集成学习总结(Bagging/Boosting)
目录
前言
一、Bagging
1、随机抽样
2、Bagging算法总述
3、随机森林
二、Boosting
1、AdaBoost
2、GBDT(梯度提升决策树)
2.1 提升树模型(Boosting Tree)
2.2 GBDT
3、XGBoost
三、Stacking
前言
集成学习是机器学习的一个重要分支,利用一种“三个臭皮匠赛过诸葛亮”的思想,通过某种方法将多个弱分类器组合起来,形成一个具有很高预测准确率的强分类器的算法。集成学习分为三大类:
1、Bagging:代表是随机森林
2、Boosting:代表是AdaBoost,GBDT,XGBoost
3、Stacking:暂无著名代表,可以视为一种集成的套路 参考资料1
一、Bagging
1、随机抽样
我首先介绍一下随机抽样,这将在随机森林中用到。我们都知道抽样有两种:有放回抽样和无放回抽样。有放回中一个样本被抽中之后会放回去,下次仍有机会抽中。而无放回一个样本抽中之后就从样本集去除,下次不会参与其中。随机森林用的抽样方法Bootstrap使用的是有放回抽样。
具体抽样做法:在n个样本的集合中有放回的抽n个形成一个数据集(看清楚是n)。所以每次抽中其中任何一个样本的概率是1/n,样本没被抽中的概率是1-1/n。由于是有放回,每两次抽样之间是独立的,对整个n次抽样过程来说,一个样本没被抽中的概率是:
![]()
大家都学过高数求极限,当n—>![]() 这个值的极限是1/e,近似为0.368,意思就是样本很大时,每个样本有0.368的概率不被抽中,由于整个过程的独立性,所有样本大约有36.8%不被抽取到。这部分数据叫包外数据(又给你补了补机器学习基础和高数哈哈)参考资料2雷明老师的书我只有纸质版
这个值的极限是1/e,近似为0.368,意思就是样本很大时,每个样本有0.368的概率不被抽中,由于整个过程的独立性,所有样本大约有36.8%不被抽取到。这部分数据叫包外数据(又给你补了补机器学习基础和高数哈哈)参考资料2雷明老师的书我只有纸质版
2、Bagging算法总述
大家都听过做高难手术的时候有专家会诊,就是一个医生可能对这个瘤子且多大决策存疑的话,那么五位专家一起来决策,给患者的治疗更好。在上面Bootstrap抽样基础上构造的Bagging算法基本流程如下:
循环,对i=1,2,……T(这里的T是Bootstrap的次数)
对训练样本进行Bootstrap抽样,得到抽样后的训练样本集
用抽样后的样本集训练一个模型![]()
结束循环
输出模型组合![]()
上面算法就是Bagging算法大概流程,每个![]() 就是一个弱分类器(We donot care this)。如果弱学习器是决策树,这种方法就是随机森林。(有疑问的你先熟悉下决策树好吗)
就是一个弱分类器(We donot care this)。如果弱学习器是决策树,这种方法就是随机森林。(有疑问的你先熟悉下决策树好吗)
3、随机森林
随机森林的步骤:
(1) 对训练样本进行bootstrap采样,即有放回的采样,获得M个采样集合;
(2) 在这M个采样集合上训练处M个弱决策树。注意到,在决策树生成中还用到了列采样的技巧,原本决策树中节点分裂时,是选择当前节点中所有属性的最优属性进行划分的,但是列采样的技巧是在所有属性中的子集中选最优属性进行划分。这样做可以进一步降低过拟合的可能性;
(3) 对这M个训练出来的弱决策树进行集成。
随机森林可以降低模型的方差,更多的好处我五一之后补充,并增加实战来说明。
二、Boosting
Boosting同Bagging的不同之处在于重点关注被前面的弱分类器错分的样本,它最著名的有:AdaBoost,GBDT,XGBoost
关于Boosting的两个核心问题:
1)在每一轮如何改变训练数据的权值或概率分布?
通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
2)通过什么方式来组合弱分类器?
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。
而提升树通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
1、AdaBoost
全称为自适应Boosting,是一种二分类算法,用弱分类器的线性组合得到强分类器,弱分类器性能较差,仅比乱猜强点,(神奇不)强分类器的计算公式为:

其中x是输入向量,F(x)是强分类器,![]() 是弱分类器,
是弱分类器,![]() 是弱分类器的权重。弱分类器的输出是+1或-1,分别对应正样本和负样本(因为适用于二分类),分类的判定规则为:
是弱分类器的权重。弱分类器的输出是+1或-1,分别对应正样本和负样本(因为适用于二分类),分类的判定规则为:
sgn(F(x))(输出也是+1或者-1)
训练中初始时所有样本权重相等,过程中被错分的样本加大权重(考试前这个知识点没掌握就重点复习),反之会减小权重(总之权重动态调整)。实际中一般用深度很小的决策树做弱分类器,因为它的非线性。AdaBoost的主要思想就是在不改变训练数据的情况下,通过在迭代训练弱学习器中,不断提升被错分类样本的权重(也就是使被错分的样本在下一轮训练时得到更多的重视),不断减少正确分类样本的权重。最后通过加权线性组合M个弱分类器得到最终的分类器,正确率越高的弱分类器的投票权数越高,正确率低的弱分类器自然投票权数就低。
随机森林和AdaBoost算法的比较见下图:
| 随机森林 | AdaBoost | |
| 决策树规模 | 大 | 小 |
| 是否对样本进行随机采样 | 是 | 否 |
| 是否对特征进行随机采样 | 是 | 否 |
| 弱分类器是否有权重 | 否 | 是 |
| 训练样本是否有权重 | 否 | 是 |
| 是否支持多分类 | 是 | 否,可改造 |
| 是否支持回归问题 | 是 | 否,可改造 |
几个关键问题:
弱分类器的数量:一种做法是在训练时一直增加弱分类器的个数,同时统计训练误差,当误差达到指定的阈值时迭代终止。
样本权重如何改:随着权重调整,有些样本权重很小,我们设定一个阈值,迭代中权重小于该阈值则该样本不参与后续训练。
2、GBDT(梯度提升决策树)
基本原理是提升树(boosting tree),并使用gradient boost。GBDT又叫MART,该算法由多颗决策树组成,所有树累加起来得到最终答案。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合。业界中,Facebook使用其来自动发现有效的特征、特征组合,来作为LR模型中的特征,以提高 CTR预估(Click-Through Rate Prediction)的准确性(详见参考文献5、6);GBDT在淘宝的搜索及预测业务上也发挥了重要作用。参考资料4
2.1 提升树模型(Boosting Tree)
提升方法采用加法模型和前向分步算法,以决策树为基础的提升方法称为提升树。对分类问题,决策树是二叉分类树,对回归问题,决策树是二叉回归树,提升树表示为决策树的加法模型:(在看博客之前一定要很熟悉决策树!)
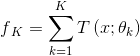
其中fk为包含所有回归树的函数空间。因此,回归树是一个将特征空间映射为分值的函数。
提升树算法的过程如下:
输入:数据集D={(x1,y1),(x2,y2),……,(xN,yN)}
输出:提升树
步骤:1. 初始化
2. 循环,k=1,2,……,K
计算每个样本的残差:r(i)=y(i)-f(下标k-1)(xi)(残差=真实值-预测值)
拟合fit 残差学习得一个回归树
更新
3. 得到提升树:
2.2 GBDT
对于一般的损失函数一步最优不可能(心机吃不了热豆腐),就提出了利用梯度下降,即利用损失函数的负梯度在当前模型的值,作为残差的近似值,去拟合回归树
算法步骤解释:
- 1、初始化,估计使损失函数极小化的常数值,它是只有一个根节点的树,即ganma是一个常数值。
- 2、(a)计算损失函数的负梯度在当前模型的值,将它作为残差的估计
(b)估计回归树叶节点区域,以拟合残差的近似值
(c)利用线性搜索估计叶节点区域的值,使损失函数极小化
(d)更新回归树 参考资料 - 3、得到输出的最终模型 f(x)
3、XGBoost
xgboost类似于gbdt,在计算速度和准确率上,较GBDT有明显的提升。xgboost 的全称是EXtreme Gradient Boosting。xgboost最大的特点在于,它能够自动利用CPU的多线程进行并行,同时在算法上加以改进提高了精度。具体优点有:
1、损失函数用泰勒展式二项逼近,而不是GBDT的一阶导;
2、对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能;
3、节点分裂方式不同,GBDT是gini系数,xgboost是经过优化推导之后
xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。下面所有的内容来自原始paper,包括公式。
(1) xgboost在目标函数中显示的加上了正则化项,基学习器为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。

(2) GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数。第t次的loss:
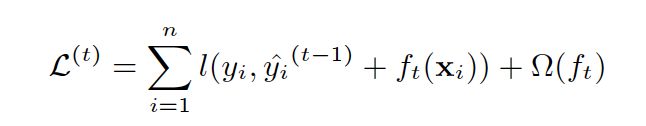
对上式做二阶泰勒展开:
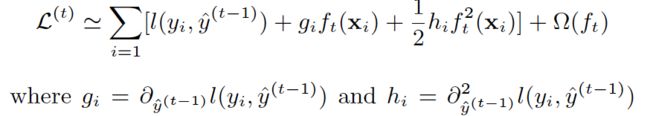
(3) 上面提到CART回归树中寻找最佳分割点的衡量标准是最小化均方差,xgboost寻找分割点的标准是最大化Lsplit

xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
xgboost与gdbt除了上述三点的不同,xgboost在实现时还做了许多优化:
- 在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
- xgboost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,paper提到50倍。
- xgboost借鉴了随机森林中的列(特征)采样技术,即在某个节点分裂时,不是在当前节点中所有属性中选取最佳分裂属性,而是在当前属性集合中的某些属性中来选择最优分裂属性。这种方法降低了过拟合的可能性。
特征列排序后以块的形式存储在内存中,在迭代中可以重复使用;虽然boosting算法迭代必须串行,但是在处理每个特征列时可以做到并行。
按照特征列方式存储能优化寻找最佳的分割点,但是当以行计算梯度数据时会导致内存的不连续访问,严重时会导致cache miss,降低算法效率。paper中提到,可先将数据收集到线程内部的buffer,然后再计算,提高算法的效率。
- xgboost还考虑了当数据量比较大,内存不够时怎么有效的使用磁盘,主要是结合多线程、数据压缩、分片的方法,尽可能的提高算法的效率。
来自知乎的经典问答:为什么基于tree-ensemble的机器学习方法,在kaggle比赛中效果很好?
xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
GBDT和XGBOOST的区别有哪些?(找机器学习算法工程师必问)
三、Stacking
暂时还没尖子生(代表性算法),具体做法是:
(1) 先将训练集D拆成k个大小相似但互不相交的子集D1,D2,…,Dk;
(2) 令Dj’= D - Dj,在Dj’上训练一个弱学习器Lj。将Dj作为测试集,获得Lj在Dj上的输出Dj’’;
(3) 步骤2可以得到k个弱学习器以及k个相应的输出Dj’’,这个k个输出加上原本的类标构成新的训练集Dn;
(4) 在Dn训练次学习器L,L即为最后的学习器。
以上Stacking只做了一层,据kaggle上的大神反馈,Stacking可以做好多层,会有神奇的效果。
下面给出kaggle中一个Stacking的实例,就是入门级的titanic那道题单层stacking的源码(只给出了stacking 的过程,前面特征工程处理的代码被省略掉了)。Stacking后的xgboost(得分:0.77990)比我之前只用xgboost时(得分:0.77512)提高了一点,排名上升了396…… 原博戳这 +++++++源码戳这
Log on 2017-6-22: Stacking了两次之后,得分从单次stacking的0.77990上升到了0.79904
Log on 2017-6-22: Stacking了三次之后,得分从两次stacking的0.77990降低到了0.78469。所以,Stacking并不是越多层
越好,反而会变坏。
专题介绍——Bagging和Boosting的区别
参考资料
[1] https://xijunlee.github.io/2017/06/03/%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93/?tdsourcetag=s_pctim_aiomsg
[2] https://www.jianshu.com/p/005a4e6ac775?tdsourcetag=s_pctim_aiomsg
[3] https://www.cnblogs.com/liuwu265/p/4690486.html?tdsourcetag=s_pctim_aiomsg
[4] 雷明《机器学习与应用》