Java后端面试题(Java基础)(更新中)
1.JAVA中的几种基本数据类型是什么,各自占用多少字节.
先了解2个单词:
1、bit --位:位是计算机中存储数据的最小单位,指二进制数中的一个位数,其值为“0”或“1”。
2、byte --字节:字节是计算机存储容量的基本单位,一个字节由8位二进制数组成。在计算机内部,一个字节可以表示一个数据,也可以表示一个英文字母,两个字节可以表示一个汉字。
- 1B=8bit
- 1Byte=8bit
- 1KB=1024Byte(字节)=8*1024bit
- 1MB=1024KB
- 1GB=1024MB
- 1TB=1024GB
3、基本数据类型注意事项:
- 未带有字符后缀标识的整数默认为int类型;未带有字符后缀标识的浮点数默认为double类型。
- 如果一个整数的值超出了int类型能够表示的范围,则必须增加后缀“L”(不区分大小写,建议用大写,因为小写的L与阿拉伯数字1很容易混淆),表示为long型。
- 带有“F”(不区分大小写)后缀的整数和浮点数都是float类型的;带有“D”(不区分大小写)后缀的整数和浮点数都是double类型的。
- 编译器会在编译期对byte、short、int、long、float、double、char型变量的值进行检查,如果超出了它们的取值范围就会报错。
- int型值可以赋给所有数值类型的变量;
- long型值可以赋给long、float、double类型的变量;
- float型值可以赋给float、double类型的变量;
- double型值只能赋给double类型变量
4、基本数据类型取值范围:

boolean : This data type represents one bit of information, but its "size" isn't something that's precisely defined.(ref)
这种数据类型代表一个比特的信息,但它的“大小”没有明确的定义。(参考)
boolean类型没有给出精确的定义,《Java虚拟机规范》给出了4个字节,和boolean数组1个字节的定义,具体还要看虚拟机实现是否按照规范来,所以1个字节、4个字节都是有可能的。
2.String 类能被继承吗?为什么?
String 被声明为 final,因此它不可被继承。
内部使用 char 数组存储数据,该数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
public final class String implements java.io.Serializable, Comparable, CharSequence {
/** The value is used for character storage. */
private final char value[];
不可变的好处:
1. 可以缓存 hash 值
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
2. String Pool 的需要
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
3. 安全性
String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 对象的那一方以为现在连接的是其它主机,而实际情况却不一定是。
4. 线程安全
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
Program Creek : Why String is immutable in Java?
平常我们定义的String str=”a”;其实和String str=new String(“a”)还是有差异的。
前者默认调用的是String.valueOf来返回String实例对象,至于调用哪个则取决于你的赋值,比如String num=1,调用的是
public static String valueOf(int i) {
return Integer.toString(i);
}
后者则是调用如下部分:
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
最后我们的变量都存储在一个char数组中。
3.String ,StringBuffer,StringBuilder的区别?
1. 可变性
- String 不可变
- StringBuffer 和 StringBuilder 可变
2. 线程安全
- String 不可变,因此是线程安全的
- StringBuilder 不是线程安全的
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
StackOverflow : String, StringBuffer, and StringBuilder
4.ArrayList和LinkedList有什么区别?
ArrayList和Vector使用了基于动态数组的实现,可以认为ArrayList或者Vector封装了对内部数组的操作,比如向数组
中添加,删除,插入新的元素或者数据的扩展和重定向。
LinkedList使用了循环双向链表数据结构。与基于数组的ArrayList 相比,这是两种截然不同的实现技术,这也决
定了它们将适用于完全不同的工作场景。
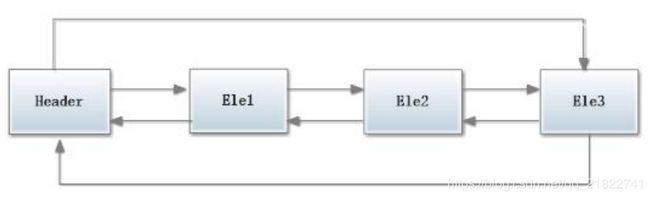
LinkedList链表由一系列表项连接而成。 一个表项总是包含3个部分:元素内容,前驱表和后驱表,如图所示:

在下图展示了一个包含3个元素的LinkedList 的各个表项间的连接关系。在JDK的实现中,无论LikedList 是否
为空,链表内部都有一个header表项,它既表示链表的开始,也表示链表的结尾。表项header的后驱表项便是链表
中第一个元素, 表项header的前驱表项便是链表中最后一个元素。
ArrayList和LinkedList在性能上各有优缺点,都有各自所适用的地方,总的说来可以描述如下:
- 对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是统一的,分配一个内部Entry对象。
- 在ArrayList的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的。
- LinkedList不支持高效的随机元素访问。
- ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
可以这样说:当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
5.讲讲类的实例化顺序,比如父类静态数据,构造函数,字段,子类静态数据,构造函数,字段,当new的时候,他们的执行顺序。
- 父类静态成员和静态初始化块 ,按在代码中出现的顺序依次执行
- 子类静态成员和静态初始化块 ,按在代码中出现的顺序依次执行
- 父类实例成员和实例初始化块 ,按在代码中出现的顺序依次执行
- 父类构造方法
- 子类实例成员和实例初始化块 ,按在代码中出现的顺序依次执行
- 子类构造方法
结论:对象初始化的顺序,先静态方法,再构造方法,每个又是先基类后子类。
6.用过哪些Map类,都有什么区别,HashMap是线程安全的吗,并发下使用的Map是什么,他们内部原理分别是什么,比如存储方式,hashcode,扩容,默认容量等。
HashMap, TreeMap, LinkedHashMap, WeakHashMap, IdentityHashMap
7.JAVA8的ConcurrentHashMap为什么放弃了分段锁,有什么问题吗,如果你来设计,你如何设计。
8.有没有有顺序的Map实现类,如果有,他们是怎么保证有序的。
reeMap和LinkedHashMap是有序的(TreeMap默认升序,LinkedHashMap则记录了插入顺序)。
9.抽象类和接口的区别,类可以继承多个类么,接口可以继承多个接口么,类可以实现多个接口么。
1. 抽象类
抽象类和抽象方法都使用 abstract 关键字进行声明。抽象类一般会包含抽象方法,抽象方法一定位于抽象类中。
抽象类和普通类最大的区别是,抽象类不能被实例化,需要继承抽象类才能实例化其子类。
public abstract class AbstractClassExample {
protected int x;
private int y;
public abstract void func1();
public void func2() {
System.out.println("func2");
}
}
public class AbstractExtendClassExample extends AbstractClassExample {
@Override
public void func1() {
System.out.println("func1");
}
}
// AbstractClassExample ac1 = new AbstractClassExample(); // 'AbstractClassExample' is abstract; cannot be instantiated
AbstractClassExample ac2 = new AbstractExtendClassExample();
ac2.func1();2. 接口
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类。
接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。
接口的字段默认都是 static 和 final 的。
public interface InterfaceExample {
void func1();
default void func2(){
System.out.println("func2");
}
int x = 123;
// int y; // Variable 'y' might not have been initialized
public int z = 0; // Modifier 'public' is redundant for interface fields
// private int k = 0; // Modifier 'private' not allowed here
// protected int l = 0; // Modifier 'protected' not allowed here
// private void fun3(); // Modifier 'private' not allowed here
}
public class InterfaceImplementExample implements InterfaceExample {
@Override
public void func1() {
System.out.println("func1");
}
}
// InterfaceExample ie1 = new InterfaceExample(); // 'InterfaceExample' is abstract; cannot be instantiated
InterfaceExample ie2 = new InterfaceImplementExample();
ie2.func1();
System.out.println(InterfaceExample.x);3. 比较
- 从设计层面上看,抽象类提供了一种 IS-A 关系,那么就必须满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
4. 使用选择
使用接口:
- 需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Compareable 接口中的 compareTo() 方法;
- 需要使用多重继承。
使用抽象类:
- 需要在几个相关的类中共享代码。
- 需要能控制继承来的成员的访问权限,而不是都为 public。
- 需要继承非静态和非常量字段。
在很多情况下,接口优先于抽象类。因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
深入理解 abstract class 和 interface
When to Use Abstract Class and Interface
- 抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。
- 抽象类要被子类继承,接口要被类实现。
- 接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现
- 接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
- 抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
- 抽象方法只能申明,不能实现。abstract void abc();不能写成abstract void abc(){}。
- 抽象类里可以没有抽象方法
- 如果一个类里有抽象方法,那么这个类只能是抽象类
- 抽象方法要被实现,所以不能是静态的,也不能是私有的。
- 接口可继承接口,并可多继承接口,但类只能单根继承。
10.继承和聚合的区别在哪。
继承指的是一个类继承另外的一个类的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;在Java中此类关系通过关键字extends明确标识。

聚合体现的是整体与部分、拥有的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期;比如计算机与CPU、公司与员工的关系等;

11.IO模型有哪些,讲讲你理解的nio ,他和bio,aio的区别是啥,谈谈reactor模型。
IO是面向流的,NIO是面向缓冲区的
12.反射的原理,反射创建类实例的三种方式是什么。
13.反射中,Class.forName和ClassLoader区别 。
1.Java类装载过程

- 装载:通过类的全限定名获取二进制字节流,将二进制字节流转换成方法区中的运行时数据结构,在内存中生成Java.lang.class对象;
- 链接:执行下面的校验、准备和解析步骤,其中解析步骤是可以选择的;
- 校验:检查导入类或接口的二进制数据的正确性;(文件格式验证,元数据验证,字节码验证,符号引用验证)
- 准备:给类的静态变量分配并初始化存储空间;
- 解析:将常量池中的符号引用转成直接引用;
- 初始化:激活类的静态变量的初始化Java代码和静态Java代码块,并初始化程序员设置的变量值。
2. 分析 Class.forName()和ClassLoader.loadClass
Class.forName(className)方法,内部实际调用的方法是 Class.forName(className,true,classloader);
第2个boolean参数表示类是否需要初始化, Class.forName(className)默认是需要初始化。
一旦初始化,就会触发目标对象的 static块代码执行,static参数也也会被再次初始化。
ClassLoader.loadClass(className)方法,内部实际调用的方法是 ClassLoader.loadClass(className,false);
第2个 boolean参数,表示目标对象是否进行链接,false表示不进行链接,由上面介绍可以,
不进行链接意味着不进行包括初始化等一些列步骤,那么静态块和静态对象就不会得到执行
3.数据库链接为什么使用Class.forName(className)
JDBC Driver源码如下,因此使用Class.forName(classname)才能在反射回去类的时候执行static块。
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}14.描述动态代理的几种实现方式,分别说出相应的优缺点。
15.动态代理与cglib实现的区别。
16.为什么CGlib方式可以对接口实现代理。
17.final的用途。
final可以修饰类、方法、成员变量
- 当final修饰类的时候,说明该类不能被继承
- 当final修饰方法的时候,说明该方法不能被重写
-
- 在早期,可能使用final修饰的方法,编译器针对这些方法的所有调用都转成内嵌调用,这样提高效率(但到现在一般我们不会去管这事了,编译器和JVM都越来越聪明了)
- 当final修饰成员变量时,有两种情况:
-
- 如果修饰的是基本类型,说明这个变量的所代表数值永不能变(不能重新赋值)!
- 如果修饰的是引用类型,该变量所的引用不能变,但引用所代表的对象内容是可变的!
值得一说的是:并不是被final修饰的成员变量就一定是编译期常量了。比如说我们可以写出这样的代码:private final int java3y = new Randon().nextInt(20);
你有没有这样的编程经验,在编译器写代码时,某个场景下一定要将变量声明为final,否则会出现编译不通过的情况。为什么要这样设计?
在编写匿名内部类的时候就可能会出现这种情况,匿名内部类可能会使用到的变量:
- 外部类实例变量
- 方法或作用域内的局部变量
- 方法的参数
class Outer {
// string:外部类的实例变量
String string = "";
//ch:方法的参数
void outerTest(final char ch) {
// integer:方法内局部变量
final Integer integer = 1;
new Inner() {
void innerTest() {
System.out.println(string);
System.out.println(ch);
System.out.println(integer);
}
};
}
public static void main(String[] args) {
new Outer().outerTest(' ');
}
class Inner {
}
}
其中我们可以看到:方法或作用域内的局部变量和方法参数都要显示使用final关键字来修饰(在jdk1.7下)!

如果切换到jdk1.8编译环境下,可以通过编译的~

下面我们首先来说一下显示声明为final的原因:为了保持内部外部数据一致性
- Java只是实现了capture-by-value形式的闭包,也就是匿名函数内部会重新拷贝一份自由变量,然后函数外部和函数内部就有两份数据。
- 要想实现内部外部数据一致性目的,只能要求两处变量不变。JDK8之前要求使用final修饰,JDK8聪明些了,可以使用effectively final的方式
为什么仅仅针对方法中的参数限制final,而访问外部类的属性就可以随意
内部类中是保存着一个指向外部类实例的引用,内部类访问外部类的成员变量都是通过这个引用。
- 在内部类修改了这个引用的数据,外部类再获取时拿到的数据是一致的!
那当你在匿名内部类里面尝试改变外部基本类型的变量的值的时候,或者改变外部引用变量的指向的时候,表面上看起来好像都成功了,但实际上并不会影响到外部的变量。所以,Java为了不让自己看起来那么奇怪,才加了这个final的限制。
参考资料:
- java为什么匿名内部类的参数引用时final?https://www.zhihu.com/question/21395848
18.写出三种单例模式实现 。
单例模式:单例模式的意思就是只有一个实例。单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例。这个类称为单例类。
单例模式有三种:懒汉式单例,饿汉式单例,登记式单例,双重校验锁。
单例模式的好处
- 对于频繁使用的对象,可以省略new操作花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
- 由于new操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻GC压力,缩短GC停顿时间。
1.懒汉式单例
public class Singleton {
private static Singleton singleton;
private Singleton() {} //此类不能被实例化
public static synchronized Singleton getInstance() {
if (singleton == null) {
singleton = new Singleton();
}
return singleton;
}
}优点:第一次调用才初始化,避免内存浪费。
缺点:必须加锁synchronized 才能保证单例,(如果两个线程同时调用getInstance方法,会chuxia)但加锁会影响效率。
2.饿汉式单例
public class Singleton {
private static final Singleton SINGLETON = new Singleton();
private Singleton() {} //此类不能被实例化
public static Singleton getInstance() {
return SINGLETON;
}
}优点:没有加锁,执行效率会提高。
缺点:类加载时就初始化,浪费内存。
3.登记式模式(holder)
public class Singleton {
private Singleton() {} //构造方法是私有的,从而避免外界利用构造方法直接创建任意多实例。
public static Singleton getInstance() {
return Holder.SINGLETON;
}
private static class Holder {
private static final Singleton SINGLETON = new Singleton();
}
}内部类只有在外部类被调用才加载,产生SINGLETON实例;又不用加锁。此模式有上述两个模式的优点,屏蔽了它们的缺点,是最好的单例模式。
4.双重校验锁-懒汉式(jdk1.5)
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}这样方式实现线程安全地创建实例,而又不会对性能造成太大影响。它只是第一次创建实例的时候同步,以后就不需要同步了。
由于volatile关键字屏蔽了虚拟机中一些必要的代码优化,所以运行效率并不是很高,因此建议没有特别的需要不要使用。双重检验锁方式的单例不建议大量使用,根据情况决定。
总结
有两个问题需要注意:
1.如果单例由不同的类装载器装入,那便有可能存在多个单例类的实例。假定不是远端存取,例如一些servlet容器对每个servlet使用完全不同的类装载器,这样的话如果有两个servlet访问一个单例类,它们就都会有各自的实例。
2.如果Singleton实现了java.io.Serializable接口,那么这个类的实例就可能被序列化和复原。不管怎样,如果你序列化一个单例类的对象,接下来复原多个那个对象,那你就会有多个单例类的实例。
对第一个问题修复的办法是:
private static Class getClass(String classname)
throws ClassNotFoundException {
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
if(classLoader == null)
classLoader = Singleton.class.getClassLoader();
return (classLoader.loadClass(classname));
}
}对第二个问题修复的办法是:
public class Singleton implements java.io.Serializable {
public static Singleton INSTANCE = new Singleton();
protected Singleton() {
}
private Object readResolve() {
return INSTANCE;
}
}19.如何在父类中为子类自动完成所有的hashcode和equals实现?这么做有何优劣。
同时复写hashcode和equals方法,优势可以添加自定义逻辑,且不必调用超类的实现。
20.请结合OO设计理念,谈谈访问修饰符public、private、protected、default在应用设计中的作用。
访问修饰符,主要标示修饰块的作用域,方便隔离防护

21.深拷贝和浅拷贝区别。
1.为什么要用clone?
在实际编程过程中,我们常常要遇到这种情况:有一一个对象A,在某时刻A中已经包含了-些有效值,此时可
能会需要一个和 A完全相同新对象B,并且此后对B任何改动都不会影响到A中的值,也就是说, A与B是两个独立
的对象,但B的初始值是由A对象确定的。在Java语言中,用简单的赋值语句是不能满足这种需求的。要满足这种需
求虽然有很多途径,但实现done ()方法是其中最简单,也是最高效的手段。
2. new一个对象的过程和clone -一个对象的过程区别
new操作符的本意是分配内存。程序执行到new操作符时,首先去看new操作符后面的类型,因为知道了类型,
才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,
构造方法返回后,-个对象创建完毕,可以把他的引用(地址)发布到外部,在外部就可以使用这个引用操纵这个对
象。
clone在第一步是和new相似的,都是分配内存,调用clone方法时,分配的内存和原对象(即调用clone方法
的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域,填充完成之后,clone方法返回,一个新的相同
的对象被创建,同样可以把这个新对象的引用发布到外部。
3.clone对象的使用
3.1复制对象和复制引用的区别
Person p = new Person(23,"zhang");
Person p1 = p;
System.out.println(p);
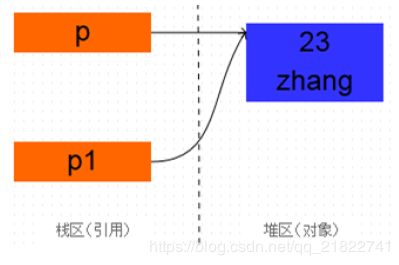
System.out.println(p1);当Pserson p1 = p;执行之后,是创建了一个新的对象吗?
可以看出,打印的地址值是相同的,既然地址都是相同的,那么肯定是同一个对象。p和p1只是引用而已,他们
都指向了一个相同的对象Person(23,"zhang") 。可以把这种现象叫做引用的复 制。上面代码执行完成之后,内
存中的情景如下图所示:
而下面的代码是真真正正的克隆了一个对象.
Person p = new Person(23, "zhang");
Person p1 = (Person) p.clone() ;
System.out. println(p) ;
System. out.println(p1);从打印结果可以看出,两个对象的地址是不同的,也就是说创建了新的对象,而不是把原对象的地址赋给了一个新的引用变量.
以上代码执行完成后,内存中的情景如下图所示:

3.3.2深拷贝和浅拷贝
上面的示例代码中,Person中有两个成员量, 分别是name和age, name是String类型, age是int类型。代码非常简单,如下所示:
public class Person implements Cloneable{
privatint age ;
private String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public Person() {}
public int getAge() {
return age;
}
public String getName() {
return name;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return (Person) super.clone();
}
}
由于age是基本数据类型,那么对它的拷贝没有什么疑议,直接将一个4字节的整数值拷贝过来就行。但是name是String类型的,它只是一 个引用,指向一 个真正的String对象,那么对它的拷贝有两种方式:直接将原对象中的name的引用值拷贝给新对象的name字段,或者是根据原 Person对象中的name指向的字符串对象创建一个新的相同的字符串对象,将这个新字符串对象的弓用赋给新拷贝的Person对象的name字段。这两种拷贝方式分别叫做浅拷贝和深拷贝。深拷贝和浅拷贝的原理如下图所示:
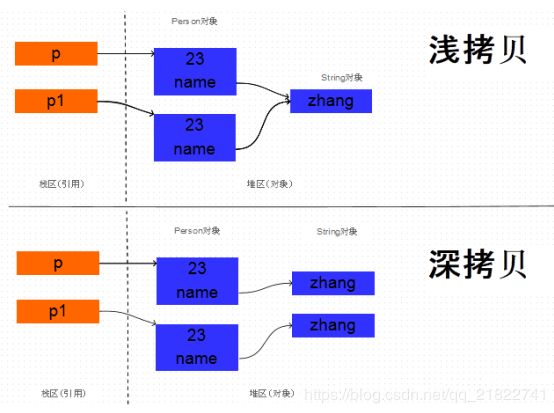
下面通过代码进行验证。如果两个Person对象的name的地址值相同,说明两个对象的name都指向同一个String对象,也就是浅拷贝, 而如果两个对象的name的地址值不同,那么就说明指向不同的 String 对象,也就是在拷贝Person对象的时候,同时拷贝了 name引用的String对象,也就是深拷贝。 验证代码如下:
Person p = new Person(23, "zhang");
Person pl = (Person) p.clone();
String result = p.getName() == pl.getName () ? "clone 是浅拷贝的" : "clone 是深拷贝的";
System. out.println(result);
打印结果为:
clone是浅拷贝的
所以,clone方法执行的是浅拷贝,在编写程序时要注意这个细节.
如何进行深拷贝:
由上一节的内容可以得出如下结论:如果想要深拷贝一个对象, 这个对象必须要实现Cloneable接口,实现clone
方法,并且在clone方法内部,把该对象引用的其他对象也要clone -份,这就要求这个被弓|用的对象必须也要实现
Cloneable接口并且实现clone方法。那么,按照上面的结论,实现以下代码Body类组合了Head类,要想深拷贝
Body类,必须在Body类的clone方法中将Head类也要拷贝一份。代码如下:
static class Body implements Cloneable{
public Head head;
public Body(){}
public Body (Head head) {this.head = head;}
@Override
protected object clone() throws CloneNotSupportedException{
Body newBody = (Body) super.clone();
newBody.head = (Head) head.clone();
return newBody;
}
}
static class Head implements Cloneable{
public Face face;
public Head() {}
@Override
protected object clone() throws CloneNotSupportedException {
return super .clone();
}
}
public static void main(String[] s args) throws CloneNotSupportedException{
Body body = new Body (new Head (new Face()));
Body body1 = (Body) body.clone() ;
System.out.println("body == body1 : "+ (body== bodyl) ) ;
System.out.println("body.head == body1.head : " + (body .head == body1 .head));
}打印结果为:
body == body1 : false
body.head == body1.head : false1. cloneable
clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。
public class CloneExample {
private int a;
private int b;
}
CloneExample e1 = new CloneExample();
// CloneExample e2 = e1.clone(); // 'clone()' has protected access in 'java.lang.Object'重写 clone() 得到以下实现:
public class CloneExample {
private int a;
private int b;
@Override
public CloneExample clone() throws CloneNotSupportedException {
return (CloneExample)super.clone();
}
}
CloneExample e1 = new CloneExample();
try {
CloneExample e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
java.lang.CloneNotSupportedException: CloneExample以上抛出了 CloneNotSupportedException,这是因为 CloneExample 没有实现 Cloneable 接口。
应该注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 clone() 方法,就会抛出 CloneNotSupportedException。
public class CloneExample implements Cloneable {
private int a;
private int b;
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}2. 浅拷贝
拷贝对象和原始对象的引用类型引用同一个对象。
public class ShallowCloneExample implements Cloneable {
private int[] arr;
public ShallowCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected ShallowCloneExample clone() throws CloneNotSupportedException {
return (ShallowCloneExample) super.clone();
}
}
ShallowCloneExample e1 = new ShallowCloneExample();
ShallowCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 2223. 深拷贝
拷贝对象和原始对象的引用类型引用不同对象。
public class DeepCloneExample implements Cloneable {
private int[] arr;
public DeepCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected DeepCloneExample clone() throws CloneNotSupportedException {
DeepCloneExample result = (DeepCloneExample) super.clone();
result.arr = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
result.arr[i] = arr[i];
}
return result;
}
}
DeepCloneExample e1 = new DeepCloneExample();
DeepCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 24. clone() 的替代方案
使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
public class CloneConstructorExample {
private int[] arr;
public CloneConstructorExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public CloneConstructorExample(CloneConstructorExample original) {
arr = new int[original.arr.length];
for (int i = 0; i < original.arr.length; i++) {
arr[i] = original.arr[i];
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
}
CloneConstructorExample e1 = new CloneConstructorExample();
CloneConstructorExample e2 = new CloneConstructorExample(e1);
e1.set(2, 222);
System.out.println(e2.get(2)); // 222.数组和链表数据结构描述,各自的时间复杂度。
数组 是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。但是如果要在数组中增加一个元素,需要移动大量元素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。同样的道理,如果想删除一个元素,同样需要移动大量元素去填掉被移动的元素。如果应用需要快速访问数据,很少插入和删除元素,就应该用数组。
链表 中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起,每个结点包括两个部分:一个是存储 数据元素 的 数据域,另一个是存储下一个结点地址的 指针。
如果要访问链表中一个元素,需要从第一个元素开始,一直找到需要的元素位置。但是增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了。如果应用需要经常插入和删除元素你就需要用链表。
内存存储区别
- 数组从栈中分配空间, 对于程序员方便快速,但自由度小。
- 链表从堆中分配空间, 自由度大但申请管理比较麻烦.
逻辑结构区别
- 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费。
- 链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项)
总结
- 存取方式上,数组可以顺序存取或者随机存取,而链表只能顺序存取;
- 存储位置上,数组逻辑上相邻的元素在物理存储位置上也相邻,而链表不一定;
- 存储空间上,链表由于带有指针域,存储密度不如数组大;
- 按序号查找时,数组可以随机访问,时间复杂度为O(1),而链表不支持随机访问,平均需要O(n);
- 按值查找时,若数组无序,数组和链表时间复杂度均为O(1),但是当数组有序时,可以采用折半查找将时间复杂度降为O(logn);
- 插入和删除时,数组平均需要移动n/2个元素,而链表只需修改指针即可;
- 空间分配方面:
- 数组在静态存储分配情形下,存储元素数量受限制,动态存储分配情形下,虽然存储空间可以扩充,但需要移动大量元素,导致操作效率降低,而且如果内存中没有更大块连续存储空间将导致分配失败;
- 链表存储的节点空间只在需要的时候申请分配,只要内存中有空间就可以分配,操作比较灵活高效;
23.error和exception的区别,CheckedException,RuntimeException的区别。
Error(错误)是系统中的错误,程序员是不能改变的和处理的,是在程序编译时出现的错误,只能通过修改程序才能修正。一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
Exception(异常)表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。
Exception又分为两类
CheckedException:(编译时异常) 需要用try——catch显示的捕获,对于可恢复的异常使用CheckedException。
UnCheckedException(RuntimeException):(运行时异常)不需要捕获,对于程序错误(不可恢复)的异常使用RuntimeException。
常见的RuntimeException异常
- illegalArgumentException:此异常表明向方法传递了一个不合法或不正确的参数。
- NullpointerException:空指针异常(我目前遇见的最多的)
- IndexOutOfBoundsException:索引超出边界异常
- illegalStateException:在不合理或不正确时间内唤醒一方法时出现的异常信息。即 Java 环境或 Java 应用不满足请求操作。
常见的CheckedException异常
- 我们在编写程序过程中try——catch捕获到的一场都是CheckedException。
- io包中的IOExecption及其子类,都是CheckedException。
举个简单的例子(看别人的,觉得很形象,很好理解)
Error和Exception就像是水池和水池里的水的区别
“水池”,就是代码正常运行的外部环境,如果水池崩溃(系统崩溃),或者池水溢出(内存溢出)等,这些都是跟水池外部环境有关。这些就是java中的error
“水池里的水”,就是正常运行的代码,水污染了、有杂质了,浑浊了,这些影响水质的因素就是Exception。
24.请列出5个运行时异常。
java运行时异常是可能在java虚拟机正常工作时抛出的异常。java提供了两种异常机制。一种是运行时异常(RuntimeExepction),一种是检查式异常(checked execption)。
- 检查式异常:我们经常遇到的IO异常及sql异常就属于检查式异常。对于这种异常,java编译器要求我们必须对出现的这些异常进行catch 所以 面对这种异常不管我们是否愿意,只能自己去写一堆catch来捕捉这些异常。
- 运行时异常:我们可以不处理。当出现这样的异常时,总是由虚拟机接管。比如:我们从来没有人去处理过NullPointerException异常,它就是运行时异常,并且这种异常还是最常见的异常之一。
RuntimeExecption在java.lang包下。
常见的几种如下:
- ClassCastException(类转换异常)
- IndexOutOfBoundsException(下标越界异常)
- NullPointerException(空指针异常)
- ArrayStoreException(数据存储异常,操作数组时类型不一致)
- BufferOverflowException(还有IO操作的,缓冲溢出异常)
- IllegalArgumentException - 传递非法参数异常。
- ArithmeticException - 算术运算异常
- ArrayStoreException - 向数组中存放与声明类型不兼容对象异常
- NegativeArraySizeException - 创建一个大小为负数的数组错误异常
- NumberFormatException - 数字格式异常
- SecurityException - 安全异常
- UnsupportedOperationException - 不支持的操作异常
25.在自己的代码中,如果创建一个java.lang.String类,这个类是否可以被类加载器加载?为什么?
java是一种类型安全的语言,它的四类成为安全沙箱机制的安全机制来保证语言的安全性,这四类安全沙箱分别是:
- 类加载体系
- .class文件检验器
- 内置于Java虚拟机(及语言)的安全特性
- 安全管理器及Java API
Java程序中的.java文件编译完成会生成.class文件,而.class文件就是用过被称为类加载器的ClassLoader加载的,而ClassLoder在加载过程中会使用"双亲委派机制"来加载.class文件.
类加载器就是Java运行时环境(Java Runtime Environment)的一部分,负责动态加载Java类到Java虚拟机的内存空间中。恩看了这个介绍就知道了~~~原来平常的.class文件是通过这个加载器,加载到内存中的。
1.Bootstrap ClassLoader
负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类
2、Extension ClassLoader
负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包
3、App ClassLoader(SystemClassLoader)
负责记载classpath中指定的jar包及目录中class
4、Custom ClassLoader
属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader
OK那么好了,我们现在知道了什么是类加载器以及它的种类及作用了,那么现在问题来了,为什么我们自己写的Sring类能否被加载到呢?我们自己写一个来看看
首先,写了一个跟JAVA自带的String类一个一样的String,包名也一样就是在构造方法里面多了一行输出。
public String() {
this.value = new char[0];
System.out.println("==================");
}
也就是说只要调用了我们自己写的String类得话应该是有输出的,接下来我们来试试:
import java.lang.String;
public class Test {
public static void main(String[] args) {
String test =new String();
test = "测试";
System.out.println(test);
}
}
运行结果如下:

可以看到调用的是系统的String类,没有输出。
这是为什么呢?查阅了一些资料终于发现问题所在,这就是类加载器的委托机制。
3.类加载器的委托机制
从JDK1.2开始,类的加载过程采用父亲委托机制。这种机制能更好的保证java平台的安全。在此委托机制中,除了Java虚拟机自带的根类加载器以外,其余的类加载器都有且只有一个父加载器。当Java程序请求加载器loader1加载Sample类时,loader1首先委托自己的父加载器去加载Sample类,若父加载器能加载,则由父加载器完成加载任务,否则才由加载器loader1本身加载Sample类。
好吧~~~这下看明白了类加载器有个加载顺序我们来看一下这个加载顺序
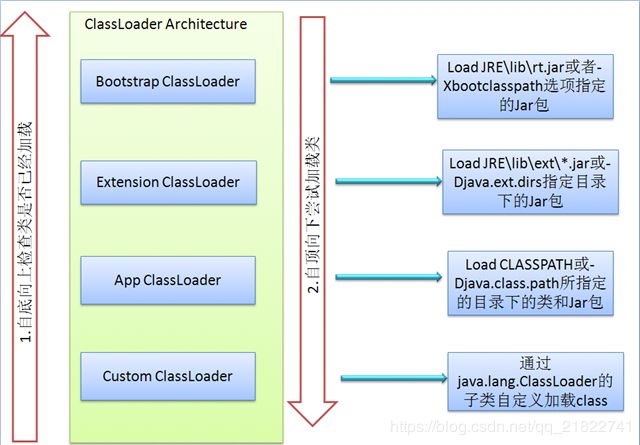
加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个classloader已加载就视为已加载此类,保证此类只所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是说当发现这个类没有的时候会先去让自己的父类去加载,父类没有再让儿子去加载,那么在这个例子中我们自己写的String应该是被Bootstrap ClassLoader加载了,所以App ClassLoader就不会再去加载我们写的String类了,导致我们写的String类是没有被加载的。
26.说说你对java.lang.Object对象中hashCode和equals方法的理解。在什么场景下需要重新实现这两个方法。
在程序设计中,有很多的“公约”,遵守约定去实现你的代码,会让你避开很多坑,这些公约是前人总结出来的设计规范。Object类是Java中的万类之祖,其中,equals和hashCode是2个非常重要的方法。
public boolean equals(Object obj)
Object类中默认的实现方式是 : return this == obj 。那就是说,只有this 和 obj引用同一个对象,才会返回true。
而我们往往需要用equals来判断 2个对象是否等价,而非验证他们的唯一性。这样我们在实现自己的类时,就要重写equals.
按照约定,equals要满足以下规则。
- 自反性: x.equals(x) 一定是true
- 对null: x.equals(null) 一定是false
- 对称性: x.equals(y) 和 y.equals(x)结果一致
- 传递性: a 和 b equals , b 和 c equals,那么 a 和 c也一定equals。
- 一致性: 在某个运行时期间,2个对象的状态的改变不会不影响equals的决策结果,那么,在这个运行时期间,无论调用多少次equals,都返回相同的结果。
一个例子
class Test
{
private int num;
private String data;
public boolean equals(Object obj)
{
if (this == obj)
return true;
if ((obj == null) || (obj.getClass() != this.getClass()))
return false;
//能执行到这里,说明obj和this同类且非null。
Test test = (Test) obj;
return num == test.num&& (data == test.data || (data != null && data.equals(test.data)));
}
public int hashCode()
{
//重写equals,也必须重写hashCode。具体后面介绍。
}
}
equals编写指导
Test类对象有2个字段,num和data,这2个字段代表了对象的状态,他们也用在equals方法中作为评判的依据。
在第8行,传入的比较对象的引用和this做比较,这样做是为了 save time ,节约执行时间,如果this 和 obj是 对同一个堆对象的引用,那么,他们一定是qeuals 的。
接着,判断obj是不是为null,如果为null,一定不equals,因为既然当前对象this能调用equals方法,那么它一定不是null,非null 和 null当然不等价。
然后,比较2个对象的运行时类,是否为同一个类。不是同一个类,则不equals。getClass返回的是 this 和obj的运行时类的引用。如果他们属于同一个类,则返回的是同一个运行时类的引用。注意,一个类也是一个对象。
1、有些程序员使用下面的第二种写法替代第一种比较运行时类的写法。应该避免这样做。
if((obj == null) || (obj.getClass() != this.getClass()))
return false;
if(!(obj instanceof Test))
return false; // avoid 避免!它违反了公约中的对称原则。
例如:假设Dog扩展了Aminal类。
dog instanceof Animal 得到true
animal instanceof Dog 得到false
这就会导致
animal.equls(dog) 返回true
dog.equals(animal) 返回false
仅当Test类没有子类的时候,这样做才能保证是正确的。
2、按照第一种方法实现,那么equals只能比较同一个类的对象,不同类对象永远是false。但这并不是强制要求的。一般我们也很少需要在不同的类之间使用equals。
3、在具体比较对象的字段的时候,对于基本值类型的字段,直接用 == 来比较(注意浮点数的比较,这是一个坑)对于引用类型的字段,你可以调用他们的equals,当然,你也需要处理字段为null 的情况。对于浮点数的比较,我在看Arrays.binarySearch的源代码时,发现了如下对于浮点数的比较的技巧:
if ( Double.doubleToLongBits(d1) == Double.doubleToLongBits(d2) ) //d1 和 d2 是double类型
if( Float.floatToIntBits(f1) == Float.floatToIntBits(f2) ) //f1 和 f2 是d2是float类型
4、并不总是要将对象的所有字段来作为equals 的评判依据,那取决于你的业务要求。比如你要做一个家电功率统计系统,如果2个家电的功率一样,那就有足够的依据认为这2个家电对象等价了,至少在你这个业务逻辑背景下是等价的,并不关心他们的价钱啊,品牌啊,大小等其他参数。
5、最后需要注意的是,equals 方法的参数类型是Object,不要写错!
public int hashCode()
这个方法返回对象的散列码,返回值是int类型的散列码。
对象的散列码是为了更好的支持基于哈希机制的Java集合类,例如 Hashtable, HashMap, HashSet 等。
关于hashCode方法,一致的约定是:
重写了euqls方法的对象必须同时重写hashCode()方法。
如果2个对象通过equals调用后返回是true,那么这个2个对象的hashCode方法也必须返回同样的int型散列码
如果2个对象通过equals返回false,他们的hashCode返回的值允许相同。(然而,程序员必须意识到,hashCode返回独一无二的散列码,会让存储这个对象的hashtables更好地工作。)
在上面的例子中,Test类对象有2个字段,num和data,这2个字段代表了对象的状态,他们也用在equals方法中作为评判的依据。那么, 在hashCode方法中,这2个字段也要参与hash值的运算,作为hash运算的中间参数。这点很关键,这是为了遵守:2个对象equals,那么 hashCode一定相同规则。
也是说,参与equals函数的字段,也必须都参与hashCode 的计算。
合乎情理的是:同一个类中的不同对象返回不同的散列码。典型的方式就是根据对象的地址来转换为此对象的散列码,但是这种方式对于Java来说并不是唯一的要求的
的实现方式。通常也不是最好的实现方式。
相比 于 equals公认实现约定,hashCode的公约要求是很容易理解的。有2个重点是hashCode方法必须遵守的。约定的第3点,其实就是第2点的
细化,下面我们就来看看对hashCode方法的一致约定要求。
第一:在某个运行时期间,只要对象的(字段的)变化不会影响equals方法的决策结果,那么,在这个期间,无论调用多少次hashCode,都必须返回同一个散列码。
第二:通过equals调用返回true 的2个对象的hashCode一定一样。
第三:通过equasl返回false 的2个对象的散列码不需要不同,也就是他们的hashCode方法的返回值允许出现相同的情况。
总结一句话:等价的(调用equals返回true)对象必须产生相同的散列码。不等价的对象,不要求产生的散列码不相同。
hashCode编写指导
在编写hashCode时,你需要考虑的是,最终的hash是个int值,而不能溢出。不同的对象的hash码应该尽量不同,避免hash冲突。
那么如果做到呢?下面是解决方案。
1、定义一个int类型的变量 hash,初始化为 7。
接下来让你认为重要的字段(equals中衡量相等的字段)参入散列运,算每一个重要字段都会产生一个hash分量,为最终的hash值做出贡献(影响)
| 重要字段var的类型 | 他生成的hash分量 |
| byte, char, short , int | (int)var |
| long | (int)(var ^ (var >>> 32)) |
| boolean | var?1:0 |
| float | Float.floatToIntBits(var) |
| double | long bits = Double.doubleToLongBits(var); 分量 = (int)(bits ^ (bits >>> 32)); |
| 引用类型 | (null == var ? 0 : var.hashCode()) |
最后把所有的分量都总和起来,注意并不是简单的相加。选择一个倍乘的数字31,参与计算。然后不断地递归计算,直到所有的字段都参与了。
int hash = 7;
hash = 31 * hash + 字段1贡献分量;
hash = 31 * hash + 字段2贡献分量;
.....
return hash;27.在jdk1.5中,引入了泛型,泛型的存在是用来解决什么问题。
1.泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。比如我们要写一个排序方法,能够对整型数组、字符串数组甚至其他任何类型的数组进行排序,我们就可以使用 Java 泛型。 拥有Java1.4或更早版本的开发背景的人都知道,在集合中存储对象并在使用前进行类型转换是多么的不方便。泛型防止了那种情况的发生。它提供了编译期的类型安全,确保你只能把正确类型的对象放入集合中,避免了在运行时出现ClassCastException。
Java 中的泛型基本上都是在编译器这个层次来实现的。在生成的 Java 字节代码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会被编译器在编译的时候去掉,所以在运行时不存在任何类型相关的信息。这个过程就称为类型擦除。如在代码中定义的 List