目录
- Logistic回归(鸢尾花分类)
- 一、导入模块
- 二、获取数据
- 三、构建决策边界
- 四、训练模型
- 4.1 C参数与权重系数的关系
- 五、可视化
更新、更全的《机器学习》的更新网站,更有python、go、数据结构与算法、爬虫、人工智能教学等着你:https://www.cnblogs.com/nickchen121/p/11686958.html
Logistic回归(鸢尾花分类)
一、导入模块
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib.font_manager import FontProperties
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')二、获取数据
iris_data = datasets.load_iris()
X = iris_data.data[:, [2, 3]]
y = iris_data.target
label_list = ['山鸢尾', '杂色鸢尾', '维吉尼亚鸢尾']三、构建决策边界
def plot_decision_regions(X, y, classifier=None):
marker_list = ['o', 'x', 's']
color_list = ['r', 'b', 'g']
cmap = ListedColormap(color_list[:len(np.unique(y))])
x1_min, x1_max = X[:, 0].min()-1, X[:, 0].max()+1
x2_min, x2_max = X[:, 1].min()-1, X[:, 1].max()+1
t1 = np.linspace(x1_min, x1_max, 666)
t2 = np.linspace(x2_min, x2_max, 666)
x1, x2 = np.meshgrid(t1, t2)
y_hat = classifier.predict(np.array([x1.ravel(), x2.ravel()]).T)
y_hat = y_hat.reshape(x1.shape)
plt.contourf(x1, x2, y_hat, alpha=0.2, cmap=cmap)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
for ind, clas in enumerate(np.unique(y)):
plt.scatter(X[y == clas, 0], X[y == clas, 1], alpha=0.8, s=50,
c=color_list[ind], marker=marker_list[ind], label=label_list[clas])四、训练模型
# C与正则化参数λ成反比,即减小参数C增大正则化的强度
# lbfgs使用拟牛顿法优化参数
# 分类方式为OvR(One-vs-Rest)
lr = LogisticRegression(C=100, random_state=1,
solver='lbfgs', multi_class='ovr')
lr.fit(X, y)LogisticRegression(C=100, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr',
n_jobs=None, penalty='l2', random_state=1, solver='lbfgs',
tol=0.0001, verbose=0, warm_start=False)4.1 C参数与权重系数的关系
weights, params = [], []
for c in np.arange(-5, 5):
lr = LogisticRegression(C=10.**c, random_state=1,
solver='lbfgs', multi_class='ovr')
lr.fit(X, y)
# lr.coef_[1]拿到类别1的权重系数
weights.append(lr.coef_[1])
params.append(10.**c)
# 把weights转为numpy数组,即包含两个特征的权重的数组
weights = np.array(weights)
'''
params:
[1e-05, 0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0, 10000.0]
'''
'''
weights:
[[ 2.50572107e-04 6.31528229e-05]
[ 2.46565843e-03 6.15303747e-04]
[ 2.13003731e-02 4.74899392e-03]
[ 9.09176960e-02 -1.80703318e-03]
[ 1.19168871e-01 -2.19313511e-01]
[ 8.35644722e-02 -9.08030470e-01]
[ 1.60682631e-01 -2.15860167e+00]
[ 5.13026897e-01 -2.99137299e+00]
[ 1.14643413e+00 -2.79518356e+00]
[ 1.90317264e+00 -2.26818639e+00]]
'''
plt.plot(params, weights[:, 0], linestyle='--', c='r', label='花瓣长度(cm)')
plt.plot(params, weights[:, 1], c='g', label='花瓣长度(cm)')
plt.xlabel('C')
# 改变x轴的刻度
plt.xscale('log')
plt.ylabel('权重系数', fontproperties=font)
plt.legend(prop=font)
plt.show()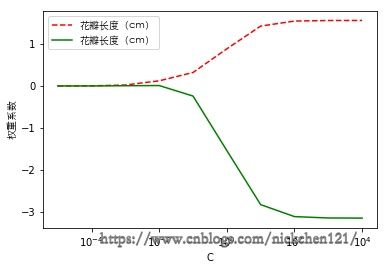
上图显示了10个不同的逆正则化参数C值拟合逻辑回归模型,此处只收集标签为1(杂色鸢尾)的权重系数。由于数据没有经过处理,所以显示的不太美观,但是总体趋势还是可以看出减小参数C会增大正则化强度,在\(10^{-3}\)的时候权重系数开始收敛为0。
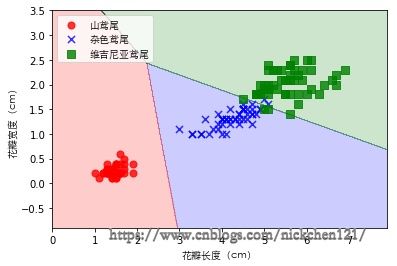
五、可视化
plot_decision_regions(X, y, classifier=lr)
plt.xlabel('花瓣长度(cm)', fontproperties=font)
plt.ylabel('花瓣宽度(cm)', fontproperties=font)
plt.legend(prop=font)
plt.show()