python使用OpenCV-Python结合百度图像识别api实现图片中的文字识别
上篇文章写了利用百度api实现图像识别提取图片上的文字,但是发现不是那么准确,所以现在结合OpenCV-Python找出图片上的文字,再把需要的文字切分出来,再调用接口识别,这样就会精确很多,附上参考的资料,多不多说,开干。
1.读取文件,并专成灰度图
imagePath = "20190610181452.png"
img = cv2.imread(imagePath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
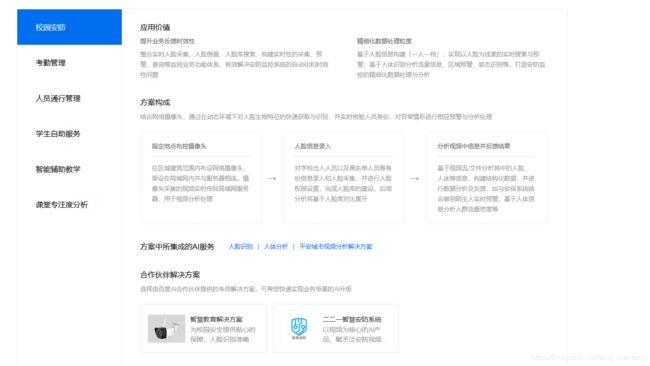

2.形态学变换的预处理,得到可以查找矩形的图片
sobel = cv2.Sobel(gray, cv2.CV_8U, 1, 0, ksize = 3)
cv2.imshow('sobel',sobel)
cv2.waitKey()
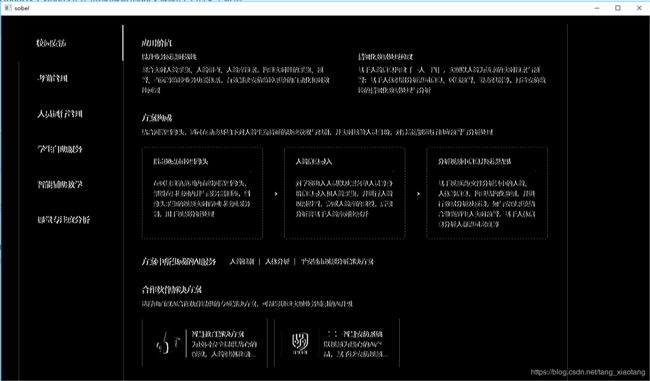
3.二值化并设置膨胀和腐蚀操作的核函数
#二值化
ret, binary = cv2.threshold(sobel, 0, 255, cv2.THRESH_OTSU+cv2.THRESH_BINARY)
# 设置膨胀和腐蚀操作的核函数
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (30, 9))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (24, 6))
4.膨胀一次,让轮廓突出
dilation = cv2.dilate(binary, element2, iterations = 1)

5.腐蚀一次,去掉细节,如表格线等。注意这里去掉的是竖直的线
erosion = cv2.erode(dilation, element1, iterations = 1)
 6.再次膨胀,让轮廓明显一些
6.再次膨胀,让轮廓明显一些
dilation2 = cv2.dilate(erosion, element2, iterations = 3)
7.查找和筛选文字区域
region = []
# 查找轮廓
contours, hierarchy = cv2.findContours(dilation2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 利用以上函数可以得到多个轮廓区域,存在一个列表中。
# 筛选那些面积小的
for i in range(len(contours)):
# 遍历所有轮廓
# cnt是一个点集
cnt = contours[i]
# 计算该轮廓的面积
area = cv2.contourArea(cnt)
# 面积小的都筛选掉、这个1000可以按照效果自行设置
if(area < 1000):
continue
# # 将轮廓形状近似到另外一种由更少点组成的轮廓形状,新轮廓的点的数目由我们设定的准确度来决定
# # 轮廓近似,作用很小
# # 计算轮廓长度
# epsilon = 0.001 * cv2.arcLength(cnt, True)
# #
# # approx = cv2.approxPolyDP(cnt, epsilon, True)
# 找到最小的矩形,该矩形可能有方向
rect = cv2.minAreaRect(cnt)
# 打印出各个矩形四个点的位置
# print ("rect is: ")
# print (rect)
# box是四个点的坐标
box = cv2.boxPoints(rect)
box = np.int0(box)
# 计算高和宽
height = abs(box[0][1] - box[2][1])
width = abs(box[0][0] - box[2][0])
# 筛选那些太细的矩形,留下扁的
if(height > width * 1.3):
continue
region.append(box)
# 用绿线画出这些找到的轮廓
for box in region:
cv2.drawContours(img, [box], 0, (0, 255, 0), 2)
print(box)
# plt.imshow(img, 'brg')
# plt.show()
# 弹窗显示
cv2.namedWindow("img", cv2.WINDOW_NORMAL)
cv2.imshow("img", img)
# 带轮廓的图片
cv2.waitKey(0)
cv2.destroyAllWindows()

8.把绿色框切分出来并保存
Xs = [i[0] for i in box]
Ys = [i[1] for i in box]
x1 = min(Xs)
x2 = max(Xs)
y1 = min(Ys)
y2 = max(Ys)
hight = y2 - y1
width = x2 - x1
crop_img: object = img[y1:y1 + hight, x1:x1 + width]
print('result/%d'%i+'.jpg')
# im=cv2.imshow('crop_img', crop_img)
cv2.imwrite('result/%d'%i+'.jpg',crop_img,[int(cv2.IMWRITE_JPEG_QUALITY),70])

9.再用这些切分出来的小图片请求百度api就行了,上篇已经讲过了,传送门
完成代码
# coding:utf8
import numpy as np
import cv2
# 读取文件
imagePath = "1560.png"
img = cv2.imread(imagePath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# cv2.imshow('img',gray)
# cv2.waitKey()
# 此步骤形态学变换的预处理,得到可以查找矩形的图片
# 参数:输入矩阵、输出矩阵数据类型、设置1、0时差分方向为水平方向的核卷积,设置0、1为垂直方向,ksize:核的尺寸
sobel = cv2.Sobel(gray, cv2.CV_8U, 1, 0, ksize = 3)
# cv2.imshow('sobel',sobel)
# cv2.waitKey()
# 二值化
ret, binary = cv2.threshold(sobel, 0, 255, cv2.THRESH_OTSU+cv2.THRESH_BINARY)
# 设置膨胀和腐蚀操作的核函数
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (30, 9))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (24, 6))
# 膨胀一次,让轮廓突出
dilation = cv2.dilate(binary, element2, iterations = 1)
cv2.imshow('dilation',dilation)
cv2.waitKey()
# 腐蚀一次,去掉细节,如表格线等。注意这里去掉的是竖直的线
erosion = cv2.erode(dilation, element1, iterations = 1)
cv2.imshow('erosion',erosion)
cv2.waitKey()
# aim = cv2.morphologyEx(binary, cv2.MORPH_CLOSE,element1, 1 ) #此函数可实现闭运算和开运算
# 以上膨胀+腐蚀称为闭运算,具有填充白色区域细小黑色空洞、连接近邻物体的作用
# 再次膨胀,让轮廓明显一些
dilation2 = cv2.dilate(erosion, element2, iterations = 3)
# 显示膨胀一次后的图像处理效果
# plt.imshow(dilation2,'gray')
#
# # 显示一次闭运算后的效果
# plt.imshow(erosion,'gray')
#
# # 显示连续膨胀3次后的效果
# plt.imshow(dilation2,'gray')
# 查找和筛选文字区域
region = []
# 查找轮廓
contours, hierarchy = cv2.findContours(dilation2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 利用以上函数可以得到多个轮廓区域,存在一个列表中。
# 筛选那些面积小的
for i in range(len(contours)):
# 遍历所有轮廓
# cnt是一个点集
cnt = contours[i]
# 计算该轮廓的面积
area = cv2.contourArea(cnt)
# 面积小的都筛选掉、这个1000可以按照效果自行设置
if(area < 1000):
continue
# # 将轮廓形状近似到另外一种由更少点组成的轮廓形状,新轮廓的点的数目由我们设定的准确度来决定
# # 轮廓近似,作用很小
# # 计算轮廓长度
# epsilon = 0.001 * cv2.arcLength(cnt, True)
# #
# # approx = cv2.approxPolyDP(cnt, epsilon, True)
# 找到最小的矩形,该矩形可能有方向
rect = cv2.minAreaRect(cnt)
# 打印出各个矩形四个点的位置
# print ("rect is: ")
# print (rect)
# box是四个点的坐标
box = cv2.boxPoints(rect)
box = np.int0(box)
# 计算高和宽
height = abs(box[0][1] - box[2][1])
width = abs(box[0][0] - box[2][0])
# 筛选那些太细的矩形,留下扁的
if(height > width * 1.3):
continue
region.append(box)
# 用绿线画出这些找到的轮廓
for box in region:
cv2.drawContours(img, [box], 0, (0, 255, 0), 2)
print(box)
# plt.imshow(img, 'brg')
# plt.show()
Xs = [i[0] for i in box]
Ys = [i[1] for i in box]
x1 = min(Xs)
x2 = max(Xs)
y1 = min(Ys)
y2 = max(Ys)
hight = y2 - y1
width = x2 - x1
crop_img: object = img[y1:y1 + hight, x1:x1 + width]
print('result/%d'%i+'.jpg')
# im=cv2.imshow('crop_img', crop_img)
cv2.imwrite('result/%d'%i+'.jpg',crop_img,[int(cv2.IMWRITE_JPEG_QUALITY),70])
# 弹窗显示
cv2.namedWindow("img", cv2.WINDOW_NORMAL)
cv2.imshow("img", img)
# 带轮廓的图片
cv2.waitKey(0)
cv2.destroyAllWindows()