轻量级网络--ShuffleNet论文解读
ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
原文地址: ShuffleNet
代码:
- TensorFlow
- Caffe
Abstract
论文介绍一个效率极高的CNN架构ShuffleNet,专门应用于计算力受限的移动设备。新的架构利用两个操作:逐点群卷积(pointwise group convolution)和通道混洗(channel shuffle),与现有先进模型相比在类似的精度下大大降低计算量。在ImageNet和MS COCO上ShuffleNet表现出比其他先进模型的优越性能。
Introduction
现许多CNNs模型的发展方向是更大更深,这让深度网络模型难以运行在移动设备上,针对这一问题,许多工作的重点放在对现有预训练模型的修剪、压缩或使用低精度数据表示。
论文中提出的ShuffleNet是探索一个可以满足受限的条件的高效基础架构。论文的Insight是现有的先进basic架构如 X c e p t i o n Xception Xception和 R e s N e X t ResNeXt ResNeXt在小型网络模型中效率较低,因为大量的 1 × 1 1×1 1×1卷积耗费很多计算资源,论文提出了逐点群卷积(pointwise group convolution)帮助降低计算复杂度;但是使用逐点群卷积会有幅作用,故在此基础上,论文提出通道混洗(channel shuffle)帮助信息流通。基于这两种技术,我们构建一个名为ShuffleNet的高效架构,相比于其他先进模型,对于给定的计算复杂度预算,ShuffleNet允许使用更多的特征映射通道,在小型网络上有助于编码更多信息。
论文在ImageNet和MS COCO上做了相关实验,展现出ShuffleNet设计原理的有效性和结构优越性。同时论文还探讨了在真实嵌入式设备上运行效率。
Related Work
-
高效模型设计: CNNs在CV任务中取得了极大的成功,在嵌入式设备上运行高质量深度神经网络需求越来越大,这也促进了对高效模型的探究。例如,与单纯的堆叠卷积层,GoogleNet增加了网络的宽度,复杂度降低很多;SqueezeNet在保持精度的同时大大减少参数和计算量;ResNet利用高效的bottleneck结构实现惊人的效果。Xception中提出深度可分卷积概括了Inception序列。MobileNet利用深度可分卷积构建的轻量级模型获得了先进的成果;ShuffleNet的工作是推广群卷积(group convolution)和深度可分卷积(depthwise separable convolution)。
-
模型加速: 该方向旨在保持预训练模型的精度同时加速推理过程。常见的工作有:通过修剪网络连接或减少通道数减少模型中连接冗余;量化和因式分解减少计算中冗余;不修改参数的前提下,通过FFT和其他方法优化卷积计算消耗;蒸馏将大模型的知识转化为小模型,是的小模型训练更加容易;ShuffleNet的工作专注于设计更好的模型,直接提高性能,而不是加速或转换现有模型。
Approch
针对群卷积的通道混洗(Channel Shuffle for Group Convolutions)
现代卷积神经网络会包含多个重复模块。其中,最先进的网络例如Xception和ResNeXt将有效的深度可分离卷积或群卷积引入构建block中,在表示能力和计算消耗之间取得很好的折中。但是,我们注意到这两个设计都没有充分采用 1 × 1 1×1 1×1的逐点卷积,因为这需要很大的计算复杂度。例如,在ResNeXt中 3 × 3 3×3 3×3卷积配有群卷积,逐点卷积占了93.4%的multiplication-adds。
在小型网络中,昂贵的逐点卷积造成有限的通道之间充满约束,这会显著的损失精度。为了解决这个问题,一个直接的方法是应用通道稀疏连接,例如组卷积(group convolutions)。通过确保每个卷积操作仅在对应的输入通道组上,组卷积可以显著的降低计算损失。然而,如果多个组卷积堆叠在一起,会有一个副作用: 某个通道输出仅从一小部分输入通道中导出,如下图(a)所示,这样的属性降低了通道组之间的信息流通,降低了信息表示能力。

如果我们允许组卷积能够得到不同组的输入数据,即上图(b)所示效果,那么输入和输出通道会是全关联的。具体来说,对于上一层输出的通道,我们可做一个混洗(Shuffle)操作,如上图©所示,再分成几个组,feed到下一层。
对于这个混洗操作,有一个有效高雅(efficiently and elegantly)的实现:
对于一个卷积层分为 g g g组,
- 1.有 g × n g×n g×n个输出通道
- 2.reshape为 ( g , n ) (g,n) (g,n)
- 3.再转置为 ( n , g ) (n,g) (n,g)
- 4.平坦化,再分回 g g g组作为下一层的输入
示意图如下:

这样操作有点在于是可微的,模型可以保持end-to-end训练.
Shuffle unit
前面我们讲了通道混洗的好处了,在实际过程中我们构建了一个ShuffleNet unit,便于构建实际模型。
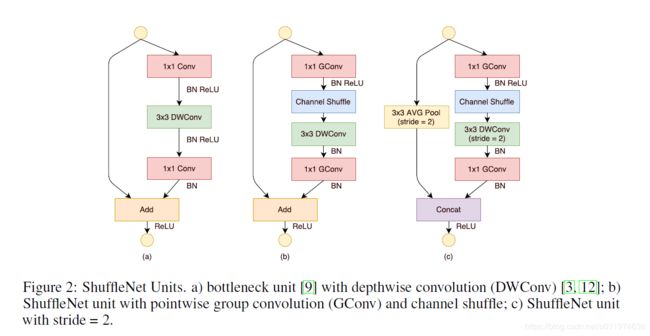
-
图(a)是一个残差模块。对于主分支部分,我们可将其中标准卷积 3 × 3 3×3 3×3拆分成深度分离卷积(可参考我的
MobileNet笔记)。我们将第一个 1 × 1 1×1 1×1卷积替换为逐点组卷积,再作通道混洗(即(b))。 -
图(b)即ShuffleNet unit,主分支最后的 1 × 1 C o n v 1×1 Conv 1×1Conv改为 1 × 1 G C o n v 1×1 GConv 1×1GConv,为了适配和恒等映射做通道融合。配合BN层和ReLU激活函数构成基本单元.
-
图©即是做降采样的ShuffleNet unit,这主要做了两点修改:
- 在辅分支加入步长为2的
3×3平均池化 - 原本做元素相加的操作转为了通道级联,这扩大了通道维度,增加的计算成本却很少
- 在辅分支加入步长为2的
归功于逐点群卷积和通道混洗,ShuffleNet unit可以高效的计算。相比于其他先进的单元,在相同设置下复杂度较低。
例如:给定输入大小 h × w × c h×w×c h×w×c,通道数为 c c c。对于的bottleneck通道为 m m m:
- ResNet unit需要 h w ( 2 c m + 9 m 2 ) F L O P S hw(2cm+9m^2)FLOPS hw(2cm+9m2)FLOPS计算量。
- ResNeXt需要 h w ( 2 c m + 9 m 2 / g ) hw(2cm+9m^2/g) hw(2cm+9m2/g)FLOPS
- 而ShuffleNet unit只需要 h w ( 2 c m / g + 9 m ) hw(2cm/g+9m) hw(2cm/g+9m)FLOPS.
其中 g g g代表组卷积数目。即表示**:给定一个计算限制,ShuffleNet可以使用更宽的特征映射。我们发现这对小型网络很重要,因为小型网络没有足够的通道传递信息**。
**需要注意的是:**虽然深度卷积可以减少计算量和参数量,但在低功耗设备上,与密集的操作相比,计算/存储访问的效率更差。故在ShuffleNet上我们只在bottleneck上使用深度卷积,尽可能的减少开销.
NetWork Architecture
在上面的基本单元基础上,我们提出了ShuffleNet的整体架构:
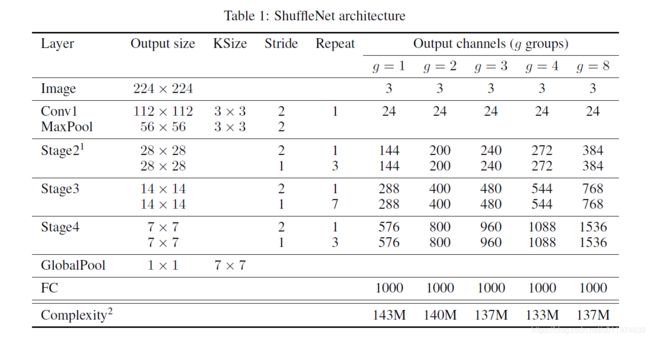
主要分为三个阶段:
- 每个阶段的第一个block的步长为2,下一阶段的通道翻倍
- 每个阶段内的除步长其他超参数保持不变
- 每个ShuffleNet unit的bottleneck通道数为输出的1/4(和ResNet设置一致)
这里主要是给出一个baseline。在ShuffleNet Unit中,参数 g g g控制逐点卷积的连接稀疏性(即分组数),对于给定的限制下,越大的 g g g会有越多的输出通道,这帮助我们编码信息。
定制模型需要满足指定的预算,我们可以简单的使用放缩因子 s s s控制通道数,ShuffleNet s × s× s×即表示通道数放缩到 s s s倍。
Experiment
实验在ImageNet的分类集上做评估,大多数遵循ResNeXt的设置,除了两点:
- 权重衰减从1e-4降低到了4e-5
- 数据增强使用较少的aggressive scale 增强
这样做的原因是小型网络在训练过程通常会遇到欠拟合而不是过拟合问题。
On the Importance of Pointwise Group Convolutions
为了评估逐点卷积的重要性,比较相同复杂度下组数从1到8的ShuffleNet模型,同时我们通过放缩因子 s s s控制网络宽度,扩展为3种:

从结果来看,有组卷积的一致比没有组卷积( g = 1 g=1 g=1)的效果要好。注意组卷积可允许获得更多通道的信息,我们假设性能的收益源于更宽的特征映射,这帮助我们编码更多信息。并且,较小的模型的特征映射通道更少,这意味着能多的从特征映射上获取收益。
表2还显示,对于一些模型,随着 g g g增大,性能上有所下降。意味组数增加,每个卷积滤波器的输入通道越来越少,损害了模型表示能力。
值得注意的是,对于小型的ShuffleNet 0.25×,组数越大性能越好,这表明对于小模型更宽的特征映射更有效。受此启发,在原结构的阶段3删除两个单元,即表2中的arch2结构,放宽对应的特征映射,明显新的架构效果要好很多。
Channel Shuffle vs. No Shuffle
Shuffle操作是为了实现多个组之间信息交流,下表表现了有无Shuffle操作的性能差异:

在三个不同复杂度下带Shuffle的都表现出更优异的性能,尤其是当组更大(arch2, g = 8 g=8 g=8),具有shuffle操作性能提升较多,这表现出Shuffle操作的重要性。
Comparison with Other Structure Units
我们对比不同unit之间的性能差异,使用表1的结构,用各个unit控制阶段2-4之间的Shuffle unit,调整通道数保证复杂度类似。

可以看到ShuffleNet的表现是比较出色的。有趣的是,我们发现特征映射通道和精度之间是存在直观上的关系,以38MFLOPs为例,VGG-like, ResNet, ResNeXt, Xception-like, ShuffleNet模型在阶段4上的输出通道为50, 192, 192, 288, 576,这是和精度的变化趋势是一致的。我们可以在给定的预算中使用更多的通道,通常可以获得更好的性能。
上述的模型不包括GoogleNet或Inception结构,因为Inception涉及到太多超参数了,做为参考,我们采用了一个类似的轻量级网络PVANET。结果如下:
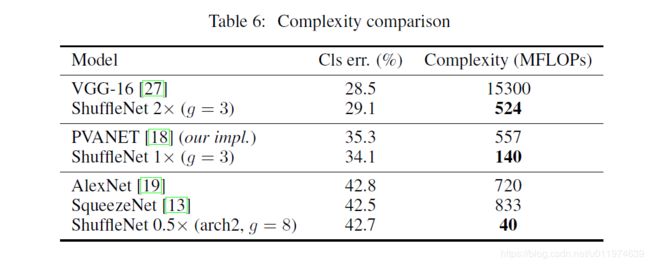
ShuffleNet模型效果要好点
Comparison with MobileNets and Other Frameworks
与MobileNet和其他模型相比:
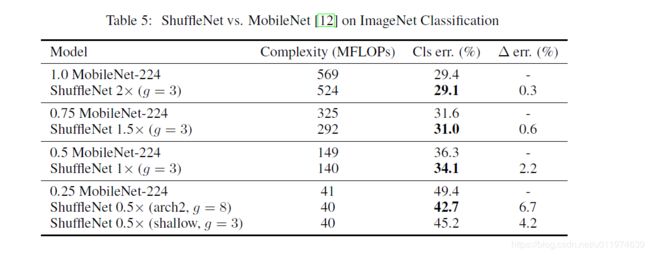
相比于不同深度的模型对比,可以看到我们的模型要比MobileNet的效果要好,这表明ShuffleNet的有效性主要来源于高效的结构设计,而不是深度。
Generalization Ability
我们在MS COCO目标检测任务上测试ShuffleNet的泛化和迁移学习能力,以Faster RCNN为例:

ShuffleNet的效果要比同等条件下的MobileNet效果要好,我们认为收益源于ShuffleNet的设计。
Actual Speedup Evaluation
评估ShuffleNet在ARM平台的移动设备上的推断速度。
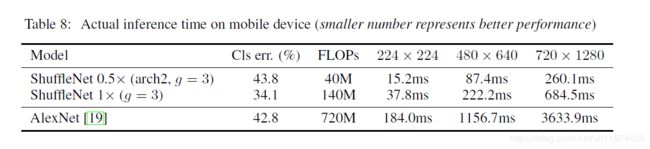
三种分辨率输入做测试,由于内存访问和其他开销,原本理论上4倍的加速降低到了2.6倍左右。
Conclusion
论文针对现多数有效模型采用的逐点卷积存在的问题,提出了组卷积和通道混洗的处理方法,并在此基础上提出了一个ShuffleNet unit,后续对该单元做了一系列的实验验证,证明ShuffleNet的结构有效性。
代码分析
这里分析的github-MG2033的代码。
层定义
先看layers.py文件,这部分定义了模型中使用的层。
# 构建的shufflenet unit
def shufflenet_unit(name, x, w=None, num_groups=1, group_conv_bottleneck=True, num_filters=16, stride=(1, 1),
l2_strength=0.0, bias=0.0, batchnorm_enabled=True, is_training=True, fusion='add'):
# Paper parameters. If you want to change them feel free to pass them as method parameters.
activation = tf.nn.relu
with tf.variable_scope(name) as scope:
residual = x
bottleneck_filters = (num_filters // 4) if fusion == 'add' else (num_filters - residual.get_shape()[
3].value) // 4
if group_conv_bottleneck:
# 先1x1卷积
bottleneck = grouped_conv2d('Gbottleneck', x=x, w=None, num_filters=bottleneck_filters, kernel_size=(1, 1),
padding='VALID',
num_groups=num_groups, l2_strength=l2_strength, bias=bias,
activation=activation,
batchnorm_enabled=batchnorm_enabled, is_training=is_training)
# 通道混洗
shuffled = channel_shuffle('channel_shuffle', bottleneck, num_groups)
else:
bottleneck = conv2d('bottleneck', x=x, w=None, num_filters=bottleneck_filters, kernel_size=(1, 1),
padding='VALID', l2_strength=l2_strength, bias=bias, activation=activation,
batchnorm_enabled=batchnorm_enabled, is_training=is_training)
shuffled = bottleneck
# 3x3深度分离卷积
padded = tf.pad(shuffled, [[0, 0], [1, 1], [1, 1], [0, 0]], "CONSTANT")
depthwise = depthwise_conv2d('depthwise', x=padded, w=None, stride=stride, l2_strength=l2_strength,
padding='VALID', bias=bias,
activation=None, batchnorm_enabled=batchnorm_enabled, is_training=is_training)
# 如果步长为2,则下采样
if stride == (2, 2):
residual_pooled = avg_pool_2d(residual, size=(3, 3), stride=stride, padding='SAME')
else:
residual_pooled = residual
# 如果是通道连接
if fusion == 'concat':
group_conv1x1 = grouped_conv2d('Gconv1x1', x=depthwise, w=None,
num_filters=num_filters - residual.get_shape()[3].value,
kernel_size=(1, 1),
padding='VALID',
num_groups=num_groups, l2_strength=l2_strength, bias=bias,
activation=None,
batchnorm_enabled=batchnorm_enabled, is_training=is_training)
return activation(tf.concat([residual_pooled, group_conv1x1], axis=-1))
# 最后像素加
elif fusion == 'add':
group_conv1x1 = grouped_conv2d('Gconv1x1', x=depthwise, w=None,
num_filters=num_filters,
kernel_size=(1, 1),
padding='VALID',
num_groups=num_groups, l2_strength=l2_strength, bias=bias,
activation=None,
batchnorm_enabled=batchnorm_enabled, is_training=is_training)
residual_match = residual_pooled
# This is used if the number of filters of the residual block is different from that
# of the group convolution.
if num_filters != residual_pooled.get_shape()[3].value:
residual_match = conv2d('residual_match', x=residual_pooled, w=None, num_filters=num_filters,
kernel_size=(1, 1),
padding='VALID', l2_strength=l2_strength, bias=bias, activation=None,
batchnorm_enabled=batchnorm_enabled, is_training=is_training)
return activation(group_conv1x1 + residual_match)
else:
raise ValueError("Specify whether the fusion is \'concat\' or \'add\'")
# 通道混洗
def channel_shuffle(name, x, num_groups):
with tf.variable_scope(name) as scope:
n, h, w, c = x.shape.as_list()
x_reshaped = tf.reshape(x, [-1, h, w, num_groups, c // num_groups]) # 先合并重组
x_transposed = tf.transpose(x_reshaped, [0, 1, 2, 4, 3]) # 转置
output = tf.reshape(x_transposed, [-1, h, w, c]) # 摊平
return output
模型定义
直接看model.py文件,有了上面的层定义,这代码看起来就整洁很多了。
import tensorflow as tf
from layers import shufflenet_unit, conv2d, max_pool_2d, avg_pool_2d, dense, flatten
class ShuffleNet:
"""ShuffleNet is implemented here!"""
MEAN = [103.94, 116.78, 123.68]
NORMALIZER = 0.017
def __init__(self, args):
self.args = args
self.X = None
self.y = None
self.logits = None
self.is_training = None
self.loss = None
self.regularization_loss = None
self.cross_entropy_loss = None
self.train_op = None
self.accuracy = None
self.y_out_argmax = None
self.summaries_merged = None
# A number stands for the num_groups
# Output channels for conv1 layer
self.output_channels = {'1': [144, 288, 576], '2': [200, 400, 800], '3': [240, 480, 960], '4': [272, 544, 1088],
'8': [384, 768, 1536], 'conv1': 24}
self.__build()
def __init_input(self):
batch_size = self.args.batch_size if self.args.train_or_test == 'train' else 1
with tf.variable_scope('input'):
# Input images
self.X = tf.placeholder(tf.float32,
[batch_size, self.args.img_height, self.args.img_width,
self.args.num_channels])
# Classification supervision, it's an argmax. Feel free to change it to one-hot,
# but don't forget to change the loss from sparse as well
self.y = tf.placeholder(tf.int32, [batch_size])
# is_training is for batch normalization and dropout, if they exist
self.is_training = tf.placeholder(tf.bool)
def __resize(self, x):
return tf.image.resize_bicubic(x, [224, 224])
def __stage(self, x, stage=2, repeat=3):
if 2 <= stage <= 4:
stage_layer = shufflenet_unit('stage' + str(stage) + '_0', x=x, w=None,
num_groups=self.args.num_groups,
group_conv_bottleneck=not (stage == 2),
num_filters=
self.output_channels[str(self.args.num_groups)][
stage - 2],
stride=(2, 2),
fusion='concat', l2_strength=self.args.l2_strength,
bias=self.args.bias,
batchnorm_enabled=self.args.batchnorm_enabled,
is_training=self.is_training)
for i in range(1, repeat + 1):
stage_layer = shufflenet_unit('stage' + str(stage) + '_' + str(i),
x=stage_layer, w=None,
num_groups=self.args.num_groups,
group_conv_bottleneck=True,
num_filters=self.output_channels[
str(self.args.num_groups)][stage - 2],
stride=(1, 1),
fusion='add',
l2_strength=self.args.l2_strength,
bias=self.args.bias,
batchnorm_enabled=self.args.batchnorm_enabled,
is_training=self.is_training)
return stage_layer
else:
raise ValueError("Stage should be from 2 -> 4")
def __init_output(self):
with tf.variable_scope('output'):
# Losses
self.regularization_loss = tf.reduce_sum(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))
self.cross_entropy_loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.logits, labels=self.y, name='loss'))
self.loss = self.regularization_loss + self.cross_entropy_loss
# Optimizer
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
self.optimizer = tf.train.AdamOptimizer(learning_rate=self.args.learning_rate)
self.train_op = self.optimizer.minimize(self.loss)
# This is for debugging NaNs. Check TensorFlow documentation.
self.check_op = tf.add_check_numerics_ops()
# Output and Metrics
self.y_out_softmax = tf.nn.softmax(self.logits)
self.y_out_argmax = tf.argmax(self.y_out_softmax, axis=-1, output_type=tf.int32)
self.accuracy = tf.reduce_mean(tf.cast(tf.equal(self.y, self.y_out_argmax), tf.float32))
with tf.name_scope('train-summary-per-iteration'):
tf.summary.scalar('loss', self.loss)
tf.summary.scalar('acc', self.accuracy)
self.summaries_merged = tf.summary.merge_all()
def __build(self):
self.__init_global_epoch()
self.__init_global_step()
self.__init_input()
with tf.name_scope('Preprocessing'):
red, green, blue = tf.split(self.X, num_or_size_splits=3, axis=3)
preprocessed_input = tf.concat([
tf.subtract(blue, ShuffleNet.MEAN[0]) * ShuffleNet.NORMALIZER,
tf.subtract(green, ShuffleNet.MEAN[1]) * ShuffleNet.NORMALIZER,
tf.subtract(red, ShuffleNet.MEAN[2]) * ShuffleNet.NORMALIZER,
], 3)
x_padded = tf.pad(preprocessed_input, [[0, 0], [1, 1], [1, 1], [0, 0]], "CONSTANT")
conv1 = conv2d('conv1', x=x_padded, w=None, num_filters=self.output_channels['conv1'], kernel_size=(3, 3),
stride=(2, 2), l2_strength=self.args.l2_strength, bias=self.args.bias,
batchnorm_enabled=self.args.batchnorm_enabled, is_training=self.is_training,
activation=tf.nn.relu, padding='VALID')
padded = tf.pad(conv1, [[0, 0], [0, 1], [0, 1], [0, 0]], "CONSTANT")
max_pool = max_pool_2d(padded, size=(3, 3), stride=(2, 2), name='max_pool')
stage2 = self.__stage(max_pool, stage=2, repeat=3)
stage3 = self.__stage(stage2, stage=3, repeat=7)
stage4 = self.__stage(stage3, stage=4, repeat=3)
global_pool = avg_pool_2d(stage4, size=(7, 7), stride=(1, 1), name='global_pool', padding='VALID')
logits_unflattened = conv2d('fc', global_pool, w=None, num_filters=self.args.num_classes,
kernel_size=(1, 1),
l2_strength=self.args.l2_strength,
bias=self.args.bias,
is_training=self.is_training)
self.logits = flatten(logits_unflattened)
self.__init_output()
def __init_global_epoch(self):
"""
Create a global epoch tensor to totally save the process of the training
:return:
"""
with tf.variable_scope('global_epoch'):
self.global_epoch_tensor = tf.Variable(-1, trainable=False, name='global_epoch')
self.global_epoch_input = tf.placeholder('int32', None, name='global_epoch_input')
self.global_epoch_assign_op = self.global_epoch_tensor.assign(self.global_epoch_input)
def __init_global_step(self):
"""
Create a global step variable to be a reference to the number of iterations
:return:
"""
with tf.variable_scope('global_step'):
self.global_step_tensor = tf.Variable(0, trainable=False, name='global_step')
self.global_step_input = tf.placeholder('int32', None, name='global_step_input')
self.global_step_assign_op = self.global_step_tensor.assign(self.global_step_input)