【Airbnb搜索】:Real-time Personalization using Embeddings for Search Ranking at Airbnb
原始论文下载地址:
本文是kdd 2018 的best paper,文章来自airbnb的搜索推荐团队,描述的是airbnb如何使用embedding来提高搜索和排序的效果。
知乎有官方认证的中文文章(文章地址,原始论文)。文章利用搜索的session数据来获取Listing和用户的embedding,全文思想相对来说还是比较简单的,但是整体针对业务实际情况,一步步的解决问题的思路很清晰,和airbnb之前发的“Applying Deep Learning To Airbnb Search”这篇论文一样,将他们算法应用和改进到实际业务中的探索过程都讲的非常清晰,非常适合在一线开发的人员阅读。
最后的学习type级别的embedding,其实也可以扩展用来学习冷启动的一些embedding,不知道效果会不会也不错。下面就开始介绍一下。
airbnb是一个双端的房屋短租平台,用户通过搜索或者平台的推荐来找到喜欢的房源。因为一个用户很少会预定同一个房源多次,一个房源(后面就用listing来代替)在一个时间段内只能被一个用户租赁,所以该平台的数据存在严重的稀疏问题。本文主要针对airbnb在搜索排序和推荐的实时个性化中设计了一套listing和user的embedding。embedding学习过程将搜索session中数据看作类似序列信息,并通过类似word2vec的方式学习出每个房源id的embedding值,从而在有效学习出房源的多种特征外,还很好的结合到了自身的业务。
搜索的目标根据业务不同需求也不同。有的是为了点击率,有的是为了新闻的观看时长,还有的是为了提高商品购买的转化率等等。而airbnb作为一个双端市场,需要同时为市场两端用户提高搜索的性能,即那些买(guest)和卖的(host)。这类市场的内容发现和搜索排名需要同时满足生态系统的供需双方,才能发展和繁荣。
在airbnb中,需要同时为host和guest优化搜索结果,比如输入一query,query带有位置和旅行的时间,那么我们就需要根据位置,价格,类型,评论等因素排序来获得客户喜欢的listing。进一步,还需要过滤掉那些有坏的评论,宠物,停留时间,人数,等其他因素而拒绝guest的listing,将这些listing排列的低一点。为了解决这个问题,作者团队采用Learnig to rank来做,将该问题形式化为pairwise regression问题,将预定的listing作为正样本,拒绝的作为负样本。
因为guest通常在预定前进行多次的搜索,即点击多个listing,并且联系其中的多个host,这就可以进一步利用点击,联系信息等等来做实时的个性化,以此来展示更多他们可能喜欢的listing。于此同时也可以进一步利用一些负反馈,比如他们跳过的排名靠前的listing,以此来减少他们可能不喜欢的listing。为了能够计算listing和guest之间的相似性,本文团队采用了一个从搜索交互session中学习得到的embedding来表示listing。并利用这些相似性来为搜索排序模型和推荐系统提供个性化特征。
除了使用即时用户交互的实时个性化,比如一些点击,这些可以被认为是用户的短期兴趣,作者还介绍了另外一种embedding方法,从预定信息中捕获用户的长期兴趣。考虑到旅行商业的特殊性,一个用户平均一年通常只会旅行1-2次,所以预定listing是一个很稀疏的信号,他拥有很大一块长尾的单次预定信息。为了解决这块问题,作者使用用户类型来学习用户的embedding,而不是直接通过用户的embedding,而这里的用户类型是类似于根据用户的一些已知属性来对用户分成很个类别。于此同时在相同的向量空间下,学习出listing的类型embedding。这使得用户和listing之间的相似性计算变得方便。
本文贡献:
1.实时个性化:之前一些文献做的个性化和推荐embedding都是通过离线构造user-item交互和item-item来做离线推荐。并在推荐的时候读取数据。本文实现了用户最近交互的item embedding是被结合到在线的方式去计算item之间的相似性。
2.适应集中式搜索的训练方式:不像一般的网站搜索,旅行平台的搜索都先对比较集中,比如如果是搜索的巴黎,那么就很少会跨域进行搜索,所以为了更好的捕获同一市场内的listing相似性,在模型的负采样中做了一定的优化。
3.利用转化来作为全局上下文:作者认为那些以转化成功结束(就是被预定的)的点击session更加重要,在学习listing embedding的时候将预定的listing 作为全局上下文,在滑动窗口在整个session中移动的时候总能被预测。
4.用户类型embedding:之前的工作很大都是给每个id训练一个embedding,但是当用户行为很稀疏的时候,是没有办法训练出一个好的embedding的,而且为每个用户存储embedding值,对实时计算来说,需要将embedding存储在内存中,是相当费内存的。而我们只去学习用户类型的embdding,这样同一个类型的用户就会拥有相同的embedding值。
5. 拒绝作为明确的负反馈:所谓拒绝就是说曝光在头部的数据,但是用户却没有点或者预定,为了尽量减少导致拒绝的推荐,作者在为用户和listing编码的时候将host的喜好作为负反馈加入到用户和listing的embedding中。
Listing Embedding
训练数据集的构造:数据集由N个用户的点击Session组成,其中每个session ![]() 表示的是用户点击的n个listing id序列。其中时间间隔超过30分钟的,就需要被分成两个session。给定数据集,目标就是通过集合S,学习出每个listing的d维的向量,让相似listing在embedding空间的距离更近。这里定义的embedding维度为32,低纬度的设置可以在模型上线后让实时召回的速度更快。
表示的是用户点击的n个listing id序列。其中时间间隔超过30分钟的,就需要被分成两个session。给定数据集,目标就是通过集合S,学习出每个listing的d维的向量,让相似listing在embedding空间的距离更近。这里定义的embedding维度为32,低纬度的设置可以在模型上线后让实时召回的速度更快。
这里提出的方法其实很简单,就是类似将session看着一个句子,然后采用类似word2vec的方式把session中的每个id看着一个词,来学习每个id的embedding。我们可以把该模型先理解为skipgram模型。如下图所示:

从上图可以看出来,相比正常的skipgram,这里它做了一些改变,它把session中被预定的listing作为一个全局的上下文始终出现在每次的滑动窗口中。具体的改进可以总结为两点:
1.使用session被预定的listing作为全局上下文(Global Context):全局上下文什么意思呢?其实就是比如我们在训练skipgram的时候,学习每个词的时候,根据设置的大小,只会选择每个词前后n个词作为正样本,所以随着窗口的滑动,窗口内的词是一直在变的,而这个全局上下文就是这个listing id一直存在与该session的滑动窗口内。
2.适配聚集搜索:因为一个人的旅行目的地通常在确定后,房源的租赁都会限制在该目的地内,因此在模型训练时,对于正在训练的中心listing来说,它的负样本不应该是其他地区的listing,而应该是在同一个区域内的房源,因为一个人只会在同一个区内进行比较不同listing的好坏。所以针对这个问题,模型在进行负采样的时候并不是从全部的listing中抽样,而是从训练的中心listin的同一区域内进行随机的抽样作为负样本。
所以最终的优化目标就变成了:
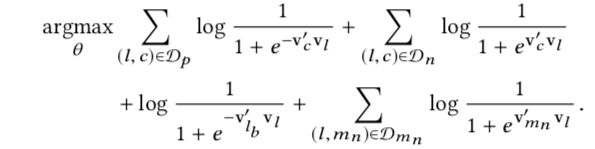
具体参数解释如下:

其实整个公式,上半部分就是原始的是kipgram需要优化的目标,而下半部分为本文加入的东西,分别为全局上下文和同区域内的采样。
冷启动 Listing Embedding
冷启动问题在任何推荐系统中都是在所难免的,对于冷启动的Listing,这里采用了一个近似取值的方法,即对于刚组成的Listing,获取其原始的特征,如位置,价格等,然后去找到其最近的三个Listing,将最近的三个Listing embedding 平均后作为其Embedding值。这样基本能覆盖到98%的新Listing。
评估 Listing Embedding
为了检验embedding的效果,文章用了多种方法从多个角度来进行验证。
1.K-means 聚类,将embdding进行聚类,然后可以发现其在地理位置上的区分度。如下图:

2. embeddng之间的余弦距离度量
在不同类型的listing之间计算余弦距离,不同价格范围的listing之间计算余弦距离,结果如下:

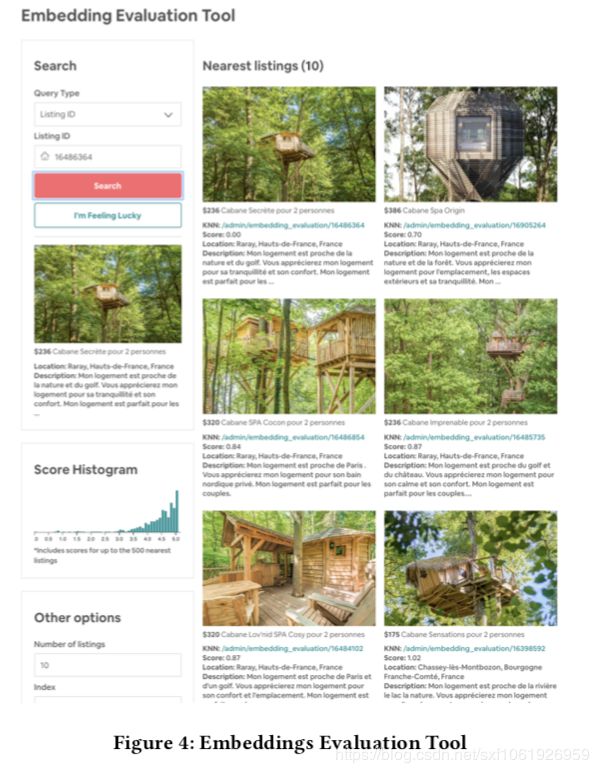
效果还是有的。当然这些价格,地理位置的特征其实都是一些基础的属性,是可以直接获取的属性,但是embedding其实不光学到来这些,而是将所有影响用户点击的属性都包含在来embedding内,很多可能都无法直接度量。这里还展示来一个他们自己研究的用来评估embedding学习纹理的工具,结果如下:
用户类型 Embedding 和Listing类型 Embedding
前面描述的Listing embedding 能很好的表达同一市场下Listing之间的相似性,所以他们很适合做短期的个性化,用于比较session内的实时推荐。但是一些长期的行为,比如一个人在很久之前在另外一个城市预定过房间,那么现在在当前城市很有可能还是会喜欢预定同类型的房源。所以进一步从预定的Listing中来捕获这些信息。
构造数据集:由前面的点击序列变成预定序列,数据集为N个用户预定的Listing 组成的session集合。每个sesison可以表示为![]() 是用户的预定listing序列。
是用户的预定listing序列。
但是用这种方式训练存在很多问题:
1.训练数据集会很小,因为相比点击,预定的数据会小一个量级。
2.很多用户在过去只预定过一次,这些数据是没法用来训练模型的。
3.需要进一步去掉那些在平台上总共就被预定的次数很少的Listing。比如少于5-10次的Listing。
4.长时间的跨度,可能用户的喜欢已经一些习惯已经发生变化。
为了处理这些问题,提出了学习类型级别的embedding学习,而不是去学习id级别的embedding。给定Listing的原始数据,比如位置,价格,类型,床位数等等,然后给定一些硬性的规则生成每个Listing的类别,如下图

这样原本稀疏的数据,将id变成类型后,很多session出现了共现。
同样,用户的embedding方式也用了相同的方法,将拥有一些相同的基础属性和相同行为的用户也进行了分桶,如下图所示:

其实可以理解为,分别对用户和房源做了聚类,按聚类后的数据进行学习embedding,以此来获取粗粒度的长期兴趣。
基于Embedding的实时个性化
首先,embedding的训练是设置的训练数据像窗口一样,按天前进。设置好窗口大小后按天进行训练。
实时个性化主要分两边,一块是从候选集中实时对比每个候选集和用户相关listing的相似度,再将相似度分值作为特征,进一步作为排序模型的特征,对候选集进一步重排序。
如何实时收集用户短期行为,aitbnb团队采用kafka消息队列来收集用户的两个历史记录:
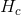 : 用户过去两周内点击过的Listing id
: 用户过去两周内点击过的Listing id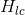 : 用户点击并且停留在listing详情页超过60s
: 用户点击并且停留在listing详情页超过60s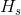 : 用户过去两周内跳过的Listing id(跳过的定义是那些排在前面但是用户没有点,反而点了后面的Listing)
: 用户过去两周内跳过的Listing id(跳过的定义是那些排在前面但是用户没有点,反而点了后面的Listing)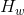 : 用户添加到期望列表
: 用户添加到期望列表- : 用户联系了但是没有预定
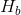 : 两周内用户预定的
: 两周内用户预定的
有了这两个规则后,就可以获得一批Listing id,然后根据这批Listing id,利用整个Hc的embedding均值和候选集Listing 的相似度表。这样就可以获得每个H*和候选listing embedding的相似度,然后把这些相似度分别作为特征,进一步的放到后一层的排序模型中对候选集进行排序。当然最后的排序模型还用到了其他的特征,比如用户类型和lsiting 类型级别的embedding相似度,以及其他的一些基础特征等等。