Prometheus+grafana监控:cAdvisor输出的容器内存相关的指标的解读
概述
对容器中的服务进行监控,常见方案是采用Prometheus+grafana。其中对内存的监控有很多指标,本文对它们进行了一些分析和解读,并做了一些试验。我们使用了四台虚机做了一个容器集群,其中一台做容器master,另外三台是容器node节点。
查看cAdvisor输出的内存指标
我们使用kubernetes进行管理,自带了容器监控cAdvisor exporter,可以直接通过页面查看监控指标,例如直接访问一台IP为172.18.12.188的node节点:
http://172.18.12.188:4194/metrics
页面显示如下:

摘取与内存相关的指标,格式类似于:container_memory_xxxxxxx
具体一条container_memory_rss指标的数据如下所示:
container_memory_rss
{
container_name="kube-flannel",
id="/kubepods/besteffort/pod013e338d-6e3a-11e8-b687-fa163e6f3f6b/987ba969e2d44729b03a543cb284ee398f975d75d6a11935c64517b053cfb10f",
image="sha256:2b736d06ca4c91b9fe5fd542b9960d597e0cbf15a2cb0e0f33d3f7e2ec7dbd54",
name="k8s_kube-flannel_kube-flannel-ds-665lq_kube-system_013e338d-6e3a-11e8-b687-fa163e6f3f6b_8",
namespace="kube-system",
pod_name="kube-flannel-ds-665lq"
} 2.4334336e+07
容器监控的内存相关指标
容器内存相关的指标有如下八个,说明如下:
| 名称 | 类型 | 单位 | 说明 |
|---|---|---|---|
| container_memory_rss | gauge | 字节数 bytes |
RSS内存,即常驻内存集(Resident Set Size),是分配给进程使用实际物理内存,而不是磁盘上缓存的虚拟内存。RSS内存包括所有分配的栈内存和堆内存,以及加载到物理内存中的共享库占用的内存空间,但不包括进入交换分区的内存。 |
| container_memory_usage_bytes | gauge | 字节数 bytes |
当前使用的内存量,包括所有使用的内存,不管有没有被访问。 |
| container_memory_max_usage_bytes | gauge | 字节数 bytes |
最大内存使用量的记录。 |
| container_memory_cache | gauge | 字节数 bytes |
高速缓存(cache)的使用量。cache是位于CPU与主内存间的一种容量较小但速度很高的存储器,是为了提高cpu和内存之间的数据交换速度而设计的。 |
| container_memory_swap | gauge | 字节数 bytes |
虚拟内存使用量。虚拟内存(swap)指的是用磁盘来模拟内存使用。当物理内存快要使用完或者达到一定比例,就可以把部分不用的内存数据交换到硬盘保存,需要使用时再调入物理内存 |
| container_memory_working_set_bytes | gauge | 字节数 bytes |
当前内存工作集(working set)使用量。 |
| container_memory_failcnt | counter | 次 | 申请内存失败次数计数 |
| container_memory_failures_total | counter | 次 | 累计的内存申请错误次数 |
用Grafana查看内存指标
以我们部署在容器中的某服务 xy-cloud-html为例,在grafana的dashborad中配置如下查询:
container_memory_rss
container_memory_usage_bytes
container_memory_working_set_bytes
container_memory_max_usage_bytes
查询指标如下:
container_memory_rss{name=~"(k8s_xy-cloud-xy-html).+"}
container_memory_usage_bytes{name=~"(k8s_xy-cloud-xy-html).+"}
container_memory_working_set_bytes{name=~"(k8s_xy-cloud-xy-html).+"}
container_memory_max_usage_bytes{name=~"(k8s_xy-cloud-xy-html).+"}
实际显示的结果如下:
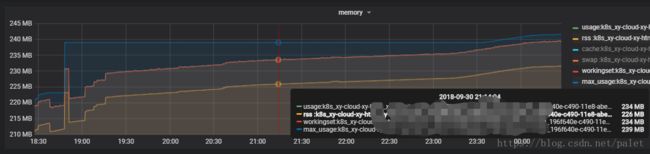
可以看出:
container_memory_max_usage_bytes > container_memory_usage_bytes >= container_memory_working_set_bytes > container_memory_rss
这个也基本可以理解。在我们这个环境的例子中,container_memory_usage_bytes 跟 container_memory_working_set_bytes 几乎重合,可能是因为虚拟内存使用几乎为零的原因。见下图:
container_memory_swap
查询指标如下:
container_memory_swap{name=~"(k8s_xy-cloud-xy-html).+"}显示结果是:
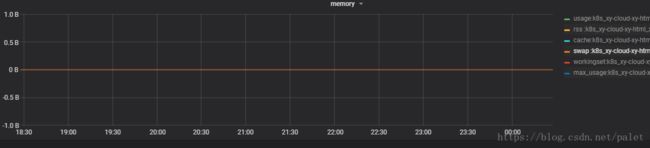
可见在我们的测试环境中容器服务 xy-cloud-html虚拟内存的使用为0。
container_memory_cache
查询指标如下:
container_memory_cache{name=~"(k8s_xy-cloud-xy-html).+"}显示结果是:
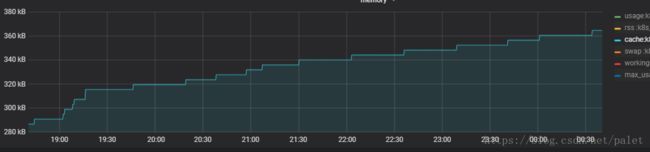
可见在我们的测试环境中,容器服务 xy-cloud-html高速缓存cache的使用量才几百kB,非常小。
container_memory_failcnt
因为这个是count类型的指标,我们用的是 rate函数,统计5分钟内的错误率,尝试了两种查询指标,如下:
rate(container_memory_failcnt{name=~"(k8s_xy-cloud-xy-html).+"}[5m])
rate(container_memory_failcnt{name=~".+"}[5m])其中按上面第二行的指标进行查询,显示结果是:
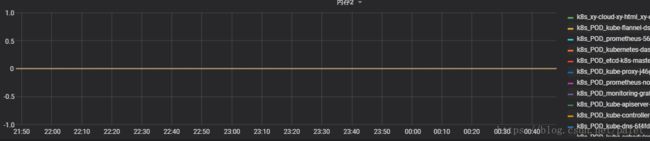
也就是说,所有服务都没有内存错误。
container_memory_failures_total
通过分析这个指标,发现对于同一个容器name,其中有两个label:scope和type
container_memory_failures_total{......,name="xy-cloud-xy-html-7d5c95f6c-txd69",scope="container",type="pgfault"}
container_memory_failures_total{......,name="xy-cloud-xy-html-7d5c95f6c-txd69", scope="container",type="pgmajfault"}
container_memory_failures_total{......,name="xy-cloud-xy-html-7d5c95f6c-txd69",scope="hierarchy",type="pgfault"}
container_memory_failures_total{......,name="xy-cloud-xy-html-7d5c95f6c-txd69",scope="hierarchy",type="pgmajfault"}
其中type有两种取值:pgfault 和 pgmajfault,有的文章解释为:
pgfault #从启动到现在二级页面错误数
pgmajfault #从启动到现在一级页面错误数
对于scope,取值为container 和hierarchy,具体意义还有待研究。
设置grafana的不同查询方式进行一些试验:
rate(container_memory_failures_total{name=~".+",type="pgfault",scope="hierarchy"}[5m])
rate(container_memory_failures_total{name=~"(k8s_xy-cloud-xy-html).+"}[5m])其中按上面第二行的指标,对某个特定的容器服务xy-cloud-html的内容错误进行查询,显示结果是:
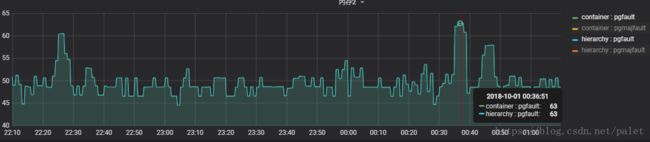
其中二级页面错误pgfaul为50多个,scope为container 和hierarchy时,取值都一样。
一级页面错误pgmajfault 为0,此处就不截图了。
附:指标的原始注释
# HELP container_memory_rss Size of RSS in bytes.
# TYPE container_memory_rss gauge# HELP container_memory_swap Container swap usage in bytes.
# TYPE container_memory_swap gauge
# HELP container_memory_usage_bytes Current memory usage in bytes, including all memory regardless of when it was accessed
# TYPE container_memory_usage_bytes gauge# HELP container_memory_working_set_bytes Current working set in bytes.
# TYPE container_memory_working_set_bytes gauge# HELP container_memory_cache Number of bytes of page cache memory.
# TYPE container_memory_cache gauge
# HELP container_memory_failcnt Number of memory usage hits limits
# TYPE container_memory_failcnt counter以上的注释怀疑是写错了!!!
# HELP container_memory_failures_total Cumulative count of memory allocation failures.
# TYPE container_memory_failures_total counter
# HELP container_memory_max_usage_bytes Maximum memory usage recorded in bytes
# TYPE container_memory_max_usage_bytes gauge