c语言*零碎知识便签
这篇博客是写一写c语言学习过程中的一些零碎的知识,不定时更新!一部分原创,一部分转自一些博客,或者是摘抄书本上的讲解~,c语言知识本来就比较零碎,感觉就是捡漏一样。
1
引脚,又叫管脚,英文叫 Pin。就是从集成电路(芯片)内部电路引出与外围电路的接线,所有的引脚就构成了这块芯片的接口。引线末端的一段,通过软钎焊使这一段与印制板上的焊盘共同形成焊点。我们电脑的触摸鼠标就是运用了引脚。
2
Abort 终止
\t 制表符
\n 回车符 16
\0 字符串结束的标志
0 数字0
‘0’ char字符0 48
‘\0’ char字符反斜杠0 标志一个字符串的结束
%d 打印十进制
%p 打印地址
0x%x 打印十六进制
%u 打印无符号数
\取整
%取余 只有整数可以取余
\接续符号 将两行连接在一起
3
代码段
代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
4
栈(栈里存放的数据是先进去后出来)
1.栈的定义
栈是限制仅在表的一端进行插入和删除运算的线性表又称为后进先出表(LIFO表)。插入、删除端称为栈顶,另一端称栈底。表中无元素称空栈。
2 栈的逻辑结构和存储表示
栈的逻辑结构和线性表相同。
栈的抽象数据类型有两种典型的存储表示:基于数组的存储表示和基于链表的存储表示。
(1)基于数组的存储表示实现的栈称为顺序栈,顺序栈可以采用顺序表作为其存储表示,因此,可以在顺序栈的声明中用顺序表定义它的存储空间。
(2)基于链表的存储表示实现的栈称为链式栈,链式栈可以采用单链表作为其存储表示,因此,可以在链式栈的声明中用单链表定义它的存储空间。
5
内联函数 inline
Tip: 只有当函数只有 10 行甚至更少时才将其定义为内联函数.
定义: 当函数被声明为内联函数之后, 编译器会将其内联展开, 而不是按通常的函数调用机制进行调用.
优点: 当函数体比较小的时候, 内联该函数可以令目标代码更加高效. 对于存取函数以及其它函数体比较短, 性能关键的函数, 鼓励使用内联.
缺点: 滥用内联将导致程序变慢. 内联可能使目标代码量或增或减, 这取决于内联函数的大小. 内联非常短小的存取函数通常会减少代码大小, 但内联一个相当大的函数将戏剧性的增加代码大小. 现代处理器由于更好的利用了指令缓存, 小巧的代码往往执行更快。
6
寄存器
寄存器是cpu的小太监,就是比在内存读取数据要快,但是寄存器很贵,一般一个电脑几十个寄存器的样子。
寄存器是CPU内部的元件,寄存器拥有非常高的读写速度,所以在寄存器之间的数据传送非常快。
寄存器用途
1.可将寄存器内的数据执行算术及逻辑运算;
2.存于寄存器内的地址可用来指向内存的某个位置,即寻址;
3.可以用来读写数据到电脑的周边设备。
7
printf()函数入参
例如:
打印出 a + b + c / b = b * 2 / c = c * 3
按照编译器从左至右编译的结果应该是打印a+b+c 再把b*2的值赋给b
结果应该是 6 4 9
但是结果是 14 4 9
这里我们要注意 printf函数的打印入参是从右到左的!
也就是说先把b*2的值赋给b c * 3的数值赋给c 然后再计算的a+b+c

8
内存中没有出现变量名,只是出现地址。
例如 :int a = 3
内存中不会存储a这个变量,只是为a开辟了一块内存,数值3就以二进制存放在这块地址里面。
函数名也是一个地址值。
在c语言里面,正数是按原码存放的,而负数是按补码(反码+1)存放的,在对负数进行操作(例如位与,位或时)都是对它的补码进行操作,而不是原码。
在对正负数进行操作时:
负数右移,左边自动补1,正数右移,左边自动补0
~ 是按位取反,符号位也会取反!
计算机存放的都是补码存放的 因此操作起来也是对补码进行操作。
9
循环
If()可以放什么
条件表达式 数字 小数 表达式
switch()里面可以放什么
条件表达式 数字 表达式 (不能放小数)
for (int i =1;i< 6;i++) c++里面可以这么写
for (i=1;i< 6; i++) 标准c里面要这么写
10
程序预处理过程
程序开头的头文件,编译程序时编译器会把头文件先展开。
我们可以通过预编译生成的文件来查看这个展开过程。
在linux下gcc file.c -E (预先编译)-o(指定名字)filename
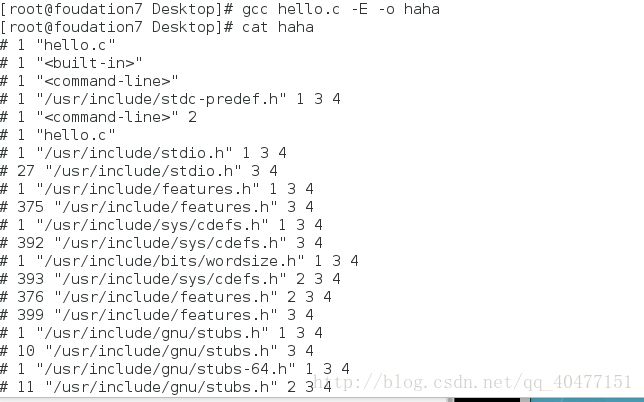
一直到最后才是我们写入的程序结构。
11
sizeof
sizeof不是函数,它是c语言的一个关键字
1.求变量开辟空间的大小 sizeof(a)
2.求类型声明的变量开辟的空间大小 sizeof(int)
3.求常量需要的空间大小sizeof(65)
sizeof出来的数可以当做常量来使用。
12
数据类型的隐式转换
当不同类型的数据进行运算的时候会发生隐式转换
不同数据类型进行运算是时:
四个看齐
1.整型要向浮点型看齐
2.float 向double 看齐
3.短字节向长字节看齐
4.有符号向无符号看齐
低精度转化成高精度
短字节转化为长字节
13
宏
预处理
预处理 ——-> 编译——-> 汇编——–> 链接—
在预处理阶段 会处理 “#”开头的预处理语句
在于处理阶段 会把宏替换原来宏定义的后面的一串代码
1.无参宏
#indefine 宏名 一串代码
#indefine PI 3.14159262.带参数的宏
#define SUM(x,y) x+y例:ret=SUM(1,2);<——————> ret=1+2;
#define MUL(x,y) x*y;
ret=MUL(1+2,3+3); <----------------->ret=1+2*3+3;所以定义带参宏的宏 参数和整体最好都要加();
宏定义和函数的区别:
宏定义在同一行;
宏会使代码体积增大 函数不会
定义方式不一样
宏不会压栈
宏不检查类型 函数会检查
宏不能调用自己 函数可以
14
if
elseif
else
是三者选其中一个
15
指针的大小
在ubuntu系统下,32位的编译器,指针大小是四个字节。
在linux系统下,64位的编译器,指针的大小是八个字节。
16
函数的返回值
函数只能有一个返回值,如果想要看其他的值,必须要引用类型是指针的参数。
例如下面这段代码当中的找到数组中最大值的下标的函数中的int *p就是一个输出型参数。(因为你此时不仅想知道最大值是多少,还想知道的是最大值的下标是多少)
#include 2; i++)
{
temp = arr[lenth-1-i];
arr[lenth-1-i] = arr[i];
arr[i] = temp;
}
}
//打印数组的函数
void func_show_arr(int arr[], int lenth)
{
int i = 0;
for (i=0; iprintf("arr[%d] = %d.\n", i, arr[i]);
}
}
//找到数组中最大值的下标的函数
int find_max_data(int arr[], int lenth, int *p)
{
int i = 0, max = arr[0];
//假设下标0的数组元素是最大的数arr[0]
for (i=0; i//判断max是不是需要更新
if (arr[i]>max)
{
max = arr[i];
//更新max
*p = i;
}
}
return max;
}
int main(void)
{
/*
int index = 0, max = 0;
int arr[5] = {1, 2, 6, 3, 0};
max = find_max_data(arr, 5, &index);
printf("下标%d是最大的元素%d.\n", index, max);
*/
/*
int arr[5] = {1, 2, 3, 4, 5};
func_show_arr(arr, 5);
/调用函数,首尾元素调用{5, 4, 3, 2, 1}
func(arr, 5);
func_show_arr(arr, 5);
*/
return 0;
} 17
数组名
arr 代表数组首元素的首地址
&arr 数组的地址
&arr[0] 首元素的首地址
18
putchar
putchar(10); 等同于 printf(“\n”)和putchar(‘\n’)
19
char *和str【】的区别(代码段只读代码和栈里面的代码)
定义char *类型的p1 和p2
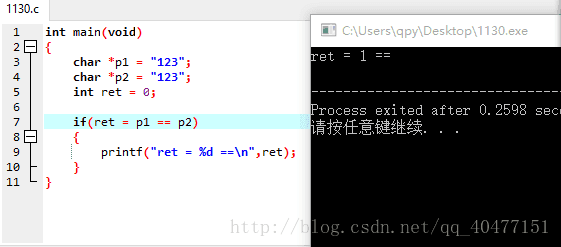
p1 p2指向的都是代码段中的同一个123
p1 p2中存放的地址是一样的
定义char类型分的str1[]和str2[]

str1[]和str2[]的123都存放在栈里,而且在不同的位置。
所以ret=0
20
内存对齐
首先说说为什么要对齐。为了提高效率,计算机从内存中取数据是按照一个固定长度的。以32位机为例,它每次取32个位,也就是4个字节(每字节8个位)。
字节对齐有什么好处?
以int型数据为例,如果它在内存中存放的位置按4字节对齐,也就是说1个int的数据全部落在计算机一次取数的区间内,那么只需要取一次就可以了。如果不对齐,很不巧,这个int数据刚好跨越了取数的边界,这样就需要取两次才能把这个int的数据全部取到,这样效率也就降低了。
内存对齐是会浪费一些空间的。但是这种空间上得浪费却可以减少取数的时间。这是典型的一种以空间换时间的做法。
以下以GCC为例讲解结构体的对齐.
一、原则:
1.结构体内成员按自身按自身长度自对齐。
自身长度,如char=1,short=2,int=4,double=8,。所谓自对齐,指的是该成员的起始位置的内存地址必须是它自身长度的整数倍。如int只能以0,4,8这类的地址开始
2.结构体的总大小为结构体的有效对齐值的整数倍
结构体的有效对齐值的确定:
1)当未明确指定时,以结构体中最长的成员的长度为其有效值
2)当用#pragma pack(n)指定时,以n和结构体中最长的成员的长度中较小者为其值。
3)当用attribute ((packed))指定长度时,强制按照此值为结构体的有效对齐值。
我们来看两个程序理解一下结构体的内存对齐:
(gcc编译器)
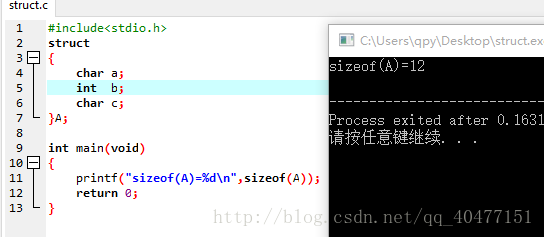
结构体A在内存中放的是
0 a
1
2
3
4 b
5 b
6 b
7 b
8 c
9
10
11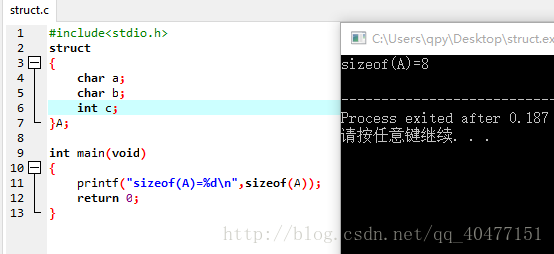
此时结构体A在内存中放的是:
0 a
1 b
2
3
4 c
5 c
6 c
7 c21
◆ 总线的概念 所谓总线(Bus),一般指通过分时复用的方式,将信息以一个或多个源部件传送到一个或多个目的部件的一组传输线。是电脑中传输数据的公共通道。
◆ 工作原理
当 总线空闲(其他器件都以高阻态形式连接在总线上)且一个器件要与目的器件通信时,发起通信的器件驱动总线,发出地址和数据。其他以高阻态形式连接在总线上的器件如果收到(或能够收到)与自己相符的地址信息后,即接收总线上的数据。发送器件完成通信,将总线让出(输出变为高阻态)。
◆ 总线的分类
系统总线包含有三种不同功能的总线,即数据总线DB(Data Bus)、地址总线AB(Address Bus)和控制总线CB(Control Bus)
”
数据总线DB用于传送数据信息。数据总线是双向三态形式的总线,即他既可以把CPU的数据传送到存储器或I/O接口等其它部件,也可以将其它部件的数据传送到CPU。需要指出的是,数据的含义是广义的,它可以是真正的数据,也可以指令代码或状态信息,有时甚至是一个控制信息,因此,在实际工作中,数据总线上传送的并不一定仅仅是真正意义上的数据。“
”
地址总线AB是专门用来传送地址的,由于地址只能从CPU传向外部存储器或I/O端口,所以地址总线总是单向三态的,这与数据总线不同。地址总线的位数决定了CPU可直接寻址的内存空间大小,比如8位微机的地址总线为16位,则其最大可寻址空间为216=64KB,16位微型机的地址总线为20位,其可寻址空间为220=1MB。一般来说,若地址总线为n位,则可寻址空间为2n字节。“
“
控制总线CB用来传送控制信号和时序信号。控制信号中,有的是微处理器送往存储器和I/O接口电路的,如读/写信号,片选信号、中断响应信号等;也有是其它部件反馈给CPU的,比如:中断申请信号、复位信号、总线请求信号、限备就绪信号等。因此,控制总线的传送方向由具体控制信号而定,一般是双向的,控制总线的位数要根据系统的实际控制需要而定。实际上控制总线的具体情况
22
man 3 查看的是c库函数
man 2 查看的是系统的API
23
关于<< 和 >>产生的临时变量的类型
看下面程序:
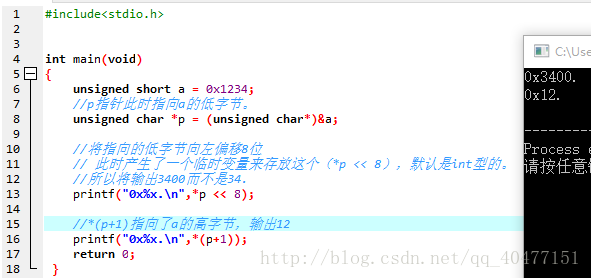
24
大端和小端存储
大端字节序:数据的高字节保存在低地址。
小端字节序:数据的高字节保存在高地址。
TCP/IP协议
RFC1700规定使用“大端”字节序为网络字节序,其他不使用大端的计算机要注意了,发送数据的时候必须要将自己的主机字节序转换为网络字节序(即“大端”字节序),接收到的数据再转换为自己的主机字节序。这样就与CPU、操作系统无关了,实现了网络通信的标准化。
像ip/port(端口)等这些都是网络字节序,因此在传给外面的时候要将本地的字节序装换为大端模式,可以使用函数 htons
25
windows下可执行文件的后缀是exe
而linux下的二进制可执行文件是elf
26
size_t是int的意思,还有ssize_t。
27
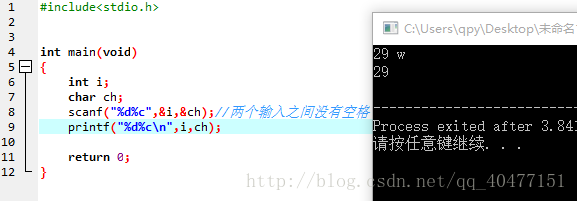
scanf 的 输入 问题
如图:
此时输入29空格w
29赋给了i 空格赋给了ch
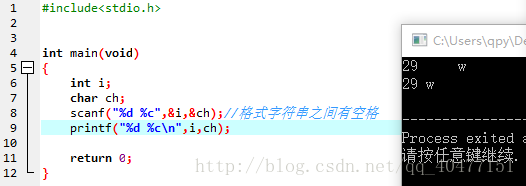
格式字符串内部的空白字符可以匹配输入中的任意个空白字符串
如图:
此时的29赋给了i
w赋给了ch
用 scanf函数接受字符串的时候是无法接受空格和回车的,遇到空格和回车就默认接受已经结束了!!
如图:
虽然我键入了hello world 但是输出只有hello 也就是说在空格处scanf就认为已经结束了
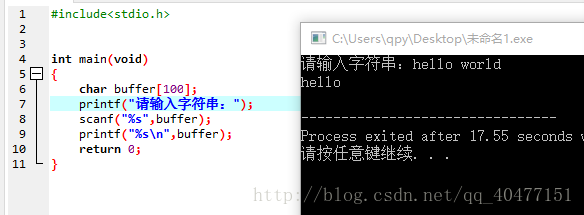
要避免这种可以用fgets函数 fgets(buffer,LEN,stdin)就可以避免键入空格或者回车符这些导致scanf函数接受结束的情况!
28
EOF(End of file)是C/C++里面的宏定义,具体定义式是#define EOF -1,表示的是文件的结束标志,值等于-1,一般用在文件读取的函数里面,比如fscanf fgetc fgets等,一旦读取到文件最后就返回EOF标志并结束函数调用
29
函数的参数的压栈顺序
void func(int k,char * sz,int b)
对于这个问题,我们要知道两点:第一,参数压栈的顺序是从右到左,对应到上面的代码也就是先压b,然后是sz,最后是k。 第二,栈空间是从高地址向低地址发展的。
所以,我们可以估计出他们在内存中的分布,从高地址到低地址的顺序是:b, sz,k。
30
.分别写出BOOL,int,float,指针类型的变量a 与“零”的比较语句。
答案:
bool : if ( !a ) or if(a)
int : if ( a == 0)
float : const EXPRESSION EXP = 0.000001
if ( a < EXP && a >-EXP)
pointer : if ( a != NULL) or if(a == NULL)