对抗的训练来从模拟和无监督图像中学习
来自Ashish Shrivastava 1 等人的文章“Learning from Simulated and Unsupervised Images through Adversarial Training”。
摘要
无需昂贵的标注,用合成图像更容易训练模型。但因合成图像分布与真实图像分布的差异,用合成图像学习效果不理想。因此提出:
- “模拟+无监督”(S+U)学习:保留模拟器给出的标注信息的同时,用无标签的真实数据来提高模拟器(simulator)输出的真实度。
- S+U学习方法:对抗网络的输入为合成图像,而非随机向量。改动标准GAN来保留标注,避免合成现象(artifacts)和稳定训练:(i)“自正则”项,(ii)局部的对抗损失,和(iii)用细化图像(refined images)的历史来更新判别器。
- 泛化至真实图像:定性和用户研究来表明生成图像的逼真。训练模型来估计注视和手部姿态,定量评估生成的图像。
1. 简介
标注大数据集昂贵耗时,但可自动获得合成数据的标注。用合成数据已解决Kinect的手部姿态估计及最近一些其它任务。
而学习合成图像会有问题:合成图像与真实图像的差异—合成数据通常不够真实,使网络仅学到合成图像的细节,却难以泛化至真实图像。
解决方案之一为改善模拟器,而增加真实度计算昂贵,设计渲染器的工作量很大,且顶级渲染器仍可能难以建模真实图像的所有特征。这可能会使模型在合成图像中“不真实”的细节上过拟合。
- S+U学习应保留训练机器学习模型的标注信息,如保留图 1 中的注视方向。

- S+U学习方法(SimGAN)用一细化网络(“refiner network”)细化合成图像,概述见图 2 ,合成图像由黑箱模拟器生成,并经细化网络细化。(i)为增加真实度,类似GANs训练对抗网络,用正则损失,使判别网络无法区分细化的生成图像与真实图像。(ii)为保留合成图像的标注,为对抗损失补充自正则损失,来惩罚合成图像与真实图像间的巨大改变。进一步用一全卷积网络操作像素并保留全局结构(而非如全连接编码网络那样去完全改变图像内容)。(iii)GAN框架用竞争的目标来训练 2 个网络,使网络不稳定且易引入合成现象。因此限制判别器的感受野至局部区域(而非整幅图像),使每幅图有多个局部的对抗损失。并用细化图像的历史(而非当前细化网络输出的细化图像)更新判别器来稳定训练。

2. 使用SimGAN的S+U学习
S+U学习是为用无标签的真实图像 yi∈Y 来学习细化合成图像 x 的细化器 Rθ(x) , θ 为细化器的参数。 x~ 表示细化图像,有:
S+U学习要求保留模拟器的标注信息的同时,细化图像 x~ 应看起来接近真实图像。
至此,结合 2 个损失后最小化来学习 θ :
其中, xi 为第 i 幅合成的训练图像, x~i 为第 i 幅细化图像。第 1 部分损失 lreal 增加了合成图像的逼真度,而第 2 部分损失 lreg 通过最小化合成图像与细化图像间的差异来保留标注信息。
2.1 关于自正则(Self-Regularization)的对抗损失
理想的细化器会使其输出图像难以判别真假。因此,训练对抗判别网络 Dϕ 来分类图像的真假,其中 ϕ 为判别网络的参数。训练细化网络 R 的对抗损失来“愚弄”网络 D 判断图像真假。使用GAN方法为 1 个双玩家的最小最大游戏,并交替更新细化网络 Rθ和 判别网络 Dϕ 。
最小化如下损失来更新判别网络的参数:
希望判别器可判别真实图像不为合成图像: Dϕ(yi)↓,1−Dϕ(yi)↑,−∑jlog(1−Dϕ(yj))↓ ;
希望判别器可判别细化图像为合成图像: Dϕ(x~i)↑,−∑ilog(Dϕ(x~i))↓ 。
它等价于二分类问题的交叉熵,其中 Dϕ(.) 为输入合成图像的概率,则 1−Dϕ(.) 为输入真实图像的概率。 Dϕ 用卷积网络,网络的最后一层输出样本为细化图像的概率。训练该判别网络时,每个小块(minibatch)包含随机采样的细化的合成图像 x~′is 和真实图像 y′js 。每个 yj 的交叉损失层的目标标签为 0 ,每个 x~i 的目标标签为 1 。小块的损失的梯度上用随机梯度下降(SGD)步来更新小块的参数。
这里,方程 (1) 中的真实度损失函数 lreal 使用训练好的判别器 D :
希望细化器使判别器难以判别细化图像为合成图像: Dϕ(Rθ(xi))↓,−∑ilog(1−Dϕ(Rθ(xi))↓ 。
最小化该损失函数。除生成逼真图像,细化网络应保留模拟器的标注信息。如,
- 注视估计:学到的变换不应改变注视方向;
- 手部姿态估计:关节的位置不应改变。
因而使机器学习模型能用有标注信息的细化图像。为此,提出自正则损失来最小化合成图像与细化图像间的图像差异。因此,该应用下方程 (1) 中的全部损失函数为:
其中 ||.||1 为L 1 正则。无跨越(striding)或池化的全卷积神经网络作为 Rθ 。 像素层面上修改合成图像,而非如全连接编码器那样完全改变图像内容,并保留全局结构与标注。
交替最小化 LR(θ) 和 LD(ϕ) 来学习细化器和判别器的参数:更新 Rθ 的参数时,保持 ϕ 不变;更新 Dϕ 的参数时,保持 θ 不变。
2.2 局部的对抗损失
还要求不引入合成现象的同时,细化网络应学到真实图像的特征:训练单个强判别网络时,细化网络往往过分强调特定的图像特征来愚弄当前的判别网络。从细化图像中采样的局部块应与真实图像中的对应块有相似的统计特性。因此,定义一可单独分类所有图像块的判别网络(而非一全局判别网络)。这样限制了感受野的大小(判别网络的容量);为学习判别网络提供很多样本;更好地训练细化网络(每幅图像多个“真实度损失”)。
这里,设计判别器 D 为一输出 w×h 维的块概率图,判断输入块是否为合成图像。其中, w×h 为图像中局部块的数目。训练细化网络时, w×h 个局部块上求和交叉熵损失,见图 3 。

2.3 用细化图像的历史更新判别器
对抗训练另一问题:判别网络仅关注最近时间步上的细化图像。这可能导致:(i)训练发散,(ii)细化网络引入判别网络遗忘的合成现象。
对于判别网络,整个训练中所有时间步上,所有细化网络生成的细化图像都为合成图像。因此,判别器应能将所有这些图像分类为合成图像。基于此,用细化图像的历史更新判别网络来提高训练的稳定性(而非仅用当前时间步上的小块)。修改方法 1 ,使其有之前网络生成的细化图像缓冲。方法 1 中,令 B 为缓冲的大小, b 为小块的大小。

训练判别网络时每次迭代,从当前细化网络和缓冲中分别采样 b2 张图像来更新参数 ϕ 。固定缓冲大小 B 。每次迭代后,从缓冲中随机采样 b2 张图像作为新的生成的细化图像,见图 4 。

3. 实验
MPIIGaze数据集和NYU手部姿态的深度图像数据集上评估方法。所有实验用全卷积细化网络(带残差网络模块),见图 6 。
3.1 注视(Gaze)估计
尤其当遇到低质量图像时(笔记本或移动手机的相机),从眼部图像中估计注视方向面临挑战。甚至人类用注视方向向量来标注眼部图像也是有挑战的。为生成大量的标注数据,最近的研究者用大量的合成数据来训练模型。这里,该任务上用SimGAN生成的细化的合成图像有显著的改善。
注视估计数据集包含 1.2M 张用眼部注视合成器UnityEyes合成的图像和 214K 张MPIIGaze数据集上的真实图像,样本见图 5 。

3.1.1 定性结果
SimGAN成功获取真实图像中皮肤纹理,传感器噪声和虹膜区域的外观。注意到该方法提高真实度的同时,保留了标注信息(注视方向)。
3.1.2 视觉图灵测试
为定量评估细化图像的视觉质量,设计简单的用户研究,询问用户来分类细化的合成图像与真实图像。
展示给每个用户随机选择的 50 张真实图像和乱序的 50 张细化图像,每次给用户连续展示 20 张图像。总体分析, 10 个用户可从 1000 次( (50+50)×10 )尝试中正确选择 517 次( p=0.148 ),比碰运气略好。表 1 为混淆矩阵。
相反,展示给每个用户 10 张真实图像和 10 张合成图像, 200 次( (10+10)×10 )尝试中正确选择 162 次( p≤10−8 ),比碰运气好得多。
![]()
H0:μ≤0.5;H1:μ>0.5 。p值计算结果2: 0.148344675387;9.92185044371e−20
print stats.binom_test(517, 1000, 0.5, 'greater')
print stats.binom_test(162, 200, 0.5, 'greater')
3.1.3 定量结果
训练一卷积网络来预测眼部的注视方向(用 3 维向量 [x,y,z] 编码和 L2 损失)。UnityEyes上训练,MPIIGaze上测试。图 7 和表 2 比较了卷积网络用合成数据和用细化的合成数据(SimGAN输出)训练出的结果。SimGAN输出的结果有 22.3 %的提高。
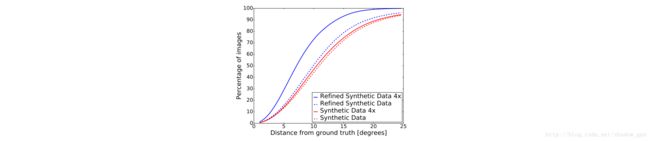

表 3 与最新成果比较。细化图像上训练卷积网络比MPIIGaze数据集上最新结果提高 21 %。

3.1.4 应用细节
细化网络, Rθ ,为一残差网络。每个残差网络模块包含 2 个卷积层,每个卷积层包含 64 个特征图,见图 6 。
3×3 大小的滤波器卷积 55×35 大小的输入图像,输出 64 个特征图。输出经过 4 个残差模块。最后 1 个残差模块的输出经过 1 个 1×1 大小的卷积层来输出 1 个对应细化的合成图像的特征图。

判别网络, Dϕ ,包含 5 个卷积层和 1 个最大池化层,如下:
(1) Conv3×3,stride=2,feature maps=96
(2) Conv3×3,stride=2,feature maps=64
(3) MaxPool3×3,stride=1
(4) Conv3×3,stride=1,feature maps=32
(5) Conv1×1,stride=1,feature maps=32
(6) Conv1×1,stride=1,feature maps=2
(7) Softmax
对抗网络为全卷积网络,设计该网络使 Rθ 与 Dϕ 中最后 1 层神经元的感受野相似。先训练仅有自正则损失的 Rθ 网络 1000 步,训练 Dϕ200 步;然后, Dϕ 每更新 1 次, Rθ 更新 2 次,即方法 1 中, Kd 设为 1 且 Kg 设为 50 。
注:先单独训练细化网络和判别网络,再同时训练。 Kg 应改为 2 ,但也有可能为 50 ~
眼部注视估计网络的输入为 35×55 大小的灰度图像,经过 5 个卷积层和 3 个全连接层,最后 1 全连接层编码 3 维注视向量:
(1) Conv3×3,feature maps=32
(2) Conv3×3,feature maps=32
(3) Conv3×3,feature maps=64
(4) MaxPool3×3,stride=2
(5) Conv3×3,feature maps=80
(6) Conv3×3,feature maps=192
(7) MaxPool2×2,stride=2
(8) FC9600
(9) FC1000
(10) FC3
(11) Euclidean loss
用不变的学习率 0.001 和 512 个块来训练所有的网络,直到验证误差收敛。
3.2 从深度图像估计手部姿态
NYU手部姿态数据集包含 72757 个训练帧和从 3 个Kinect相机( 1 个前视, 2 个侧视)捕获的 8251 个测试帧。手部姿态信息用于创建合成的深度图像,用其标注每个深度帧。图 10 显示其中一帧。预处理时,用合成图像从真实图像中裁剪手部像素区域,传入卷积网络前缩放至 224×224 大小。背景深度值设为 0 ,前景深度值设为原深度值减 2000 (假设相机距背景 2000 mm)。

3.2.1 定性结果
图 11 为NYU手部姿态数据集上SimGAN的示例输出。显然,真实深度图像中的噪声主要来自边缘处深度的不连续。SimGAN无需真实图像的任何标注信息,就能学到建模该类噪声,从而使这些合成图像更加逼真。

3.2.2 定量结果
类似堆叠的沙漏网络(Stacked Hourglass Net),NYU手部姿态训练集的真实图像,合成图像和细化的合成图像上训练 1 个全卷积手部姿态估计CNN;NYU手部姿态测试集的所有真实图像上评估网络。
图 12 和表 4 为NYU手部姿态数据集上的定量结果。
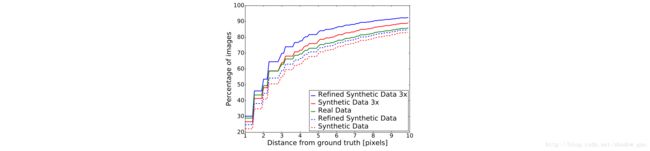

细化的合成数据(SimGAN输出)上的训练不要求真实图像的任何标注。相比有监督的真实图像上训练出的模型,效果超出 8.8 %;合成图像上训练效果也更好;训练样本增加后有很大提高。
3.2.3 应用细节
细化网络的结构与眼部注视估计的细化网络的结构相同,除了输入 224×224 大小的图像,滤波器大小为 7×7 ,用 10 个残差网络。
判别网络, Dϕ ,为:
(1) Conv7×7,stride=4,feature maps=96
(2) Conv5×5,stride=2,feature maps=64
(3) MaxPool3×3,stride=2
(4) Conv3×3,stride=2,feature maps=32
(5) Conv1×1,stride=1,feature maps=32
(6) Conv1×1,stride=1,feature maps=2
(7) Softmax
先训练仅有自正则损失的 Rθ 网络 500 步,训练 Dϕ200 步;然后, Dϕ 每更新 1 次, Rθ 更新 2 次,即方法 1 中, Kd 设为 1 且 Kg 设为 2 。
手动姿态估计网络用 2 个沙漏模块,输出 64×64 大小的热度图。训练时,随机旋转 [−20,20] 和裁剪来增广数据。训练所有的网络,直到验证误差收敛。
3.3 分析对抗训练的改动
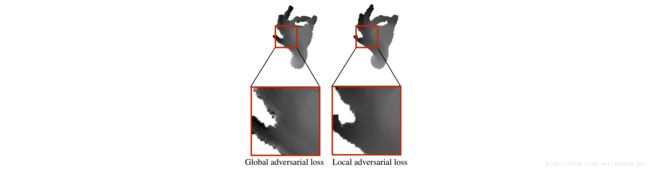
比较训练时局部和全局的对抗损失。局部的对抗损失移除合成现象,使生成的图像更真实,见图 8 。
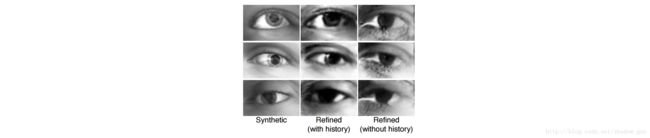
使用细化图像的历史,与注视估计中标准的对抗训练比较,见图 9 。细化图像的缓冲阻碍标准训练中严重的合成现象,如眼角周围。
4. 小结
本文主要意图:合成图像可自动被标注,而大量真实图像的标注代价高;模拟器生成合成图像,经细化网络输出细化的合成图像;细化的合成图像逼近真实图像,并保留了标注信息;所用的真实图像测试集上,相比用原真实图像训练出的模型,用细化的合成图像训练出的模型效果更好。
全文未经校正,有问题欢迎指出~ (๑•̀ㅂ•́)و✧