用python理解数据---房价预测数据可视化分析kernel读后感
kernel原链接:https://www.kaggle.com/pmarcelino/comprehensive-data-exploration-with-python
该比赛是针对房价预测这种回归任务
开场白:生活中最难懂的是自我。
kernel关于四个方面展开
1. 理解问题:相对于问题而言,对每一个变量研究他们的意义和重要性
2. 单变量研究:该比赛中就针对目标变量(预测的房价)
3. 多变量分析:尝试分析独立变量和相关变量之间的关系
4. 清洗数据:处理缺失值,离群点和类别属性
注:其中导入的包中有一个seaborn的库特别好用,特别适合可视化分析变量
一:理解问题与单变量研究
该问题是根据关于房屋的一系列属性来预测房价,在这个问题中我们首先需要去观察房价的分布,波动范围。像这种我们能够用主观意思去分析的问题,可以尝试以自己的主观意识分析哪些变量可能和目标(房价预测)有较强的相关性。当然,主观分析不能具有理性说服力,并且在很多任务中,主观意思不准确或者无主观意思可参考。
主观意思分析问题能将我们带入问题,但是更好的方法还是从数据中分析变量的相关性。
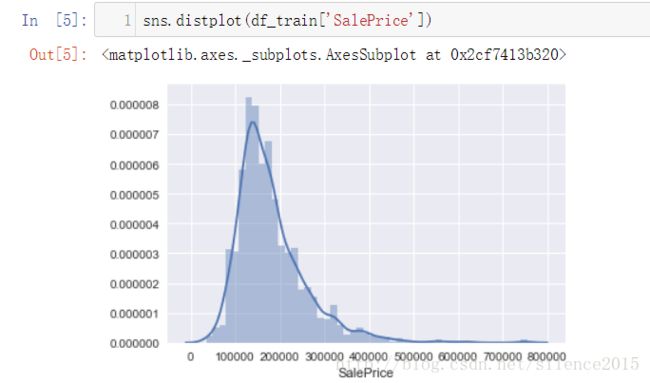
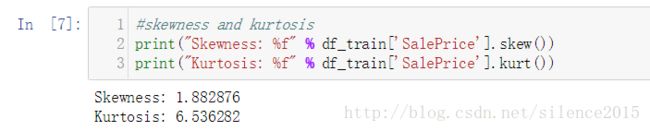
我们先分析一下目标:房价。先describe一下,看看大致分布,也可以用(sns是seaborn的简称)sns.distplot查看房价分布,还可以进一步计算偏度,峰度信息,这些都可以由pandas的dataframe数据结构很好支持。
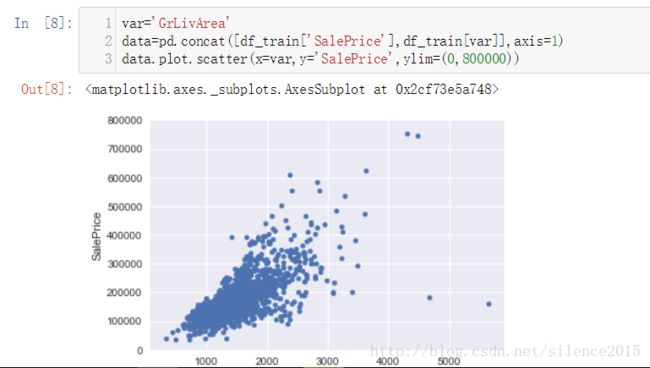
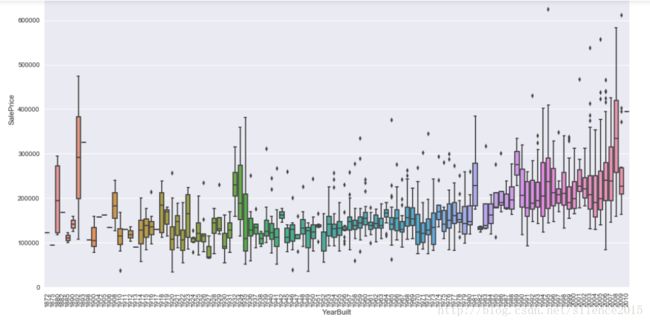
研究完房价后,我们将眼光放在和房价相关的属性研究上。比如在这个例子中,我们先看看数据由哪些属性列,根据属性列的数据我们根据主观意识觉得OverallQual、YearBuilt,totalBsmtSF,GrLivArea与预测的房价有较强的相关性。对于数值型属性,我们可以将属性与房价的关系用散点图描述出来,很容易发现自己猜测的属性特征究竟和房价有没有线性相关性。对于类别型属性,我们可以画出类别属性与房价的箱线图来描述它们之间的关系。(seaborn真的是绘图神器)

二:多变量研究
好了,我们已经对目标(房价)单变量作出分析,并且通过主观意识去分析哪些变量很有可能与房价相关。通过散点图、箱线图很容易验证自己的猜想。
但是数据分析需要用数据说话,而不是人为经验,当然经验起到辅助分析的作用。
下面我们通过数据计算分析,哪些属性与房价有强相关,究竟怎么相关。
想要研究变量之间相关性(包括属性与房价之间的关系)可以通过协方差矩阵来研究
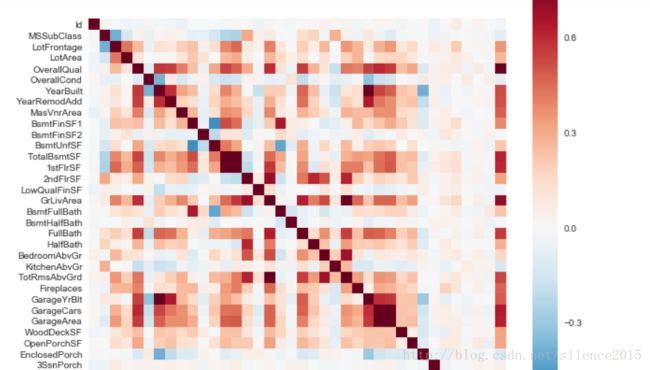
通过dataframe的corr()很容易计算相关系数,然后用热图很容易可视化相关性(nice)
ok,现在来个筛选,筛选出个房价最相关的10个属性,并画出热图
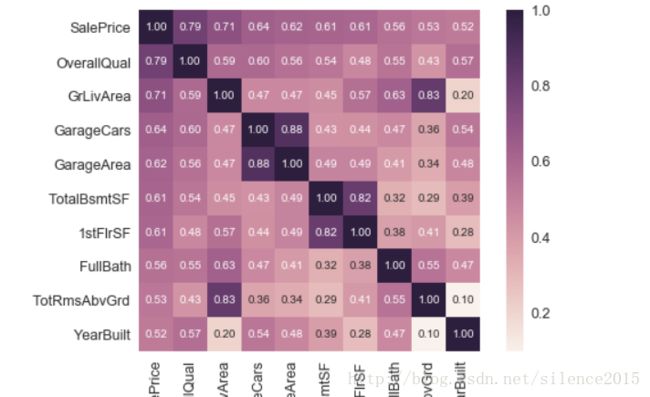
nice!根据上面的热图,很容易去分析哪些属性和房价高度线性相关,并且还可以分析出哪些属性之间是高度相关的,这可以为特征筛选提供思路。
最后seaborn还有大招,就是直接可视化所有属性之间的分布情况,简直完美

三:数据清洗
缺失数据处理
对于缺失数据,我们需要考虑两个问题。第一:缺失数据的分布情况, 第二:缺失数据是随机的还是有模式的,它所在属性列与目标之间相关性如何
怀揣这疑问,我们首先看看缺失数据的分布情况
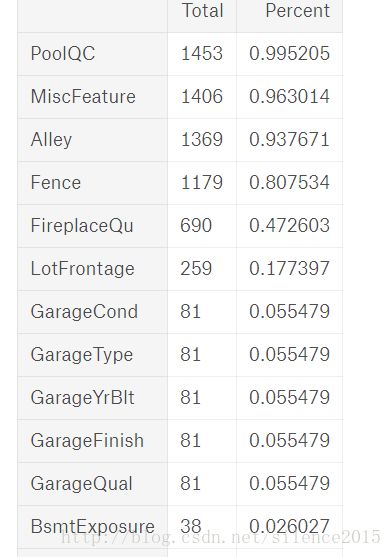
一看发现,有些列缺失率都达到90%以上了,对于缺失严重的属性列,可以采取删除这个属性列。
我们再考虑缺失数据数据属性列与目标的相关性,根据之前的协方差系数矩阵热图,我们知道GarageXX这几个属性相关性本来就很高,这儿他们的缺失率也接近,故可以考虑留下最相关的属性,删除剩余的几个。
离群点数据处理
离群点的处理还是在于离群点的发现与分析。
发现的话可以使用散点图和排序分析
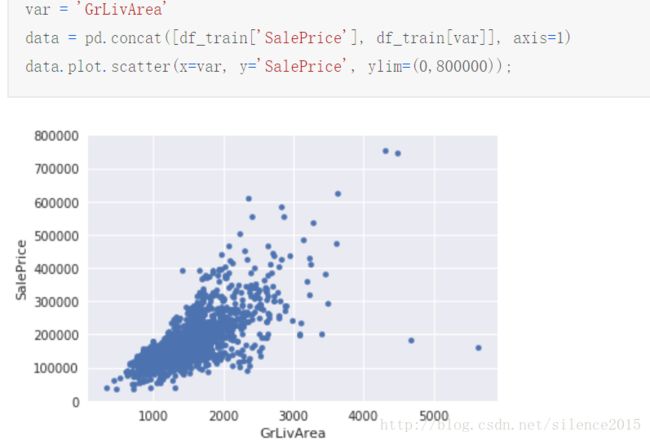
从上图可以发现几个疑似的离群点:右下角两个和右上角两个。右下角两个明显有问题,可做移除处理,右上角两个虽然远离大部队,但是他们总体还是符合属性和房价的线性分布趋势的,故可以留着。
最后要说的是Normality 、Homoscedasticity 、Linearity、Absence of correlated errors
这几个概念我在原文中还是没太能理解,但是原文中作者提出用log来修正数据分布,使得符合正态分布,貌似这样处理使得数据更容易分析和处理,数据更规范?(不太明白这块)
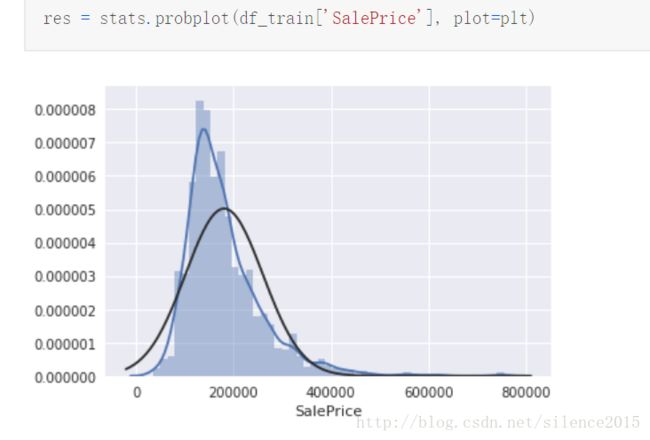

这儿有个例子解释了log使得分布正态化,原来GrLivArea和SalePrice分布是如下图,发现有明显的锥形部分
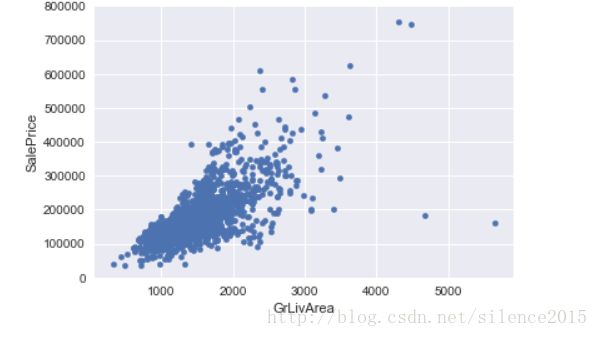
经历过正态化后,锥形分布不见了,数据分布更加自然、线性。

最后要说的就是类别型的数据要做one-hot编码。