Haar+adaboost物体检测算法知识点归纳总结
基于此方法研究车牌识别系统相关应用,以下主要总结其中的关键点和难点,需要对haar特征和adaboost原理有一定了解,供刚开始学习和使用此法的童鞋参考,肯定不够全面,亦或存在不够准确的地方,诸位可指出,交流补充。
一、训练
1、训练模型是很重要的一环,训练haar+adaboost模型其实就是挑选特征,再组合特征的过程。
2、训练样本准备:正样本,负样本,更新样本。正样本和负样本的大小比例应接近于你需要训练的模型的大小比例。比如就车牌而言,你要训练宽高比为60:15的模型,那正负样本图像最好都接近这一比例,越接近越好。因为在训练过程中都会把样本缩放到60:15这一尺度进行计算特征值。当然,监督学习中,这里正样本就是车牌图像,负样本则是不包含车牌的图像,为了适应不同环境下的车牌检测,则正样本分布需要多样性,比如正常光线的,反光的,模糊的,暗的都有(当然这样一般会提高误检率,看实际需求调整),而负样本同样需要不同背景。正样本整理比较严格,对车牌不同的截取方式,可能导致最后模型效果差异大。比如截取的车牌样本是有车牌框的还是没有,是紧贴字符还是较宽松,如图1所示。

![]()
![]()
图 1
当然正样本的整理是根据应用需要进行的,不同的应用肯定有差异。还有一个更新样本,这个在网络上比较少介绍,后面会详细说明。更新样本和负样本类似但不相同,更新样本不需要在大小比例上接近模型尺寸,但尽量用大图,且图像需要复杂多样不包含车牌。
此外,还有一个经常会听到的词:难例。或者说困难样本。参考这里,简单来说就是你训练完一个模型了,拿一个测试集来测试,则可能会检测到不是目标的区域,那这些区域保存下来就是困难样本,收集这些后组成一个负样本集,再次进行训练,这样不断加强模型的性能。
3、训练前预挑选特征。使用5种常见的haar特征,在30*30的尺度上,特征就有394725个,具体计算看这里,所以考虑实时,可以先预挑选一些特征出来,再对这些特征进行再次挑选。不管是预挑选还是后面训练弱分类器,实质都是在挑选强区分能力靠前的那些特征。那如何预挑选特征?依据是什么?前面也说了,依据当然是看特征的区分能力,问题转变为如何判断特征的区分能力。看这篇。
假设进行人脸检测,现在有正样本2706,负样本4381个,在使用的haar特征中,随机抽取了两个特征A和B,这两个特征遍历了2,706 个人脸样本和4,381 个非人脸样本,计算了每张图像对应的特征值,即每个特征对应有7087个特征值,将特征值进行了从小到大的排序,并按照这个新的顺序表绘制了分布图如下所示:
人脸和非人脸特征值分布曲线其实就是正样本和负样本基于A特征的特征值的样本分布曲线。
特征A人脸和非人脸样本的分布曲线虽然在过零点位置上差异大(因为正负样本数量不一样),但是过零点位置的左右区间的曲线走势是接近的,所以A对人脸和非人脸的区分能力一般。
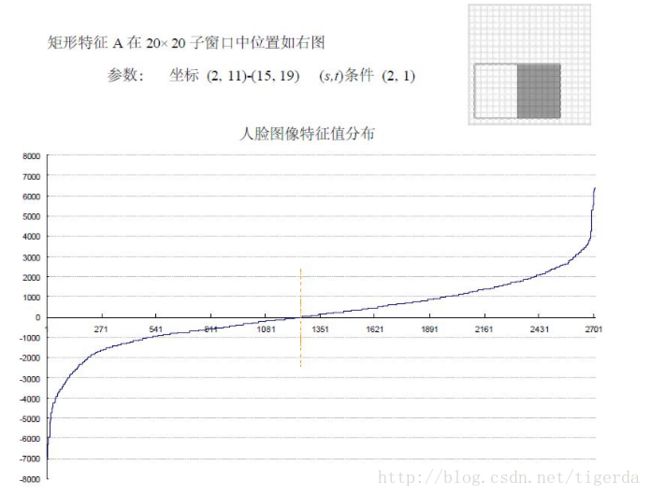
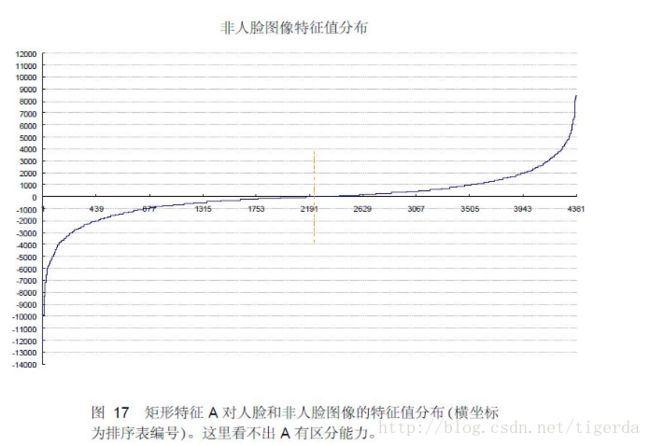
图 2
下面看B特征的情况, 特征B人脸和非人脸样本的分布曲线过零点位置的左右区间的曲线走势是有明显差异的,所以相比于特征A,特征B对人脸和非人脸的区分能力更强。

非人脸图像特征值分布

图 3
这里分别从正负样本特征值的分布情况来看特征的分辨能力,其实也可以把7087个特征值排序后的分布曲线画出来,通过统计其他量来作为分辨能力依据。所以这里是一个研究点。
4、每个特征其实就是一个弱分类器,通常说训练弱分类器,其实就是挑选最优弱分类器,最优弱分类器的分类误差是最小的。现在需要得到T个最优弱分,即需迭代T次训练,每次得到一个。T个最优弱分加权求和得到一个强分类器,n个强分类器又级联成一个更强的级联分类器。比如一个级联分类器,我们设置为20层,每一层即为一个强分类器,那么每一个强分类器中的弱分,就是上面说的迭代训练生成,其中迭代过程中每次训练都会对样本的权值进行重新计算,那样,样本数量虽然没变,但是每个样本的权值变了,可以看成样本分布变了,所以每次训练才会有不同的最优弱分出现。权值的修改机制就是弱分训练的核心。
5、再次说到更新样本。更新样本机制是级联分类器中层与层之间的机制。一般开始训练前我们设置一些训练参数,例如强分类器(每个stage,每一层)的识别率99%,错分率为50%。训练过程中,当分类器达到识别率这个指标时(不一定是训练结束的唯一目标),则训练结束。错分率为50%,即可能有50%的负样本被判断为是目标,另50%的负样本被正确判断为是非目标,根据adaboost的机制,被正确判断的负样本进行丢弃,也就是现在负样本剩下一半,那就要补充负样本了。例如:现在训练完第1 stage,在进入第2 stage前要更新负样本,假设原来负样本100个,现在只剩下30个(负样本的筛选机制也有不同情况,有的机制是一定以50%进行筛选),则要补充一定数量负样本(不一定是70个)进去,才能满足开始时设定的正负样本比例。这时更新样本登场了。前面训练完成的一个强分类器对更新样本集进行检测,判断为目标的则保存为负样本,补充进去,直到数量达到要求(就是当前正样本和负样本比例和初始设定的一样,或者丢弃多少补多少)。为什么正样本不用补充?因为识别率设置为99%,即很少的正样本被丢弃。正样本数量不用补充,但是其权值会更新,同样改变了样本分布。所以更新样本集的数量必须要足够多。可以看这里,也进行了讨论,博主说不是补充样本而是更新,个人认为应该是一样的,说法 不一样,还有博主没提到更新样本,个人认为只是训练时样本补充机制设置不一样而已。
6、从训练情况看,训练样本非常重要。一般需要多次尝试,不断添加困难样本,才能训练出比较好的模型。
二、检测
1、在模型正常训练完成的情况下,影响检测效果的因素有很多,其中有几个常见的:尺度变化步长,检测窗口滑动步长和检测的机制。
2、滑动步长和尺度变换步长比较好理解,可以通过简单调整知道哪种步长对检测效果最好。一般是步长越小,检测率越好,但是要考虑到误检和时间问题。所以找一个平衡点。
3、检测机制。一般有两种,一是被检测对象大小不变,改变检测窗口尺度。二是检测窗口尺度不变,通过改变图像大小。这里用第一种(考虑效率问题)。一般是训练的检测模型的尺度为起始尺度 ,逐渐放大。尺度范围需能覆盖被检测目标的尺寸范围。还有一种情况,在训练时,模型的尺度设定是小点好还是大点好,比如训练车牌检测模型,是60:15好,还是120:30好?如果模型尺度是120:30,那么在检测时,必然要从120:30这个尺度向两边进行尺度变化,因为有的车牌宽度不到120,那么这时的模型对于小于120的车牌,检测效果不一定好。因为在训练时用120:30的模型,这个模型中计算出的特征和用模型60:15时计算的特征是不一样的,即以大尺度模型进行训练时,小于模型尺度的有区分能力的的特征不一定被挑选出来。
4、假设训练的模型为60:15, 检测窗口最小尺度(m1)为60:15,最大尺度(m2)为240 :60,则从m1开始到m2进行检测和从m2开始到m1进行检测,效果是一样的。
暂时到这里,后续如果有心得会继续补充。
reference
1、http://blog.csdn.net/watkinsong/article/details/7631241.
2、http://blog.csdn.net/zhaocj/article/details/54015501#comments.
3、http://blog.csdn.net/masibuaa/article/details/16113373?utm_source=tuicool&utm_medium=referral.
4、http://blog.csdn.net/zouxy09/article/details/7922923