基于Pytorch实现深度学习优化算法(Adagrad/RmsProp/Momentum/Adam)
以下介绍深度学习的主要几种参数更新的优化方法
1.Adagrad
通过引入二阶动量 v t = ∑ i = 0 t ( g i 2 ) v_t=\sqrt{\sum\limits_{i=0}^t(g_i^2)} vt=i=0∑t(gi2)使得学习率 η v t \frac{\eta} {v_t} vtη的更新可以自适应的记性,对于出现频率较低( v t 较 小 v_t较小 vt较小)参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
w t + 1 ← w t − η ∑ i = 0 t ( g i 2 ) + ε g t w_{t+1} \leftarrow w_t - \frac{\eta}{\sqrt{\sum_{i=0}^t(g_i^2)+\varepsilon}}g_t wt+1←wt−∑i=0t(gi2)+εηgt
这里的 ε \varepsilon ε 是为了数值稳定性而加上的,因为初始时有可能 v t v_t vt 的值为 0,那么 0 出现在分母就会出现无穷大的情况,通常 ε \varepsilon ε 取 1 0 − 10 10^{-10} 10−10 ,这样不同的参数由于梯度不同,得到的学习率也就不同,从而实现了自适应的学习率。但Adagrad有个缺点,其引入了二阶动量 v t = ∑ i = 0 t ( g i 2 ) v_t=\sqrt{\sum\limits_{i=0}^t(g_i^2)} vt=i=0∑t(gi2)的概念,由于 v t v_t vt是单调递增的,所以学习率单调递减,而当学习率递减速度过快的时候可能就会导致模型没有完全收敛的情况下提前终止。
核心代码:
def sgd_adagrad(parameters, sqrs, lr):
eps = 1e-10
for param, sqr in zip(parameters, sqrs):
sqr[:] = sqr + param.grad.data ** 2
div = lr / torch.sqrt(sqr + eps) * param.grad.data
param.data = param.data - div
以下栗子为采用Adagrad参数更新方法,利用pytorch实现简单的三层神经网络进行MNIST手写数据集的识别
import numpy as np
import torch
from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据
from torch.utils.data import DataLoader
from torch import nn
from torch.autograd import Variable
import time
import matplotlib.pyplot as plt
%matplotlib inline
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换
test_set = MNIST('./data', train=False, transform=data_tf, download=True)
# 定义 loss 函数
criterion = nn.CrossEntropyLoss()
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
# 初始化梯度平方项
sqrs = []
for param in net.parameters():
sqrs.append(torch.zeros_like(param.data))
# 开始训练
losses = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
net.zero_grad()
loss.backward()
sgd_adagrad(net.parameters(), sqrs, 1e-2) # 学习率设为 0.01
# 记录误差
train_loss += loss.data[0]
if idx % 30 == 0:
losses.append(loss.data[0])
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))epoch: 0, Train Loss: 0.406752
epoch: 1, Train Loss: 0.248588
epoch: 2, Train Loss: 0.211789
epoch: 3, Train Loss: 0.188928
epoch: 4, Train Loss: 0.172839
使用时间: 54.70610 s
运行的result如下所示:
epoch: 0, Train Loss: 0.406752
epoch: 1, Train Loss: 0.248588
epoch: 2, Train Loss: 0.211789
epoch: 3, Train Loss: 0.188928
epoch: 4, Train Loss: 0.172839
使用时间: 54.70610 s
以下为训练过程中的loss
x_axis = np.linspace(0, 5, len(losses), endpoint=True)
plt.semilogy(x_axis, losses, label='adagrad')
plt.legend(loc='best')
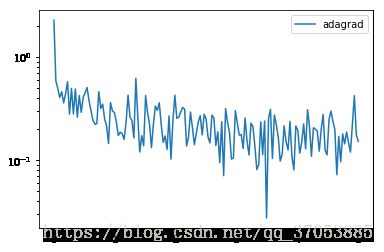
当然 pytorch 也内置了 adagrad 的优化算法,只需要调用 torch.optim.Adagrad() 就可以了,下面是例子
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
optimizer = torch.optim.Adagrad(net.parameters(), lr=1e-2)
# 开始训练
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data[0]
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
2.RMSProp
Adagrad会累加之前所有的梯度平方,而RMSprop这里 α 是一个移动平均的系数,也是因为这个系数,导致了 RMSProp 和 Adagrad 不同的地方,这个系数使得 RMSProp 更新到后期累加的梯度平方较小,从而保证 σ \sigma σ 不会太大,也就使得模型后期依然能够找到比较优的结果
w 1 ← w 0 − η σ 0 + ε g 0 , σ 0 = g 0 w 2 ← w 1 − η σ 1 + ε g 1 , σ 1 = α ( σ 0 ) 2 + ( 1 − α ) ( g 1 ) 2 w 3 ← w 2 − η σ 2 + ε g 2 , σ 2 = α ( σ 1 ) 2 + ( 1 − α ) ( g 2 ) 2 . . . w t ← w t − 1 − η σ t − 1 + ε g t − 1 , σ t − 1 = α ( σ t − 2 ) 2 + ( 1 − α ) ( g t − 1 ) 2 w_1 \leftarrow w_0 - \frac{\eta}{\sqrt{\sigma_0+\varepsilon}}g_0\;,\sigma_0=g_0\\ w_2 \leftarrow w_1 - \frac{\eta}{\sqrt{\sigma_1+\varepsilon}}g_1\;,\sigma_1={\alpha(\sigma_0)^2+(1-\alpha)(g_1)^2}\\ w_3 \leftarrow w_2 - \frac{\eta}{\sqrt{\sigma_2+\varepsilon}}g_2\;,\sigma_2={\alpha(\sigma_1)^2+(1-\alpha)(g_2)^2}\\ ...\\ w_t \leftarrow w_{t-1} - \frac{\eta}{\sqrt{\sigma_{t-1}+\varepsilon}}g_{t-1}\;,\sigma_{t-1}={\alpha(\sigma_{t-2})^2+(1-\alpha)(g_t-1)^2}\\ w1←w0−σ0+εηg0,σ0=g0w2←w1−σ1+εηg1,σ1=α(σ0)2+(1−α)(g1)2w3←w2−σ2+εηg2,σ2=α(σ1)2+(1−α)(g2)2...wt←wt−1−σt−1+εηgt−1,σt−1=α(σt−2)2+(1−α)(gt−1)2
核心代码
def rmsprop(parameters, sqrs, lr, alpha):
eps = 1e-10
for param, sqr in zip(parameters, sqrs):
sqr[:] = alpha * sqr + (1 - alpha) * param.grad.data ** 2
div = lr / torch.sqrt(sqr + eps) * param.grad.data
param.data = param.data - div
以下为利用RMSProp优化方法实现的MNIST手写体数字的识别
import numpy as np
import torch
from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据
from torch.utils.data import DataLoader
from torch import nn
from torch.autograd import Variable
import time
import matplotlib.pyplot as plt
%matplotlib inline
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换
test_set = MNIST('./data', train=False, transform=data_tf, download=True)
# 定义 loss 函数
criterion = nn.CrossEntropyLoss()
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
# 初始化梯度平方项
sqrs = []
for param in net.parameters():
sqrs.append(torch.zeros_like(param.data))
# 开始训练
losses = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
net.zero_grad()
loss.backward()
rmsprop(net.parameters(), sqrs, 1e-3, 0.9) # 学习率设为 0.001,alpha 设为 0.9
# 记录误差
train_loss += loss.data[0]
if idx % 30 == 0:
losses.append(loss.data[0])
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
训练的结果如下所示:
epoch: 0, Train Loss: 0.363507
epoch: 1, Train Loss: 0.161640
epoch: 2, Train Loss: 0.120954
epoch: 3, Train Loss: 0.101136
epoch: 4, Train Loss: 0.085934
使用时间: 58.86966 s
可视化Loss函数
x_axis = np.linspace(0, 5, len(losses), endpoint=True)
plt.semilogy(x_axis, losses, label='alpha=0.9')
plt.legend(loc='best')

当然 pytorch 也内置了 rmsprop 的方法,非常简单,只需要调用 torch.optim.RMSprop() 就可以了,下面是例子
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
optimizer = torch.optim.RMSprop(net.parameters(), lr=1e-3, alpha=0.9)
# 开始训练
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data[0]
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
当然 pytorch 也内置了 rmsprop 的方法,非常简单,只需要调用 torch.optim.RMSprop() 就可以了,下面是例子当然 pytorch 也内置了 rmsprop 的方法,非常简单,只需要调用 torch.optim.RMSprop() 就可以了,下面是例子
3.Momentum


该方法源于了物理学上动量的概念,试想一下小球从山上滚下来,那么小球每次前进不仅和当前时刻外力对它做的功所决定(当前时刻参数的更新,即当前计算出来的梯度 ∇ L ( θ i ) \nabla L(\theta^i) ∇L(θi))而且还受到惯性的作用(以往的参数更新)。因此该方法引入参数v用于表示动量, v t − 1 v^{t-1} vt−1表示此前的更新结果,而 v t v^t vt则表示当前的参数
θ \theta θ为待更新的参数,v代表过往的参数更新结果(可以看做是之前更新数据积累下来的惯性)
θ 0 为 还 未 更 新 的 参 数 , v 0 = 0 \theta_0为还未更新的参数,v^0=0 θ0为还未更新的参数,v0=0则有以下公式:
v 1 = λ v 0 − η ∇ L ( θ 0 ) v 2 = λ v 1 − η ∇ L ( θ 1 ) . . . v t = λ v t − 1 − η ∇ L ( θ t − 1 ) v^1=\lambda v^{0}-\eta \nabla L(\theta^{0})\\ v^2=\lambda v^{1}-\eta \nabla L(\theta^{1})\\ ...\\ v^t=\lambda v^{t-1}-\eta \nabla L(\theta^{t-1})\\ v1=λv0−η∇L(θ0)v2=λv1−η∇L(θ1)...vt=λvt−1−η∇L(θt−1)

以下是核心代码:
def sgd_momentum(parameters, vs, lr, gamma):
for param, v in zip(parameters, vs):
v[:] = gamma * v + lr * param.grad.data
param.data = param.data - v
以下为利用Momentum参数优化更新方法来训练一个三层神经网络的MNIST手写体数字识别
import numpy as np
import torch
from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据
from torch.utils.data import DataLoader
from torch import nn
from torch.autograd import Variable
import time
import matplotlib.pyplot as plt
# %matplotlib inline
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
# train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换
# test_set = MNIST('./data', train=False, transform=data_tf, download=True)
# 下载训练集 MNIST手写数字训练集
train_set = MNIST(root='/home/hk/Desktop/learn_pytorch/data', train=True, transform=data_tf, download=False)#data_tf auto normalization in the process of the transform
test_set = MNIST(root='/home/hk/Desktop/learn_pytorch/data', train=False, transform=data_tf, download=True)
# 定义 loss 函数
criterion = nn.CrossEntropyLoss()
def sgd_momentum(parameters, vs, lr, gamma):
for param, v in zip(parameters, vs):
v[:] = gamma * v + lr * param.grad.data
param.data = param.data - v
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
# 将速度初始化为和参数形状相同的零张量
vs = []
for param in net.parameters():
vs.append(torch.zeros_like(param.data))
# 开始训练
losses = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
net.zero_grad()
loss.backward()
sgd_momentum(net.parameters(), vs, 1e-2, 0.9) # 使用的动量参数为 0.9,学习率 0.01
# 记录误差
train_loss += loss.data
if idx % 20 == 0:
losses.append(loss.data)
idx+=1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
x_axis = np.linspace(0, 5, len(losses), endpoint=True)
plt.semilogy(x_axis, losses, label='adagrad')
plt.legend(loc='best')
plt.show()
以下为训练的结果
epoch: 0, Train Loss: 0.367609
epoch: 1, Train Loss: 0.168976
epoch: 2, Train Loss: 0.123189
epoch: 3, Train Loss: 0.100595
epoch: 4, Train Loss: 0.083965
使用时间: 69.73666 s

可以看到,加完动量之后 loss 能下降非常快,但是一定要小心学习率和动量参数,这两个值会直接影响到参数每次更新的幅度,所以可以多试几个值
当然,pytorch 内置了动量法的实现,非常简单,直接在 torch.optim.SGD(momentum=0.9) 即可,下面实现一下
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
optimizer = torch.optim.SGD(net.parameters(), lr=1e-2, momentum=0.9) # 加动量
# 开始训练
losses = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data[0]
if idx % 30 == 0: # 30 步记录一次
losses.append(loss.data[0])
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
我们可以对比一下不加动量的随机梯度下降法
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
optimizer = torch.optim.SGD(net.parameters(), lr=1e-2) # 不加动量
# 开始训练
losses1 = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data[0]
if idx % 30 == 0: # 30 步记录一次
losses1.append(loss.data[0])
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
4.Adam

Adam是RMSProp和Momentum的结合,它是另一种自适应学习率的方法。它利用过去的梯度( m t m_t mt)和过去的平方梯度( v t v_t vt)动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
参数说明:
α \alpha α是最终参数 θ \theta θ更新的步幅
β 1 , β 2 为 对 过 往 梯 度 的 估 计 的 指 数 衰 减 率 \beta1,\beta2为对过往梯度的估计的指数衰减率 β1,β2为对过往梯度的估计的指数衰减率
θ 0 为 初 始 的 参 数 的 向 量 \theta_0为初始的参数的向量 θ0为初始的参数的向量
Adam的具体伪代码如下所示:
m 0 ← 0 v 0 ← 0 t ← 0 m_0 \leftarrow 0\\ v_0 \leftarrow 0\\ t \leftarrow 0\\ m0←0v0←0t←0
while θ t \theta_t θt is not converged do
t ← t + 1 g t ← ∇ f ( θ ) m t ← β 1 ⋅ m t − 1 + ( 1 − β 1 ) ⋅ g t v t ← β 2 ⋅ v t − 1 + ( 1 − β 2 ) ⋅ g t 2 m ^ t ← m t 1 − β 1 t ( 修 正 , 仅 在 初 始 时 起 作 用 ) v ^ t ← v t 1 − β 2 t ( 修 正 , 仅 在 初 始 时 起 作 用 ) θ t ← θ t − 1 − α ⋅ m ^ t v ^ t + ε t \leftarrow t+1\\ g_t\leftarrow\nabla f(\theta)\\ m_t\leftarrow\beta_1\cdot m_{t-1}+(1-\beta_1)\cdot g_t\\ v_t\leftarrow\beta_2\cdot v_{t-1}+(1-\beta_2)\cdot g_t^2\\ \hat m_t \leftarrow \frac{m_t}{1-\beta_1^t}(修正,仅在初始时起作用)\\ \hat v_t \leftarrow \frac{v_t}{1-\beta_2^t}(修正,仅在初始时起作用)\\ \theta_t \leftarrow \theta_{t-1} - \alpha \cdot \frac{\hat m_t}{\sqrt{\hat v_t}+\varepsilon} t←t+1gt←∇f(θ)mt←β1⋅mt−1+(1−β1)⋅gtvt←β2⋅vt−1+(1−β2)⋅gt2m^t←1−β1tmt(修正,仅在初始时起作用)v^t←1−β2tvt(修正,仅在初始时起作用)θt←θt−1−α⋅v^t+εm^t
end while
return θ t \theta_t θt
以下为核心代码:
def adam(parameters, vs, sqrs, lr, t, beta1=0.9, beta2=0.999):
eps = 1e-8
for param, v, sqr in zip(parameters, vs, sqrs):
v[:] = beta1 * v + (1 - beta1) * param.grad.data
sqr[:] = beta2 * sqr + (1 - beta2) * param.grad.data ** 2
v_hat = v / (1 - beta1 ** t)
s_hat = sqr / (1 - beta2 ** t)
param.data = param.data - lr * v_hat / torch.sqrt(s_hat + eps)
以下为Adam优化方法实现的有三层的网络MNIST手写体数字识别
import numpy as np
import torch
from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据
from torch.utils.data import DataLoader
from torch import nn
from torch.autograd import Variable
import time
import matplotlib.pyplot as plt
%matplotlib inline
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换
test_set = MNIST('./data', train=False, transform=data_tf, download=True)
# 定义 loss 函数
criterion = nn.CrossEntropyLoss()
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
# 初始化梯度平方项和动量项
sqrs = []
vs = []
for param in net.parameters():
sqrs.append(torch.zeros_like(param.data))
vs.append(torch.zeros_like(param.data))
t = 1
# 开始训练
losses = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
net.zero_grad()
loss.backward()
adam(net.parameters(), vs, sqrs, 1e-3, t) # 学习率设为 0.001
t += 1
# 记录误差
train_loss += loss.data
if idx % 30 == 0:
losses.append(loss.data)
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
x_axis = np.linspace(0, 5, len(losses), endpoint=True)
plt.semilogy(x_axis, losses, label='adam')
plt.legend(loc='best')
以下为运行的结果
epoch: 0, Train Loss: 0.372057
epoch: 1, Train Loss: 0.186132
epoch: 2, Train Loss: 0.132870
epoch: 3, Train Loss: 0.107864
epoch: 4, Train Loss: 0.091208
使用时间: 85.96051 s
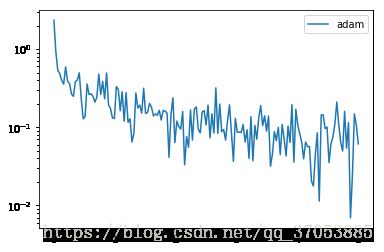
当然 pytorch 中也内置了 adam 的实现,只需要调用 torch.optim.Adam(),下面是例子
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
# 开始训练
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data[0]
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
在学习完以上四种参数的优化方法之后我们在这里对四种方法进行对比,观察loss函数的变化情况(loss越小并不代表最终的模型效果越好)
以下为四中算法进行比较的代码
import numpy as np
import torch
from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据
from torch.utils.data import DataLoader
from torch import nn
from torch.autograd import Variable
import time
import matplotlib.pyplot as plt
# %matplotlib inline
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
# 下载训练集 MNIST手写数字训练集
train_set = MNIST(root='/home/hk/Desktop/learn_pytorch/data', train=True, transform=data_tf, download=False)#data_tf auto normalization in the process of the transform
test_set = MNIST(root='/home/hk/Desktop/learn_pytorch/data', train=False, transform=data_tf, download=True)
# 定义 loss 函数
criterion = nn.CrossEntropyLoss()
def sgd_momentum(parameters, vs, lr, gamma):
for param, v in zip(parameters, vs):
v[:] = gamma * v + lr * param.grad.data
param.data = param.data - v
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
# 将速度初始化为和参数形状相同的零张量
vs = []
for param in net.parameters():
vs.append(torch.zeros_like(param.data))
# 开始训练
print("*"*10)
losses = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
net.zero_grad()
loss.backward()
sgd_momentum(net.parameters(), vs, 1e-2, 0.9) # 使用的动量参数为 0.9,学习率 0.01
# 记录误差
train_loss += loss.data
if idx % 30 == 0:
losses.append(loss.data)
idx+=1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('Momentum:使用时间: {:.5f} s'.format(end - start))
#SGD
optimizer = torch.optim.SGD(net.parameters(), lr=1e-2) # 不加动量
# 开始训练
print("*"*10)
losses1 = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data
if idx % 30 == 0: # 30 步记录一次
losses1.append(loss.data)
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('SGD:使用时间: {:.5f} s'.format(end - start))
#Adam
print("*"*10)
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
losses2 = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
net.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data
if idx % 30 == 0:
losses2.append(loss.data)
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('Adam:使用时间: {:.5f} s'.format(end - start))
#RMSProp
print("*"*10)
optimizer = torch.optim.RMSprop(net.parameters(), lr=1e-3, alpha=0.9)
losses3 = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
net.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data
if idx % 30 == 0:
losses3.append(loss.data)
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('RMSProp:使用时间: {:.5f} s'.format(end - start))
#Adagrad
print("*"*10)
optimizer = torch.optim.Adagrad(net.parameters(), lr=1e-2)
losses4 = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
net.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data
if idx % 30 == 0:
losses4.append(loss.data)
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('Adagrad:使用时间: {:.5f} s'.format(end - start))
x_axis = np.linspace(0, 5, len(losses), endpoint=True)
plt.semilogy(x_axis, losses, label='Momentum:alpha=0.9')
plt.semilogy(x_axis, losses1, label='SGD')
plt.semilogy(x_axis, losses2, label='Adam')
plt.semilogy(x_axis, losses3, label='RMSProp:alpha=0.9')
plt.semilogy(x_axis, losses4, label='Adagrad')
plt.legend(loc='best')
plt.show()
以下是代码的运行结果
**********
epoch: 0, Train Loss: 0.370089
epoch: 1, Train Loss: 0.171468
epoch: 2, Train Loss: 0.123055
epoch: 3, Train Loss: 0.098832
epoch: 4, Train Loss: 0.085154
Momentum:使用时间: 78.35162 s
**********
epoch: 0, Train Loss: 0.056292
epoch: 1, Train Loss: 0.052914
epoch: 2, Train Loss: 0.051503
epoch: 3, Train Loss: 0.050107
epoch: 4, Train Loss: 0.049181
SGD:使用时间: 55.99813 s
**********
epoch: 0, Train Loss: 0.109644
epoch: 1, Train Loss: 0.087866
epoch: 2, Train Loss: 0.080869
epoch: 3, Train Loss: 0.070733
epoch: 4, Train Loss: 0.063566
Adam:使用时间: 81.13758 s
**********
epoch: 0, Train Loss: 0.062457
epoch: 1, Train Loss: 0.057542
epoch: 2, Train Loss: 0.054834
epoch: 3, Train Loss: 0.051196
epoch: 4, Train Loss: 0.048507
RMSProp:使用时间: 64.00369 s
**********
epoch: 0, Train Loss: 0.061198
epoch: 1, Train Loss: 0.014729
epoch: 2, Train Loss: 0.011167
epoch: 3, Train Loss: 0.009214
epoch: 4, Train Loss: 0.007709
Adagrad:使用时间: 53.32201 s

最后两个动画展示多种不同的参数更新方法的过程对比,可以直观的观察到参数更新的过程。
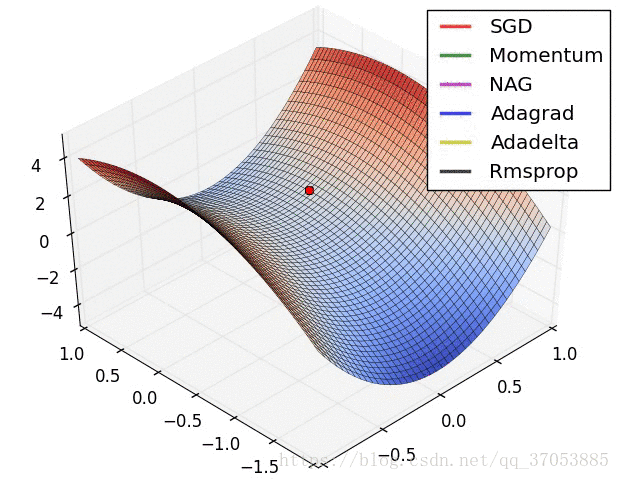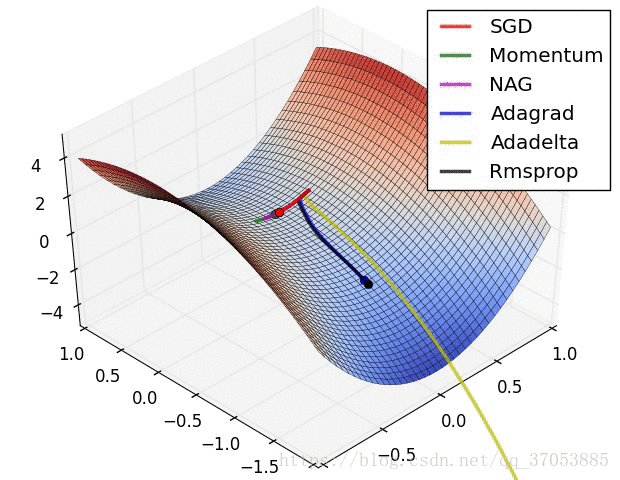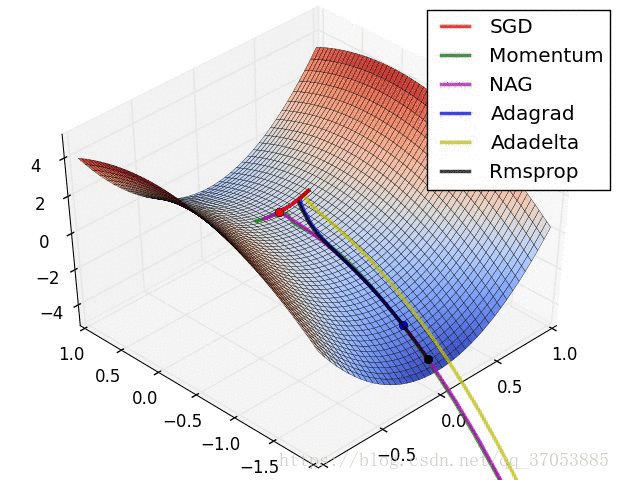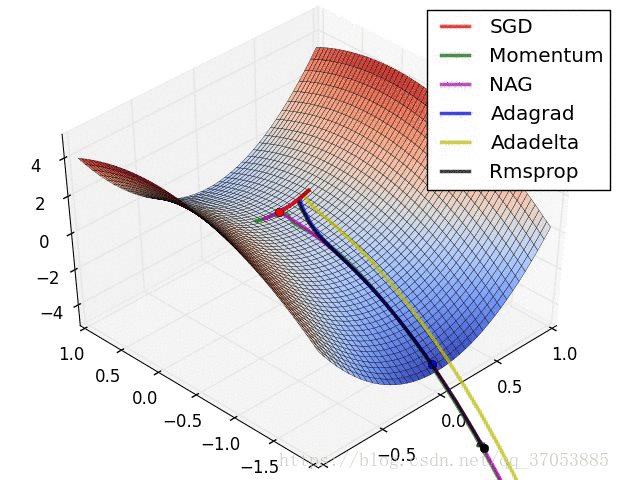

力推:(可以多优化算法的框架有个全局的了解)
https://zhuanlan.zhihu.com/p/32230623
最后再附上一张深度学习中各种优化算法的发展关系图谱

References:
http://ruder.io/optimizing-gradient-descent/index.html
https://github.com/L1aoXingyu/code-of-learn-deep-learning-with-pytorch