C语言源程序词法分析器(Java实现)
一. 介绍
词法分析器,又称扫描器,输入源程序,进行词法分析,输出单词符号。词法分析仅仅是编译程序工作中的一部分,编译程序一般可以划分为5个阶段:词法分析,语法分析,语义分析与中间代码产生,优化,目标代码生成。我们这里编写一个简单的C语言源程序词法分析器。
二. 目的
设计并实现一个包含预处理功能的词法分析程序,加深对编译中词法分析过程的理解。
四. 要求
1、实现预处理功能
源程序中可能包含有对程序执行无意义的符号,要求将其剔除。
首先编制一个源程序的输入过程,从键盘、文件或文本框输入若干行语句,依次存入输入缓冲区(字符型数据);然后编制一个预处理子程序,去掉输入串中的回车符、换行符和跳格符等编辑性文字;把多个空白符合并为一个;去掉注释。
2、实现词法分析功能
输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。其中,
syn为单词种别码。
Token为存放的单词自身字符串。
Sum为整型常量。
具体实现时,可以将单词的二元组用结构进行处理。
3、待分析的C语言子集的词法
1)关键字
main if then while do static int double struct break else long switch case typedef char return const float short continue for void default sizeof do
所有的关键字都是小写。
2)运算符和界符
+ - * / : := < <> <= > >= = ; ( ) #
3)其他标记ID和NUM
通过以下正规式定义其他标记:
ID→letter(letter|digit)*
NUM→digit digit*
letter→a|…|z|A|…|Z
digit→0|…|9…
4)空格由空白、制表符和换行符组成
空格一般用来分隔ID、NUM、专用符号和关键字,词法分析阶段通常被忽略。
4、各种单词符号对应的种别码
单词符号 种别码 单词符号 种别码
main 1 void 23
if 2 sizeof 24
then 3 ID 25
while 4 NUM 26
do 5 + 27
static 6 - 28
int 7 * 29
double 8 / 30
struct 9 ** 31
break 10 == 32
else 11 < 33
long 12 <> 34
switch 13 <= 35
case 14 > 36
typedef 15 >= 37
char 16 = 38
return 17 [ 39
const 18 ] 40
float 19 ; 41
short 20 ( 42
continue 21 ) 43
for 22 # 0
五. 源代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class LexicalAnalyzer {
static String[] rwtab=new String[]{"main","if","then","while","do","static",
"int","double","struct","break","else",
"long","switch","case","typedef","char",
"return","const","float","short","continue",
"for","void","sizeof"}; //已经定义的24个关键字,种别码从1开始
static String storage=""; //存储源程序字符串
static StringBuilder token=new StringBuilder(""); //存储单词自身组成的字符串
static char ch;
static int index;
static int syn, sum=0, row;
//分析器
static void analyzer(){
token.delete(0, token.length()); //置空token对象,清除
ch=storage.charAt(index++);
while(ch==' '){
ch=storage.charAt(index++); //去除空格符号
}
if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){ //可能是关键字或者自定义的标识符
while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){
token.append(ch);
ch=storage.charAt(index++);
}
index--; //此次识别的最后一个字符未识别入,需要将标记退原处
syn=25; //默认为识别出的字符串为自定义的标识符,种别码为25
String s=token.toString();
for(int i=0; iif(s.equals(rwtab[i])){
syn=i+1;
break; //识别出是关键字
}
}
}
else if((ch>='0'&&ch<='9')){
sum=0;
while((ch>='0'&&ch<='9')){
sum=sum*10+ch-'0';
ch=storage.charAt(index++);
}
index--;
syn=26;
}
else switch(ch){
case '<':
token.append(ch);
ch=storage.charAt(index++);
if(ch=='='){
token.append(ch);
syn=35;
}
else if(ch=='>'){
token.append(ch);
syn=34;
}
else{
syn=33;
index--;
}
break;
case '>':
token.append(ch);
ch=storage.charAt(index++);
if(ch=='='){
token.append(ch);
syn=37;
}
else{
syn=36;
index--;
}
break;
case '*':
token.append(ch);
ch=storage.charAt(index++);
if(ch=='*'){
token.append(ch);
syn=31;
}
else{
syn=13;
index--;
}
break;
case '=':
token.append(ch);
ch=storage.charAt(index++);
if(ch=='='){
syn=32;
token.append(ch);
}
else{
syn=38;
index--;
}
break;
case '/':
token.append(ch);
ch=storage.charAt(index++);
if(ch=='/'){
while(ch!=' '){
ch=storage.charAt(index++); //忽略掉注释,以空格为界定
}
syn=-2;
break;
}
else{
syn=30;
index--;
}
break;
case '+':
syn=27;
token.append(ch);
break;
case '-':
syn=28;
token.append(ch);
break;
case ';':
syn=41;
token.append(ch);
break;
case '(':
syn=42;
token.append(ch);
break;
case ')':
syn=43;
token.append(ch);
break;
case '#':
syn=0;
token.append(ch);
break;
case '\n':
syn=-2;
token.append(ch);
break;
default:
syn=-1;
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
BufferedReader stdin=new BufferedReader(new InputStreamReader(System.in));
index=0;
row=1;
String tempString;
System.out.println("请输入C语言源程序字符串(以#结尾):");
//输入过程
try{
do{
tempString=stdin.readLine();
storage+=tempString;
ch=tempString.charAt(tempString.length()-1); //得到一行中最后一个字符
}while(ch!='#'); //输入以#字符结尾
}catch(IOException e){
e.printStackTrace();
}
index=0;
//输出过程
do{
analyzer();
switch(syn){
case 26:
System.out.println("("+syn+","+sum+")");
break;
case -1:
System.out.println("Error in row"+row+"!");
break;
case -2:
break;
default:
System.out.println("("+syn+","+token+")");
}
}while(syn!=0);
}
}
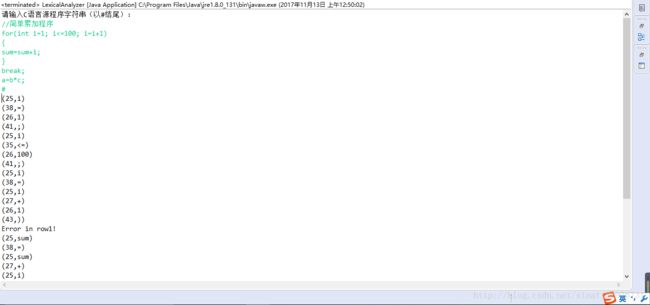
六. 运行结果