Python之网络爬虫完全教程
原文传送门:http://blog.csdn.net/column/details/why-bug.html
[Python]网络爬虫(一):抓取网页的含义和URL基本构成
一、网络爬虫的定义
网络爬虫,即Web Spider,是一个很形象的名字。
把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。
网络蜘蛛是通过网页的链接地址来寻找网页的。
从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,
然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
这样看来,网络爬虫就是一个爬行程序,一个抓取网页的程序。
网络爬虫的基本操作是抓取网页。
那么如何才能随心所欲地获得自己想要的页面?
我们先从URL开始。
二、浏览网页的过程
抓取网页的过程其实和读者平时使用IE浏览器浏览网页的道理是一样的。
比如说你在浏览器的地址栏中输入 www.baidu.com 这个地址。
打开网页的过程其实就是浏览器作为一个浏览的“客户端”,向服务器端发送了 一次请求,把服务器端的文件“抓”到本地,再进行解释、展现。
HTML是一种标记语言,用标签标记内容并加以解析和区分。
三、URI和URL的概念和举例
简单的来讲,URL就是在浏览器端输入的 http://www.baidu.com 这个字符串。
在理解URL之前,首先要理解URI的概念。
什么是URI?
Web上每种可用的资源,如 HTML文档、图像、视频片段、程序等都由一个通用资源标志符(Universal Resource Identifier, URI)进行定位。
URI通常由三部分组成:
①访问资源的命名机制;
②存放资源的主机名;
③资源自身 的名称,由路径表示。
如下面的URI:
http://www.why.com.cn/myhtml/html1223/
我们可以这样解释它:
①这是一个可以通过HTTP协议访问的资源,
②位于主机 www.webmonkey.com.cn上,
③通过路径“/html/html40”访问。
四、URL的理解和举例
URL是URI的一个子集。它是Uniform Resource Locator的缩写,译为“统一资源定位 符”。
通俗地说,URL是Internet上描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上。
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。
URL的一般格式为(带方括号[]的为可选项):
protocol :// hostname[:port] / path / [;parameters][?query]#fragment
URL的格式由三部分组成:
①第一部分是协议(或称为服务方式)。
②第二部分是存有该资源的主机IP地址(有时也包括端口号)。
③第三部分是主机资源的具体地址,如目录和文件名等。
第一部分和第二部分用“://”符号隔开,
第二部分和第三部分用“/”符号隔开。
第一部分和第二部分是不可缺少的,第三部分有时可以省略。
五、URL和URI简单比较
URI属于URL更低层次的抽象,一种字符串文本标准。
换句话说,URI属于父类,而URL属于URI的子类。URL是URI的一个子集。
URI的定义是:统一资源标识符;
URL的定义是:统一资源定位符。
二者的区别在于,URI表示请求服务器的路径,定义这么一个资源。
而URL同时说明要如何访问这个资源(http://)。
下面来看看两个URL的小例子。
1.HTTP协议的URL示例:
使用超级文本传输协议HTTP,提供超级文本信息服务的资源。
例:http://www.peopledaily.com.cn/channel/welcome.htm
其计算机域名为www.peopledaily.com.cn。
超级文本文件(文件类型为.html)是在目录 /channel下的welcome.htm。
这是中国人民日报的一台计算机。
例:http://www.rol.cn.net/talk/talk1.htm
其计算机域名为www.rol.cn.net。
超级文本文件(文件类型为.html)是在目录/talk下的talk1.htm。
这是瑞得聊天室的地址,可由此进入瑞得聊天室的第1室。
2.文件的URL
用URL表示文件时,服务器方式用file表示,后面要有主机IP地址、文件的存取路 径(即目录)和文件名等信息。
有时可以省略目录和文件名,但“/”符号不能省略。
例:file://ftp.yoyodyne.com/pub/files/foobar.txt
上面这个URL代表存放在主机ftp.yoyodyne.com上的pub/files/目录下的一个文件,文件名是foobar.txt。
例:file://ftp.yoyodyne.com/pub
代表主机ftp.yoyodyne.com上的目录/pub。
例:file://ftp.yoyodyne.com/
代表主机ftp.yoyodyne.com的根目录。
爬虫最主要的处理对象就是URL,它根据URL地址取得所需要的文件内容,然后对它 进行进一步的处理。
因此,准确地理解URL对理解网络爬虫至关重要。
[Python]网络爬虫(二):利用urllib2通过指定的URL抓取网页内容
版本号:Python2.7.5,Python3改动较大,各位另寻教程。
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。
类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的内容发送到服务器端, 然后读取服务器端的响应资源。
在Python中,我们使用urllib2这个组件来抓取网页。
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。
它以urlopen函数的形式提供了一个非常简单的接口。
最简单的urllib2的应用代码只需要四行。
我们新建一个文件urllib2_test01.py来感受一下urllib2的作用:
- import urllib2
- response = urllib2.urlopen('http://www.baidu.com/')
- html = response.read()
- print html
按下F5可以看到运行的结果:

我们可以打开百度主页,右击,选择查看源代码(火狐OR谷歌浏览器均可),会发现也是完全一样的内容。
也就是说,上面这四行代码将我们访问百度时浏览器收到的代码们全部打印了出来。
这就是一个最简单的urllib2的例子。
除了"http:",URL同样可以使用"ftp:","file:"等等来替代。
HTTP是基于请求和应答机制的:
客户端提出请求,服务端提供应答。
urllib2用一个Request对象来映射你提出的HTTP请求。
在它最简单的使用形式中你将用你要请求的地址创建一个Request对象,
通过调用urlopen并传入Request对象,将返回一个相关请求response对象,
这个应答对象如同一个文件对象,所以你可以在Response中调用.read()。
我们新建一个文件urllib2_test02.py来感受一下:
- import urllib2
- req = urllib2.Request('http://www.baidu.com')
- response = urllib2.urlopen(req)
- the_page = response.read()
- print the_page
可以看到输出的内容和test01是一样的。
urllib2使用相同的接口处理所有的URL头。例如你可以像下面那样创建一个ftp请求。
- req = urllib2.Request('ftp://example.com/')
1.发送data表单数据
这个内容相信做过Web端的都不会陌生,
有时候你希望发送一些数据到URL(通常URL与CGI[通用网关接口]脚本,或其他WEB应用程序挂接)。
在HTTP中,这个经常使用熟知的POST请求发送。
这个通常在你提交一个HTML表单时由你的浏览器来做。
并不是所有的POSTs都来源于表单,你能够使用POST提交任意的数据到你自己的程序。
一般的HTML表单,data需要编码成标准形式。然后做为data参数传到Request对象。
编码工作使用urllib的函数而非urllib2。
我们新建一个文件urllib2_test03.py来感受一下:
- import urllib
- import urllib2
- url = 'http://www.someserver.com/register.cgi'
- values = {'name' : 'WHY',
- 'location' : 'SDU',
- 'language' : 'Python' }
- data = urllib.urlencode(values) # 编码工作
- req = urllib2.Request(url, data) # 发送请求同时传data表单
- response = urllib2.urlopen(req) #接受反馈的信息
- the_page = response.read() #读取反馈的内容
如果没有传送data参数,urllib2使用GET方式的请求。
GET和POST请求的不同之处是POST请求通常有"副作用",
它们会由于某种途径改变系统状态(例如提交成堆垃圾到你的门口)。
Data同样可以通过在Get请求的URL本身上面编码来传送。
- import urllib2
- import urllib
- data = {}
- data['name'] = 'WHY'
- data['location'] = 'SDU'
- data['language'] = 'Python'
- url_values = urllib.urlencode(data)
- print url_values
- name=Somebody+Here&language=Python&location=Northampton
- url = 'http://www.example.com/example.cgi'
- full_url = url + '?' + url_values
- data = urllib2.open(full_url)
这样就实现了Data数据的Get传送。
2.设置Headers到http请求
有一些站点不喜欢被程序(非人为访问)访问,或者发送不同版本的内容到不同的浏览器。
默认的urllib2把自己作为“Python-urllib/x.y”(x和y是Python主版本和次版本号,例如Python-urllib/2.7),
这个身份可能会让站点迷惑,或者干脆不工作。
浏览器确认自己身份是通过User-Agent头,当你创建了一个请求对象,你可以给他一个包含头数据的字典。
下面的例子发送跟上面一样的内容,但把自身模拟成Internet Explorer。
(多谢大家的提醒,现在这个Demo已经不可用了,不过原理还是那样的)。
- import urllib
- import urllib2
- url = 'http://www.someserver.com/cgi-bin/register.cgi'
- user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
- values = {'name' : 'WHY',
- 'location' : 'SDU',
- 'language' : 'Python' }
- headers = { 'User-Agent' : user_agent }
- data = urllib.urlencode(values)
- req = urllib2.Request(url, data, headers)
- response = urllib2.urlopen(req)
- the_page = response.read()
先来说一说HTTP的异常处理问题。
当urlopen不能够处理一个response时,产生urlError。
不过通常的Python APIs异常如ValueError,TypeError等也会同时产生。
HTTPError是urlError的子类,通常在特定HTTP URLs中产生。
1.URLError
通常,URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。
这种情况下,异常同样会带有"reason"属性,它是一个tuple(可以理解为不可变的数组),
包含了一个错误号和一个错误信息。
我们建一个urllib2_test06.py来感受一下异常的处理:
- import urllib2
- req = urllib2.Request('http://www.baibai.com')
- try: urllib2.urlopen(req)
- except urllib2.URLError, e:
- print e.reason
按下F5,可以看到打印出来的内容是:
[Errno 11001] getaddrinfo failed
也就是说,错误号是11001,内容是getaddrinfo failed
2.HTTPError
服务器上每一个HTTP 应答对象response包含一个数字"状态码"。
有时状态码指出服务器无法完成请求。默认的处理器会为你处理一部分这种应答。
例如:假如response是一个"重定向",需要客户端从别的地址获取文档,urllib2将为你处理。
其他不能处理的,urlopen会产生一个HTTPError。
典型的错误包含"404"(页面无法找到),"403"(请求禁止),和"401"(带验证请求)。
HTTP状态码表示HTTP协议所返回的响应的状态。
比如客户端向服务器发送请求,如果成功地获得请求的资源,则返回的状态码为200,表示响应成功。
如果请求的资源不存在, 则通常返回404错误。
HTTP状态码通常分为5种类型,分别以1~5五个数字开头,由3位整数组成:
------------------------------------------------------------------------------------------------
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304 请求的资源未更新 处理方式:丢弃
400 非法请求 处理方式:丢弃
401 未授权 处理方式:丢弃
403 禁止 处理方式:丢弃
404 没有找到 处理方式:丢弃
5XX 回应代码以“5”开头的状态码表示服务器端发现自己出现错误,不能继续执行请求 处理方式:丢弃
------------------------------------------------------------------------------------------------
Error Codes错误码
因为默认的处理器处理了重定向(300以外号码),并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。
BaseHTTPServer.BaseHTTPRequestHandler.response是一个很有用的应答号码字典,显示了HTTP协议使用的所有的应答号。
当一个错误号产生后,服务器返回一个HTTP错误号,和一个错误页面。
你可以使用HTTPError实例作为页面返回的应答对象response。
这表示和错误属性一样,它同样包含了read,geturl,和info方法。
我们建一个urllib2_test07.py来感受一下:
- import urllib2
- req = urllib2.Request('http://bbs.csdn.net/callmewhy')
- try:
- urllib2.urlopen(req)
- except urllib2.URLError, e:
- print e.code
- #print e.read()
按下F5可以看见输出了404的错误码,也就说没有找到这个页面。
3.Wrapping
所以如果你想为HTTPError或URLError做准备,将有两个基本的办法。推荐使用第二种。
我们建一个urllib2_test08.py来示范一下第一种异常处理的方案:
- from urllib2 import Request, urlopen, URLError, HTTPError
- req = Request('http://bbs.csdn.net/callmewhy')
- try:
- response = urlopen(req)
- except HTTPError, e:
- print 'The server couldn\'t fulfill the request.'
- print 'Error code: ', e.code
- except URLError, e:
- print 'We failed to reach a server.'
- print 'Reason: ', e.reason
- else:
- print 'No exception was raised.'
- # everything is fine
和其他语言相似,try之后捕获异常并且将其内容打印出来。
因为HTTPError是URLError的子类,如果URLError在前面它会捕捉到所有的URLError(包括HTTPError )。
我们建一个urllib2_test09.py来示范一下第二种异常处理的方案:
- from urllib2 import Request, urlopen, URLError, HTTPError
- req = Request('http://bbs.csdn.net/callmewhy')
- try:
- response = urlopen(req)
- except URLError, e:
- if hasattr(e, 'reason'):
- print 'We failed to reach a server.'
- print 'Reason: ', e.reason
- elif hasattr(e, 'code'):
- print 'The server couldn\'t fulfill the request.'
- print 'Error code: ', e.code
- else:
- print 'No exception was raised.'
- # everything is fine
在开始后面的内容之前,先来解释一下urllib2中的两个个方法:info and geturl
urlopen返回的应答对象response(或者HTTPError实例)有两个很有用的方法info()和geturl()1.geturl():
这个返回获取的真实的URL,这个很有用,因为urlopen(或者opener对象使用的)或许会有重定向。获取的URL或许跟请求URL不同。
以人人中的一个超级链接为例,
我们建一个urllib2_test10.py来比较一下原始URL和重定向的链接:
- from urllib2 import Request, urlopen, URLError, HTTPError
- old_url = 'http://rrurl.cn/b1UZuP'
- req = Request(old_url)
- response = urlopen(req)
- print 'Old url :' + old_url
- print 'Real url :' + response.geturl()

2.info():
这个返回对象的字典对象,该字典描述了获取的页面情况。通常是服务器发送的特定头headers。目前是httplib.HTTPMessage 实例。
经典的headers包含"Content-length","Content-type",和其他内容。
我们建一个urllib2_test11.py来测试一下info的应用:
- from urllib2 import Request, urlopen, URLError, HTTPError
- old_url = 'http://www.baidu.com'
- req = Request(old_url)
- response = urlopen(req)
- print 'Info():'
- print response.info()

下面来说一说urllib2中的两个重要概念:Openers和Handlers。
1.Openers:
当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例)。
正常情况下,我们使用默认opener:通过urlopen。
但你能够创建个性的openers。
2.Handles:
Openers使用处理器handlers,所有的“繁重”工作由handlers处理。
每个handlers知道如何通过特定协议打开URLs,或者如何处理URL打开时的各个方面。
例如HTTP重定向或者HTTP cookies。
如果你希望用特定处理器获取URLs你会想创建一个openers,例如获取一个能处理cookie的opener,或者获取一个不重定向的opener。
要创建一个 opener,可以实例化一个OpenerDirector,
然后调用.add_handler(some_handler_instance)。
同样,可以使用build_opener,这是一个更加方便的函数,用来创建opener对象,他只需要一次函数调用。build_opener默认添加几个处理器,但提供快捷的方法来添加或更新默认处理器。
其他的处理器handlers你或许会希望处理代理,验证,和其他常用但有点特殊的情况。
Opener对象有一个open方法。
该方法可以像urlopen函数那样直接用来获取urls:通常不必调用install_opener,除了为了方便。
说完了上面两个内容,下面我们来看一下基本认证的内容,这里会用到上面提及的Opener和Handler。
Basic Authentication 基本验证为了展示创建和安装一个handler,我们将使用HTTPBasicAuthHandler。
当需要基础验证时,服务器发送一个header(401错误码) 请求验证。这个指定了scheme 和一个‘realm’,看起来像这样:Www-authenticate: SCHEME realm="REALM".
例如Www-authenticate: Basic realm="cPanel Users"
客户端必须使用新的请求,并在请求头里包含正确的姓名和密码。
这是“基础验证”,为了简化这个过程,我们可以创建一个HTTPBasicAuthHandler的实例,并让opener使用这个handler就可以啦。
HTTPBasicAuthHandler使用一个密码管理的对象来处理URLs和realms来映射用户名和密码。
如果你知道realm(从服务器发送来的头里)是什么,你就能使用HTTPPasswordMgr。
通常人们不关心realm是什么。那样的话,就能用方便的HTTPPasswordMgrWithDefaultRealm。
这个将在你为URL指定一个默认的用户名和密码。
这将在你为特定realm提供一个其他组合时得到提供。
我们通过给realm参数指定None提供给add_password来指示这种情况。
最高层次的URL是第一个要求验证的URL。你传给.add_password()更深层次的URLs将同样合适。
说了这么多废话,下面来用一个例子演示一下上面说到的内容。
我们建一个urllib2_test12.py来测试一下info的应用:
- # -*- coding: utf-8 -*-
- import urllib2
- # 创建一个密码管理者
- password_mgr = urllib2.HTTPPasswordMgrWithDefaultRealm()
- # 添加用户名和密码
- top_level_url = "http://example.com/foo/"
- # 如果知道 realm, 我们可以使用他代替 ``None``.
- # password_mgr.add_password(None, top_level_url, username, password)
- password_mgr.add_password(None, top_level_url,'why', '1223')
- # 创建了一个新的handler
- handler = urllib2.HTTPBasicAuthHandler(password_mgr)
- # 创建 "opener" (OpenerDirector 实例)
- opener = urllib2.build_opener(handler)
- a_url = 'http://www.baidu.com/'
- # 使用 opener 获取一个URL
- opener.open(a_url)
- # 安装 opener.
- # 现在所有调用 urllib2.urlopen 将用我们的 opener.
- urllib2.install_opener(opener)
注意:以上的例子我们仅仅提供我们的HHTPBasicAuthHandler给build_opener。
默认的openers有正常状况的handlers:ProxyHandler,UnknownHandler,HTTPHandler,HTTPDefaultErrorHandler, HTTPRedirectHandler,FTPHandler, FileHandler, HTTPErrorProcessor。
代码中的top_level_url 实际上可以是完整URL(包含"http:",以及主机名及可选的端口号)。
例如:http://example.com/。
也可以是一个“authority”(即主机名和可选的包含端口号)。
例如:“example.com” or “example.com:8080”。
后者包含了端口号。
[Python]网络爬虫(五):urllib2的使用细节与抓站技巧
前面说到了urllib2的简单入门,下面整理了一部分urllib2的使用细节。
1.Proxy 的设置
urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。
如果想在程序中明确控制 Proxy 而不受环境变量的影响,可以使用代理。
新建test14来实现一个简单的代理Demo:
- import urllib2
- enable_proxy = True
- proxy_handler = urllib2.ProxyHandler({"http" : 'http://some-proxy.com:8080'})
- null_proxy_handler = urllib2.ProxyHandler({})
- if enable_proxy:
- opener = urllib2.build_opener(proxy_handler)
- else:
- opener = urllib2.build_opener(null_proxy_handler)
- urllib2.install_opener(opener)
这里要注意的一个细节,使用 urllib2.install_opener() 会设置 urllib2 的全局 opener 。
这样后面的使用会很方便,但不能做更细致的控制,比如想在程序中使用两个不同的 Proxy 设置等。
比较好的做法是不使用 install_opener 去更改全局的设置,而只是直接调用 opener 的 open 方法代替全局的 urlopen 方法。
2.Timeout 设置
在老版 Python 中(Python2.6前),urllib2 的 API 并没有暴露 Timeout 的设置,要设置 Timeout 值,只能更改 Socket 的全局 Timeout 值。
- import urllib2
- import socket
- socket.setdefaulttimeout(10) # 10 秒钟后超时
- urllib2.socket.setdefaulttimeout(10) # 另一种方式
在 Python 2.6 以后,超时可以通过 urllib2.urlopen() 的 timeout 参数直接设置。
- import urllib2
- response = urllib2.urlopen('http://www.google.com', timeout=10)
3.在 HTTP Request 中加入特定的 Header
要加入 header,需要使用 Request 对象:- import urllib2
- request = urllib2.Request('http://www.baidu.com/')
- request.add_header('User-Agent', 'fake-client')
- response = urllib2.urlopen(request)
- print response.read()
对有些 header 要特别留意,服务器会针对这些 header 做检查
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。常见的取值有:
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
urllib2 默认情况下会针对 HTTP 3XX 返回码自动进行 redirect 动作,无需人工配置。要检测是否发生了 redirect 动作,只要检查一下 Response 的 URL 和 Request 的 URL 是否一致就可以了。
- import urllib2
- my_url = 'http://www.google.cn'
- response = urllib2.urlopen(my_url)
- redirected = response.geturl() == my_url
- print redirected
- my_url = 'http://rrurl.cn/b1UZuP'
- response = urllib2.urlopen(my_url)
- redirected = response.geturl() == my_url
- print redirected
如果不想自动 redirect,除了使用更低层次的 httplib 库之外,还可以自定义HTTPRedirectHandler 类。
- import urllib2
- class RedirectHandler(urllib2.HTTPRedirectHandler):
- def http_error_301(self, req, fp, code, msg, headers):
- print "301"
- pass
- def http_error_302(self, req, fp, code, msg, headers):
- print "303"
- pass
- opener = urllib2.build_opener(RedirectHandler)
- opener.open('http://rrurl.cn/b1UZuP')
5.Cookie
urllib2 对 Cookie 的处理也是自动的。如果需要得到某个 Cookie 项的值,可以这么做:- import urllib2
- import cookielib
- cookie = cookielib.CookieJar()
- opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
- response = opener.open('http://www.baidu.com')
- for item in cookie:
- print 'Name = '+item.name
- print 'Value = '+item.value
运行之后就会输出访问百度的Cookie值:

6.使用 HTTP 的 PUT 和 DELETE 方法
urllib2 只支持 HTTP 的 GET 和 POST 方法,如果要使用 HTTP PUT 和 DELETE ,只能使用比较低层的 httplib 库。虽然如此,我们还是能通过下面的方式,使 urllib2 能够发出 PUT 或DELETE 的请求:- import urllib2
- request = urllib2.Request(uri, data=data)
- request.get_method = lambda: 'PUT' # or 'DELETE'
- response = urllib2.urlopen(request)
7.得到 HTTP 的返回码
对于 200 OK 来说,只要使用 urlopen 返回的 response 对象的 getcode() 方法就可以得到 HTTP 的返回码。但对其它返回码来说,urlopen 会抛出异常。这时候,就要检查异常对象的 code 属性了:- import urllib2
- try:
- response = urllib2.urlopen('http://bbs.csdn.net/why')
- except urllib2.HTTPError, e:
- print e.code
8.Debug Log
使用 urllib2 时,可以通过下面的方法把 debug Log 打开,这样收发包的内容就会在屏幕上打印出来,方便调试,有时可以省去抓包的工作- import urllib2
- httpHandler = urllib2.HTTPHandler(debuglevel=1)
- httpsHandler = urllib2.HTTPSHandler(debuglevel=1)
- opener = urllib2.build_opener(httpHandler, httpsHandler)
- urllib2.install_opener(opener)
- response = urllib2.urlopen('http://www.google.com')
这样就可以看到传输的数据包内容了:

9.表单的处理
登录必要填表,表单怎么填?
首先利用工具截取所要填表的内容。
比如我一般用firefox+httpfox插件来看看自己到底发送了些什么包。
以verycd为例,先找到自己发的POST请求,以及POST表单项。
可以看到verycd的话需要填username,password,continueURI,fk,login_submit这几项,其中fk是随机生成的(其实不太随机,看上去像是把epoch时间经过简单的编码生成的),需要从网页获取,也就是说得先访问一次网页,用正则表达式等工具截取返回数据中的fk项。continueURI顾名思义可以随便写,login_submit是固定的,这从源码可以看出。还有username,password那就很显然了:
- # -*- coding: utf-8 -*-
- import urllib
- import urllib2
- postdata=urllib.urlencode({
- 'username':'汪小光',
- 'password':'why888',
- 'continueURI':'http://www.verycd.com/',
- 'fk':'',
- 'login_submit':'登录'
- })
- req = urllib2.Request(
- url = 'http://secure.verycd.com/signin',
- data = postdata
- )
- result = urllib2.urlopen(req)
- print result.read()
10.伪装成浏览器访问
某些网站反感爬虫的到访,于是对爬虫一律拒绝请求
这时候我们需要伪装成浏览器,这可以通过修改http包中的header来实现
- #…
- headers = {
- 'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
- }
- req = urllib2.Request(
- url = 'http://secure.verycd.com/signin/*/http://www.verycd.com/',
- data = postdata,
- headers = headers
- )
- #...
11.对付"反盗链"
某些站点有所谓的反盗链设置,其实说穿了很简单,
就是检查你发送请求的header里面,referer站点是不是他自己,
所以我们只需要像把headers的referer改成该网站即可,以cnbeta为例:
#...
headers = {
'Referer':'http://www.cnbeta.com/articles'
}
#...
headers是一个dict数据结构,你可以放入任何想要的header,来做一些伪装。
例如,有些网站喜欢读取header中的X-Forwarded-For来看看人家的真实IP,可以直接把X-Forwarde-For改了。
[Python]网络爬虫(六):一个简单的百度贴吧的小爬虫
- # -*- coding: utf-8 -*-
- #---------------------------------------
- # 程序:百度贴吧爬虫
- # 版本:0.1
- # 作者:why
- # 日期:2013-05-14
- # 语言:Python 2.7
- # 操作:输入带分页的地址,去掉最后面的数字,设置一下起始页数和终点页数。
- # 功能:下载对应页码内的所有页面并存储为html文件。
- #---------------------------------------
- import string, urllib2
- #定义百度函数
- def baidu_tieba(url,begin_page,end_page):
- for i in range(begin_page, end_page+1):
- sName = string.zfill(i,5) + '.html'#自动填充成六位的文件名
- print '正在下载第' + str(i) + '个网页,并将其存储为' + sName + '......'
- f = open(sName,'w+')
- m = urllib2.urlopen(url + str(i)).read()
- f.write(m)
- f.close()
- #-------- 在这里输入参数 ------------------
- # 这个是山东大学的百度贴吧中某一个帖子的地址
- #bdurl = 'http://tieba.baidu.com/p/2296017831?pn='
- #iPostBegin = 1
- #iPostEnd = 10
- bdurl = str(raw_input(u'请输入贴吧的地址,去掉pn=后面的数字:\n'))
- begin_page = int(raw_input(u'请输入开始的页数:\n'))
- end_page = int(raw_input(u'请输入终点的页数:\n'))
- #-------- 在这里输入参数 ------------------
- #调用
- baidu_tieba(bdurl,begin_page,end_page)
接下来准备用糗百做一个爬虫的小例子。
但是在这之前,先详细的整理一下Python中的正则表达式的相关内容。
正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器。
以下内容转自CNBLOG:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
整理时没有注意,实在抱歉。
一、 正则表达式基础
1.1.概念介绍正则表达式是用于处理字符串的强大工具,它并不是Python的一部分。
其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同。
它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的。
下图展示了使用正则表达式进行匹配的流程:

正则表达式的大致匹配过程是:
1.依次拿出表达式和文本中的字符比较,
2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
3.如果表达式中有量词或边界,这个过程会稍微有一些不同。
下图列出了Python支持的正则表达式元字符和语法:

1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。
贪婪模式,总是尝试匹配尽可能多的字符;
非贪婪模式则相反,总是尝试匹配尽可能少的字符。
Python里数量词默认是贪婪的。
例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。
而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的问题
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。
假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":
第一个和第三个用于在编程语言里将第二个和第四个转义成反斜杠,
转换成两个反斜杠\\后再在正则表达式里转义成一个反斜杠用来匹配反斜杠\。
这样显然是非常麻烦的。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。
同样,匹配一个数字的"\\d"可以写成r"\d"。
有了原生字符串,妈妈再也不用担心我的反斜杠问题~
二、 介绍re模块
2.1. Compile
Python通过re模块提供对正则表达式的支持。
使用re的一般步骤是:
Step1:先将正则表达式的字符串形式编译为Pattern实例。
Step2:然后使用Pattern实例处理文本并获得匹配结果(一个Match实例)。
Step3:最后使用Match实例获得信息,进行其他的操作。
我们新建一个re01.py来试验一下re的应用:
- # -*- coding: utf-8 -*-
- #一个简单的re实例,匹配字符串中的hello字符串
- #导入re模块
- import re
- # 将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串”
- pattern = re.compile(r'hello')
- # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
- match1 = pattern.match('hello world!')
- match2 = pattern.match('helloo world!')
- match3 = pattern.match('helllo world!')
- #如果match1匹配成功
- if match1:
- # 使用Match获得分组信息
- print match1.group()
- else:
- print 'match1匹配失败!'
- #如果match2匹配成功
- if match2:
- # 使用Match获得分组信息
- print match2.group()
- else:
- print 'match2匹配失败!'
- #如果match3匹配成功
- if match3:
- # 使用Match获得分组信息
- print match3.group()
- else:
- print 'match3匹配失败!'
可以看到控制台输出了匹配的三个结果:

下面来具体看看代码中的关键方法。
★ re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。
第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。
另外,你也可以在regex字符串中指定模式,
比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
- re.I(全拼:IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- re.M(全拼:MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
- re.S(全拼:DOTALL): 点任意匹配模式,改变'.'的行为
- re.L(全拼:LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- re.U(全拼:UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- re.X(全拼:VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
以下两个正则表达式是等价的:
- # -*- coding: utf-8 -*-
- #两个等价的re匹配,匹配一个小数
- import re
- a = re.compile(r"""\d + # the integral part
- \. # the decimal point
- \d * # some fractional digits""", re.X)
- b = re.compile(r"\d+\.\d*")
- match11 = a.match('3.1415')
- match12 = a.match('33')
- match21 = b.match('3.1415')
- match22 = b.match('33')
- if match11:
- # 使用Match获得分组信息
- print match11.group()
- else:
- print u'match11不是小数'
- if match12:
- # 使用Match获得分组信息
- print match12.group()
- else:
- print u'match12不是小数'
- if match21:
- # 使用Match获得分组信息
- print match21.group()
- else:
- print u'match21不是小数'
- if match22:
- # 使用Match获得分组信息
- print match22.group()
- else:
- print u'match22不是小数'
re提供了众多模块方法用于完成正则表达式的功能。
这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,
但同时也无法复用编译后的Pattern对象。
这些方法将在Pattern类的实例方法部分一起介绍。
如一开始的hello实例可以简写为:
- # -*- coding: utf-8 -*-
- #一个简单的re实例,匹配字符串中的hello字符串
- import re
- m = re.match(r'hello', 'hello world!')
- print m.group()
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 - groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 - groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 - start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 - end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 - span([group]):
返回(start(group), end(group))。 - expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g、\g 引用分组,但不能使用编号0。\id与\g 是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
- # -*- coding: utf-8 -*-
- #一个简单的match实例
- import re
- # 匹配如下内容:单词+空格+单词+任意字符
- m = re.match(r'(\w+) (\w+)(?P
.*)' , 'hello world!') - print "m.string:", m.string
- print "m.re:", m.re
- print "m.pos:", m.pos
- print "m.endpos:", m.endpos
- print "m.lastindex:", m.lastindex
- print "m.lastgroup:", m.lastgroup
- print "m.group():", m.group()
- print "m.group(1,2):", m.group(1, 2)
- print "m.groups():", m.groups()
- print "m.groupdict():", m.groupdict()
- print "m.start(2):", m.start(2)
- print "m.end(2):", m.end(2)
- print "m.span(2):", m.span(2)
- print r"m.expand(r'\g<2> \g<1>\g<3>'):", m.expand(r'\2 \1\3')
- ### output ###
- # m.string: hello world!
- # m.re: <_sre.SRE_Pattern object at 0x016E1A38>
- # m.pos: 0
- # m.endpos: 12
- # m.lastindex: 3
- # m.lastgroup: sign
- # m.group(1,2): ('hello', 'world')
- # m.groups(): ('hello', 'world', '!')
- # m.groupdict(): {'sign': '!'}
- # m.start(2): 6
- # m.end(2): 11
- # m.span(2): (6, 11)
- # m.expand(r'\2 \1\3'): world hello!
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造,也就是re.compile()返回的对象。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
- # -*- coding: utf-8 -*-
- #一个简单的pattern实例
- import re
- p = re.compile(r'(\w+) (\w+)(?P
.*)' , re.DOTALL) - print "p.pattern:", p.pattern
- print "p.flags:", p.flags
- print "p.groups:", p.groups
- print "p.groupindex:", p.groupindex
- ### output ###
- # p.pattern: (\w+) (\w+)(?P
.*) - # p.flags: 16
- # p.groups: 3
- # p.groupindex: {'sign': 3}
下面重点介绍一下pattern的实例方法及其使用。
1.match
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;
如果pattern结束时仍可匹配,则返回一个Match对象;
如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);
re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。
当pattern结束时若string还有剩余字符,仍然视为成功。
想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
下面来看一个Match的简单案例:
- # encoding: UTF-8
- import re
- # 将正则表达式编译成Pattern对象
- pattern = re.compile(r'hello')
- # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
- match = pattern.match('hello world!')
- if match:
- # 使用Match获得分组信息
- print match.group()
- ### 输出 ###
- # hello
2.search
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。
从string的pos下标处起尝试匹配pattern,
如果pattern结束时仍可匹配,则返回一个Match对象;
若无法匹配,则将pos加1后重新尝试匹配;
直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));
re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
那么它和match有什么区别呢?
match()函数只检测re是不是在string的开始位置匹配,
search()会扫描整个string查找匹配,
match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none
例如:
print(re.match(‘super’, ‘superstition’).span())
会返回(0, 5)
print(re.match(‘super’, ‘insuperable’))
则返回None
search()会扫描整个字符串并返回第一个成功的匹配
例如:
print(re.search(‘super’, ‘superstition’).span())
返回(0, 5)
print(re.search(‘super’, ‘insuperable’).span())
返回(2, 7)
看一个search的实例:
- # -*- coding: utf-8 -*-
- #一个简单的search实例
- import re
- # 将正则表达式编译成Pattern对象
- pattern = re.compile(r'world')
- # 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
- # 这个例子中使用match()无法成功匹配
- match = pattern.search('hello world!')
- if match:
- # 使用Match获得分组信息
- print match.group()
- ### 输出 ###
- # world
3.split
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。
maxsplit用于指定最大分割次数,不指定将全部分割。
- import re
- p = re.compile(r'\d+')
- print p.split('one1two2three3four4')
- ### output ###
- # ['one', 'two', 'three', 'four', '']
4.findall
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。
- import re
- p = re.compile(r'\d+')
- print p.findall('one1two2three3four4')
- ### output ###
- # ['1', '2', '3', '4']
5.finditer
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
- import re
- p = re.compile(r'\d+')
- for m in p.finditer('one1two2three3four4'):
- print m.group(),
- ### output ###
- # 1 2 3 4
6.sub
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
- import re
- p = re.compile(r'(\w+) (\w+)')
- s = 'i say, hello world!'
- print p.sub(r'\2 \1', s)
- def func(m):
- return m.group(1).title() + ' ' + m.group(2).title()
- print p.sub(func, s)
- ### output ###
- # say i, world hello!
- # I Say, Hello World!
7.subn
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。
- import re
- p = re.compile(r'(\w+) (\w+)')
- s = 'i say, hello world!'
- print p.subn(r'\2 \1', s)
- def func(m):
- return m.group(1).title() + ' ' + m.group(2).title()
- print p.subn(func, s)
- ### output ###
- # ('say i, world hello!', 2)
- # ('I Say, Hello World!', 2)
至此,Python的正则表达式基本介绍就算是完成了^_^
[Python]网络爬虫(八):糗事百科的网络爬虫(v0.3)源码及解析(简化更新)
Q&A:
1.为什么有段时间显示糗事百科不可用?
答:前段时间因为糗事百科添加了Header的检验,导致无法爬取,需要在代码中模拟Header。现在代码已经作了修改,可以正常使用。
2.为什么需要单独新建个线程?
答:基本流程是这样的:爬虫在后台新起一个线程,一直爬取两页的糗事百科,如果剩余不足两页,则再爬一页。用户按下回车只是从库存中获取最新的内容,而不是上网获取,所以浏览更顺畅。也可以把加载放在主线程,不过这样会导致爬取过程中等待时间过长的问题。
项目内容:
用Python写的糗事百科的网络爬虫。
使用方法:
新建一个Bug.py文件,然后将代码复制到里面后,双击运行。
程序功能:
在命令提示行中浏览糗事百科。
原理解释:
首先,先浏览一下糗事百科的主页:http://www.qiushibaike.com/hot/page/1
可以看出来,链接中page/后面的数字就是对应的页码,记住这一点为以后的编写做准备。
然后,右击查看页面源码:

观察发现,每一个段子都用div标记,其中class必为content,title是发帖时间,我们只需要用正则表达式将其“扣”出来就可以了。
明白了原理之后,剩下的就是正则表达式的内容了,可以参照这篇博文:
http://blog.csdn.net/wxg694175346/article/details/8929576
运行效果:

-
- import urllib2
- import urllib
- import re
- import thread
- import time
- #----------- 加载处理糗事百科 -----------
- class Spider_Model:
- def __init__(self):
- self.page = 1
- self.pages = []
- self.enable = False
- # 将所有的段子都扣出来,添加到列表中并且返回列表
- def GetPage(self,page):
- myUrl = "http://m.qiushibaike.com/hot/page/" + page
- user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
- headers = { 'User-Agent' : user_agent }
- req = urllib2.Request(myUrl, headers = headers)
- myResponse = urllib2.urlopen(req)
- myPage = myResponse.read()
- #encode的作用是将unicode编码转换成其他编码的字符串
- #decode的作用是将其他编码的字符串转换成unicode编码
- unicodePage = myPage.decode("utf-8")
- # 找出所有class="content"的div标记
- #re.S是任意匹配模式,也就是.可以匹配换行符
- myItems = re.findall('
[Python]网络爬虫(九):百度贴吧的网络爬虫(v0.4)源码及解析
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件。
源码下载:
http://download.csdn.net/detail/wxg694175346/6925583
用Python写的百度贴吧的网络爬虫。
使用方法:
新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行。
程序功能:
将贴吧中楼主发布的内容打包txt存储到本地。
原理解释:
首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了:
http://tieba.baidu.com/p/2296712428?see_lz=1&pn=1
可以看出来,see_lz=1是只看楼主,pn=1是对应的页码,记住这一点为以后的编写做准备。
这就是我们需要利用的url。接下来就是查看页面源码。
首先把题目抠出来存储文件的时候会用到。
可以看到百度使用gbk编码,标题使用h1标记:
- <h1 class="core_title_txt" title="【原创】时尚首席(关于时尚,名利,事业,爱情,励志)">【原创】时尚首席(关于时尚,名利,事业,爱情,励志)h1>
同样,正文部分用div和class综合标记,接下来要做的只是用正则表达式来匹配即可。
运行截图:

生成的txt文件:

- # -*- coding: utf-8 -*-
- #---------------------------------------
- # 程序:百度贴吧爬虫
- # 版本:0.5
- # 作者:why
- # 日期:2013-05-16
- # 语言:Python 2.7
- # 操作:输入网址后自动只看楼主并保存到本地文件
- # 功能:将楼主发布的内容打包txt存储到本地。
- #---------------------------------------
- import string
- import urllib2
- import re
- #----------- 处理页面上的各种标签 -----------
- class HTML_Tool:
- # 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
- BgnCharToNoneRex = re.compile("(\t|\n| |
- # 用非 贪婪模式 匹配 任意<>标签
- EndCharToNoneRex = re.compile("<.*?>")
- # 用非 贪婪模式 匹配 任意
标签
- BgnPartRex = re.compile("
- CharToNewLineRex = re.compile("(
||| |)")- CharToNextTabRex = re.compile("
") - # 将一些html的符号实体转变为原始符号
- replaceTab = [("<","<"),(">",">"),("&","&"),("&","\""),(" "," ")]
- def Replace_Char(self,x):
- x = self.BgnCharToNoneRex.sub("",x)
- x = self.BgnPartRex.sub("\n ",x)
- x = self.CharToNewLineRex.sub("\n",x)
- x = self.CharToNextTabRex.sub("\t",x)
- x = self.EndCharToNoneRex.sub("",x)
- for t in self.replaceTab:
- x = x.replace(t[0],t[1])
- return x
- class Baidu_Spider:
- # 申明相关的属性
- def __init__(self,url):
- self.myUrl = url + '?see_lz=1'
- self.datas = []
- self.myTool = HTML_Tool()
- print u'已经启动百度贴吧爬虫,咔嚓咔嚓'
- # 初始化加载页面并将其转码储存
- def baidu_tieba(self):
- # 读取页面的原始信息并将其从gbk转码
- myPage = urllib2.urlopen(self.myUrl).read().decode("gbk")
- # 计算楼主发布内容一共有多少页
- endPage = self.page_counter(myPage)
- # 获取该帖的标题
- title = self.find_title(myPage)
- print u'文章名称:' + title
- # 获取最终的数据
- self.save_data(self.myUrl,title,endPage)
- #用来计算一共有多少页
- def page_counter(self,myPage):
- # 匹配 "共有
- myMatch = re.search(r'class="red">(\d+?)', myPage, re.S)
- if myMatch:
- endPage = int(myMatch.group(1))
- print u'爬虫报告:发现楼主共有%d页的原创内容' % endPage
- else:
- endPage = 0
- print u'爬虫报告:无法计算楼主发布内容有多少页!'
- return endPage
- # 用来寻找该帖的标题
- def find_title(self,myPage):
- # 匹配
- myMatch = re.search(r'
- title = u'暂无标题'
- if myMatch:
- title = myMatch.group(1)
- else:
- print u'爬虫报告:无法加载文章标题!'
- # 文件名不能包含以下字符: \ / : * ? " < > |
- title = title.replace('\\','').replace('/','').replace(':','').replace('*','').replace('?','').replace('"','').replace('>','').replace('<','').replace('|','')
- return title
- # 用来存储楼主发布的内容
- def save_data(self,url,title,endPage):
- # 加载页面数据到数组中
- self.get_data(url,endPage)
- # 打开本地文件
- f = open(title+'.txt','w+')
- f.writelines(self.datas)
- f.close()
- print u'爬虫报告:文件已下载到本地并打包成txt文件'
- print u'请按任意键退出...'
- raw_input();
- # 获取页面源码并将其存储到数组中
- def get_data(self,url,endPage):
- url = url + '&pn='
- for i in range(1,endPage+1):
- print u'爬虫报告:爬虫%d号正在加载中...' % i
- myPage = urllib2.urlopen(url + str(i)).read()
- # 将myPage中的html代码处理并存储到datas里面
- self.deal_data(myPage.decode('gbk'))
- # 将内容从页面代码中抠出来
- def deal_data(self,myPage):
- myItems = re.findall('id="post_content.*?>(.*?)',myPage,re.S)
- for item in myItems:
- data = self.myTool.Replace_Char(item.replace("\n","").encode('gbk'))
- self.datas.append(data+'\n')
- #-------- 程序入口处 ------------------
- print u"""#---------------------------------------
- # 程序:百度贴吧爬虫
- # 版本:0.5
- # 作者:why
- # 日期:2013-05-16
- # 语言:Python 2.7
- # 操作:输入网址后自动只看楼主并保存到本地文件
- # 功能:将楼主发布的内容打包txt存储到本地。
- #---------------------------------------
- """
- # 以某小说贴吧为例子
- # bdurl = 'http://tieba.baidu.com/p/2296712428?see_lz=1&pn=1'
- print u'请输入贴吧的地址最后的数字串:'
- bdurl = 'http://tieba.baidu.com/p/' + str(raw_input(u'http://tieba.baidu.com/p/'))
- #调用
- mySpider = Baidu_Spider(bdurl)
- mySpider.baidu_tieba()
[Python]网络爬虫(十):一个爬虫的诞生全过程(以山东大学绩点运算为例)
先来说一下我们学校的网站:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
查询成绩需要登录,然后显示各学科成绩,但是只显示成绩而没有绩点,也就是加权平均分。
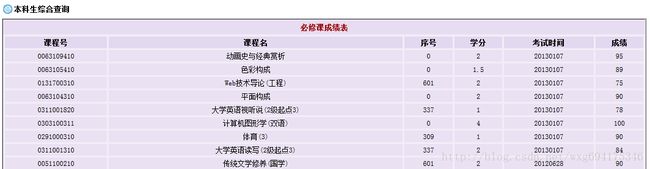
显然这样手动计算绩点是一件非常麻烦的事情。所以我们可以用python做一个爬虫来解决这个问题。
1.决战前夜
先来准备一下工具:HttpFox插件。
这是一款http协议分析插件,分析页面请求和响应的时间、内容、以及浏览器用到的COOKIE等。
以我为例,安装在火狐上即可,效果如图:
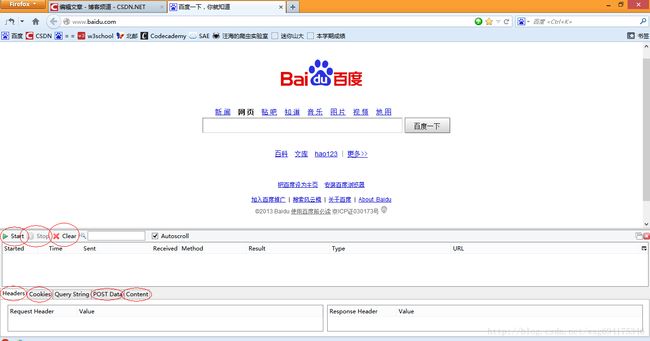
可以非常直观的查看相应的信息。
点击start是开始检测,点击stop暂停检测,点击clear清除内容。
一般在使用之前,点击stop暂停,然后点击clear清屏,确保看到的是访问当前页面获得的数据。
2.深入敌后
下面就去山东大学的成绩查询网站,看一看在登录的时候,到底发送了那些信息。
先来到登录页面,把httpfox打开,clear之后,点击start开启检测: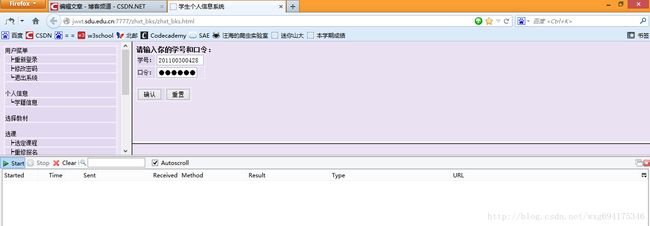
输入完了个人信息,确保httpfox处于开启状态,然后点击确定提交信息,实现登录。
这个时候可以看到,httpfox检测到了三条信息:
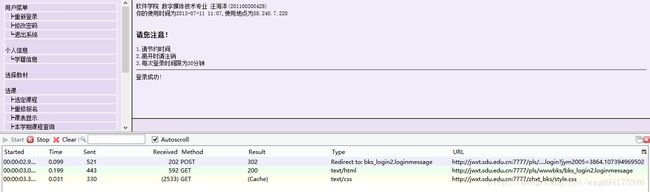
这时点击stop键,确保捕获到的是访问该页面之后反馈的数据,以便我们做爬虫的时候模拟登陆使用。
3.庖丁解牛
乍一看我们拿到了三个数据,两个是GET的一个是POST的,但是它们到底是什么,应该怎么用,我们还一无所知。
所以,我们需要挨个查看一下捕获到的内容。
先看POST的信息:
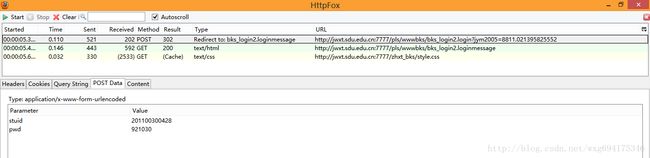
既然是POST的信息,我们就直接看PostData即可。
可以看到一共POST两个数据,stuid和pwd。
并且从Type的Redirect to可以看出,POST完毕之后跳转到了bks_login2.loginmessage页面。
由此看出,这个数据是点击确定之后提交的表单数据。
点击cookie标签,看看cookie信息:
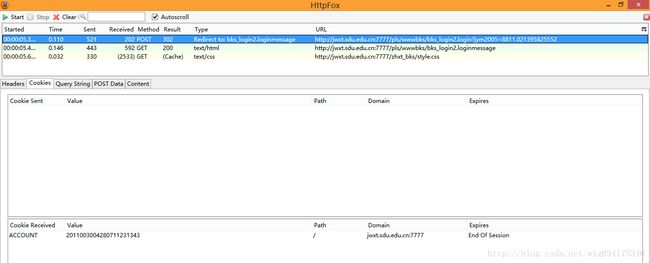
没错,收到了一个ACCOUNT的cookie,并且在session结束之后自动销毁。
那么提交之后收到了哪些信息呢?
我们来看看后面的两个GET数据。
先看第一个,我们点击content标签可以查看收到的内容,是不是有一种生吞活剥的快感-。-HTML源码暴露无疑了:
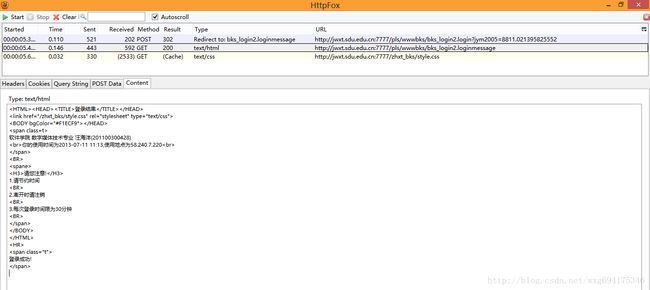
看来这个只是显示页面的html源码而已,点击cookie,查看cookie的相关信息:
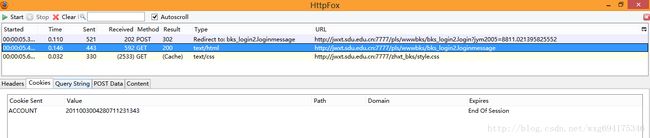
啊哈,原来html页面的内容是发送了cookie信息之后才接受到的。
再来看看最后一个接收到的信息:
大致看了一下应该只是一个叫做style.css的css文件,对我们没有太大的作用。
4.冷静应战
既然已经知道了我们向服务器发送了什么数据,也知道了我们接收到了什么数据,基本的流程如下:
- 首先,我们POST学号和密码--->然后返回cookie的值
- 然后发送cookie给服务器--->返回页面信息。
- 获取到成绩页面的数据,用正则表达式将成绩和学分单独取出并计算加权平均数。
OK,看上去好像很简单的样纸。那下面我们就来试试看吧。
但是在实验之前,还有一个问题没有解决,就是POST的数据到底发送到了哪里?
再来看一下当初的页面:

很明显是用一个html框架来实现的,也就是说,我们在地址栏看到的地址并不是右边提交表单的地址。
那么怎样才能获得真正的地址-。-右击查看页面源代码:
嗯没错,那个name="w_right"的就是我们要的登录页面。
网站的原来的地址是:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
所以,真正的表单提交的地址应该是:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/xk_login.html
输入一看,果不其然:
靠居然是清华大学的选课系统。。。目测是我校懒得做页面了就直接借了。。结果连标题都不改一下。。。
但是这个页面依旧不是我们需要的页面,因为我们的POST数据提交到的页面,应该是表单form的ACTION中提交到的页面。
也就是说,我们需要查看源码,来知道POST数据到底发送到了哪里:
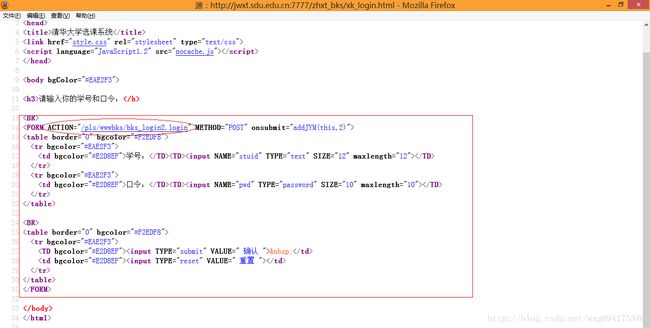
嗯,目测这个才是提交POST数据的地址。
整理到地址栏中,完整的地址应该如下:
http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login
(获取的方式很简单,在火狐浏览器中直接点击那个链接就能看到这个链接的地址了)
5.小试牛刀
接下来的任务就是:用python模拟发送一个POST的数据并取到返回的cookie值。
关于cookie的操作可以看看这篇博文:http://blog.csdn.net/wxg694175346/article/details/8925978
我们先准备一个POST的数据,再准备一个cookie的接收,然后写出源码如下:
- # -*- coding: utf-8 -*-
- #---------------------------------------
- # 程序:山东大学爬虫
- # 版本:0.1
- # 作者:why
- # 日期:2013-07-12
- # 语言:Python 2.7
- # 操作:输入学号和密码
- # 功能:输出成绩的加权平均值也就是绩点
- #---------------------------------------
- import urllib
- import urllib2
- import cookielib
- cookie = cookielib.CookieJar()
- opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
- #需要POST的数据#
- postdata=urllib.urlencode({
- 'stuid':'201100300428',
- 'pwd':'921030'
- })
- #自定义一个请求#
- req = urllib2.Request(
- url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
- data = postdata
- )
- #访问该链接#
- result = opener.open(req)
- #打印返回的内容#
- print result.read()
如此这般之后,再看看运行的效果:
ok,如此这般,我们就算模拟登陆成功了。
6.偷天换日
接下来的任务就是用爬虫获取到学生的成绩。
再来看看源网站。
开启HTTPFOX之后,点击查看成绩,发现捕获到了如下的数据:
点击第一个GET的数据,查看内容可以发现Content就是获取到的成绩的内容。
而获取到的页面链接,从页面源代码中右击查看元素,可以看到点击链接之后跳转的页面(火狐浏览器只需要右击,“查看此框架”,即可):
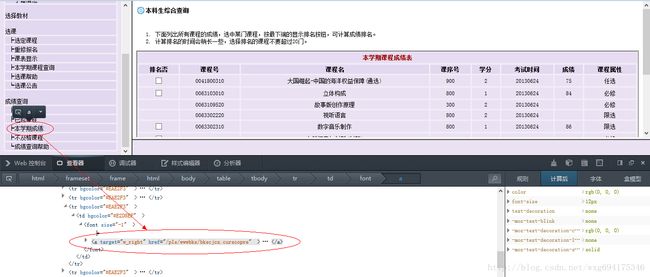
从而可以得到查看成绩的链接如下:
http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre
7.万事俱备
现在万事俱备啦,所以只需要把链接应用到爬虫里面,看看能否查看到成绩的页面。
从httpfox可以看到,我们发送了一个cookie才能返回成绩的信息,所以我们就用python模拟一个cookie的发送,以此来请求成绩的信息:
- # -*- coding: utf-8 -*-
- #---------------------------------------
- # 程序:山东大学爬虫
- # 版本:0.1
- # 作者:why
- # 日期:2013-07-12
- # 语言:Python 2.7
- # 操作:输入学号和密码
- # 功能:输出成绩的加权平均值也就是绩点
- #---------------------------------------
- import urllib
- import urllib2
- import cookielib
- #初始化一个CookieJar来处理Cookie的信息#
- cookie = cookielib.CookieJar()
- #创建一个新的opener来使用我们的CookieJar#
- opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
- #需要POST的数据#
- postdata=urllib.urlencode({
- 'stuid':'201100300428',
- 'pwd':'921030'
- })
- #自定义一个请求#
- req = urllib2.Request(
- url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
- data = postdata
- )
- #访问该链接#
- result = opener.open(req)
- #打印返回的内容#
- print result.read()
- #打印cookie的值
- for item in cookie:
- print 'Cookie:Name = '+item.name
- print 'Cookie:Value = '+item.value
- #访问该链接#
- result = opener.open('http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre')
- #打印返回的内容#
- print result.read()
按下F5运行即可,看看捕获到的数据吧:
既然这样就没有什么问题了吧,用正则表达式将数据稍稍处理一下,取出学分和相应的分数就可以了。
8.手到擒来
这么一大堆html源码显然是不利于我们处理的,下面要用正则表达式来抠出必须的数据。
关于正则表达式的教程可以看看这个博文:
http://blog.csdn.net/wxg694175346/article/details/8929576
我们来看看成绩的源码:
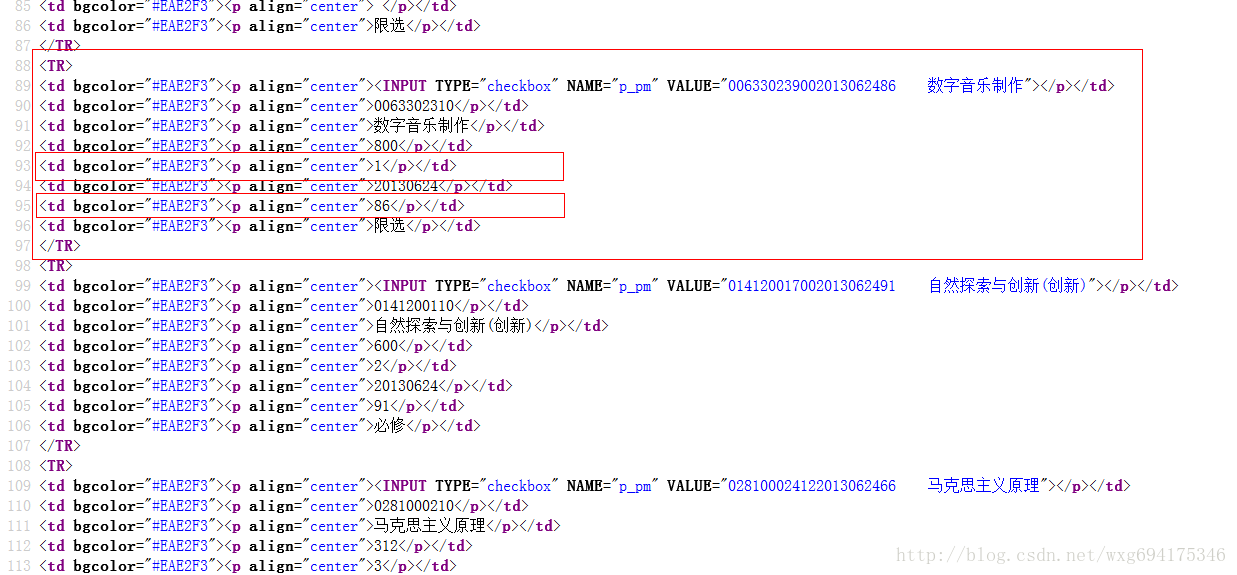
既然如此,用正则表达式就易如反掌了。
我们将代码稍稍整理一下,然后用正则来取出数据:
- # -*- coding: utf-8 -*-
- #---------------------------------------
- # 程序:山东大学爬虫
- # 版本:0.1
- # 作者:why
- # 日期:2013-07-12
- # 语言:Python 2.7
- # 操作:输入学号和密码
- # 功能:输出成绩的加权平均值也就是绩点
- #---------------------------------------
- import urllib
- import urllib2
- import cookielib
- import re
- class SDU_Spider:
- # 申明相关的属性
- def __init__(self):
- self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
- self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
- self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
- self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
- self.weights = [] #存储权重,也就是学分
- self.points = [] #存储分数,也就是成绩
- self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
- def sdu_init(self):
- # 初始化链接并且获取cookie
- myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
- result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
- result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
- # 打印返回的内容
- # print result.read()
- self.deal_data(result.read().decode('gbk'))
- self.print_data(self.weights);
- self.print_data(self.points);
- # 将内容从页面代码中抠出来
- def deal_data(self,myPage):
- myItems = re.findall('
.*? ',myPage,re.S) #获取到学分 - for item in myItems:
- self.weights.append(item[0].encode('gbk'))
- self.points.append(item[1].encode('gbk'))
- # 将内容从页面代码中抠出来
- def print_data(self,items):
- for item in items:
- print item
- #调用
- mySpider = SDU_Spider()
- mySpider.sdu_init()
水平有限,,正则是有点丑,。运行的效果如图: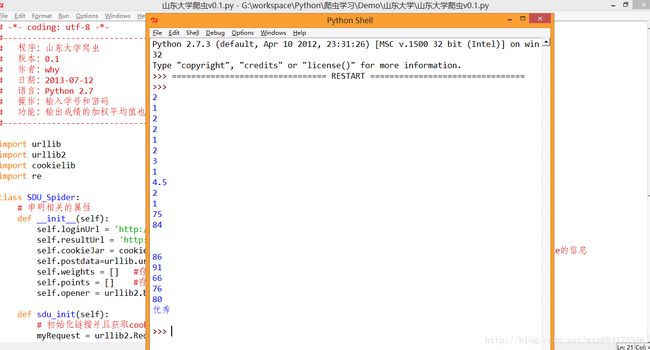
ok,接下来的只是数据的处理问题了。。
9.凯旋而归
完整的代码如下,至此一个完整的爬虫项目便完工了。
- # -*- coding: utf-8 -*-
- #---------------------------------------
- # 程序:山东大学爬虫
- # 版本:0.1
- # 作者:why
- # 日期:2013-07-12
- # 语言:Python 2.7
- # 操作:输入学号和密码
- # 功能:输出成绩的加权平均值也就是绩点
- #---------------------------------------
- import urllib
- import urllib2
- import cookielib
- import re
- import string
- class SDU_Spider:
- # 申明相关的属性
- def __init__(self):
- self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
- self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
- self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
- self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
- self.weights = [] #存储权重,也就是学分
- self.points = [] #存储分数,也就是成绩
- self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
- def sdu_init(self):
- # 初始化链接并且获取cookie
- myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
- result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
- result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
- # 打印返回的内容
- # print result.read()
- self.deal_data(result.read().decode('gbk'))
- self.calculate_date();
- # 将内容从页面代码中抠出来
- def deal_data(self,myPage):
- myItems = re.findall('
.*? ',myPage,re.S) #获取到学分 - for item in myItems:
- self.weights.append(item[0].encode('gbk'))
- self.points.append(item[1].encode('gbk'))
- #计算绩点,如果成绩还没出来,或者成绩是优秀良好,就不运算该成绩
- def calculate_date(self):
- point = 0.0
- weight = 0.0
- for i in range(len(self.points)):
- if(self.points[i].isdigit()):
- point += string.atof(self.points[i])*string.atof(self.weights[i])
- weight += string.atof(self.weights[i])
- print point/weight
- #调用
- mySpider = SDU_Spider()
- mySpider.sdu_init()
[Python]网络爬虫(11):亮剑!爬虫框架小抓抓Scrapy闪亮登场!
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识,
用来解决简单的贴吧下载,绩点运算自然不在话下。
不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点。
于是乎,爬虫框架Scrapy就这样出场了!
Scrapy = Scrach+Python,Scrach这个单词是抓取的意思,
暂且可以叫它:小抓抓吧。
小抓抓的官网地址:点我点我。
那么下面来简单的演示一下小抓抓Scrapy的安装流程。
具体流程参照:官网教程
友情提醒:一定要按照Python的版本下载,要不然安装的时候会提醒找不到Python。建议大家安装32位是因为有些版本的必备软件64位不好找。
1.安装Python(建议32位)
建议安装Python2.7.x,3.x貌似还不支持。
安装完了记得配置环境,将python目录和python目录下的Scripts目录添加到系统环境变量的Path里。
在cmd中输入python如果出现版本信息说明配置完毕。
2.安装lxml
lxml是一种使用 Python 编写的库,可以迅速、灵活地处理 XML。点击这里选择对应的Python版本安装。
3.安装setuptools
用来安装egg文件,点击这里下载python2.7的对应版本的setuptools。
4.安装zope.interface
可以使用第三步下载的setuptools来安装egg文件,现在也有exe版本,点击这里下载。
5.安装Twisted
Twisted是用Python实现的基于事件驱动的网络引擎框架,点击这里下载。
6.安装pyOpenSSL
pyOpenSSL是Python的OpenSSL接口,点击这里下载。
7.安装win32py
提供win32api,点击这里下载
8.安装Scrapy
终于到了激动人心的时候了!安装了那么多小部件之后终于轮到主角登场。
直接在cmd中输入easy_install scrapy回车即可。
9.检查安装
打开一个cmd窗口,在任意位置执行scrapy命令,得到下列页面,表示环境配置成功。

[Python]网络爬虫(12):爬虫框架Scrapy的第一个爬虫示例入门教程
(建议大家多看看官网教程:教程地址)
我们使用dmoz.org这个网站来作为小抓抓一展身手的对象。
首先先要回答一个问题。
问:把网站装进爬虫里,总共分几步?
答案很简单,四步:
- 新建项目 (Project):新建一个新的爬虫项目
- 明确目标(Items):明确你想要抓取的目标
- 制作爬虫(Spider):制作爬虫开始爬取网页
- 存储内容(Pipeline):设计管道存储爬取内容
好的,基本流程既然确定了,那接下来就一步一步的完成就可以了。
1.新建项目(Project)
在空目录下按住Shift键右击,选择“在此处打开命令窗口”,输入一下命令:
- scrapy startproject tutorial
其中,tutorial为项目名称。可以看到将会创建一个tutorial文件夹,目录结构如下:
- tutorial/
- scrapy.cfg
- tutorial/
- __init__.py
- items.py
- pipelines.py
- settings.py
- spiders/
- __init__.py
- ...
下面来简单介绍一下各个文件的作用:
- scrapy.cfg:项目的配置文件
- tutorial/:项目的Python模块,将会从这里引用代码
- tutorial/items.py:项目的items文件
- tutorial/pipelines.py:项目的pipelines文件
- tutorial/settings.py:项目的设置文件
- tutorial/spiders/:存储爬虫的目录
2.明确目标(Item)
在Scrapy中,items是用来加载抓取内容的容器,有点像Python中的Dic,也就是字典,但是提供了一些额外的保护减少错误。
一般来说,item可以用scrapy.item.Item类来创建,并且用scrapy.item.Field对象来定义属性(可以理解成类似于ORM的映射关系)。
接下来,我们开始来构建item模型(model)。
首先,我们想要的内容有:
- 名称(name)
- 链接(url)
- 描述(description)
修改tutorial目录下的items.py文件,在原本的class后面添加我们自己的class。
因为要抓dmoz.org网站的内容,所以我们可以将其命名为DmozItem:
- # Define here the models for your scraped items
- #
- # See documentation in:
- # http://doc.scrapy.org/en/latest/topics/items.html
- from scrapy.item import Item, Field
- class TutorialItem(Item):
- # define the fields for your item here like:
- # name = Field()
- pass
- class DmozItem(Item):
- title = Field()
- link = Field()
- desc = Field()
刚开始看起来可能会有些看不懂,但是定义这些item能让你用其他组件的时候知道你的 items到底是什么。
可以把Item简单的理解成封装好的类对象。
3.制作爬虫(Spider)
制作爬虫,总体分两步:先爬再取。
也就是说,首先你要获取整个网页的所有内容,然后再取出其中对你有用的部分。
3.1爬
Spider是用户自己编写的类,用来从一个域(或域组)中抓取信息。
他们定义了用于下载的URL列表、跟踪链接的方案、解析网页内容的方式,以此来提取items。
要建立一个Spider,你必须用scrapy.spider.BaseSpider创建一个子类,并确定三个强制的属性:
- name:爬虫的识别名称,必须是唯一的,在不同的爬虫中你必须定义不同的名字。
- start_urls:爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
- parse():解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL。
这里可以参考宽度爬虫教程中提及的思想来帮助理解,教程传送:[Java] 知乎下巴第5集:使用HttpClient工具包和宽度爬虫。
也就是把Url存储下来并依此为起点逐步扩散开去,抓取所有符合条件的网页Url存储起来继续爬取。
下面我们来写第一只爬虫,命名为dmoz_spider.py,保存在tutorial\spiders目录下。
dmoz_spider.py代码如下:
allow_domains是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页。- from scrapy.spider import Spider
- class DmozSpider(Spider):
- name = "dmoz"
- allowed_domains = ["dmoz.org"]
- start_urls = [
- "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
- "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
- ]
- def parse(self, response):
- filename = response.url.split("/")[-2]
- open(filename, 'wb').write(response.body)
从parse函数可以看出,将链接的最后两个地址取出作为文件名进行存储。
然后运行一下看看,在tutorial目录下按住shift右击,在此处打开命令窗口,输入:
- scrapy crawl dmoz
运行结果如图: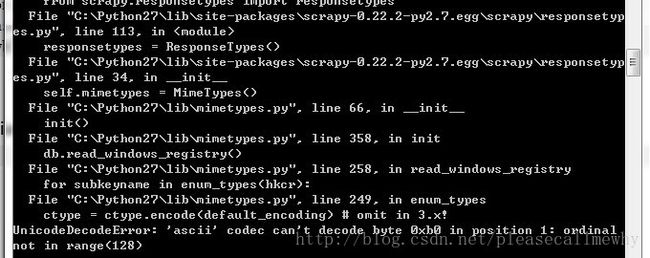
报错了:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xb0 in position 1: ordinal not in range(128)
运行第一个Scrapy项目就报错,真是命运多舛。
应该是出了编码问题,谷歌了一下找到了解决方案:
在python的Lib\site-packages文件夹下新建一个sitecustomize.py:
- import sys
- sys.setdefaultencoding('gb2312')
再次运行,OK,问题解决了,看一下结果:
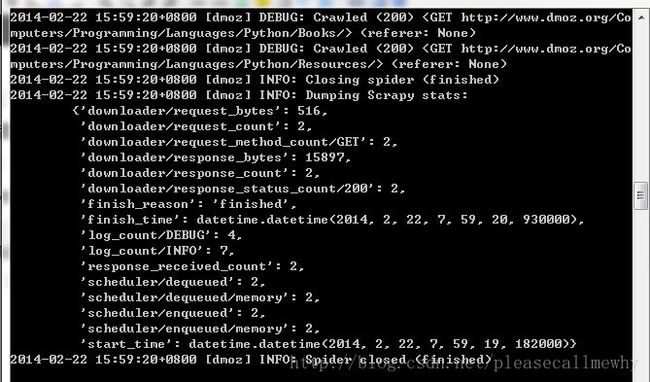
最后一句INFO: Closing spider (finished)表明爬虫已经成功运行并且自行关闭了。
包含 [dmoz]的行 ,那对应着我们的爬虫运行的结果。
可以看到start_urls中定义的每个URL都有日志行。
还记得我们的start_urls吗?
http://www.dmoz.org/Computers/Programming/Languages/Python/Books
http://www.dmoz.org/Computers/Programming/Languages/Python/Resources因为这些URL是起始页面,所以他们没有引用(referrers),所以在它们的每行末尾你会看到 (referer:
)。 在parse 方法的作用下,两个文件被创建:分别是 Books 和 Resources,这两个文件中有URL的页面内容。
那么在刚刚的电闪雷鸣之中到底发生了什么呢?
首先,Scrapy为爬虫的 start_urls属性中的每个URL创建了一个 scrapy.http.Request 对象 ,并将爬虫的parse 方法指定为回调函数。
然后,这些 Request被调度并执行,之后通过parse()方法返回scrapy.http.Response对象,并反馈给爬虫。
3.2取
爬取整个网页完毕,接下来的就是的取过程了。
光存储一整个网页还是不够用的。
在基础的爬虫里,这一步可以用正则表达式来抓。
在Scrapy里,使用一种叫做 XPath selectors的机制,它基于 XPath表达式。
如果你想了解更多selectors和其他机制你可以查阅资料:点我点我
这是一些XPath表达式的例子和他们的含义
- /html/head/title: 选择HTML文档元素下面的
标签。</span></li> <li><span style="font-family:'Microsoft YaHei'; font-size:18px">/html/head/title/text(): 选择前面提到的<title> 元素下面的文本内容</span></li> <li><span style="font-family:'Microsoft YaHei'; font-size:18px">//td: 选择所有 <td> 元素</span></li> <li><span style="font-family:'Microsoft YaHei'; font-size:18px">//div[@class="mine"]: 选择所有包含 class="mine" 属性的div 标签元素</span></li> </ul> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">以上只是几个使用XPath的简单例子,但是实际上XPath非常强大。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">可以参照W3C教程:点我点我。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px"><br> </span></p> <span style="line-height:26px; font-family:'Microsoft YaHei'; font-size:18px">为了方便使用XPaths,Scrapy提供XPathSelector 类,有两种可以选择,HtmlXPathSelector(HTML数据解析)和XmlXPathSelector(XML数据解析)。<br> </span> <span style="font-family:Arial; font-size:14px; line-height:26px"></span> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">必须通过一个 Response 对象对他们进行实例化操作。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">你会发现Selector对象展示了文档的节点结构。因此,第一个实例化的selector必与根节点或者是整个目录有关 。<br> </span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">在Scrapy里面,Selectors 有四种基础的方法</span><span style="font-family:'Microsoft YaHei'; font-size:18px"><span class="reference internal"><span class="xref py py-meth docutils literal"><span class="pre">(点击查看API文档):</span></span></span><span class="xref py py-meth docutils literal"><span class="pre"><br> </span></span></span></p> <ul style="font-family:Arial; font-size:14px; line-height:26px"> <li><span style="font-family:'Microsoft YaHei'; font-size:18px"><span class="xref py py-meth docutils literal"><span class="pre">xpath()</span></span>:返回一系列的selectors,每一个select表示一个xpath参数表达式选择的节点<span class="xref py py-meth docutils literal"><span class="pre"><br> </span></span></span></li> <li><span style="font-family:'Microsoft YaHei'; font-size:18px"><span class="xref py py-meth docutils literal"><span class="pre">css()</span></span>:返回一系列的selectors,每一个select表示一个css参数表达式选择的节点<span class="xref py py-meth docutils literal"><span class="pre"><br> </span></span></span></li> <li><span style="font-family:'Microsoft YaHei'; font-size:18px"><span class="xref py py-meth docutils literal"><span class="pre">extract()</span></span>:返回一个unicode字符串,为选中的数据<span class="xref py py-meth docutils literal"><span class="pre"><br> </span></span></span></li> <li><span style="font-family:'Microsoft YaHei'; font-size:18px"><span class="xref py py-meth docutils literal"><span class="pre">re()</span></span>:返回一串一个unicode字符串,为使用正则表达式抓取出来的内容</span></li> </ul> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <br> </p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px"><strong>3.3xpath实验</strong><br> </span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">下面我们在Shell里面尝试一下Selector的用法。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">实验的网址:http://www.dmoz.org/Computers/Programming/Languages/Python/Books/<br> </span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px"><a href="http://img.e-com-net.com/image/info8/232baabb95584158ac4f57c881d67279.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/232baabb95584158ac4f57c881d67279.jpg" alt="Python之网络爬虫完全教程_第34张图片" style="border:none; max-width:100%;border:1px solid black;" width="650" height="293"></a><br> </span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px"><br> </span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">熟悉完了实验的小白鼠,接下来就是用Shell爬取网页了。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">进入到项目的顶层目录,也就是第一层tutorial文件夹下,在cmd中输入:</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px"></span></p> <div class="dp-highlighter bg_plain" style="font-family:Consolas,'Courier New',Courier,mono,serif; width:936.53125px; overflow:auto; padding-top:1px; line-height:26px; margin:18px 0px!important; background-color:rgb(231,229,220)"> <div class="bar" style="padding-left:45px"> <div class="tools" style="padding:3px 8px 10px 10px; font-size:9px; line-height:normal; font-family:Verdana,Geneva,Arial,Helvetica,sans-serif; color:silver; border-left-width:3px; border-left-style:solid; border-left-color:rgb(108,226,108); background-color:rgb(248,248,248)"> <strong>[plain]</strong> view plain copy <div style="position:absolute; left:441px; top:6184px; width:18px; height:18px; z-index:99"> </div> </div> </div> <ol start="1" style="padding:0px; border:none; list-style-position:initial; color:rgb(92,92,92); margin:0px 0px 1px 45px!important; background-color:rgb(255,255,255)"> <li class="alt" style="border-style:none none none solid; border-left-width:3px; border-left-color:rgb(108,226,108); list-style:decimal-leading-zero outside; color:inherit; line-height:18px; margin:0px!important; padding:0px 3px 0px 10px!important"> <span style="margin:0px; padding:0px; border:none; color:black; background-color:inherit"><span style="margin:0px; padding:0px; border:none; background-color:inherit">scrapy shell http://www.dmoz.org/Computers/Programming/Languages/Python/Books/ </span></span></li> </ol> </div> <br style="font-family:Arial; font-size:14px; line-height:26px"> <span style="line-height:26px; font-family:'Microsoft YaHei'; font-size:18px">回车后可以看到如下的内容:</span> <span style="font-family:Arial; font-size:14px; line-height:26px"></span> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> </p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px"><a href="http://img.e-com-net.com/image/info8/2b517a785a264ec891984ca0864cff99.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/2b517a785a264ec891984ca0864cff99.png" alt="Python之网络爬虫完全教程_第35张图片" style="border:none; max-width:100%;border:1px solid black;" width="677" height="443"></a></span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px"></span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <br> </p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">在Shell载入后,你将获得response回应,存储在本地变量 response中。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">所以如果你输入response.body,你将会看到response的body部分,也就是抓取到的页面内容:</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <a href="http://img.e-com-net.com/image/info8/ba70f9937be147008d0e8b7a8411a428.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/ba70f9937be147008d0e8b7a8411a428.png" alt="Python之网络爬虫完全教程_第36张图片" style="border:none; max-width:100%;border:1px solid black;" width="677" height="443"></a><br> </p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">或者输入response.headers 来查看它的 header部分:</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <a href="http://img.e-com-net.com/image/info8/243c9a40ecb34544af37d072a52b2bd0.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/243c9a40ecb34544af37d072a52b2bd0.png" alt="Python之网络爬虫完全教程_第37张图片" style="border:none; max-width:100%;border:1px solid black;" width="677" height="443"></a><br> </p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <br> </p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">现在就像是一大堆沙子握在手里,里面藏着我们想要的金子,所以下一步,就是用筛子摇两下,把杂质出去,选出关键的内容。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">selector就是这样一个筛子。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">在旧的版本中,Shell实例化两种selectors,一个是解析HTML的 hxs 变量,一个是解析XML 的 xxs 变量。</span><span style="font-family:'Microsoft YaHei'; font-size:18px"><br> </span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">而现在的Shell为我们准备好的selector对象,sel,可以根据返回的数据类型自动选择最佳的解析方案(XML or HTML)。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">然后我们来捣弄一下!~</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">要彻底搞清楚这个问题,首先先要知道,抓到的页面到底是个什么样子。</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">比如,我们要抓取网页的标题,也就是<title>这个标签:</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <a href="http://img.e-com-net.com/image/info8/b54b50ad98984990a58afcb2369cbe93.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/b54b50ad98984990a58afcb2369cbe93.png" alt="" style="border:none; max-width:100%" width="465" height="71"></a><br> </p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> <span style="font-family:'Microsoft YaHei'; font-size:18px">可以输入:</span></p> <p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; font-family:Arial; font-size:14px; line-height:26px"> </p> <div class="dp-highlighter bg_python" style="font-family:Consolas,'Courier New',Courier,mono,serif; width:936.53125px; overflow:auto; padding-top:1px; line-height:26px; margin:18px 0px!important; background-color:rgb(231,229,220)"> <div class="bar" style="padding-left:45px"> </div> </div> </div> </div> </div> </div> </div> <!--PC和WAP自适应版--> <div id="SOHUCS" sid="1187289708271607808"></div> <script type="text/javascript" src="/views/front/js/chanyan.js"></script> <!-- 文章页-底部 动态广告位 --> <div class="youdao-fixed-ad" id="detail_ad_bottom"></div> </div> <div class="col-md-3"> <div class="row" id="ad"> <!-- 文章页-右侧1 动态广告位 --> <div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_1"> </div> </div> <!-- 文章页-右侧2 动态广告位 --> <div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_2"></div> </div> <!-- 文章页-右侧3 动态广告位 --> <div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_3"></div> </div> </div> </div> </div> </div> </div> <div class="container"> <h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(学习碎片)</h4> <div id="paradigm-article-related"> <div class="recommend-post mb30"> <ul class="widget-links"> <li><a href="/article/1899356558266003456.htm" title="基于transformer实现机器翻译(日译中)" target="_blank">基于transformer实现机器翻译(日译中)</a> <span class="text-muted">小白_laughter</span> <a class="tag" taget="_blank" href="/search/%E8%AF%BE%E7%A8%8B%E5%AD%A6%E4%B9%A0/1.htm">课程学习</a><a class="tag" taget="_blank" href="/search/transformer/1.htm">transformer</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E7%BF%BB%E8%AF%91/1.htm">机器翻译</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a> <div>文章目录一、引言二、使用编码器—解码器和注意力机制来实现机器翻译模型2.0含注意力机制的编码器—解码器2.1读取和预处理数据2.2含注意力机制的编码器—解码器2.3训练模型2.4预测不定长的序列2.5评价翻译结果三、使用Transformer架构和PyTorch深度学习库来实现的日中机器翻译模型3.1、导入必要的库3.2、数据集准备3.3、准备分词器3.4、构建TorchText词汇表对象,并将句</div> </li> <li><a href="/article/1899351263640875008.htm" title="【NLP 39、激活函数 ⑤ Swish激活函数】" target="_blank">【NLP 39、激活函数 ⑤ Swish激活函数】</a> <span class="text-muted">L_cl</span> <a class="tag" taget="_blank" href="/search/NLP/1.htm">NLP</a><a class="tag" taget="_blank" href="/search/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86/1.htm">自然语言处理</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a> <div>我的孤独原本是座荒岛,直到你称成潮汐,原来爱是让个体失序的永恒运动——25.2.25Swish激活函数是一种近年来在深度学习中广泛应用的激活函数,由GoogleBrain团队在2017年提出。其核心设计结合了Sigmoid门控机制和线性输入的乘积,通过引入平滑性和非单调性来提升模型性能。一、数学定义与变体1.基础形式Swish的标准表达式为:Swish(x)=x⋅σ(βx)其中:σ(x)是Sigm</div> </li> <li><a href="/article/1899347478755471360.htm" title="机器学习(Machine Learning)" target="_blank">机器学习(Machine Learning)</a> <span class="text-muted">七指琴魔御清绝</span> <a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%AD%A6%E4%B9%A0/1.htm">大数据学习</a> <div>原文链接:http://blog.csdn.net/zhoubl668/article/details/42921187希望转载的朋友,你可以不用联系我.但是一定要保留原文链接,因为这个项目还在继续也在不定期更新.希望看到文章的朋友能够学到更多.《BriefHistoryofMachineLearning》介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机、神经网络、决策树、SVM、Ada</div> </li> <li><a href="/article/1899343573246078976.htm" title="web前端期末大作业:婚纱网页主题网站设计——唯一旅拍婚纱公司网站HTML+CSS+JavaScript" target="_blank">web前端期末大作业:婚纱网页主题网站设计——唯一旅拍婚纱公司网站HTML+CSS+JavaScript</a> <span class="text-muted">IT-司马青衫</span> <a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/%E8%AF%BE%E7%A8%8B%E8%AE%BE%E8%AE%A1/1.htm">课程设计</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a> <div>静态网站的编写主要是用HTMLDⅣV+CSSJS等来完成页面的排版设计,一般的网页作业需要融入以下知识点:div布局、浮动定位、高级css、表格、表单及验证、js轮播图、音频视频Fash的应用、uli、下拉导航栏、鼠标划过效果等知识点,学生网页作业源码,制作水平和原创度都适合学习或交作业用,记得点赞。精彩专栏推荐【作者主页——获取更多优质源码】【web前端期末大作业——毕设项目精品实战案例(1</div> </li> <li><a href="/article/1899342938668855296.htm" title="【Go语言圣经1.1】" target="_blank">【Go语言圣经1.1】</a> <span class="text-muted">Pyroyster</span> <a class="tag" taget="_blank" href="/search/golang/1.htm">golang</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a> <div>目标学习Go的编译方式、包的组织方式以及工具链的统一调用方式概念与定义packageGo语言通过包来组织代码。包类似于其它语言的库librarries或模块modules,每个包通常对应一个目录,目录中的所有.go文件都属于同一个包。特殊的main包:当代码使用packagemain声明时,表示这是一个可独立执行的程序而非一个库。程序的执行入口就是main函数import通过import语句,编译</div> </li> <li><a href="/article/1899340040690003968.htm" title="大语言模型(LLM)入门学习路线图_llm教程,从零基础到精通,理论与实践结合的最佳路径!" target="_blank">大语言模型(LLM)入门学习路线图_llm教程,从零基础到精通,理论与实践结合的最佳路径!</a> <span class="text-muted">AGI学习社</span> <a class="tag" taget="_blank" href="/search/%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B/1.htm">语言模型</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/LLM/1.htm">LLM</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%A8%A1%E5%9E%8B/1.htm">大模型</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a><a class="tag" taget="_blank" href="/search/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86/1.htm">自然语言处理</a> <div>Github项目上有一个大语言模型学习路线笔记,它全面涵盖了大语言模型的所需的基础知识学习,LLM前沿算法和架构,以及如何将大语言模型进行工程化实践。这份资料是初学者或有一定基础的开发/算法人员入门活深入大型语言模型学习的优秀参考。这份资料重点介绍了我们应该掌握哪些核心知识,并推荐了一系列优质的学习视频和博客,旨在帮助大家系统性地掌握大型语言模型的相关技术。大语言模型(LargeLanguageM</div> </li> <li><a href="/article/1899336890570567680.htm" title="机器学习实战——音乐流派分类(主页有源码)" target="_blank">机器学习实战——音乐流派分类(主页有源码)</a> <span class="text-muted">喵了个AI</span> <a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%AE%9E%E6%88%98/1.htm">机器学习实战</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E7%B1%BB/1.htm">分类</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a> <div>✨个人主页欢迎您的访问✨期待您的三连✨✨个人主页欢迎您的访问✨期待您的三连✨✨个人主页欢迎您的访问✨期待您的三连✨1.简介音乐流派分类是音乐信息检索(MusicInformationRetrieval,MIR)中的一个重要任务,旨在通过分析音频信号的特征,将音乐自动分类到不同的流派(如古典、摇滚、爵士、流行等)。随着数字音乐平台的普及,音乐流派分类技术被广泛应用于音乐推荐、自动标签生成和音乐库管理</div> </li> <li><a href="/article/1899335126219812864.htm" title="Flutter中使用NetworkImage加载网络图片缓存问题学习实践" target="_blank">Flutter中使用NetworkImage加载网络图片缓存问题学习实践</a> <span class="text-muted">云水-禅心</span> <a class="tag" taget="_blank" href="/search/flutter/1.htm">flutter</a><a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a> <div>Flutter中默认的NetworkImage会有缓存机制,如果图片的url不变化,但是url的图片已经发生变化,NetworkImage不会下载新的图片deepseek是这么解决问题的,但是在鸿蒙上禁用缓存无效在Flutter中,NetworkImage默认会使用缓存机制来优化性能。如果你想禁用缓存,可以通过以下几种方式实现:1.使用NetworkImage的headers参数你可以通过设置he</div> </li> <li><a href="/article/1899333110311481344.htm" title="什么是XSS" target="_blank">什么是XSS</a> <span class="text-muted">藤原千花的败北</span> <a class="tag" taget="_blank" href="/search/web%E6%BC%8F%E6%B4%9E/1.htm">web漏洞</a><a class="tag" taget="_blank" href="/search/xss/1.htm">xss</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/web%E5%AE%89%E5%85%A8/1.htm">web安全</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8/1.htm">网络安全</a> <div>文章目录前言1.前端知识2.什么是XSS3.漏洞挖掘4.参考前言之前对XSS的理解就是停留在弹窗,认为XSS这种漏洞真的是漏洞吗?安全学习了蛮久了,也应该对XSS有更进一步的认识了。1.前端知识现代浏览器是一个高度复杂的软件系统,由多个核心组件协同工作,旨在高效、安全地呈现网页内容并执行交互逻辑。对一般用户来讲,其主要功能就是向服务器发出请求,在窗口中展示用户所选择的网络资源。这里所说的资源一般是</div> </li> <li><a href="/article/1899332478573801472.htm" title="Oracle创建表空间、删除、状态、重命名、修改、增加、移动" target="_blank">Oracle创建表空间、删除、状态、重命名、修改、增加、移动</a> <span class="text-muted">水煮白菜王</span> <a class="tag" taget="_blank" href="/search/Oracle/1.htm">Oracle</a><a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a> <div>目录Oracle基本学习笔记创建表空间1.表空间创建格式3.表空间状态属性4.重命名表空间5.修改表空间数据文件的大小6.删除表空间的数据文件7.修改表空间中数据文件的状态8.表空间中数据文件的移动Oracle基本学习笔记创建表空间需要使用CREATETABLESPACE语句。其基本语法如下:CREATE[TEMPORARYIUNDO]TABLESPACEtablespacename[DATAFI</div> </li> <li><a href="/article/1899331721439014912.htm" title="python catia catalog文件_Python封装的获取文件目录的函数" target="_blank">python catia catalog文件_Python封装的获取文件目录的函数</a> <span class="text-muted">卢新生</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/catia/1.htm">catia</a><a class="tag" taget="_blank" href="/search/catalog%E6%96%87%E4%BB%B6/1.htm">catalog文件</a> <div>获取指定文件夹中文件的函数,网上学习时东拼西凑的结果。注意,其中文件名如1.txt,文件路径如D:\文件夹\1.txt;direct为第一层子级importos#filePath输入文件夹全路径#mode#1递归获取所有文件名;#2递归获取所有文件路径;#3获取direct文件名;#4获取direct文件路径;#5获取direct文件名和direct子文件夹名;#6获取direct文件路径和dir</div> </li> <li><a href="/article/1899328948634972160.htm" title="CSS入门指南:从零开始学习网页开发——(一)简介" target="_blank">CSS入门指南:从零开始学习网页开发——(一)简介</a> <span class="text-muted">GIS小白吃</span> <a class="tag" taget="_blank" href="/search/css/1.htm">css</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a> <div>一、什么是CSS?CSS(CascadingStyleSheets,层叠样式表)是一种用于描述网页的外观和布局的样式表语言。它通过定义网页元素的样式(如颜色、字体、边距等)来与HTML内容分离,提升了网页的可维护性和设计的灵活性。CSS的核心目的是增强网页的表现力。早期的网页仅使用HTML来进行内容的展示,但由于HTML只能描述内容的结构,页面设计和内容变得难以管理。于是,CSS作为一种辅助技术应</div> </li> <li><a href="/article/1899328443783376896.htm" title="学习笔记09——并发编程之线程基础" target="_blank">学习笔记09——并发编程之线程基础</a> <span class="text-muted">码代码的小仙女</span> <a class="tag" taget="_blank" href="/search/%E9%AB%98%E7%BA%A7%E5%BC%80%E5%8F%91%E5%BF%85%E5%A4%87%E6%8A%80%E8%83%BD/1.htm">高级开发必备技能</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>线程基础1.1进程与线程的区别,Java中线程的实现(用户线程与内核线程)进程是操作系统分配资源的基本单位,而线程是CPU调度的基本单位。每个进程有独立的内存空间,而同一进程内的线程共享内存.可以从资源分配、切换开销、通信方式和独立性四个方面来比较两者的区别资源分配进程:操作系统分配资源(如内存、文件句柄等)的基本单位,拥有独立的地址空间。线程:隶属于进程,共享进程的资源(如内存、文件等),是CP</div> </li> <li><a href="/article/1899328316687577088.htm" title="学习笔记10——并发编程2线程安全问题与同步机制" target="_blank">学习笔记10——并发编程2线程安全问题与同步机制</a> <span class="text-muted">码代码的小仙女</span> <a class="tag" taget="_blank" href="/search/%E9%AB%98%E7%BA%A7%E5%BC%80%E5%8F%91%E5%BF%85%E5%A4%87%E6%8A%80%E8%83%BD/1.htm">高级开发必备技能</a><a class="tag" taget="_blank" href="/search/java%E7%9F%A5%E8%AF%86/1.htm">java知识</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a> <div>线程安全问题与同步机制线程安全的本质问题线程安全问题源于多线程环境下对共享资源(数据或状态)的非原子性、非可见性、非有序性访问,导致程序行为不符合预期。主要表现如下:竞态条件(RaceCondition):多个线程对同一资源进行非原子操作,导致结果依赖线程执行顺序。示例:两个线程同时执行count++(非原子操作,实际包含读-改-写三步)。内存可见性问题:线程修改共享变量后,其他线程无法立即看到最</div> </li> <li><a href="/article/1899325544734978048.htm" title="Java学习笔记——并发编程(三)" target="_blank">Java学习笔记——并发编程(三)</a> <span class="text-muted">__________习惯</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a> <div>一、wait和notifywait和notify原理Owner线程发现条件不满足,调用wait方法,即可进入WaitSet变为WAITING状态BLOCKED和WAITING的线程都处于阻塞状态,不占用CPU时间片BLOCKED线程会在Owner线程释放锁时唤醒WAITING线程会在Owner线程调用notify或notifyAll时唤醒,但唤醒后并不意味着立刻获得锁,仍需进入EntryList重</div> </li> <li><a href="/article/1899325165188214784.htm" title="C 语言中的数组详解" target="_blank">C 语言中的数组详解</a> <span class="text-muted">812503533</span> <a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>在C语言中,数组是一种非常基础且常用的数据结构。数组是存储一组相同类型元素的集合,允许我们以统一的方式访问和操作这些元素。C语言中的数组不仅在编程中使用广泛,而且它的灵活性和效率使得它成为了许多算法实现的基础。本篇文章将深入分析C语言中的一维数组,包括定义、存储方式、操作方式、常见问题等等,所有的数据结构都可以从这几个方面来学习。1.数组的定义与存储方式1.1一维数组的定义数组的定义方式包括数组大</div> </li> <li><a href="/article/1899323266678452224.htm" title="SeisMoLLM: Advancing Seismic Monitoring via Cross-modal Transfer with Pre-trained Large Language" target="_blank">SeisMoLLM: Advancing Seismic Monitoring via Cross-modal Transfer with Pre-trained Large Language</a> <span class="text-muted">UnknownBody</span> <a class="tag" taget="_blank" href="/search/LLM/1.htm">LLM</a><a class="tag" taget="_blank" href="/search/Daily/1.htm">Daily</a><a class="tag" taget="_blank" href="/search/Multimodal/1.htm">Multimodal</a><a class="tag" taget="_blank" href="/search/%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B/1.htm">语言模型</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86/1.htm">自然语言处理</a> <div>摘要深度学习的最新进展给地震监测带来了革命性变化,但开发一个能在多个复杂任务中表现出色的基础模型仍然充满挑战,尤其是在处理信号退化或数据稀缺的情况时。本文提出SeisMoLLM,这是首个利用跨模态迁移进行地震监测的基础模型,它无需在地震数据集上进行直接预训练,就能充分发挥大规模预训练大语言模型的强大能力。通过精心设计的波形标记化处理和对预训练GPT-2模型的微调,SeisMoLLM在DiTing和</div> </li> <li><a href="/article/1899323013787086848.htm" title="50 种不同编程语言的“Hello World”,你知多少?" target="_blank">50 种不同编程语言的“Hello World”,你知多少?</a> <span class="text-muted">逗逗逗逗666</span> <a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a><a class="tag" taget="_blank" href="/search/hello/1.htm">hello</a><a class="tag" taget="_blank" href="/search/world/1.htm">world</a><a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80/1.htm">编程语言</a> <div>当我们学习一门编程语言时,都是从“Hello,World!”开始。所有程序员在其职业生涯中,都至少接触过一个经典的“Hello,World!”程序。通常程序员会使用多种编程语言,多的甚至实现了十几种。还有一种称为TTHW(Timeto“Hello,World!”)的方法,来衡量程序员创建一个新的“Hello,World!”程序的时间。你可以用多少种不同的语言编写一个“Hello,World!”程序</div> </li> <li><a href="/article/1899317973517135872.htm" title="【C语言】八进制、十六进制" target="_blank">【C语言】八进制、十六进制</a> <span class="text-muted">Octopus2077</span> <a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/visual/1.htm">visual</a><a class="tag" taget="_blank" href="/search/studio/1.htm">studio</a> <div>前言在我们日常生活中使用的数往往是十进制的,而当我们学习C语言后我们会接触到许多不同的进制并且时常需要去思考与使用这些不同的进制(尤其是2的幂相关的进制,因为这种计数系统比十进制更接近于计算机的二进制系统),所以学习和掌握这些不同进制是非常重要的。本文将对八进制和十六进制(8和16都为2的幂)进行一些讲解。通常情况C语言都假定整型常量是十进制的数,但在表达与计算机相关的值时,八进制和十六进制却十分</div> </li> <li><a href="/article/1899317343830470656.htm" title="C# &Unity 唐老狮 No.8 模拟面试题" target="_blank">C# &Unity 唐老狮 No.8 模拟面试题</a> <span class="text-muted">咩咩-哈基米版</span> <a class="tag" taget="_blank" href="/search/C%23/1.htm">C#</a><a class="tag" taget="_blank" href="/search/%26amp%3B%26amp%3B/1.htm">&&</a><a class="tag" taget="_blank" href="/search/Unity/1.htm">Unity</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95%E9%A2%98%E4%B8%8E%E7%AE%97%E6%B3%95%E5%90%88%E9%9B%86/1.htm">面试题与算法合集</a><a class="tag" taget="_blank" href="/search/c%23/1.htm">c#</a><a class="tag" taget="_blank" href="/search/unity/1.htm">unity</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>本文章不作任何商业用途仅作学习与交流安利唐老狮与其他老师合作的网站,内有大量免费资源和优质付费资源,我入门就是看唐老师的课程打好坚实的基础非常非常重要:全部-游习堂-唐老狮创立的游戏开发在线学习平台-PoweredByEduSoho如果你发现了文章内特殊的字体格式,那是AI补充的知识,我发现原网站下面有答案,我将会把答案以不同样式穿插在回答之中目录C#1.如果我们想为Unity中的Transfor</div> </li> <li><a href="/article/1899316838844657664.htm" title="学习笔记12——并发编程之线程之间协作方式" target="_blank">学习笔记12——并发编程之线程之间协作方式</a> <span class="text-muted">码代码的小仙女</span> <a class="tag" taget="_blank" href="/search/%E9%AB%98%E7%BA%A7%E5%BC%80%E5%8F%91%E5%BF%85%E5%A4%87%E6%8A%80%E8%83%BD/1.htm">高级开发必备技能</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/jvm/1.htm">jvm</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>线程之间协作有哪些方式当多个线程可以一起工作去解决某个问题时,如果某些部分必须在其他部分之前完成,那么就需要对线程进行协调。共享变量和轮询方式实现:定义一个共享变量(如volatile修饰的布尔标志)。线程通过检查共享变量的状态来决定是否继续执行。publicclassTest{ privatestaticvolatilebooleanflag=false; publicstaticvoi</div> </li> <li><a href="/article/1899310660534202368.htm" title="使用LangChain访问个人数据第一章-简介" target="_blank">使用LangChain访问个人数据第一章-简介</a> <span class="text-muted">明志刘明</span> <a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%AD%A6%E4%B9%A0%E6%89%8B%E5%86%8C/1.htm">大模型学习手册</a><a class="tag" taget="_blank" href="/search/langchain/1.htm">langchain</a> <div>需要学习提示词工程的同学请看面向开发者的提示词工程需要学习ChatGPT的同学请查看搭建基于ChatGPT的问答系统需要学习LangChian开发的同学请查看基于LangChain开发应用程序正文在大数据时代,数据价值逐渐凸显,打造定制化、个性化服务,个人数据尤为重要。要开发一个具备较强服务能力、能够充分展现个性化智能的应用程序,大模型与个人数据的对齐是一个重要步骤。作为针对大模型开发应运而生的框</div> </li> <li><a href="/article/1899310661024935936.htm" title="使用LangChain访问个人数据第八章-总结" target="_blank">使用LangChain访问个人数据第八章-总结</a> <span class="text-muted">明志刘明</span> <a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%AD%A6%E4%B9%A0%E6%89%8B%E5%86%8C/1.htm">大模型学习手册</a><a class="tag" taget="_blank" href="/search/langchain/1.htm">langchain</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a> <div>需要学习提示词工程的同学请看面向开发者的提示词工程需要学习ChatGPT的同学请查看搭建基于ChatGPT的问答系统需要学习LangChian开发的同学请查看基于LangChain开发应用程序本部分前几个章节请查看使用LangChain访问个人数据第一章-简介使用LangChain访问个人数据第二章-文档加载使用LangChain访问个人数据第三章-文档分割使用LangChain访问个人数据第四章</div> </li> <li><a href="/article/1899310408360062976.htm" title="基于 LangChain 开发应用程序第一章-简介" target="_blank">基于 LangChain 开发应用程序第一章-简介</a> <span class="text-muted">明志刘明</span> <a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%AD%A6%E4%B9%A0%E6%89%8B%E5%86%8C/1.htm">大模型学习手册</a><a class="tag" taget="_blank" href="/search/langchain/1.htm">langchain</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a> <div>需要学习提示词工程的同学请看面向开发者的提示词工程需要学习ChatGPT的同学请查看搭建基于ChatGPT的问答系统本部分章节目录如下:基于LangChain开发应用程序第一章-简介基于LangChain开发应用程序第二章-提示和输出基于LangChain开发应用程序第三章-储存基于LangChain开发应用程序第四章-模型链基于LangChain开发应用程序第五章-基于文档的问答基于LangCh</div> </li> <li><a href="/article/1899309401106345984.htm" title="Python学习第十一天" target="_blank">Python学习第十一天</a> <span class="text-muted">Leo来编程</span> <a class="tag" taget="_blank" href="/search/Python%E5%AD%A6%E4%B9%A0/1.htm">Python学习</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>疑惑:有很多人不知道是不是也分不清什么是单核?什么是多核?什么是时间片?进程?线程?那么在讲进程和线程前我先举个例子更好理解这些概念。单核例子:比如你是一个厨师(计算机)在一个厨房(CPU)里需要同时做3个菜(进程)、每个菜需要准备不同的调料以及协作(线程),那么这个厨师需要不断地切换时间(时间片)来达到同时在一个时间将三个菜做完。多核的话其实对应的例子就是多个厨师,这样的例子太多了因为万物皆对象</div> </li> <li><a href="/article/1899309274656468992.htm" title="python学习第三天" target="_blank">python学习第三天</a> <span class="text-muted">Leo来编程</span> <a class="tag" taget="_blank" href="/search/Python%E5%AD%A6%E4%B9%A0/1.htm">Python学习</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>条件判断条件判断使用if、elif和else关键字。它们用于根据条件执行不同的代码块。#条件判断age=18ifage0:#也可以写if(s>0)但是没必要因为python给个提示建议去掉保证代码的按照缩进来进行更加规范print("这个数字是大于0的数字!")#这行代码属于if语句的代码块elifs==0:print("这个数字是等于0的数字!")#这行代码属于elif语句的代码块else:pr</div> </li> <li><a href="/article/1899308770077503488.htm" title="docker运行容器命令 redis 指定端口" target="_blank">docker运行容器命令 redis 指定端口</a> <span class="text-muted">big maom~~</span> <a class="tag" taget="_blank" href="/search/docker/1.htm">docker</a><a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/eureka/1.htm">eureka</a><a class="tag" taget="_blank" href="/search/%E5%AE%B9%E5%99%A8/1.htm">容器</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a> <div>我整理的一些关于【Docker】的项目学习资料(附讲解~~)和大家一起分享、学习一下:https://edu.51cto.com/surl=QsXoR2使用Docker运行Redis容器并指定端口的详细指南本文旨在帮助初学者理解如何使用Docker来运行Redis容器,并指定端口。Docker是一个开源平台,允许开发者将应用和其依赖打包成一个标准的单元——容器。通过使用Docker,开发者可以确保</div> </li> <li><a href="/article/1899306873476149248.htm" title="《Natural Actor-Critic》译读笔记" target="_blank">《Natural Actor-Critic》译读笔记</a> <span class="text-muted">songyuc</span> <a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a> <div>《NaturalActor-Critic》摘要本文提出了一种新型的强化学习架构,即自然演员-评论家(NaturalActor-Critic)。Theactor的更新通过使用Amari的自然梯度方法进行策略梯度的随机估计来实现,而评论家则通过线性回归同时获得自然策略梯度和价值函数的附加参数。本文展示了使用自然策略梯度的actor改进特别有吸引力,因为这些梯度与所选策略表示的坐标框架无关,并且比常规策</div> </li> <li><a href="/article/1899306620995825664.htm" title="如何通过深度学习优化操作系统中的故障诊断与恢复机制" target="_blank">如何通过深度学习优化操作系统中的故障诊断与恢复机制</a> <span class="text-muted">金枝玉叶9</span> <a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9F%A5%E8%AF%86%E5%82%A8%E5%A4%871/1.htm">程序员知识储备1</a><a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9F%A5%E8%AF%86%E5%82%A8%E5%A4%872/1.htm">程序员知识储备2</a><a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9F%A5%E8%AF%86%E5%82%A8%E5%A4%873/1.htm">程序员知识储备3</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a> <div>如何通过深度学习优化操作系统中的故障诊断与恢复机制(副标题:智能监控、自适应诊断与自动恢复——操作系统故障自愈的新方向)摘要随着现代操作系统在多核、高并发和分布式环境中的广泛应用,系统故障及其恢复问题日益成为影响系统稳定性和业务连续性的关键挑战。传统的故障诊断方法依赖于预设规则和人工干预,难以应对复杂多变的故障场景。本文提出了一种基于深度学习的故障诊断与恢复机制,通过对大量历史日志、监控数据和故障</div> </li> <li><a href="/article/1899305361437945856.htm" title="LWC-KD:图结构感知的推荐系统增量学习对比知识蒸馏" target="_blank">LWC-KD:图结构感知的推荐系统增量学习对比知识蒸馏</a> <span class="text-muted">宇直不会放弃</span> <a class="tag" taget="_blank" href="/search/GKD-Middle/1.htm">GKD-Middle</a><a class="tag" taget="_blank" href="/search/layer/1.htm">layer</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/chatgpt/1.htm">chatgpt</a><a class="tag" taget="_blank" href="/search/gpu%E7%AE%97%E5%8A%9B/1.htm">gpu算力</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a><a class="tag" taget="_blank" href="/search/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/1.htm">神经网络</a> <div>LWC-KD:图结构感知的推荐系统增量学习对比知识蒸馏《GraphStructureAwareContrastiveKnowledgeDistillationforIncrementalLearninginRecommenderSystems》2021作者是YueningWang、YingxueZhang和MarkCoates论文地址:https://dl.acm.org/doi/10.1145/</div> </li> <li><a href="/article/88.htm" title="ztree设置禁用节点" target="_blank">ztree设置禁用节点</a> <span class="text-muted">3213213333332132</span> <a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/ztree/1.htm">ztree</a><a class="tag" taget="_blank" href="/search/json/1.htm">json</a><a class="tag" taget="_blank" href="/search/setDisabledNode/1.htm">setDisabledNode</a><a class="tag" taget="_blank" href="/search/Ajax/1.htm">Ajax</a> <div>ztree设置禁用节点的时候注意,当使用ajax后台请求数据,必须要设置为同步获取数据,否者会获取不到节点对象,导致设置禁用没有效果。 $(function(){ showTree(); setDisabledNode(); }); </div> </li> <li><a href="/article/215.htm" title="JVM patch by Taobao" target="_blank">JVM patch by Taobao</a> <span class="text-muted">bookjovi</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/HotSpot/1.htm">HotSpot</a> <div>在网上无意中看到淘宝提交的hotspot patch,共四个,有意思,记录一下。 7050685:jsdbproc64.sh has a typo in the package name 7058036:FieldsAllocationStyle=2 does not work in 32-bit VM 7060619:C1 should respect inline and</div> </li> <li><a href="/article/342.htm" title="将session存储到数据库中" target="_blank">将session存储到数据库中</a> <span class="text-muted">dcj3sjt126com</span> <a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/session/1.htm">session</a> <div>CREATE TABLE sessions ( id CHAR(32) NOT NULL, data TEXT, last_accessed TIMESTAMP NOT NULL, PRIMARY KEY (id) ); <?php /** * Created by PhpStorm. * User: michaeldu * Date</div> </li> <li><a href="/article/469.htm" title="Vector" target="_blank">Vector</a> <span class="text-muted">171815164</span> <a class="tag" taget="_blank" href="/search/vector/1.htm">vector</a> <div>public Vector<CartProduct> delCart(Vector<CartProduct> cart, String id) { for (int i = 0; i < cart.size(); i++) { if (cart.get(i).getId().equals(id)) { cart.remove(i); </div> </li> <li><a href="/article/596.htm" title="各连接池配置参数比较" target="_blank">各连接池配置参数比较</a> <span class="text-muted">g21121</span> <a class="tag" taget="_blank" href="/search/%E8%BF%9E%E6%8E%A5%E6%B1%A0/1.htm">连接池</a> <div> 排版真心费劲,大家凑合看下吧,见谅~ Druid DBCP C3P0 Proxool 数据库用户名称 Username Username User 数据库密码 Password Password Password 驱动名</div> </li> <li><a href="/article/723.htm" title="[简单]mybatis insert语句添加动态字段" target="_blank">[简单]mybatis insert语句添加动态字段</a> <span class="text-muted">53873039oycg</span> <a class="tag" taget="_blank" href="/search/mybatis/1.htm">mybatis</a> <div> mysql数据库,id自增,配置如下: <insert id="saveTestTb" useGeneratedKeys="true" keyProperty="id" parameterType=&</div> </li> <li><a href="/article/850.htm" title="struts2拦截器配置" target="_blank">struts2拦截器配置</a> <span class="text-muted">云端月影</span> <a class="tag" taget="_blank" href="/search/struts2%E6%8B%A6%E6%88%AA%E5%99%A8/1.htm">struts2拦截器</a> <div>struts2拦截器interceptor的三种配置方法 方法1. 普通配置法 <struts> <package name="struts2" extends="struts-default"> &</div> </li> <li><a href="/article/977.htm" title="IE中页面不居中,火狐谷歌等正常" target="_blank">IE中页面不居中,火狐谷歌等正常</a> <span class="text-muted">aijuans</span> <a class="tag" taget="_blank" href="/search/IE%E4%B8%AD%E9%A1%B5%E9%9D%A2%E4%B8%8D%E5%B1%85%E4%B8%AD/1.htm">IE中页面不居中</a> <div>问题是首页在火狐、谷歌、所有IE中正常显示,列表页的页面在火狐谷歌中正常,在IE6、7、8中都不中,觉得可能那个地方设置的让IE系列都不认识,仔细查看后发现,列表页中没写HTML模板部分没有添加DTD定义,就是<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3</div> </li> <li><a href="/article/1104.htm" title="String,int,Integer,char 几个类型常见转换" target="_blank">String,int,Integer,char 几个类型常见转换</a> <span class="text-muted">antonyup_2006</span> <a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/.net/1.htm">.net</a> <div>如何将字串 String 转换成整数 int? int i = Integer.valueOf(my_str).intValue(); int i=Integer.parseInt(str); 如何将字串 String 转换成Integer ? Integer integer=Integer.valueOf(str); 如何将整数 int 转换成字串 String ? 1.</div> </li> <li><a href="/article/1231.htm" title="PL/SQL的游标类型" target="_blank">PL/SQL的游标类型</a> <span class="text-muted">百合不是茶</span> <a class="tag" taget="_blank" href="/search/%E6%98%BE%E7%A4%BA%E6%B8%B8%E6%A0%87%28%E9%9D%99%E6%80%81%E6%B8%B8%E6%A0%87%29/1.htm">显示游标(静态游标)</a><a class="tag" taget="_blank" href="/search/%E9%9A%90%E5%BC%8F%E6%B8%B8%E6%A0%87/1.htm">隐式游标</a><a class="tag" taget="_blank" href="/search/%E6%B8%B8%E6%A0%87%E7%9A%84%E6%9B%B4%E6%96%B0%E5%92%8C%E5%88%A0%E9%99%A4/1.htm">游标的更新和删除</a><a class="tag" taget="_blank" href="/search/%25rowtype/1.htm">%rowtype</a><a class="tag" taget="_blank" href="/search/ref%E6%B8%B8%E6%A0%87%28%E5%8A%A8%E6%80%81%E6%B8%B8%E6%A0%87%29/1.htm">ref游标(动态游标)</a> <div>游标是oracle中的一个结果集,用于存放查询的结果; PL/SQL中游标的声明; 1,声明游标 2,打开游标(默认是关闭的); 3,提取数据 4,关闭游标 注意的要点:游标必须声明在declare中,使用open打开游标,fetch取游标中的数据,close关闭游标 隐式游标:主要是对DML数据的操作隐</div> </li> <li><a href="/article/1358.htm" title="JUnit4中@AfterClass @BeforeClass @after @before的区别对比" target="_blank">JUnit4中@AfterClass @BeforeClass @after @before的区别对比</a> <span class="text-muted">bijian1013</span> <a class="tag" taget="_blank" href="/search/JUnit4/1.htm">JUnit4</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E5%85%83%E6%B5%8B%E8%AF%95/1.htm">单元测试</a> <div>一.基础知识 JUnit4使用Java5中的注解(annotation),以下是JUnit4常用的几个annotation: @Before:初始化方法 对于每一个测试方法都要执行一次(注意与BeforeClass区别,后者是对于所有方法执行一次)@After:释放资源 对于每一个测试方法都要执行一次(注意与AfterClass区别,后者是对于所有方法执行一次</div> </li> <li><a href="/article/1485.htm" title="精通Oracle10编程SQL(12)开发包" target="_blank">精通Oracle10编程SQL(12)开发包</a> <span class="text-muted">bijian1013</span> <a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/plsql/1.htm">plsql</a> <div>/* *开发包 *包用于逻辑组合相关的PL/SQL类型(例如TABLE类型和RECORD类型)、PL/SQL项(例如游标和游标变量)和PL/SQL子程序(例如过程和函数) */ --包用于逻辑组合相关的PL/SQL类型、项和子程序,它由包规范和包体两部分组成 --建立包规范:包规范实际是包与应用程序之间的接口,它用于定义包的公用组件,包括常量、变量、游标、过程和函数等 --在包规</div> </li> <li><a href="/article/1612.htm" title="【EhCache二】ehcache.xml配置详解" target="_blank">【EhCache二】ehcache.xml配置详解</a> <span class="text-muted">bit1129</span> <a class="tag" taget="_blank" href="/search/ehcache.xml/1.htm">ehcache.xml</a> <div>在ehcache官网上找了多次,终于找到ehcache.xml配置元素和属性的含义说明文档了,这个文档包含在ehcache.xml的注释中! ehcache.xml : http://ehcache.org/ehcache.xml ehcache.xsd : http://ehcache.org/ehcache.xsd ehcache配置文件的根元素是ehcahe ehcac</div> </li> <li><a href="/article/1739.htm" title="java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoaderL" target="_blank">java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoaderL</a> <span class="text-muted">白糖_</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/eclipse/1.htm">eclipse</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/tomcat/1.htm">tomcat</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a> <div>今天学习spring+cxf的时候遇到一个问题:在web.xml中配置了spring的上下文监听器: <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener> 随后启动</div> </li> <li><a href="/article/1866.htm" title="angular.element" target="_blank">angular.element</a> <span class="text-muted">boyitech</span> <a class="tag" taget="_blank" href="/search/AngularJS/1.htm">AngularJS</a><a class="tag" taget="_blank" href="/search/AngularJS+API/1.htm">AngularJS API</a><a class="tag" taget="_blank" href="/search/angular.element/1.htm">angular.element</a> <div>angular.element 描述: 包裹着一部分DOM element或者是HTML字符串,把它作为一个jQuery元素来处理。(类似于jQuery的选择器啦) 如果jQuery被引入了,则angular.element就可以看作是jQuery选择器,选择的对象可以使用jQuery的函数;如果jQuery不可用,angular.e</div> </li> <li><a href="/article/1993.htm" title="java-给定两个已排序序列,找出共同的元素。" target="_blank">java-给定两个已排序序列,找出共同的元素。</a> <span class="text-muted">bylijinnan</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a> <div> import java.util.ArrayList; import java.util.Arrays; import java.util.List; public class CommonItemInTwoSortedArray { /** * 题目:给定两个已排序序列,找出共同的元素。 * 1.定义两个指针分别指向序列的开始。 * 如果指向的两个元素</div> </li> <li><a href="/article/2120.htm" title="sftp 异常,有遇到的吗?求解" target="_blank">sftp 异常,有遇到的吗?求解</a> <span class="text-muted">Chen.H</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/jcraft/1.htm">jcraft</a><a class="tag" taget="_blank" href="/search/auth/1.htm">auth</a><a class="tag" taget="_blank" href="/search/jsch/1.htm">jsch</a><a class="tag" taget="_blank" href="/search/jschexception/1.htm">jschexception</a> <div>com.jcraft.jsch.JSchException: Auth cancel at com.jcraft.jsch.Session.connect(Session.java:460) at com.jcraft.jsch.Session.connect(Session.java:154) at cn.vivame.util.ftp.SftpServerAccess.connec</div> </li> <li><a href="/article/2247.htm" title="[生物智能与人工智能]神经元中的电化学结构代表什么?" target="_blank">[生物智能与人工智能]神经元中的电化学结构代表什么?</a> <span class="text-muted">comsci</span> <a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a> <div> 我这里做一个大胆的猜想,生物神经网络中的神经元中包含着一些化学和类似电路的结构,这些结构通常用来扮演类似我们在拓扑分析系统中的节点嵌入方程一样,使得我们的神经网络产生智能判断的能力,而这些嵌入到节点中的方程同时也扮演着"经验"的角色.... 我们可以尝试一下...在某些神经</div> </li> <li><a href="/article/2374.htm" title="通过LAC和CID获取经纬度信息" target="_blank">通过LAC和CID获取经纬度信息</a> <span class="text-muted">dai_lm</span> <a class="tag" taget="_blank" href="/search/lac/1.htm">lac</a><a class="tag" taget="_blank" href="/search/cid/1.htm">cid</a> <div>方法1: 用浏览器打开http://www.minigps.net/cellsearch.html,然后输入lac和cid信息(mcc和mnc可以填0),如果数据正确就可以获得相应的经纬度 方法2: 发送HTTP请求到http://www.open-electronics.org/celltrack/cell.php?hex=0&lac=<lac>&cid=&</div> </li> <li><a href="/article/2501.htm" title="JAVA的困难分析" target="_blank">JAVA的困难分析</a> <span class="text-muted">datamachine</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a> <div>前段时间转了一篇SQL的文章(http://datamachine.iteye.com/blog/1971896),文章不复杂,但思想深刻,就顺便思考了一下java的不足,当砖头丢出来,希望引点和田玉。 -----------------------------------------------------------------------------------------</div> </li> <li><a href="/article/2628.htm" title="小学5年级英语单词背诵第二课" target="_blank">小学5年级英语单词背诵第二课</a> <span class="text-muted">dcj3sjt126com</span> <a class="tag" taget="_blank" href="/search/english/1.htm">english</a><a class="tag" taget="_blank" href="/search/word/1.htm">word</a> <div>money 钱 paper 纸 speak 讲,说 tell 告诉 remember 记得,想起 knock 敲,击,打 question 问题 number 数字,号码 learn 学会,学习 street 街道 carry 搬运,携带 send 发送,邮寄,发射 must 必须 light 灯,光线,轻的 front </div> </li> <li><a href="/article/2755.htm" title="linux下面没有tree命令" target="_blank">linux下面没有tree命令</a> <span class="text-muted">dcj3sjt126com</span> <a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a> <div>centos p安装 yum -y install tree mac os安装 brew install tree 首先来看tree的用法 tree 中文解释:tree 功能说明:以树状图列出目录的内容。 语 法:tree [-aACdDfFgilnNpqstux][-I <范本样式>][-P <范本样式</div> </li> <li><a href="/article/2882.htm" title="Map迭代方式,Map迭代,Map循环" target="_blank">Map迭代方式,Map迭代,Map循环</a> <span class="text-muted">蕃薯耀</span> <a class="tag" taget="_blank" href="/search/Map%E5%BE%AA%E7%8E%AF/1.htm">Map循环</a><a class="tag" taget="_blank" href="/search/Map%E8%BF%AD%E4%BB%A3/1.htm">Map迭代</a><a class="tag" taget="_blank" href="/search/Map%E8%BF%AD%E4%BB%A3%E6%96%B9%E5%BC%8F/1.htm">Map迭代方式</a> <div>Map迭代方式,Map迭代,Map循环 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> 蕃薯耀 2015年</div> </li> <li><a href="/article/3009.htm" title="Spring Cache注解+Redis" target="_blank">Spring Cache注解+Redis</a> <span class="text-muted">hanqunfeng</span> <a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a> <div>Spring3.1 Cache注解 依赖jar包: <!-- redis --> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> </div> </li> <li><a href="/article/3136.htm" title="Guava中针对集合的 filter和过滤功能" target="_blank">Guava中针对集合的 filter和过滤功能</a> <span class="text-muted">jackyrong</span> <a class="tag" taget="_blank" href="/search/filter/1.htm">filter</a> <div>在guava库中,自带了过滤器(filter)的功能,可以用来对collection 进行过滤,先看例子: @Test public void whenFilterWithIterables_thenFiltered() { List<String> names = Lists.newArrayList("John"</div> </li> <li><a href="/article/3263.htm" title="学习编程那点事" target="_blank">学习编程那点事</a> <span class="text-muted">lampcy</span> <a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a><a class="tag" taget="_blank" href="/search/android/1.htm">android</a><a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/html5/1.htm">html5</a> <div>一年前的夏天,我还在纠结要不要改行,要不要去学php?能学到真本事吗?改行能成功吗?太多的问题,我终于不顾一切,下定决心,辞去了工作,来到传说中的帝都。老师给的乘车方式还算有效,很顺利的就到了学校,赶巧了,正好学校搬到了新校区。先安顿了下来,过了个轻松的周末,第一次到帝都,逛逛吧! 接下来的周一,是我噩梦的开始,学习内容对我这个零基础的人来说,除了勉强完成老师布置的作业外,我已经没有时间和精力去</div> </li> <li><a href="/article/3390.htm" title="架构师之流处理---------bytebuffer的mark,limit和flip" target="_blank">架构师之流处理---------bytebuffer的mark,limit和flip</a> <span class="text-muted">nannan408</span> <a class="tag" taget="_blank" href="/search/ByteBuffer/1.htm">ByteBuffer</a> <div>1.前言。 如题,limit其实就是可以读取的字节长度的意思,flip是清空的意思,mark是标记的意思 。 2.例子. 例子代码: String str = "helloWorld"; ByteBuffer buff = ByteBuffer.wrap(str.getBytes()); Sy</div> </li> <li><a href="/article/3517.htm" title="org.apache.el.parser.ParseException: Encountered " ":" ": "" at line 1, column 1" target="_blank">org.apache.el.parser.ParseException: Encountered " ":" ": "" at line 1, column 1</a> <span class="text-muted">Everyday都不同</span> <a class="tag" taget="_blank" href="/search/%24/1.htm">$</a><a class="tag" taget="_blank" href="/search/%E8%BD%AC%E4%B9%89/1.htm">转义</a><a class="tag" taget="_blank" href="/search/el%E8%A1%A8%E8%BE%BE%E5%BC%8F/1.htm">el表达式</a> <div>最近在做Highcharts的过程中,在写js时,出现了以下异常: 严重: Servlet.service() for servlet jsp threw exception org.apache.el.parser.ParseException: Encountered " ":" ": "" at line 1, </div> </li> <li><a href="/article/3644.htm" title="用Java实现发送邮件到163" target="_blank">用Java实现发送邮件到163</a> <span class="text-muted">tntxia</span> <a class="tag" taget="_blank" href="/search/java%E5%AE%9E%E7%8E%B0/1.htm">java实现</a> <div>/* 在java版经常看到有人问如何用javamail发送邮件?如何接收邮件?如何访问多个文件夹等。问题零散,而历史的回复早已经淹没在问题的海洋之中。 本人之前所做过一个java项目,其中包含有WebMail功能,当初为用java实现而对javamail摸索了一段时间,总算有点收获。看到论坛中的经常有此方面的问题,因此把我的一些经验帖出来,希望对大家有些帮助。 此篇仅介绍用</div> </li> <li><a href="/article/3771.htm" title="探索实体类存在的真正意义" target="_blank">探索实体类存在的真正意义</a> <span class="text-muted">java小叶檀</span> <a class="tag" taget="_blank" href="/search/POJO/1.htm">POJO</a> <div>一. 实体类简述 实体类其实就是俗称的POJO,这种类一般不实现特殊框架下的接口,在程序中仅作为数据容器用来持久化存储数据用的 POJO(Plain Old Java Objects)简单的Java对象 它的一般格式就是 public class A{ private String id; public Str</div> </li> </ul> </div> </div> </div> <div> <div class="container"> <div class="indexes"> <strong>按字母分类:</strong> <a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a> </div> </div> </div> <footer id="footer" class="mb30 mt30"> <div class="container"> <div class="footBglm"> <a target="_blank" href="/">首页</a> - <a target="_blank" href="/custom/about.htm">关于我们</a> - <a target="_blank" href="/search/Java/1.htm">站内搜索</a> - <a target="_blank" href="/sitemap.txt">Sitemap</a> - <a target="_blank" href="/custom/delete.htm">侵权投诉</a> </div> <div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved. <!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>--> </div> </div> </footer> <!-- 代码高亮 --> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script> <link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/> <script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script> </body> </html>
- CharToNextTabRex = re.compile("