第五章:Tensorflow 2.0 利用十三层卷积神经网络实现cifar 100训练(理论+实战)
前言:本章会涉及到许多与卷积神经网络相关的核心知识点,属于对卷积神经网络知识点的一些梳理和总结,所以,需要有一些基础的小伙伴才能很好的理解,刚刚入门的小伙伴,少奶奶建议先阅读其他大牛的博文,然后再来看本篇文章的理论和实战部分。若能从第一章开始看起,那你将获得一个比较系统的学习流程。下面开始正文部分。
卷积神经网络相关知识点
卷积
对图像做卷积运算其实是一个滤波的过程
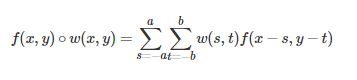
f为图像,w为滤波器(也可以叫做卷积核,响应函数等)。a,b定义了卷积核的大小
所以,整个卷积运算可以看到以下几点
1)卷积是一种线性运算
2)卷积核大小定义了图像任何一点参与运算的领域大小
3)卷积核上的权重大小说明了对应领域点的贡献能力
卷积特征层
图像特征主要体现在像素与周围像素之间形成的关系,这些领域像素关系形成了线条,角度等。而卷积运算正是这种利用领域点按一定权重去重新定义该点值的运算(按卷积核中的权重去加大需要特征的表现力度,减少不需要特征的表现力度)
卷积神经网络
在传统的多层神经网络中(全连接网络),下一层的节点会和上一层的所有节点连接,这大大增加了参数个数。在卷积神经网络中,有特征抽取层和降纬层,这些层的节点是部分连接的,一副特征图由一个卷积核生成,这一副特征图上的点就共享了这一组卷积核的参数。卷积核一般以随机小数的形式初始化,通过网络的训练得到合理的值。降纬层包含也叫做池化层,可以看作一种特殊的卷集层,该操作也可以减少模型的参数,下面会详细介绍。
卷积神经网络一般由三部分构成。第一部分为输入层,第二部分由n个卷积层和次化层的组合构成。第三部分为一个全连接的多层感知机分类器构成。
心得:深度学习的目的是利用数据集去纠正网络中的参数,让相同或者相近的输入在一定误差的影响下依旧可以输出正确的值。通过卷积神经网络,我们可以使得参数的个数和参数的表达能力达到了一个平衡,即参数个数最小化少,但表达力度会最大化。
降低参数的两大神器------局部感受野和权值共享
局部感受野
图像的空间联系是局部的像素联系较为紧密,而距离较远的像素联系较弱。所以,每一个神经元只需要对局部进行感知,然后在更高层进行组合就能得到全局的信息。
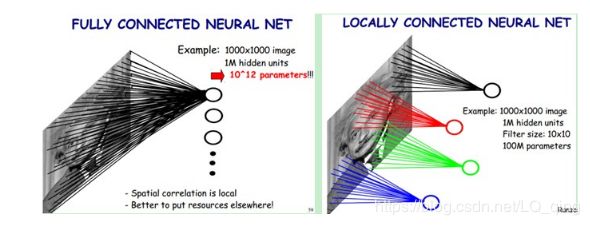
备注:局部感受野的范围为卷积核的大小
权值共享
为了让局部感受野能感知整张图片,需要很多的节点与感受野相连接,但这样导致参数变多,此时,我们可以使用权值共享的策略。即使用一个卷积核对整张图片做卷积操作,得到一张feature map,该feature map就共享了这一个卷积核中给的所有参数。
多卷积核
一个卷积核只能得到一个feature map,学习到一个特征,显然这对图像特征的提取是不够充分的,我们可以用多个卷积核对同一张图片做卷积,这样就可以得到多个feature map,例如:使用32个卷积核的话就可以学习到32个特征。
DOWN-pooling池化
通过卷积获得特征后,我们希望用这些特征去做分类。理论上讲,我们可以用所有学习到的特征进行分类,但这面临着一个计算量的挑战。例如:96x96的图片,我们用400个8x8的卷积核学习了400个特征,可以得到大约3百万特征值,虽然比全连接网络中给的参数少很多,但用这些特征去训练网络很容易造成过拟合,增加训练计算力。所以,对于feature map中的权重,我们只取值比较大的来进行训练,值小的不给予训练。这样增大了训练效率,也可以理解为减少FeatureMap中不重要的样本。常用的池化方法是平均子采样(mean-pooling)和最大值子采样(max-pooling)。
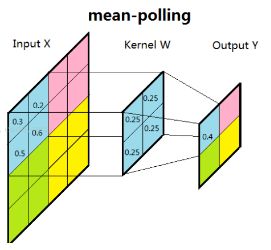
(1) 均值子采样的卷积核中每一个权重都是0.25。滑动步长为2。效果相当于把原图模糊缩减至原来的1/4。
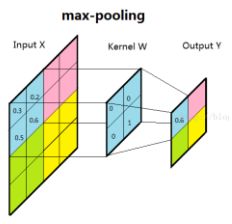
(2)最大值子采样的卷积核中各权重值中全都为0,只有一个为1,其位置不固定。滑动步长为2。其效果是把原图压缩至原来的1/4。并保留每2x2区域中最强输出
多层卷积层
在实际应用中,卷积神经网络模型,往往是用多个卷积再组合两到三 层的全连接层构成的。多层卷积的目的是因为一层卷积学到的东西往往是局部的,层数越高,学到的特征就越全局化。
计算卷积和池化时,得到结果的尺寸
N = (W - F + 2P)/S + 1
N:最终尺寸。W:原图像尺寸。F:卷集层尺寸。P:padding的像素。S:卷积核移动步长
全连接层
卷积层取得的是输入图片的局部特征,而全连接层是根据这些特征组合得到的高级特征,因为该层用到了所有的局部特征,所以叫全连接。卷积层到全连接层的过程其实可以理解成一次卷积,输入所有局部特征后,添加偏置,最后得到一个值(全连接中的某一神经元的结果)
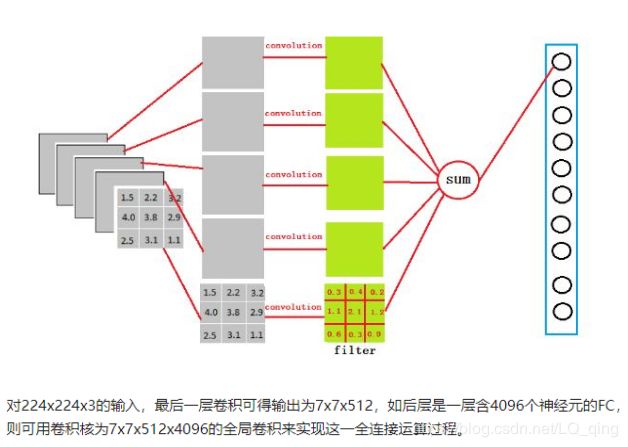
换句话讲,就是把所有卷积得到的特征整合到一起,输出为一个值,这样做能大大减少特征位置对分类带来的影响。所以,在卷积神经网络中,我们会至少加入两层全连接层。因为全连接层越多,那么最后得到的组合特征就越高级,越利于分类。
下面我们以少奶奶理解卷积神经网络中全连接层作用时,看到的一个例子为例:
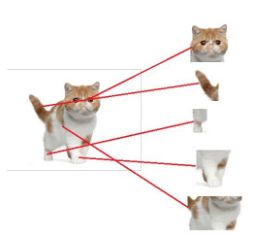
右边是我们输入的原始图片(一个不开心的小猫咪),我们通过5个卷积核,得到了5个特征图(feature map)这些特征图分别对应着喵咪的头,尾巴,前腿等。

我们继续加一层卷集层,就可以把上一层的结果再一次进行卷积,得到新的feature map,如上图所示,猫头被细分为多个局部特征:眼睛,耳朵,嘴巴等。
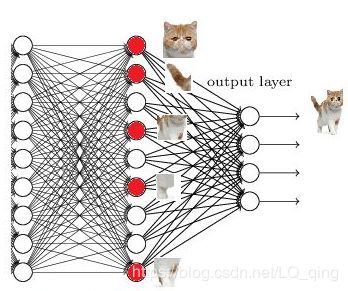
最后,添加一层全连接层,把这些局部特征进行随机组合,我们就可以输出很多奇奇怪怪的组合图片,只要全连接层够大,我们就一定能得到一张组合图片的样子最接近猫咪。这就是为什么在卷积神经网络中,需要全连接层的原因。
卷积网络中的核心------Channel(通道)
在训练时,若输入的数据是黑白图片,我们通常会用下面的tensor进行表示:
[b, w, h, c] = [b, 32, 32, 1]
这里的1表示1通道。若我们输入的数据时彩色图片,我们通常会使用下面的tensor进行表示:
[b, w, h, c] = [b, 32, 32, 3]
这里的3表示RGB三通道。这些通道的物理意义在我们日常生活中是十分了解的。但是,当训练数据进过卷集层后,其通道数在发生变化,例如:

那么,当通道数大于3时,其物理意义是什么呢?这里,少奶奶将给出自己的理解。
通道的物理意义
通道说白了还是图片,由0~255之间的像素构成,但和我们平常看到的图片不同的是,当通道数越多,其表达的内容就越抽象,包含的信息虽毫无章法,但都是高维的重要信息,就好像抽象画一样,我们很难明白该通道(图片)所展示的内容。例如,一张图片有三个通道(人肉眼可见),但在经过不同层后,图片的尺寸在减少,即图片中内容的位置信息在减少,当某一个卷集层中有n个卷积核,那么在最后的输出结果中,通道的个数等于n,即不同卷积核按照不同的观察方式把位置纬度的信息抽象化后,转化到不同通道上去, 所以,通道越多,从图片中获取的信息就越多。
卷积神经网络中通道的工作方式
我们知道通道的物理意义后,少奶奶将讲解一下,在神经网络中,通道之间是如何变化的。
少奶奶以一张彩色图片为例,其形状为: [1, 32, 32, 3]。
在第一层中,我们用四个卷积核对该图片进行卷积操作
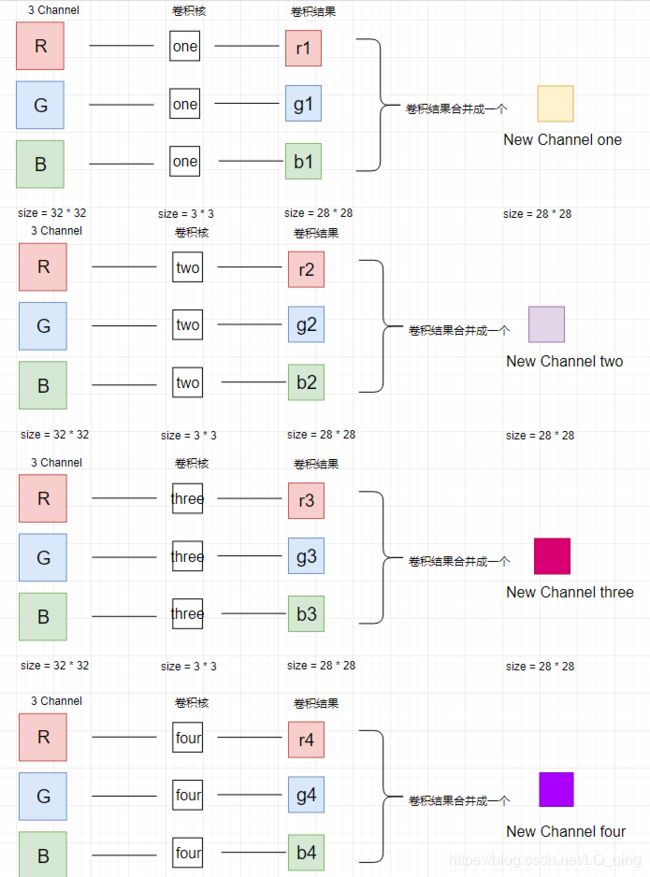
观察图片可以知道,卷积核会先对输入数据的所有通道分别进行卷积,得到对应个数的特征图,然后把这些结果合并成一个通道,这样就实现了一个卷积核输出一个通道的目的,在上图中,我们使用了4个卷积核,那么,在最后输出结果中,我们可以得到4个通道,即:
[1, 32, 32, 3 ] ------ >[1, 28, 28, 4]
这样就实现了把图片中位置纬度的信息细化到更多通道中去的目的。同理可得,其他层的卷积方式也可以用上面的流程进行解释。
实战部分
cifar 100 数据集简介
cifar 10数据集中的标签只有10类,而cifar 100数据集对每一类又划分成了10小类,总共有100个类别。例如:在cifar 100中,猫可分为,波斯猫,埃及猫,巴厘猫等。cifar 100数据集由50k训练集,10k测试集构成的32 * 32尺寸的图片,总的来说,该数据集比cifar 10更加复杂。
卷积神经网络结构
在本次实战中,我们使用的是一个13层的卷积神经网络,其具体结构如下
该网络模型是由10层卷积层结合3层全连接层构成的网络模型,所以,在编码过程中,我们需要分别构建一个卷积网络模型和一个全连接模型,为了更好的使用到前面几章的知识点,在构建全连接模型时,我们使用自定义模型的方式进行实现。
-
import tensorflow
as tf
-
from tensorflow
import keras
-
from tensorflow.keras
import datasets,layers,optimizers,Sequential,metrics
-
-
import os
-
import matplotlib.pyplot
as plt
-
-
os.environ[
"TF_CPP_MIN_LOG_LEVEL"] =
'2'
-
tf.random.set_seed(
2345)
-
# load dataset
-
(x, y), (test_x, test_y) = datasets.cifar100.load_data()
-
print(y.shape)
-
-
# 数据预处理
-
def progress(x, y):
-
x =
2 * tf.cast(x, dtype=tf.float32) /
255.
-1
-
y = tf.cast(y, dtype=tf.int32)
-
return x, y
-
# 构建dataset对象
-
db_train = tf.data.Dataset.from_tensor_slices((x, y))
-
db_train = db_train.shuffle(
1000).map(progress).batch(
128)
-
db_test = tf.data.Dataset.from_tensor_slices((test_x, test_y))
-
db_test = db_test.map(progress).batch(
64)
-
-
train_next = next(iter(db_test))
-
print(train_next[
0].shape, train_next[
1].shape)
-
# show images
-
#画图
-
# plt.close('all')
-
# plt.figure(figsize=(10,10))
-
# for i in range(25):
-
# plt.subplot(5,5,i+1)
-
# plt.xticks([])
-
# plt.yticks([])
-
# plt.grid('off')
-
# plt.imshow(train_next[0][i],cmap=plt.cm.binary)
-
# plt.show()
-
-
# 构建前半部分的卷积网络
-
cov_network = [
-
# unit 1
-
# 64代表着 利用64个卷积核把原先3通道的图片卷积成64通道
-
layers.Conv2D(
64, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.Conv2D(
64, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.MaxPool2D(pool_size=[
2,
2], strides=
2, padding=
'same'),
-
-
# unit 2
-
# 128代表着 利用128个卷积核把原先64通道的图片卷积成128通道
-
layers.Conv2D(
128, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.Conv2D(
128, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.MaxPool2D(pool_size=[
2,
2], strides=
2, padding=
'same'),
-
-
# unit 3
-
layers.Conv2D(
256, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.Conv2D(
256, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.MaxPool2D(pool_size=[
2,
2], strides=
2, padding=
'same'),
-
-
# unit 4
-
layers.Conv2D(
512, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.Conv2D(
512, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.MaxPool2D(pool_size=[
2,
2], strides=
2, padding=
'same'),
-
-
# unit 5
-
layers.Conv2D(
512, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.Conv2D(
512, kernel_size=[
3,
3], padding=
"same", activation=tf.nn.relu),
-
layers.MaxPool2D(pool_size=[
2,
2], strides=
2, padding=
'same')
-
]
-
-
# 自定义层
-
class myDense (layers.Layer):
-
# 实现__init__()方法
-
def __init__(self, in_dim, out_dim):
-
# 调用母类中的__init__()
-
super(myDense, self).__init__()
-
-
self.kernel = self.add_variable(
'w', [in_dim, out_dim])
-
self.bias = self.add_variable(
'b', [out_dim])
-
# 实现call()方法
-
def call(self, inputs, training = None):
-
# 构建模型结构
-
out = inputs @ self.kernel + self.bias
-
return out
-
#自定义网络模型
-
class myModel(keras.Model):
-
-
def __init__(self):
-
# 调用母类中的__init__()方法
-
super(myModel, self).__init__()
-
# 调用自定义层类 并构建每一层的连接数
-
self.fc1 = myDense(
512,
256)
-
self.fc2 = myDense(
256,
128)
-
self.fc3 = myDense(
128,
100)
-
-
# 构建一个三层的全连接网络
-
def call(self, inputs, training=None):
-
-
# 把训练数据输入到自定义层中
-
x = self.fc1(inputs)
-
# 利用relu函数进行非线性激活操作
-
out = tf.nn.relu(x)
-
x = self.fc2(out)
-
out = tf.nn.relu(x)
-
x = self.fc3(out)
-
return x
-
-
-
def main():
-
# 构建卷积网络对象
-
cov_model = Sequential(cov_network)
-
-
# 构建全连接网络对象
-
line_mode = myModel()
-
# 设置模型的输入tensor形状
-
cov_model.build(input_shape=[
None,
32,
32,
3])
-
line_mode.build(input_shape=[
None,
512])
-
# 把两个模型中的权重用一个变量表示,方便后面的权重更新
-
all_trainable = cov_model.trainable_variables + line_mode.trainable_variables
-
# 设置优化器
-
optimizer = optimizers.Adam(lr =
1e-4)
-
# 开始训练
-
for epoch
in range(
50):
-
for step, (x, y)
in enumerate(db_train):
-
-
with tf.GradientTape()
as tape:
-
# 把卷积网络和全连接网络进行组合
-
out = cov_model(x)
-
out = tf.reshape(out, [
-1,
512])
-
logits = line_mode(out)
-
-
y_onehot = tf.one_hot(y, depth=
100)
-
# 利用交叉熵计算loss
-
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=
True)
-
loss = tf.reduce_mean(loss)
-
# 计算梯度
-
grad = tape.gradient(loss, all_trainable)
-
# 梯度更新
-
optimizer.apply_gradients(zip(grad, all_trainable))
-
-
if step%
100 ==
0:
-
print(
'epoch' , epoch ,
'step: ',step,
'loss:' , float(loss))
-
# test
-
total_num =
0
-
total_correct =
0
-
for x, y
in db_test:
-
out = cov_model(x)
-
out = tf.reshape(out, [
-1,
512])
-
logits = line_mode(out)
-
prob = tf.nn.softmax(logits, axis=
1)
-
pre = tf.cast(tf.argmax(prob, axis=
1), dtype=tf.int32)
-
total_correct = total_correct + tf.reduce_sum(tf.cast(tf.equal(pre, y), dtype=tf.int32))
-
total_num = total_num + x.shape[
0]
-
last_correct = int(total_correct) / total_num
-
print(
"epoch:", epoch, last_correct)
-
-
if __name__ ==
'__main__':
-
main()
在下一章里,少奶奶将为大家讲解过拟合的相关概念,帮助大家理解什么是过拟合,以及如何识别和避免过拟合的发生。链接如下
开篇:开启Tensorflow 2.0时代
第一章:Tensorflow 2.0 实现简单的线性回归模型(理论+实践)
第二章:Tensorflow 2.0 手写全连接MNIST数据集(理论+实战)
第三章:Tensorflow 2.0 利用高级接口实现对cifar10 数据集的全连接(理论+实战实现)
第四章:Tensorflow 2.0 实现自定义层和自定义模型的编写并实现cifar10 的全连接网络(理论+实战)
第五章:Tensorflow 2.0 利用十三层卷积神经网络实现cifar 100训练(理论+实战)
第六章:优化神经网络的技巧(理论)
第七章:Tensorflow2.0 RNN循环神经网络实现IMDB数据集训练(理论+实践)
第八章:Tensorflow2.0 传统RNN缺陷和LSTM网络原理(理论+实战)