轮子:一个简单的node爬虫踩坑之路
一个简单的node爬虫踩坑之路
准备工作
最近在看爬虫相关的文章,偶然想起来尝试一下用node来实现一个简单的爬虫。但是爬别的多没意思,当然是爬美女图片啊。。。
这大概 node 里面造的最多的轮子了。
于是,我选取了下面的地址:美女图片戳我,简单分析后,我的目标是通过爬取首页的轮播图,然后爬取轮播图的直链后面的详情大图,并按照图片名称存到指定的文件夹中。
大致流程是下面这个样子的:
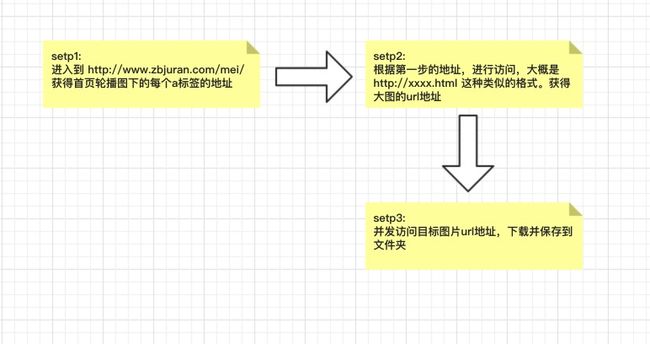
看起来挺简单的,选用的技术方案是:
superagent: 请求库mkdirp: 创建文件夹async: 控制并发请求cheerio: Dom操作库fs: 内置核心文件读写库
最终的效果
源码:
// 关键在于理清异步流程
'use strict'
let fs = require("fs");
let cheerio = require('cheerio');
let asyncQuene = require("async").queue;
let request = require('superagent');
require('superagent-charset')(request);
const config = {
urlPre: 'http://www.zbjuran.com',
indexUrl: 'http://www.zbjuran.com/mei/',
downloadConcurrent: 2,
};
let getHtmlAsync = (url) => {
return new Promise((resolve,reject) => {
request.get(url).charset('gbk').end((err,res) => {
err ? reject(err) : resolve(cheerio.load(res.text));
})
})
}
let dowloadImg = (albumList) => {
console.log('开始下载图片');
const folder = './grils/';
fs.existsSync(folder, status => {
status ? '' : fs.mkdirSync(folder);
})
let downloadCount = 0;
let queue = asyncQuene( ({ url: albumUrl, title: albumTitle},done) => {
request.get(albumUrl).end(function (err, res) {
if (err) {
console.log(err);
done();
} else {
fs.writeFile(`./${folder}/${albumTitle}-${++downloadCount}.jpg`, res.body, function (err) {
err ? console.log(err) : console.log(`${albumTitle}保存一张`);
done();
});
}
});
},config.downloadConcurrent);
queue.drain = () => {
console.log('所有图片已经下载');
}
let imgListTemp = [];
albumList.forEach(function ({ title, imgList }) {
console.log(title,imgList);
imgList.forEach(function (url) {
imgListTemp.push({ title: title, url: url });
});
});
console.log('sssss',albumList,imgListTemp);
queue.push(imgListTemp);//将所有任务加入队列
}
let getIndexAsync = () => {
return new Promise((resolve, reject) =>{
console.log('进入主页,开始获取目标url');
let targetUrl = [];
let queue = asyncQuene(async (url, done) => {
try {
let $ = await getHtmlAsync(url);
console.log(`成功获取主页${url}`);
$('div.changeDiv a').each( (index,value) => {
targetUrl.push({
title: value.attribs.title,
url: `${config.urlPre}${value.attribs.href}`,
imgList: []
})
});
} catch (err) {
console.log(`在访问${url}出现以下错误:${err}`);
}
finally {
done();
}
},config.downloadConcurrent);
queue.drain = () => {
console.log('已成功生成目标Url');
resolve(targetUrl);
}
queue.push(config.indexUrl);
})
}
let getTargetAsync = (targetUrl) => {
return new Promise((resolve, reject) =>{
console.log('进入目标页,开始获取目标url');
let queue = asyncQuene(async ({ url: url, title: title, imgList },done) => {
try {
let $ = await getHtmlAsync(url);
console.log(`成功获取主页${url}`);
let imgLength = $('div.page > li').length - 3;
$('div.picbox img').each( (index,value) => {
let imgSrcPath = value.attribs.src;
imgList.push(`${config.urlPre}${value.attribs.src}`);
for (let i = 0,length = imgLength; i < length; i++) {
if(i >= 1){
imgList.push(`${config.urlPre}${imgSrcPath.replace('-0','-'+i)}.jpg`);
}
}
});
} catch (err) {
console.log(`在访问${url}出现以下错误:${err}`);
}
finally {
done();
}
},config.downloadConcurrent);
queue.drain = () => {
console.log('已成功获取到所有图片的Url');
resolve(targetUrl);
}
queue.push(targetUrl);
})
}
let spider = async () => {
// let albumList = await getAlbumsAsync();//获取所有画册URL
// albumList = await getImageListAsync(albumList);//根据画册URL获取画册里的所有图片URL
// downloadImg(albumList);//下载画册里面的所有图片
let targetUrl = await getIndexAsync();
targetUrl = await getTargetAsync(targetUrl);
dowloadImg(targetUrl);
}
spider();划重点
1.当爬取网页编码为 gb2312的网页的时候,爬到的内容中文显示是乱码
这个问题的原因其实是挺清晰的,就是网页编码与本地编码不一致或不支持引起的。以为只是个小问题,但是在找解决办法的时候却纠结了我很久,查询了网上相关资料,有说使用 iconv 解码decode一下就可以,然并卵,有说使用encoding的,其实也没用。其实最后查阅资料得出的原因是,superagent只支持utf-8的编码,如果需要支持其他的需要引用一个官方的库:superagent-charset,使用方法如下:
const request = require('superagent');
require('superagent-charset')(request);
//请求
request.get('xxx').set('gbk').end(xxxxx)如此,即可正常返回中文
2. 异步操作用 async 来控制
对于下载图片,访问 url 这样存在异步的操作,如果操作对后面程序的执行有影响,最好使用 async 库来控制异步流程,类似的还有 eventproxy。
下面是一个使用来async来控制请求队列的官网示例,
// create a queue object with concurrency 2
var q = async.queue(function(task, callback) {
console.log('hello ' + task.name);
callback();
}, 2);
// assign a callback
q.drain = function() {
console.log('all items have been processed');
};
// add some items to the queue
q.push({name: 'foo'}, function(err) {
console.log('finished processing foo');
});
q.push({name: 'bar'}, function (err) {
console.log('finished processing bar');
});
// add some items to the queue (batch-wise)
q.push([{name: 'baz'},{name: 'bay'},{name: 'bax'}], function(err) {
console.log('finished processing item');
});
// add some items to the front of the queue
q.unshift({name: 'bar'}, function (err) {
console.log('finished processing bar');
});其实官网有好多栗子,近期还会抽时间好好研究一下类似异步流程库的具体实现。
3. 404错误。获取不到资源
这个其实还好,主要是网站为了防爬的措施,可以尝试一下方法来试试看:
- 设置
user-agent - 降低请求的并发量
- 更换IP
总结
虽然只是一个简单的爬虫,但是发现自己对于 promise 这种的异步流程还不是很熟悉,这点需要重点掌握。
另外,从爬虫的角度来说,node现在的库已经很完善了,还有 phantomjs,node-crawl 这种操作更6的库存在,掌握一门工具很容易,更重要的是要学会制作工具。
最后,练习爬虫只是出于对技术的热爱,莫要乱爬。