轻量级网络思想小结
CNN中不同层的参数数量和理论计算量
卷积核Kh*Kw,输入通道数Cin,输出通道数Cout,输出特征图的分辨率为宽H高W。参数数量用params表示,模型大小单位为M,模型大小是参数数量的4倍。理论计算量用FLOPs表示,关系到算法速度。
CONV标准卷积层:
- params:(Kh * Kw * Cin + 1) * Cout
- FLOPs:Kh * Kw * Cin * Cout * H * W
FC全连接层,卷积核k=1:
- params:(Cin + 1) * Cout
- FLOPs:Cin * Cout * H * W
GCONV分组(Group)卷积层,输入按通道数划分为g组,每小组独立分别卷积,结果concat到一起作为输出,Output channels作为GCONV的输入,分了3组分别CONV3x3,组内有信息流通,但不同分组之间没有信息流通。
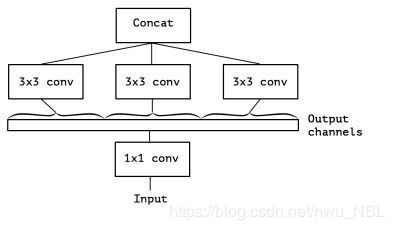
- params:(Kh * Kw * Cin/g * Cout/g) * g = Kh * Kw * Cin * Cout / g
- FLOPs:Kh * Kw * Cin * Cout * H * W / g
DWCONV深度分离(DepthWise)卷积层(Xception),是GCONV的极端情况,分组数量等于输入通道数量,即每个通道作为一个小组分别进行卷积,结果concat作为输出,Cin = Cout = g,没有bias项。
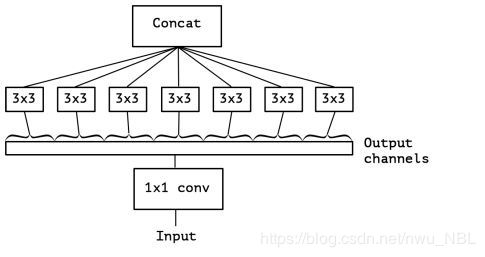
- params:Kh * Kw * Cin * Cout / Cin = Kh * Kw * Cout
- FLOPs:Kh * Kw * Cin * Cout * H * W / Cin = Kh * Kw * Cout * H * W
综合对比:
- CONV层主要贡献了计算量,FC层主要贡献了参数数量。
- GCONV和DWCONV层参数量和计算量都非常小,GCONV参数数量减少g倍,计算量降低g倍,g越大压缩加速越明显;DWCONV是g=Cin的极端情况,压缩加速比是Cin倍,这两者是高效CNN的核心构成要素。
NiN
https://arxiv.org/pdf/1312.4400.pdf
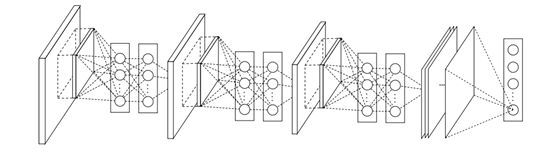
NiN(Network in Network)是Shuicheng Yan组ICLR 2014的论文,提出在CONV3x3中插入CONV1x1层和Global Average Pooling (GAP)层。
- 同等输入CONV1x1比CONV3x3参数数量少9倍,理论计算量降低9倍
- GAP层没有参数,计算量可以忽略不计,是压缩模型的关键技术
GoogLeNet
大量使用CONV1x1层和GAP,与同时期性能相近的VGG-19相比,22层GoogLeNet模型参数少20倍以上,速度快10倍以上。GoogLeNet是最早的高效小网络,Inception系列沿袭这一架构理念,在均衡网络深度和模型大小方面都比较优秀。
Inception v1
https://arxiv.org/pdf/1409.4842v1.pdf

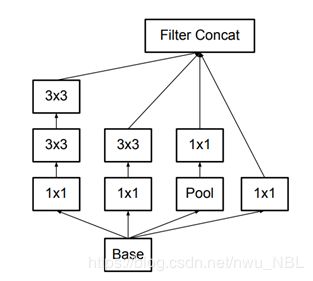
- 图(a)是原始的Inception 模块。使用 3 个不同大小的滤波器(1x1、3x3、5x5)对输入执行卷积操作,此外还会执行最大池化。所有子层的输出最后会被级联起来,并传送至下一个 Inception 模块。
- 图(b)是实现降维的 Inception 模块。为了降低算力成本,在 3x3 和 5x5 卷积层之前添加额外的 1x1 卷积层,来限制输入信道的数量。在最大池化层之后添加1x1 卷积。
Inception v2
https://arxiv.org/pdf/1512.00567v3.pdf
- 将 5×5 的卷积分解为两个 3×3 的卷积运算以提升计算速度。尽管这有点违反直觉,但一个 5×5 的卷积在计算成本上是一个 3×3 卷积的 2.78 倍。所以叠加两个 3×3 卷积实际上在性能上会有所提升,如下图所示:
- 将 n*n 的卷积核尺寸分解为 1×n 和 n×1 两个卷积。例如,一个 3×3 的卷积等价于首先执行一个 1×3 的卷积再执行一个 3×1 的卷积。他们还发现这种方法在成本上要比单个 3×3 的卷积降低 33%,如下图所示:
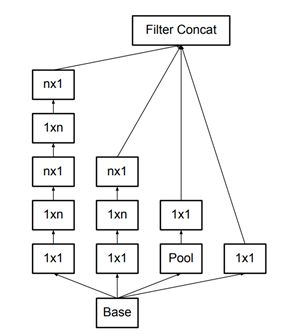
- 模块中的滤波器组被扩展(即变得更宽而不是更深),以解决表征性瓶颈。如果该模块没有被拓展宽度,而是变得更深,那么维度会过多减少,造成信息损失。如下图所示:

Inception v3
https://arxiv.org/pdf/1512.00567v3.pdf
- RMSProp 优化器;
- Factorized 7x7 卷积,将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1);
- 辅助分类器使用了 BatchNorm;
- 标签平滑(添加到损失公式的一种正则化项,旨在阻止网络对某一类别过分自信,即阻止过拟合);
- 网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块。
Inception v4
https://arxiv.org/pdf/1602.07261.pdf
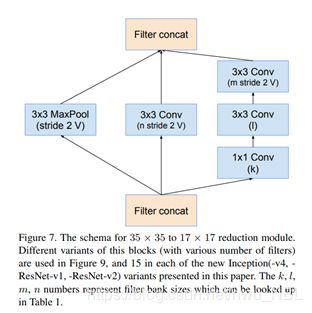
- Inception v4 引入了专用的「缩减块」(reduction block),它被用于改变网格的宽度和高度。早期的版本并没有明确使用缩减块,但也实现了其功能。缩减块 A(从 35x35 到 17x17 的尺寸缩减)如下图所示:
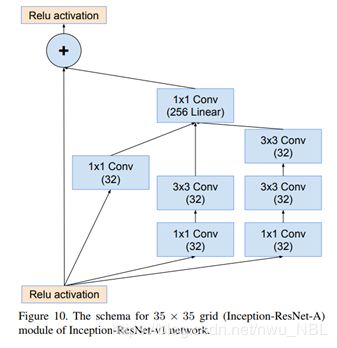
- Inception模块结合Residual Connection,发现ResNet的结构可以极大地加速训练,同时性能也有提升。残差块如下图所示:

- 为了使残差加运算可行,卷积之后的输入和输出必须有相同的维度。因此,我们在初始卷积之后使用 1x1 卷积来匹配深度(深度在卷积之后会增加)。Inception ResNet 中的 Inception 模块 A如下图所示:
SqueezeNet
论文笔记:https://blog.csdn.net/nwu_NBL/article/details/80897387
三个策略来减少SqueezeNet参数:
- 使用1x1卷积代替3x3卷积:参数减少为原来的1/9。
- 减少3x3卷积的输入通道数量:在一个完全由3x3滤波器组成的卷积层中,参数的总量是(输入通道数)x(滤波器数)x(3x3)。为了减少CNN的参数,不仅要减少3x3滤波器的数量,还要减少3x3滤波器的输入通道数量。
- 将降采样操作延后,可以给卷积层提供更大的激活图:更大的激活图保留了更多的信息,可以提供更高的分类准确率。
策略1和2是在尝试保持准确性的同时减少CNN中的参数数量。策略3是在有限的参数预算上最大化准确性。fire module结构如下图所示:

MobileNet
https://arxiv.org/pdf/1704.04861.pdf

MobileNet是第一个面向移动端的小网络,设计兼顾模型小和速度快,提出了Depthwise Separable Convolution深度分离卷积,由DWCONV3x3 + CONV1x1组成,DWCONV3x3将CONV3x3的计算量降低到恐怖程度,后面的CONV1x1帮助信息在通道之间流通。这种结构非常高效,代替CONV后性能微小下降换取速度数倍提升。
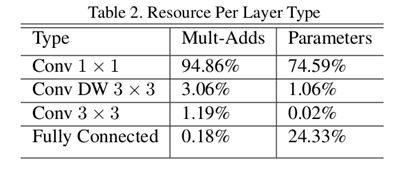
论文的Table 2统计了不同类型层的计算量和参数数量,大量使用的DWCONV3x3计算量仅3%,参数数量仅1%,CONV1x1计算量占95%,参数数量占75%,所以MobileNet速度快不快,与inferece framework中CONV1x1的优化程度密切相关。
进一步优化MobileNet,降低CONV1x1的占比是关键。
MobileNetV2
https://arxiv.org/pdf/1801.04381.pdf
MobileNetV2到底优化了什么?
bottleneck的输出通道数非常小[24 32 64-96 160-320],baseline版本通道数是[144 192 384-576 960-1920]。MobileNetV2设计上是保持DWCONV3x3层通道数基本不变或轻微增加,将bottleneck的输入和输出通道数直接减小t倍,扩展因子其实更像是压缩因子,将CONV1x1层的参数数量和计算量直接减小t倍,轻微增加DWCONV3x3的通道数以保证的网络容量。MobileNetV2中标准卷积更少、深度分离卷积更多。
降低DWCONV-bottleneck block中CONV1x1的占比:
- Inverted Residuals 逆残差:把原来两头大中间小的bottleneck block变成两头小中间大的形式,强行降低了CONV1x1与DWCONV3x3的比例,这里有个超参数expansion factor扩展因子t,推荐是5~10,参数设置小网络小一点,大网络大一点,V2中是t=6。

- Linear Bottlenecks 线性瓶颈:去掉了第二个CONV1x1后面的ReLU,改为线性神经元,其实就是没有非线性激活函数,论文解释是在低维度空间ReLU会破坏信息。
ShuffleNet
https://arxiv.org/pdf/1707.01083.pdf
论文提出了逐点群卷积(pointwise group convolution)帮助降低计算复杂度;但是使用逐点群卷积会有幅作用,故在此基础上,论文提出通道混洗(channel shuffle)帮助信息流通。
Channel Shuffle
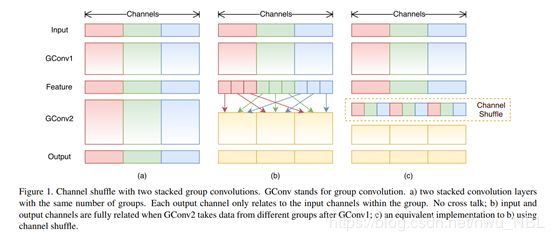
在小型网络中,昂贵的逐点卷积造成有限的通道之间充满约束,这会显著的损失精度。为了解决这个问题,一个直接的方法是应用通道稀疏连接,例如组卷积(group convolutions)。通过确保每个卷积操作仅在对应的输入通道组上,组卷积可以显著的降低计算损失。然而,如果多个组卷积堆叠在一起,会有一个副作用: 某个通道输出仅从一小部分输入通道中导出,如上图(a)所示,这样的属性降低了通道组之间的信息流通,降低了信息表示能力。
混洗操作:

Shufflenet构建块

- 图(a)是残差块。对于主分支部分,我们可将其中标准卷积3×3拆分成深度分离卷积。
- 图(b)是ShuffleNet unit,主分支的1×1Conv改为1×1GConv,加入Channel Shuffle,配合BN层和ReLU激活函数构成基本单元。
- 图(c)是做降采样的ShuffleNet unit,在辅分支加入步长为2的3×3平均池化;原本做元素相加的操作转为了通道级联,这扩大了通道维度,增加的计算成本却很少。