几句话让你明白什么是爬虫-Scrapy
Python
Scrapy是Python中为了爬去网页数据而提供的框架,主要应用于:数据挖掘,信息处理或存储历史数据等一系列的程序中。
那么我们爬数据的的本质是什么呢?就是利用Http、Https协议将开放性的web内容下载到本地中。
当然既然有爬虫就会有所谓的反爬,反反爬,反反爬。。。 各种防范措施,但是程序员是不会放弃的。
一般防止被爬的人会有一下措施:
你的请求头是否合法(是否是浏览器的请求)
被爬人在你访问首页的时候,网页会给你一个cooike
(解决方法:先进入首页,把给我们的cooike携程一个全局变量带入!)
被爬人在cooike加一个时间戳,解析里面的时间差
(解决方法:启动多任务(模拟多个用户),定时)
被爬人判断这些用户是不是来自同一个IP(也就是一台计算机)
(解决方法:这家伙咱们只能花钱买代理了哈哈哈!)
被爬人在页面让你输入验证码
(解决方法:ai图像识别。分析图像,对网页的那个图片进行识别填入)
社会工程学。刷到票后把验证码存起来给社会推广广告的人(朋友圈,扫码给钱!只需要你填这个图片是什么,然后记录进去),让大众帮忙识别。
好了说了这么多是为了让大家有一个对爬虫的宏概念,先写一个小程序体验一下爬虫吧!
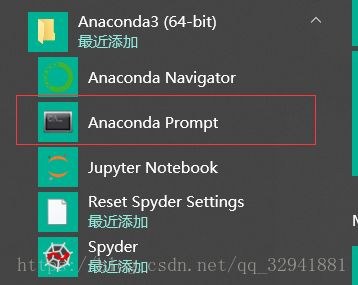
打开我们的命令窗口,输入你想要去哪个磁盘

然后我们为了生成爬虫所需要的工具类,我们就用命令创建一个爬虫项目,输入如下命令:
cd workspace是进入我的工程储存的文件夹,在这里面创建工程
scrapy startproject pachong //pachong是你要起的工程名字
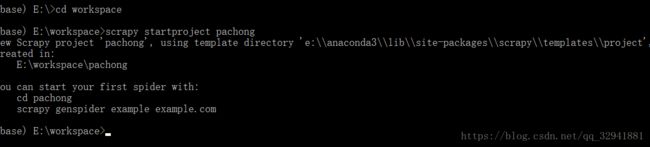
然后我们输入,dir命令查看文件夹中是否创建了一个名为pachong的工程,当然你也可以直接点进磁盘查看
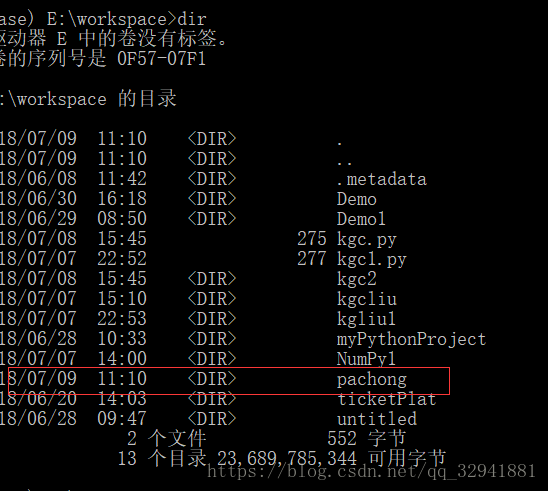
那么我们创建好这个工程后接下来就是创建一个爬虫了和我们要去哪爬的网站
输入cd pachong 是进入到我们创建的这个工程里面创建爬虫
scrapy genspider 爬虫名字 网址
大家根据自己的自身需要和业务需要去爬哪里,敲完命令回车即可

那么我们就可以打开idea导入这个项目了,如下图可以看到,生成了爬虫所需要的工具类,和我们生成的爬虫文件名叫baidu
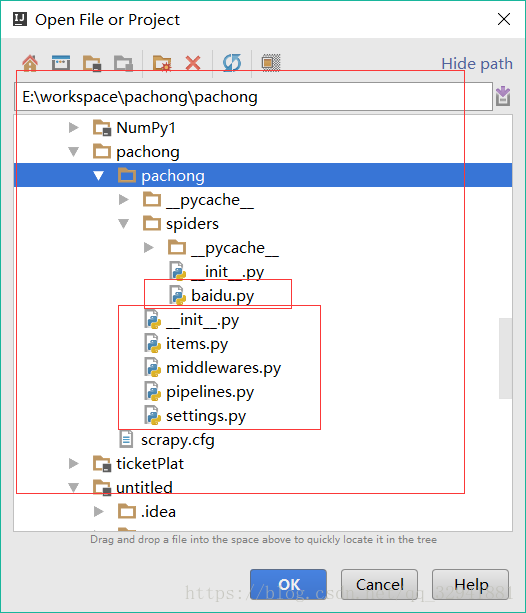
我们导入项目后,我们进入我们创建的爬虫文件看到 scrapy报错的话
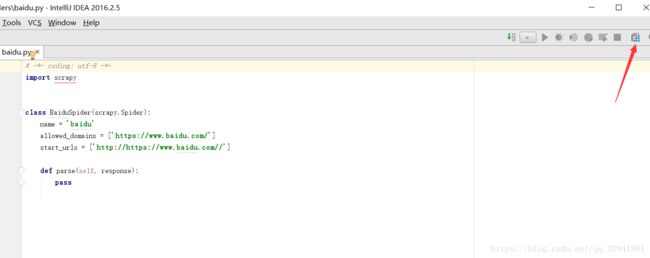
我们点击右上面这个按钮
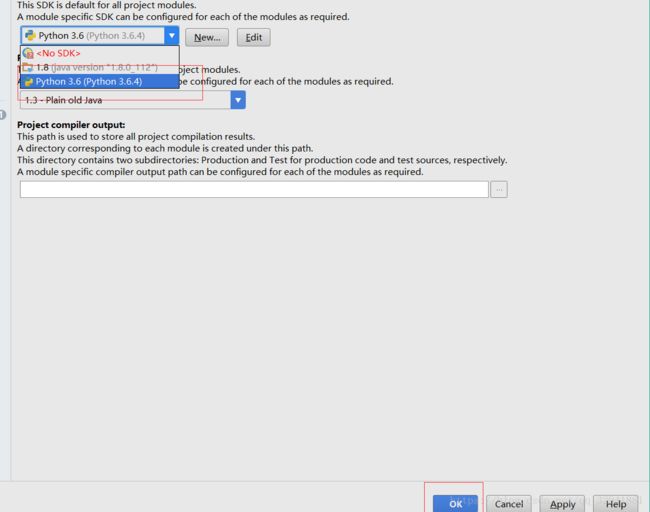
选择我们的Python包,点击OK即可。
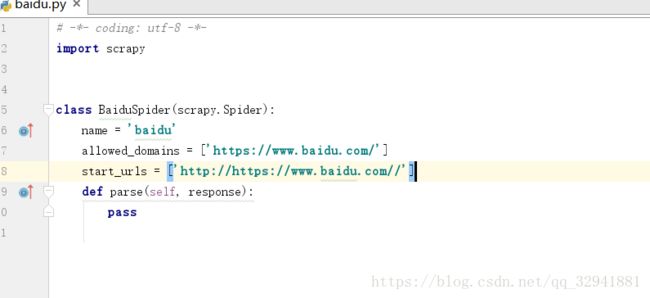
那么我们会发现我们的爬虫文件中 给我们生成了爬虫的名字,和网址,第一个代表着范围,我们现在可以直接注释即可,第二个网址多生成的http我们删掉即可 如下图,当然我们不可能去爬百度,我需要把路径改为某院校网上的
那么我们下面就要写解析的方法了,通过response相应,我们或许我们要爬数据的样式,然后引用我们的实体类,需要如下引用
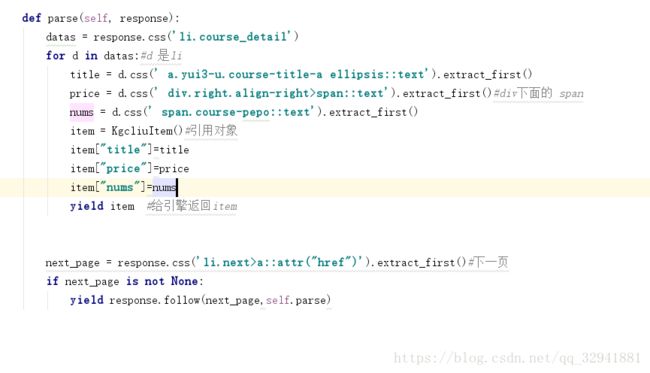
如下是引用实体类的导入
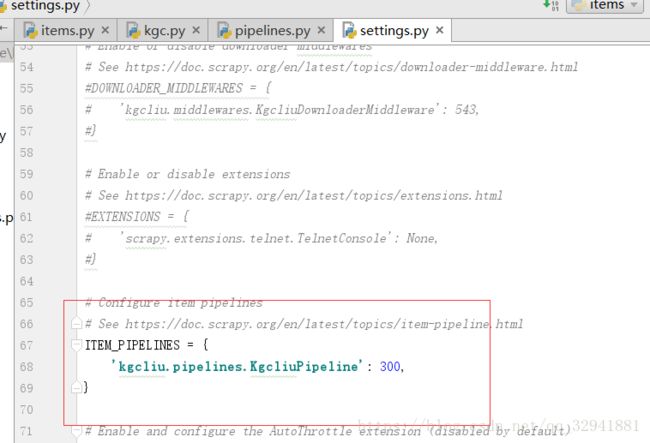
接下来我们需要把这个配置文件的管道打开,默认是注释,就是关闭了的。
接下来我们需要在我们的pipelines.py文件中,写数据库的打开,关闭 还有插入数据等操作,这里我们需要引用pymysql

到这里我们的代码就已经写完了,我这里爬的数据仅为课程名title 课程价格price 和学习人数nums

这是我们的数据库表结构
最后我们就可以输入命令,启动我们的爬虫了: scrapy crawl kgc 回车即可

那我们出现如下情况。没有出现错误信息的话就代表数据可能爬取成功了已经,我们去表里看一下

如上图所见,我们已经爬取到数据了,并存入到了库中, 我们这个简单的爬虫就已经成功了,是不是很简单呢。