Machine Learning with Scikit-Learn and Tensorflow 7.8 AdaBoost
书籍信息
Hands-On Machine Learning with Scikit-Learn and Tensorflow
出版社: O’Reilly Media, Inc, USA
平装: 566页
语种: 英语
ISBN: 1491962291
条形码: 9781491962299
商品尺寸: 18 x 2.9 x 23.3 cm
ASIN: 1491962291
系列博文为书籍中文翻译
代码以及数据下载:https://github.com/ageron/handson-ml
Boosting是将弱的模型整合成为强的模型的方法,核心思想逐个训练模型,当前的模型尝试纠正前面的模型的错误。Boosting的方法有许多,著名的方法包括AdaBoost(Adaptive Boosting)和Gradient Boosting。
当前模型纠正错误的方法包括更加关注前面模型的错误,这样的过程导致新的模型越来越关注困难的训练数据,这是AdaBoost的核心思想。
例如,当我们使用AdaBoost进行分类时,第1个模型(例如决策树)训练后预测训练数据,预测错误的训练数据权重升高。第2个模型使用新的权重训练然后预测训练数据,训练数据的权重再次被修改,以此类推。
下图展示逐个训练的模型的决策边界(基础模型是高度正则化的SVM)。第1个模型存在许多预测错误的训练数据,这些训练数据的权重升高,第2个模型因此取得更加优秀的效果。右边是学习速率(预测错误的训练数据权重增加速率)减半的结果。
from sklearn.svm import SVC
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf, X, y, axes=[-1.5, 2.5, -1, 1.5], alpha=0.5):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", alpha=alpha)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", alpha=alpha)
plt.axis(axes)
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
m = len(X_train)
plt.figure(figsize=(11, 4))
for subplot, learning_rate in ((121, 1), (122, 0.5)):
sample_weights = np.ones(m)
for i in range(4):
plt.subplot(subplot)
svm_clf = SVC(kernel="rbf", C=0.05)
svm_clf.fit(X_train, y_train, sample_weight=sample_weights)
y_pred = svm_clf.predict(X_train)
sample_weights[y_pred != y_train] *= (1 + learning_rate)
plot_decision_boundary(svm_clf, X, y, alpha=0.2)
plt.title("learning_rate = {}".format(learning_rate - 1), fontsize=16)
plt.subplot(121)
plt.text(-0.7, -0.65, "1", fontsize=14)
plt.text(-0.6, -0.10, "2", fontsize=14)
plt.text(-0.5, 0.30, "3", fontsize=14)
plt.text(-0.3, 0.60, "4", fontsize=14)
plt.show()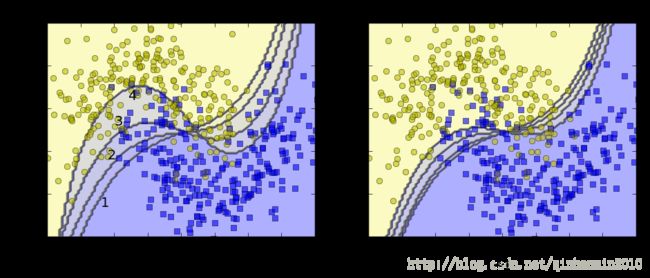
注释:
实例用于展示,事实上,SVM不适合作为AdaBoost的基础模型,因为SVM训练速度慢且使用时不稳定。
AdaBoost逐个训练模型的思想类似梯度下降。不同的是,梯度下降尝试通过寻找最优参数最小化代价函数,AdaBoost通过添加新的模型提升模型的效果。所有模型训练完成后,AdaBoost使用类似bagging的方式整合结果,只是不同的模型根据他们在带权训练数据的预测结果拥有不同的权重。
注释:
Boosting逐个训练模型的缺点是无法并行,当前模型只有在前面的模型训练完成后才能开始训练。
让我们详细分析AdaBoost。初始化时,训练数据的权值 wi 是 1m (m是训练数据数量),第1个模型训练后预测训练数据,其在带权训练数据的错误率 rj 是预测正确的训练数据的权值和除以训练数据的权值和。当前模型的权值 αj=η log1−rjrj 。其中 η 是学习速率(默认是1)。模型的效果越好,权重越高。如果模型接近随机猜测,那么模型的权重接近0。如果模型经常错误,那么模型的权重是负值。
然后,训练数据的权重被修改。如果预测值与实际值相同,那么权重 wi 不变,否则权重 wi 变为 wiexp(αj) 。注意最后所有权重需要除以 ∑mi=1wi 。
最后,第2个模型使用新的权重训练。这样的过程持续到模型的数量达到要求或者得到完美的模型。
进行预测时,AdaBoost计算所有模型的预测结果,最终的结果是获得模型权值最多的结果。
实际上,scikit-learn使用的是SAMME。当标签只有两类时,SAMME与AdaBoost相同。另外,如果基础模型能够预测类别概率,scikit-learn使用SAMMER,核心思想是通过基础模型的类别概率而不是预测结果得到最终的结果,通常能够获得更好的效果。
译者注:
根据官方文档,AdaBoostClassifier使用的是AdaBoost-SAMME和AdaBoost-SAMME.R(通过algorithm参数选择),AdaBoostRegressor使用的是AdaBoost.R2。
以下是AdaBoost实例。
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf, X, y, axes=[-1.5, 2.5, -1, 1.5], alpha=0.5):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap, linewidth=10)
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", alpha=alpha)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", alpha=alpha)
plt.axis(axes)
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=2), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5, random_state=42
)
ada_clf.fit(X_train, y_train)
plot_decision_boundary(ada_clf, X, y)
注释:
如果Adaboost存在过拟合的问题,可以考虑减少模型数量或正则化基础模型。