爬虫实战,模拟登录网站
准备工具:
-
chrome浏览器
-
SwitchyOmega代理插件
-
fiddler抓包工具
-
python
目标分析:
目标:微博易中所有自媒体平台中账户信息,分类下图所示
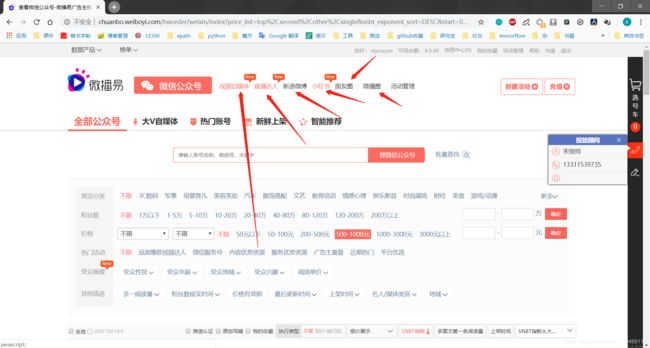
具体信息如下图所示:

由于用户登录后才能在此网站查看相应的数据,爬虫也是模拟人的行为,因此需要进行模拟登陆,然后方可发送相应强求,以获得相应数据。
模拟登陆:
通过抓包得,此网站通过发送一个form表单进行登录。form表单中包含如下信息
"web_csrf_token": "undefined",
"mode": "1",
"typelogin":"1/",
"piccode":captcha,
"username":"",
"password":""
其中可变的是piccode,username,password,piccode是验证码的字符串,username是用户名,password是密码。用户名和密码可以通过注册账号进行获得。因此需要搞清验证码的来源。
获取验证码
通过后台抓包发现,通过发送请求 (url = "http://chuanbo.weiboyi.com/hwauth/index/captcha?web_csrf_token=undefined"),可以获得一个包含验证url的json({"url":"http:\/\/img.weiboyi.com\/images\/captcha\/45a3e222a5ae77a5cf232ce6cfe3c08b.png"}),如下图所示
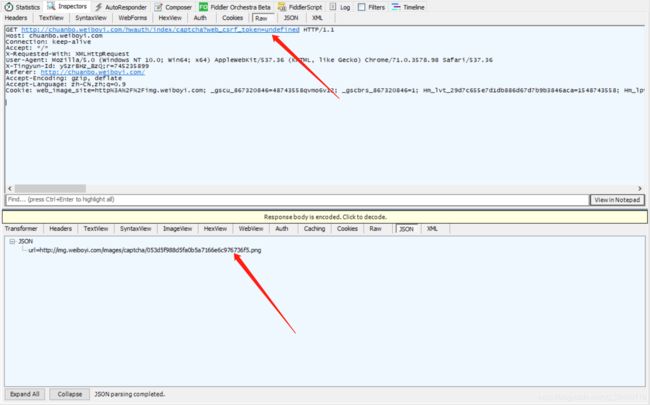
因此需要提取json中的url,然后发送请求,获得验证码图片,代码如下:
def get_json_contains_the_info_of_url_of_capture(self):
url = "http://chuanbo.weiboyi.com/hwauth/index/captcha?web_csrf_token=undefined"
response = sess.get(url=url, headers=headers)
print response.content
return response.content
"""
从content中获取验证码的url
"""
pattern = re.compile(r"http:.*.png")
result = pattern.findall(content)
return result[0].replace("\\", "").replace(" ", "")
"""
下载验证码的图片并保存在本地的./capture.png下
"""
response = sess.get(url_of_capture, headers=headers)
# print(response.content)
with open("capture.png", "wb") as f:
f.write(response.content)
在获得验证码图片后,通过手动输入验证码的形式完成登录;
登录
代码如下
captcha = raw_input("please input the captcha:")
url_of_login = "http://chuanbo.weiboyi.com/"
form_data_of_login = {
"web_csrf_token": "undefined",
"mode": "1",
"typelogin":"1/",
"piccode":captcha,
"username":"******",
"password":"******"
}
response = sess.post(url=url_of_login, data=form_data_of_login, headers=login_headers)
print response.content
运行结果为:
{"status":true,"message":"\u767b\u5f55\u6210\u529f!"}
完整代码如下,由于隐私用*代替了账户和密码
# /usr/bin/python3.6
# -*- coding:utf-8 -*-
import requests
import time
import re
def get_linux_time_of_str():
linux_time= time.time()
return str(int(linux_time*1000))
def get_the_url_of_capture_from_response(content):
pattern = re.compile(r"http:.*.png")
result = pattern.findall(content)
return result[0].replace("\\", "").replace(" ", "")
def get_the_url_of_capcha(sess, headers):
url_of_getting_capture = "http://chuanbo.weiboyi.com/hwauth/index/captcha?web_csrf_token=undefined"
response = sess.get(url=url_of_getting_capture, headers=headers)
url_of_capture = get_the_url_of_capture_from_response(response.content)
return url_of_capture
def get_the_photo_of_capcha(sess, headers, url_of_capture):
response = sess.get(url_of_capture, headers=headers)
# print(response.content)
with open("capture.png", "wb") as f:
f.write(response.content)
def login(sess, headers):
data = {
"pvid":" 6e6448e8-2244-45f3-81fc-288e98f5f72a",
"ref ":"http://chuanbo.weiboyi.com/",
"referrer":" http://chuanbo.weiboyi.com/",
"key":" ilUGEioG6wY",
"v":" 1.7.5",
"av ":" 1.7.5",
"did ":"efd85911-fded-4fdd-8307-0557ded4383d",
"sid ":"e5f624f6-06ff-4e39-934b-4642ee3c5926",
"__r ":get_linux_time_of_str()
}
url = "http://beacon.tingyun.com/xhr1"
sess.post(url=url, data=data, headers=headers)
# 模拟登陆
capture = raw_input("please input the capture:")
print("capture", capture)
data = {
"web_csrf_token": "undefined",
"mode": "1",
"typelogin":"1/",
"piccode":capture,
"username":"******",
"password":"******"
}
url_to_login = "http://chuanbo.weiboyi.com/"
response = sess.post(url=url_to_login, data=data, headers=headers)
print response.content
response = sess.get("http://chuanbo.weiboyi.com/")
with open("index_temp.html", "w") as f:
f.write(response.content)
def main():
sess = requests.session()
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 获取index
url = "http://www.weiboyi.com/"
sess.get(url,headers=headers)
# 获取验证码连接
url_of_capture = get_the_url_of_capcha(sess, headers)
# 获去验证码图片
get_the_photo_of_capcha(sess, headers, url_of_capture)
#
login(sess, headers)
if __name__ == "__main__":
main()