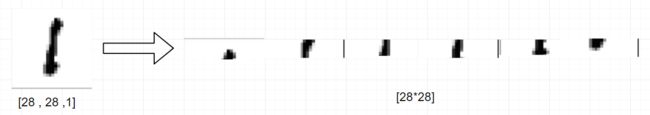
从上图可以理解,把图片进行打平操作就是把二维的数据变化成一维的数据。这种纬度的转化会保留图片左右的特征信息,但失去了图片上下的特征信息,打平后的一维数据就会作为全连接网络中第一层的神经元而输入到神经网络中。
当然对数据的预处理还有一步,就是把0~255的像素值放缩到[0 , 1]或者[-1, 1]之间,这样做的好处是避免了大数值的计算,节约内存。具体操作如下:
![]()
先把图片的像素值转化成float32类型,然后除以255. 即可。若想缩放到[-1, 1]之间的话可以这样做
![]()
3,构建非线性的全连接网络
线性模型能很好的表示一些简单的数据集(拟合二维平面中的点),但却无法表示很多复杂的数据集,例如,一个人能在10天盖好一个小木屋,两个人就可以在5天内盖好,那么10个人就能在1天内盖好吗?这显然是不可能的,所以,在现实生活中的很多事务都不满足线性关系,MNIST数据集也是一样,所以我们使用的全连接神经网络需要构建非线性的结构,才能更好的对MNIST进行描述。
如何构建非线性模型?
传统线性模型结构如下:
out = x@w + b
要想把线性结构转化到非线性结构,我们需要使用非线性的激活函数,其中,最常用给的是rule函数,其结构如下:

我们把线性模型的输出作为非线性模型的输入,则:
out = f(x@w + b) = rule( x@w + b )
当然,我们的全连接层不止有一层,在实战中,少奶奶计划构建三层,则整个非线性模型结构如下:
out1 = rule( x@w1 + b1 )
out2= rule( out1@w2 + b2 )
out3 = rule( out2x@w3 + b3)
三层的全连接层的构建,使得该神经网络拥有了比较强的非线性拟合能力。
4,非线性模型的输出结果
MNIST的标签范围为[0~9]共10种输出结果,所以每一次模型的输出结果必须是[b, 10]。其中,b代表着这一次进行训练时的图片张数,为了方便解释,我们取b=1。则[1, 10]可理解为一张图片在经过模型处理后,会得到10种结果,该结果对应的索引代表着10类标签。每一种结果的数值大小代表着当前训练图片属于哪一种标签的可能性结果。例如:
某一次输出结果:[0.1 , 0.5 , 0.11 , 0.67 ,0.001 ,0.1 , 0.0001, 0.11 , 0.22 ,0.001 ]
最大值的索引:maxindex = 3
所以当前的神经网络预测输入图片中的数据最有可能是标签3.
5,One_hot编码
神经网络输出结果为[b , 10],而我们的标签是[0 ,9]的数字,矩阵和标量是无法进行运算的,所以,我们会对标签采用ont_hot编码(0-1编码)。即先构建一个和输出结果纬度一样的零矩阵,然后把标签当作索引,修改零矩阵中对应索引的值为1即可,具体如下:
由于输出结果为[b ,10],所以先构建一个纬度相同的零矩阵:
[0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0]
标签 = 3,则把index=3的值修改成1,
label 3 = [0 ,0 ,0 ,1 ,0 ,0 ,0 ,0 ,0 ,0]
通过上述操作我们就可以把标签转化成神经网络输出的格式,方便我们使用MSE对预测值和标签进行loss计算。
6,loss函数的计算
为了计算预测值和真实值之间的差异大小,我们采用MSE来进行loss的求解。
![]()
MSE可以简单的理解成两个值之间的欧式距离。标签在经过ont_hot编码后,我们便把模型输出值和标签进行了统一,那么,我们只需要代入上述公式就可以计算出当前loss的值了。具体求解过程如下:
out = [0.1 , 0.1 , 0.1 , 0.5 ,0.1 ,0.1 , 0.1, 0.1 , 0.1 ,0.1 ]
label = [0 ,0 ,0 ,1 ,0 ,0 ,0 ,0 ,0 ,0]
代入公式可得:
loss = (0.1 - 0)^2 + (0.1 - 0)^2+(0.1 - 0)^2+(0.5 - 1)^2+(0.1 - 0)^2+(0.1 - 0)^2+(0.1 - 0)^2+(0.1 - 0)^2+(0.1 - 0)^2+(0.1 - 0)^2/10
loss = 0.034
7, 梯度更新
梯度更新的具体过程和理论依据,读者可以参考我的另一片博文,下面给出链接
第一章:Tensorflow 2.0 实现简单的线性回归模型(理论+实践)
备注:无论什么样式的网络结构,其梯度的更新的本质是一样的,
8,测试正确率
为了确保模型的正确性,我们会在训练一段时间后,输入测试集,进而获得当前模型的准确率。通常情况下,我们会选择在模型训练完一遍数据集后,执行一次测试。具体实现如下:
步骤一:把测试数据集输入当前的模型中,获得[b ,10]的预测值
步骤二:利用tf.nn.sofmax()函数,把[b ,10]中的值放缩到[0 ,1]之间,且每一个[1 , 10]中给的值总和为1。
步骤三:利用tf.argmax()获得每一个[b , 10]中概率最大值所在的索引。
步骤四:统计最大值索引等于标签值的总的个数,得到当前批次中预测正确的个数
步骤五:统计完整个测试集中正确的个数,得到最终的正确率
实战部分
-
import tensorflow
as tf
-
from tensorflow
import keras
-
from tensorflow.keras
import datasets
-
import os
-
-
# 设置后台打印日志等级 避免后台打印一些无用的信息
-
os.environ[
'TF_CPP_MIN_LOG_LEVEL'] =
'2'
-
-
# 利用Tensorflow2中的接口加载mnist数据集
-
(x, y), (x_test, y_test) = datasets.mnist.load_data()
-
-
# 对数据进行预处理
-
def preprocess(x, y):
-
x = tf.cast(x, dtype=tf.float32) /
255.
-
y = tf.cast(y, dtype=tf.int32)
-
return x,y
-
-
# 构建dataset对象,方便对数据的打乱,批处理等超操作
-
train_db = tf.data.Dataset.from_tensor_slices((x,y)).shuffle(
1000).batch(
128)
-
train_db = train_db.map(preprocess)
-
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test)).batch(
128)
-
test_db = test_db.map(preprocess)
-
-
# 构建模型中会用到的权重
-
w1 = tf.Variable(tf.random.truncated_normal([
784,
256], stddev=
0.1))
-
b1 = tf.Variable(tf.zeros([
256]))
-
w2 = tf.Variable(tf.random.truncated_normal([
256,
128], stddev=
0.1))
-
b2 = tf.Variable(tf.zeros([
128]))
-
w3 = tf.Variable(tf.random.truncated_normal([
128,
10], stddev=
0.1))
-
b3 = tf.Variable(tf.zeros([
10]))
-
-
# 学习率
-
lr =
1e-3
-
-
# epoch表示整个训练集循环的次数 这里循环100次
-
for epoch
in range(
100):
-
# step表示当前训练到了第几个Batch
-
for step, (x, y)
in enumerate(train_db):
-
# 把训练集进行打平操作
-
x = tf.reshape(x, [
-1,
28*
28])
-
# 构建模型并计算梯度
-
with tf.GradientTape()
as tape:
# tf.Variable
-
# 三层非线性模型搭建
-
h1 = x@w1 + tf.broadcast_to(b1, [x.shape[
0],
256])
-
h1 = tf.nn.relu(h1)
-
h2 = h1@w2 + b2
-
h2 = tf.nn.relu(h2)
-
out = h2@w3 + b3
-
-
# 把标签转化成one_hot编码
-
y_onehot = tf.one_hot(y, depth=
10)
-
-
# 计算MSE
-
loss = tf.square(y_onehot - out)
-
loss = tf.reduce_mean(loss)
-
-
# 计算梯度
-
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
-
-
# w = w - lr * w_grad
-
# 利用上述公式进行权重的更新
-
w1.assign_sub(lr * grads[
0])
-
b1.assign_sub(lr * grads[
1])
-
w2.assign_sub(lr * grads[
2])
-
b2.assign_sub(lr * grads[
3])
-
w3.assign_sub(lr * grads[
4])
-
b3.assign_sub(lr * grads[
5])
-
-
# 每训练100个Batch 打印一下当前的loss
-
if step %
100 ==
0:
-
print(epoch, step,
'loss:', float(loss))
-
-
# 每训练完一次数据集 测试一下啊准确率
-
total_correct, total_num =
0,
0
-
for step, (x,y)
in enumerate(test_db):
-
-
x = tf.reshape(x, [
-1,
28*
28])
-
-
h1 = tf.nn.relu(x@w1 + b1)
-
h2 = tf.nn.relu(h1@w2 + b2)
-
out = h2@w3 +b3
-
# 把输出值映射到[0~1]之间
-
prob = tf.nn.softmax(out, axis=
1)
-
# 获取概率最大值得索引位置
-
pred = tf.argmax(prob, axis=
1)
-
pred = tf.cast(pred, dtype=tf.int32)
-
-
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
-
correct = tf.reduce_sum(correct)
-
# 获取每一个batch中的正确率和batch大小
-
total_correct += int(correct)
-
total_num += x.shape[
0]
-
# 计算总的正确率
-
acc = total_correct / total_num
-
print(
'test acc:', acc)
备注:有时候直接调用 datasets.mnist.load_data()无法下载数据集,你可以网上搜索解决方案,也可以翻阅少奶奶的另一篇博文,链接如下:
亲测速度杠杠的!)解读源码------完美解决Tensorflow 常用数据集下载!
下一篇博文,少奶奶将介绍如何用Tensorflow2的高级接口 实现对chair 10 数据集的全连接理论+实战实现
开篇:开启Tensorflow 2.0时代
第一章:Tensorflow 2.0 实现简单的线性回归模型(理论+实践)
第二章:Tensorflow 2.0 手写全连接MNIST数据集(理论+实战)
第三章:Tensorflow 2.0 利用高级接口实现对cifar10 数据集的全连接(理论+实战实现)
第四章:Tensorflow 2.0 实现自定义层和自定义模型的编写并实现cifar10 的全连接网络(理论+实战)
第五章:Tensorflow 2.0 利用十三层卷积神经网络实现cifar 100训练(理论+实战)
第六章:优化神经网络的技巧(理论)
第七章:Tensorflow2.0 RNN循环神经网络实现IMDB数据集训练(理论+实践)
第八章:Tensorflow2.0 传统RNN缺陷和LSTM网络原理(理论+实战)