Hadoop之MapReduce(实践篇)
1、MapReduce编程模型概述
MapReduce应用广泛的原因之一在于它的易用性。它提供了一个因高度抽象化而变得异常简单的编程模型。MapReduce是在总结大量应用的共同特点的基础上抽象出来的分布式计算框架,它适用的应用场景往往具有一个共同的特点:任务可被分解成相互独立的子问题。基于该特点,MapReduce编程模型给出了其分布式编程方法,共分5个步骤:
迭代(iteration):遍历输入数据,并将之解析成key/value对;
将输入key/value对映射(map)成另外一些key/value对;
依据key对中间数据进行分组(grouping);
以组为单位对数据进行规约(reduce);
迭代。将最终产生的key/value对保存到输出文件中。
MapReduce将计算过程分解成以上5个步骤带来的最大好处是组件化和并行化。
为了实现MapReduce编程模型,Hadoop设计了一系列对外编程接口。从MapReduce自身的命名特点可以看出,MapReduce由两个阶段组成:Map阶段和Reduce阶段。用户只需要编写map()和reduce()两个方法,即可完成简单的分布式程序的设计实现。
map()方法以key/value对作为输入,产生另外一系列key/value对作为中间输出写入本地磁盘。MapReduce框架会自动将这些中间数据按照key值进行聚集,且key值相同(用户可以设定聚集策略,默认情况下是对key值进行哈希取模)的数据被统一交给reduce()方法处理。
reduce()方法以key及对应的value列表作为输入,经合并key相同的value值后,产生另外一系列key/value对作为最终输出写入HDFS。
2、MapReduce编程入门之”HelloWorld”
下面以MapReduce中的“helloworld”程序——WordCount为例介绍程序设计方法。
“hello world”程序是我们学习任何一门编程语言编写的第一个程序,它简单且易于理解,能够帮助我们快速入门。同样,分布式处理框架也有自己的“hello world”程序:WordCount。它完成的功能是统计输入文件中的每个单词出现的次数。
下面是本人自己编写的HelloWorld程序——MyWordCount。
MyWordCountMapper.java程序代码,如下图所示。因为MyWordCount是这篇文章的第一个程序,因此在这里就做详细的解释,后续的程序就只做简单的注释了。

MyWordCountReducer.java程序代码,如下图所示。

MyWordCountMain.java主程序代码,如下图所示。

编写完MapReduce程序后,按照一定的规则制定程序的输入和输出目录,并提交到Hadoop集群中。作业在Hadoop中的执行过程如下图所示。Hadoop将输入数据切分成若干个输入分片(input split),并将每个split交给一个Map Task处理;Map Task不断地从对应的split中解析出一个个key/value对,并调用map()方法进行处理,处理完之后根据Reduce Task个数将结果分成若干个分区(partition)写到本地磁盘;同时,每个Reduce Task从每个Map Task上读取属于自己的那个partition,然后使用基于排序的方法将key相同的数据聚集在一起,调用reduce()方法进行处理,并将最终结果输出到文件中。
下图为MyWordCount程序执行的过程。
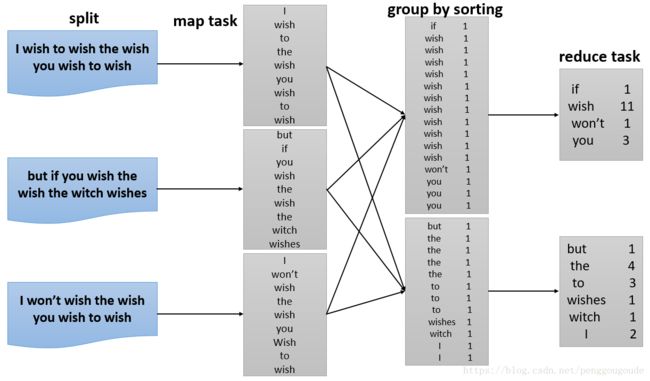
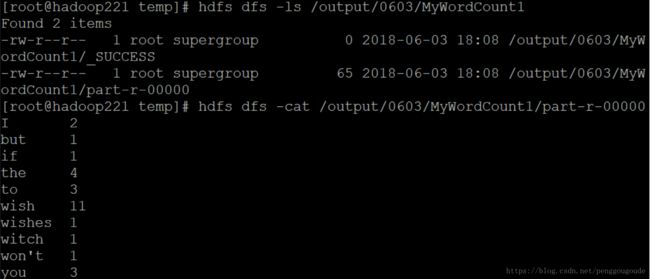
MyWordCount程序在HDFS上执行的结果,如下图所示。
细心的你也许已经注意到,上面的程序还缺少三个基本组件,它们的功能分别是:1、指定输入文件格式。将输入数据切分成若干个split,且将每个split中的数据解析成一个个map()方法要求的key/value对;2、确定map()方法产生的每个key/value对发给哪个Reduce Task方法处理;3、指定输出文件格式,即每个key/value对以何种形式保存到输出文件中。
在Hadoop MapReduce中,这三个组件分别是InputFormat、Partitioner和OutputFormat,它们均需要用户根据自己的应用需求进行配置。而对于上面的WordCount程序实例,默认情况下Hadoop采用的默认实现正好可以满足要求,因而不必再提供。综合来看,Hadoop MapReduce对外提供了5个可编程组件,分别是InputFormat、Mapper、Partitioner、Reducer以及OutputFormat。
下面再举一个比较简单的例子,对一张员工表求每个部门的工资总额,表中的数据内容如下图所示,每一行的对应的列名分别为:
1、员工号;2、员工姓名;3、职务;4、老板号;5、入职日期;6、工资;7、奖金;8、部门号。

该实例的MapReduce程序如下。
MyCountSalarySumMapper.java程序代码,如下图所示。

MyCountSalarySumReducer.java程序代码,如下图所示。

MyCountSalarySumMain.java主程序代码,如下图所示。

该实例的MapReduce程序运行结果,如下图所示。

3、MapReduce的核心——Shuffle(洗牌)
Shuffle的本意是洗牌,它把一组有一定规则的数据尽可能地转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle过程更像是洗牌的逆过程,把一组无规则的数据尽可能地转换成一组具有一定规则的数据。
从前面的编程实践中我们已经知道,MapReduce计算模型包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出就是Reduce的输入,Reduce通过Shuffle过程来获取数据。
从Map输出到Reduce输入的整个过程可以广义地称作为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包含Partition、Sort和Spill过程,在Reduce端包含copy和sort过程,整个Shuffle过程如下图所示:

A、Map端
当Map程序开始产生结果的时候,并不是直接写到文件,而是利用缓存做一些排序方面的预处理工作。每个Map任务都有一个循环内存缓冲区(默认为100MB),当缓存的数据大小达到80%时,后台Spill线程就会将缓存的数据写出到文件,此时Map任务可以继续输出结果,但如果缓冲区满了,则Map任务将暂停等待。
Map程序写出到文件使用round-robin方式,在写出到文件之前,先将数据按照Reduce进行分区,对于每一个分区,都会在内存中根据key进行排序,如果配置了Combiner,则排序后执行Combiner(Combiner的使用,可以减少写入文件和传输的数据,提高MapReduce程序的运行效率)。
每当Map程序输出的结果达到缓冲区的阈值时,都会创建一个文件,在Map程序运行结束时,可能会产生大量的文件。在Map完成前,会将这些文件进行合并和排序,如果文件的数量超过3个,则合并后会再次运行Combiner(1或2个就没有这个必要了)。如果配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据。一旦Map完成,则通知任务管理器,此时Reduce程序就可以开始复制Map的结果数据。
B、Reduce端
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据,每个节点都会启动一个常驻的HTTP Server,其中一项服务就是响应Reduce拖取Map数据。当有MapOutput的HTTP请求过来的时候,HTTP Server就读取相应的Map输出文件中对应这个Reduce部分的数据,然后通过网络流输出给Reduce任务。
Map输出的结果数据都存放在运行Map任务的机器的本地磁盘上,如果Map输出的结果数据较小就直接读入到内存中,如果Map输出的结果数据较大,则需要存放到磁盘上。这样Reduce任务拖过来的数据有些放在内存中,有些放在磁盘上,需要先对这些数据做一个全局合并操作后,再执行Reduce方法,最终Reduce结果输出到HDFS文件系统中。
4、MapReduce的特性
A、排序
数据排序是执行许多任务时要完成的第一步工作,比如学生成绩评比、数据建立索引等。MapReduce程序默认已经对输出到HDFS文件的数据进行了排序,它是根据Map端的输出key值来进行排序,如果key值的数据类型为数值型,则按照数值升序排序;如果key值为字符串型,则按照字典升序排序。如果需要MapReduce程序按照我们的意愿对输出数据进行排序,则需要定义自己的比较器,下面仍使用员工表来测试该程序,代码如下。
MySalarySortMapper.java程序代码,如下图所示。

MySalarySortComparator.java比较器程序代码,如下图所示。

MySalarySortMain.java主程序代码,如下图所示。

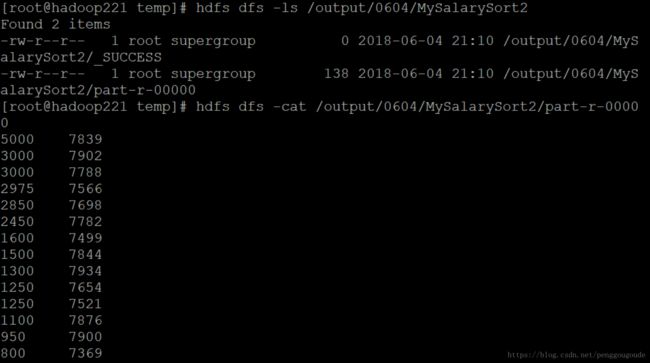
该实例的MapReduce程序运行结果,如下图所示,第一列是按降序排序的员工工资,第二列是员工号。
B、序列化
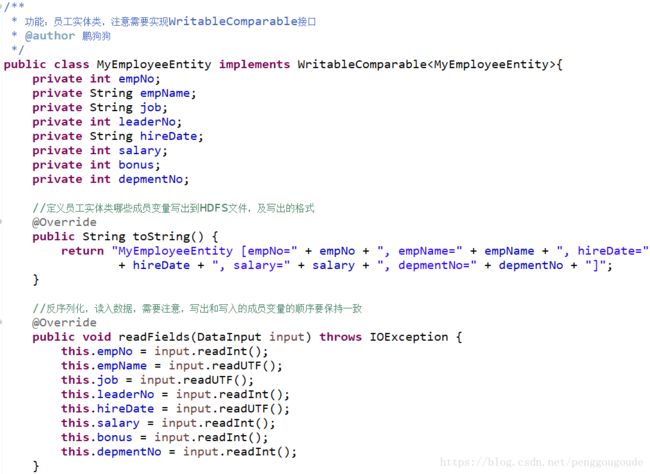
在MapReduce程序中,数据通常需要通过网络进行传输或者持久化到本地文件,因而需要对使用到的数据类型进行序列化,在MapReduce中,其基本数据类型都实现了序列化,因而可以直接进行使用。在MapReduce程序中,对一个实体类进行序列化,只需要在类定义时实现Writable接口即可。下面举一个按照类中的多个数据进行排序的实例(对员工表中的数据,按照部门号和工资进行升序排序),由于该程序不仅使用到了数据实体类,还需要使用到比较器Comparator,因此需要继承WritableComparable接口。该实例代码如下。
注意:下面MyEmployeeEntity实体类get和set方法代码没有给出。
MyEmployeeEntity.java员工实体类程序代码,如下图所示。

MyEmployeeObjectSortMapper.java程序代码,如下图所示。


MyEmployeeObjectSortMain.java主程序代码,如下图所示。

该实例的MapReduce程序运行结果如下图所示。从图中可以看到,最后一列部门号是按照10,20,30升序排序,在部门号相同的情况下,又按照倒数第二列员工工资升序进行排序。

C、分区
在MapReduce程序中,使用分区可以将数据进行归类存储,并且能够提高数据查询的效率。默认情况下,在MapReduce中只有一个分区,使用的是HashPartitioner,根据key的hashcode%reducetask的结果来分区,一个分区对应HDFS上的一个输出文件。如果要按照我们自己的需求进行分区,则需要自定义数据分发组件继承抽象类:Partitioner。需要注意的是,分区是按照Map端输出key的值来进行计算的。下面举一个实例,对员工表按照部门号进行分区,代码如下。
MyPartitionMapper.java程序代码,如下图所示。

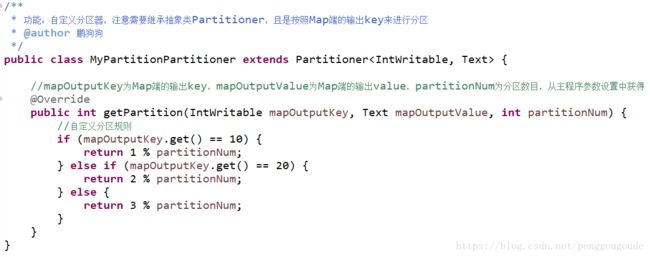
MyPartitionPartitioner.java分区组件类程序代码,如下图所示。
MyPartitionReducer.java程序代码,如下图所示。

MyPartitionMain.java主程序代码,如下图所示。

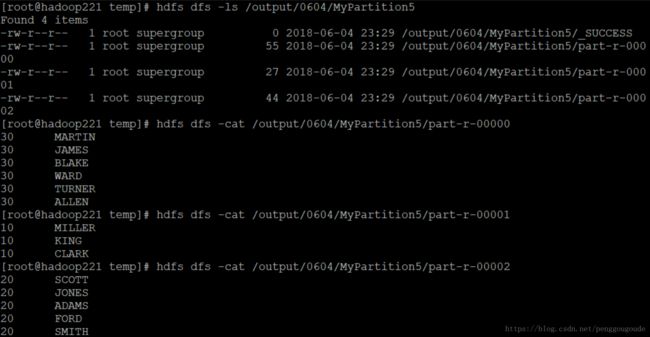
该实例的MapReduce程序运行结果,如下图所示。从图中可以看到,程序的结果分别存放到了三个文件中,每个文件中存放的是一类部门号的员工。
D、合并
每一个Map可能会产生大量的输出,Combiner的作用就是在Map端对输出先做一次合并操作,以减少传输到Reducer端的数据量。Combiner最基本的功能是实现本地key的归并,Combiner具有类似本地Reducer的作用。如果不用Combiner,那么所有的结果都是Reducer完成,效率会相对低下;使用Combiner,先完成的Map会在本地进行聚合,提升速度。
需要注意的是,Combiner的使用要非常谨慎,因为它在MapReduce过程中可能调用也可能不调用,可能调用一次也可能调用多次。Combiner的输出是Reducer的输入,如果Combiner是可插拔的,添加Combiner决不能改变最终的计算结果,所以Combiner只应该用于Reducer的输入key/value与输出key/value类型完全一致,且不影响最终结果的场合,比如累加、求最大值等。
下面举个实例,求多个文件中所有数据的累加和,代码如下。
MyCombineMapper.java程序代码,如下图所示。

MyCombineCombiner.java连接器组件类程序代码,如下图所示。

MyCombinerReducer.java程序代码,如下图所示。

MyCombinerMain.java主程序代码,如下图所示。

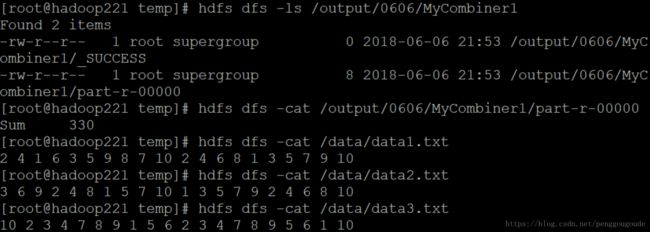
程序的输入路径为:/data/,该目录下包含三个文件,分别为data1.txt,data2.txt,data3.txt,,程序运行时会依次读取这三个文件中的内容,最终运行结果如下图所示:
5、使用MapReduce实现倒排索引
倒排索引是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方法。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而被称为倒排索引(Inverted Index)。
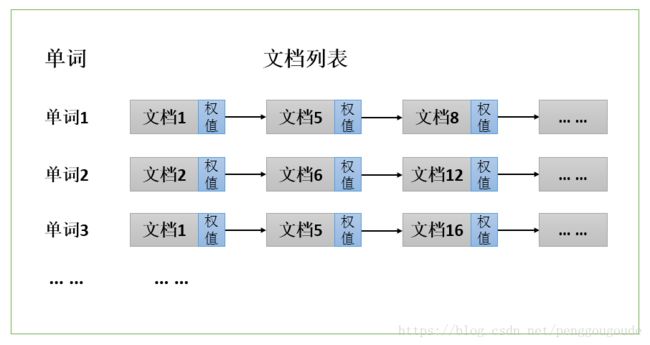
通常情况下,倒排索引由一个单词(或词组)以及相关的文档列表组成,文档列表中的文档或者是标识文档的ID号,或者是指文档所在位置的URL,如下图所示:
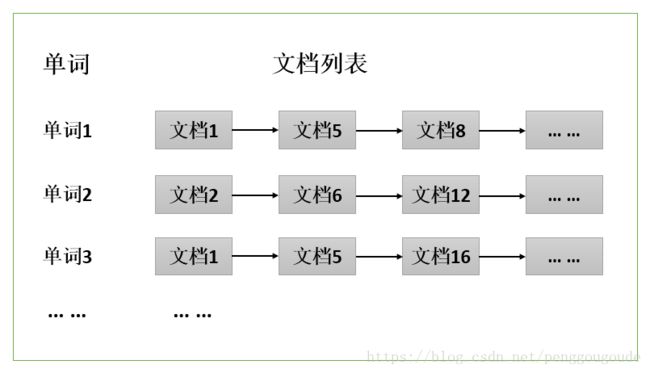
从上图可以看到,单词1出现在了{文档1,文档5,文档8,… …}中,单词2出现在了{文档2,文档6,文档12,… …}中,而单词3出现在了{文档1,文档5,文档16,… …}中。在实际应用场景中,通常还需要给每个文档添加一个权重值,用来表示每个文档与搜索内容的相关度,如下图所示。
最常见的是使用词频来作为权重值,即记录单词在文档中出现的次数。以英文单词为例,如下图所示,索引文件中的“MapReduce”一行表示:“MapReduce”这个单词在文本T0中出现过一次,在文本T1中出现过一次,在文本T2中出现过一次。当搜索条件为“MapReduce”、“is”、“Simple”时,对应的集合为:{T0,T1,T2}∩{T0,T1}∩{T0,T1}={T0,T1},即文档T0和T1包含了所要索引的全部单词,而且只有T0是连续的。

更复杂的权重还可能要记录单词在多少个文档中出现过,或者考虑单词在文档中的位置信息(单词是否出现在标题中,反映了单词在文档中的重要性)等。下面举一个倒排索引的实例:


实现上述倒排索引实例的MapReduce程序代码如下。
MyRevertedIndexMapper.java程序代码,如下图所示。

MyRevertedIndexReducer.java程序代码,如下图所示。


MyRevertedIndexMain.java主程序代码,如下图所示。

该实例的MapReduce程序运行结果如下图所示。从图中可以看到,输出结果按照单词的字母顺序进行了排序,这是MapReduce程序默认做的,结果与上面分析给出的图是一致的。

6、使用MRUnit进行单元测试
使用MRUnit对MapReduce程序进行单元测试,需要从官网下载相应的jar包,下载地址为:http://mrunit.apache.org/。其基本原理是结合使用了JUnit和EasyMock,核心的单元测试依赖于JUnit,并且MRUnit实现了一套Mock对象来控制MapReduce框架的输入和输出,从整体上来说,语法比较简单。在使用的过程中,需要特别注意的是,将mrunit-1.1.0-hadoop2.jar添加到Build Path中,并且将mockito-all-1.8.5.jar从Build Path中去掉。
下面以MyWordCount程序为例,简单介绍下如何使用MRUnit对MapReduce程序进行单元测试。
测试MyWordCountMapper类的基本功能的单元测试方法代码,如下图所示。我们需要很清楚该类的功能逻辑,对于输入的一条数据,输出的结果是怎样的,这样才能在单元测试方法代码中对输入和输出数据进行指定。当测试成功时,Eclipse工具会在界面左侧的Junit区域以绿色进行提示。

测试MyWordCountReducer类的基本功能的单元测试方法代码,如下图所示。同样地,我们也需要知道该类的功能逻辑,输入数据和输出数据分别是怎样的,然后在测试方法代码中进行指定。由于Reducer的输入数据中,Value数据是一个集合,因此在测试方法中使用列表进行指定。

测试整个MyWordCount MapReduce程序的基本功能的单元测试方法代码,如下图所示。这个测试方法将自己编写的Mapper类和Reducer类结合起来进行单元测试,由于MapReduce程序默认对数字和字母进行升序排序,因此在指定Reducer输出数据时,需要严格按照顺序进行设定,否则程序运行会失败。

更多大数据技术精彩内容,欢迎关注

参考文献:
——《Hadoop技术内幕 深入理解MapReduce架构设计与实现原理》
——《CSDN其他博文》
——《潭州大数据课程课件》