python入门爬虫3 妹子图网站爬取,成功保存性感妹妹照片!
爬取网站:https://www.mzitu.com/
我选择了爬取性感小姐姐的照片嘻嘻嘻,先看看我爬取下来的成果吧~超简单的哦
怎么办作为一个女孩子我都要心动了,言归正传!我们是来学习的!

首先分为以下四个部分
1.请求妹子图,拿到整体数据
2.抽取想要的属性
3.下载图片
4.保存图片
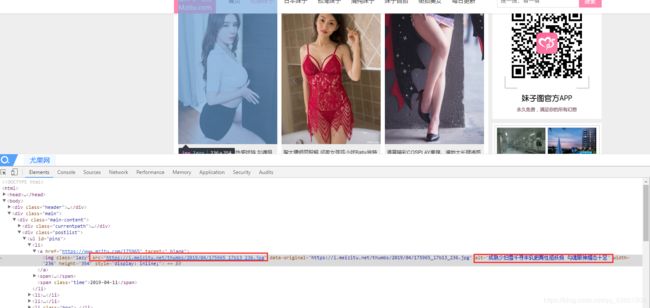
分析以下网页吧,按F12或者右击第一张图片选择检查/审查元素(浏览器不同叫法也不同,耐心找一下啦~)
在代码的以下部分可以找到第一张图片的地址和图片名称
这就是我们要提取的内容!
使用xpath解析器,使用//的话可以直接跳到 img class=“lazy”这个标签下,/需要从上往下一层一层的跳下来
注意解析时,class属性需要使用[]和@包裹起来
然后再使用/来提取子节点中需要的属性
代码如下:
alt_list = html.xpath('//img[@class="lazy"]/@alt')
src_list = html.xpath('//img[@class="lazy"]/@data-original')
下面直接放完整源码了,需要补充的地方我在代码中注释
import requests
from lxml import etree
header = {
"Referer" : "https://www.mzitu.com/xinggan/", #防盗链,下载图片时需要使用在network中跟user agent一起的地方可以找到
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
# 1.请求妹子图拿到整体数据
response = requests.get('https://www.mzitu.com/xinggan/')
html = etree.HTML(response.text)
#2.抽取想要的属性
alt_list = html.xpath('//img[@class="lazy"]/@alt')
src_list = html.xpath('//img[@class="lazy"]/@data-original')
for alt,src in zip(alt_list,src_list): #将标签和图片整合到一起
# 3.下载图片
response = requests.get(src,headers = header) #src时图片地址
file_name = "phone\\" + alt + ".jpg" # 在这个文件夹中建立一个phone的目录,用于存放下载好的图片,\\表示一个\ alt是图片名称
print("正在保存妹子图片文件:"+file_name)
# 4.保存图片
with open(file_name,"wb")as f: #wb是写二进制
f.write(response.content)
很简单啦~大家可以思考一下怎样翻页哦