第一章 整数乘法器
1.1 整数的概念
整数在IEEE 的规定上有,短整数short integer , 中整数integer 和 长整数long integer ,它们之间的关系如下:
| 整数 |
字节空间 |
取值范围 |
| 短整数 |
一个字节 |
-127 ~ 127 |
| 中整数 |
两个字节 |
-32767~32767 |
| 长整数 |
和四个字节 |
-2147483647~2147483647 |
在这里笔者以短整数为笔记的主角。
短整数的最高位是符号位,符号位的正负表示了该值是“正还是负”?。正值的表示方法很简单,反之负值的表示方法是以补码来表示。
+127 亦即8'b0111_1111;
+4 亦即8'b0000_0100;
-127 亦即8'b1000_0001;
-4 亦即8'b1111_1100;
补码在英文又叫2nd implementation , 其实是“正值的求反又加一”的操作。(哎~年轻时的笔者曾经这个东西头疼过)。一个负值表示如-4 ,是由+4 求反由加一后而成。
8'b0000_0100; // 正值4
8'b1111_1011; // 求反
8'b1111_1100; // 加1 , 负值4
那么符号位和正值,负值,补码,取值由有什么关系呢?举个例子 :A = 8'b0111_1111 (+127) 和B = 8'b1000_0001 ( -127 )。
当我们在进行判断一个短整数是正值还是负值的时候,我们可以这样表示:
if ( !A[7] ) ... // A是正值
if ( B[7] ) ... // B是负值
在事实的事实上。我们知道短整数 28 ,亦即取值范围是0~255,但是符号位的出现吃掉了最高位,所以造成由28 的取值范围变成27 = 0~171 。
你知道吗?在短整数家族里面永远存在一个幽灵成员。该成员很神秘,它不是正值,即不是负值或者0值。而且它的能力也不可忽视,它划分了正值和负值的边界,它就是8'b1000_0000。
+127 8'b0111_1111;
划分 8'b1000_0000;
-127 8'b1000_0001;
换句话说,在8'b1000_0000 之前的都是正值 ,然而在8'b1000_0000 之后是负值。如果读者硬是要说8'b1000_0000 是 “负0”,笔记也无话可说......
从上述的内容,我们可以知道:正值可以进行求反又加一之后成为负值。那么负值如何变成正值?同样的一个道理“负值求反又加一后,成为正值”。
8'b1111_1100; // 负4
8'b0000_0011; // 求反
8'b0000_0100; // 加1 , 正4
1.2 传统乘法的概念
笔者还记得笔者在上小学三年级的时候,老师在黑板上写上3 x 4 = 12。笔者对这神秘的数学公式迷糊了头脑。后来老师解释道: " 3粒苹果重复加上4 次等于12粒苹果",小时的笔者顿时恍然大悟!
当笔者上了初中,老师在黑板上写上3 + -4 = -1。大伙们都明白那是整数,但是初中的笔者,脑袋过很迟钝。因为在现实中,初中的笔者认为没有“-3粒苹果”类似实体的概念纯在,后来老师解释道:“ 小明欠小黄4粒苹果,后来小明还了小黄1粒苹果,结果小明还欠小黄一粒苹果 ”,初中的笔者又恍然大悟。
又在初中,当老师又在黑板上写上如下的内容。那时候的笔者,嘴巴长得大大 ,有好一段时间说不出话来 。好一段时间笔者都是自己在嘀咕....
3 x 4 = 12; " 3粒苹果重复叠加4次,等于12粒苹果"
-3 x 4 = -12; " 欠3粒苹果,重复欠4次,等于欠12粒苹果"
3 x -4 = -12; " 欠4粒苹果,重复欠3次,等于欠12粒苹果"
-3 x -4 = 12; " @#¥%#¥*!%……" ( 嘀咕中... )
读者们不要笑,上述的故事确实是笔者的真实故事。那时候的笔者,真的拿不到整数的乘法的门儿,考试还常常满江红,真的悲剧的初衷时代......
在传统的概念上乘法等价于“重复几次”。打个比方:B = 4;A x B 亦即A要重复加四次才能得到答案。
然而在乘法中“负值正值的关系”就是“异或的关系”。
| A值 |
B值 |
结果 |
| 正(0) |
正(0) |
正(0) |
| 正(0) |
负(1) |
负(1) |
| 负(1) |
正(0) |
负(1) |
| 负(1) |
负(1) |
正(0) |
A x B = C;
3 x 4 = 12;
-3 x 4 = -12;
3 x -4 = -12;
-3 x -4 = 12;
从上面的内容看来,无论A值和B值是什么样的“正值和负值的关系”,结果C都是一样。
那么我们可以换一个想法:
“在作乘法的时候只是我们只要对正值进行操作。然而“负值和正值的结果”,我们用“异或”关系来判断... ”
实验一 :传统的乘法器
该乘法器的大致操作如下:
(一)在初始化之际,取乘数和被乘数的正负关系,然后取被乘数和乘数的正值。
(二)每一次累加操作,递减一次乘数。直到乘数的值为零,表示操作结束。
(三)输出结果根据正负关系取得。
multiplier_module.v
|
|

|
|

第3~11行是该模块的输入输出。看到Start_Sig 和Done_Sig 是仿顺序操作的标志性结构,不明白的去看笔者之前写的笔记。Multiplicand 和Multiplier (被乘数和乘数),都是8位位宽,所以输出Product 是16位位宽。
第16~21行是该模块所使用的寄存器,i寄存表示步骤,Mcand 用来暂存Multiplicand 的正值,Mer 用来暂存Multiplier 的正值,Temp 寄存器是操作空间。然而isNeg 标志寄存器是用来寄存Multiplicand 和Multiplier 之间的正负关系。
在步骤0(36~45行)是初始化的步骤。第39行isNeg寄存“乘数和被乘数之间的正负关系”。第40行,Mcand寄存 Multiplicand 的正值,该行表示:如果被乘数的符号位是逻辑1的话,就将负值转换为正值,然后Mcand寄存该值,否则Mcand直接寄存Multiplicand 的值。第41行是用来寄存Multiplier 的正值,该行的操作和40行很相识。
在步骤1(47~49行),是“重复加几次”的操作。Temp寄存器的每一次值的叠加,Mer寄存就递减(49行)。直到Mer的值等于0(48行),就进入下一个步骤。步骤2~3是产生完成信号。
在62行,Product输出信号的输出值是由isNeg寄存器作决定,如果isNeg是逻辑1,那么Temp的结果从负值转换为正值。否则直接输出Temp的值。
multiplier_module.vt
|
|

第16~22行是复位信号和时钟信号的激励。第26~35行是multiplier_module.v 的实例化。
第39行以下和普通的仿顺序操作的写法一样,不明白的话请看笔者以往写过的笔记。
步骤0~3, 会输入不同的乘数和被乘数来激励multiplier_module.v。
仿真结果:

实验说明:
其实传统的乘法器是很容易的,但是短整数的出现,负值和正值随着出现,使得设计上难以下手。但是只要掌握负值和正值的关系以后,乘法只作正值也“无问题”。只要在输出下一点手脚就行了。
实验结论:
传统的乘法器虽然简单,但是它有一个致命的问题。就是被乘数越大就越消耗时钟。具体的原因在下一章节解释......
1.3 传统乘法器的改进
Verilog HDL 语言所描述的乘法器的消耗是以“时钟”作为时间单位。反之,组合逻辑所建立的乘法器是以“广播时间”作为时间单位。说简单点就是,Verilog HDL 语言所描述的乘法器“快不快”是根据“时钟消耗”作为评估。
假设A = 10 , B = 20, A x B ,那么时钟的消耗至少需要20个,因为A值需要累加20次才能得到结果。到底有没有什么办法,改进这个缺点呢?
有学过乘法的朋友都知道A ( B ) = B ( A )。如果以实验一的乘法器作为基础,那么A( B ) 和B( A ) 所消耗的时间就不一样了。所以我们可以这样改进:
如果被乘数小于乘数,那么被乘数和乘数互换。
{ Multiplier , Multiplicand } = Multiplicand < Multiplier ? { Multiplicand ,Multiplier } :
{Multiplier ,Multiplicand };
举个例子:Multiplicand = 2 ,Multiplicand = 10 ;
更换之前 被乘数2 需要10次的累加,才能得到结果。 更换之后 被乘数为10 乘数为2,亦即被乘数10只要累加2次就能得到结果。
如此一来,可以减少不少时钟的消耗。
实验二: 传统乘法器改进
和实验一相比,在进行累加操作之间,多了一个被乘数和乘数比较的步骤。
(一)在初始化之际,取乘数和被乘数的正负关系,然后取被乘数和乘数的正值。
(二)乘数和被乘数比较,如果被乘数小于乘数,结果乘数和被乘数互换。
(三)每一次累加操作,递减一次乘数。直到乘数的值为零,表示操作结束。
(四)输出结果根据正负关系取得。
multiplier_module_2.v
|
|

|
|

和实验一先比,添加了一个比较的步骤(46~49行)。仿真结果:
仿真.vt 文件和实验一样。

在仿真的结果上,10 x 2 和2 x 10 的时钟消耗都一样。
实验说明:
与实验一的乘法器比较,关于时钟的消耗多少都有改进。
实验结论:
传统的乘法器无论如何改进也好,当遇见如127 x 127 的乘数和被乘数,咋也看不出什么优化......
1.4 补码君存在的意义
每一个人都有存在的意义,有的人用一生的时间去寻找自己的存在意义,有的人则是经过生活的大反转,看到了自己存在意义,有的人则不闻不问... 当然补码也有存在的意义,只是在前面的实验被笔者滥用而已。
补码不仅可以执行正值和负值转换,其实补码存在的意义,就是避免计算机去做减法的操作。
1101 -3补
+ 1000 8
0101 5
假设-3 + 8,只要将-3 转为补码形式,亦即0011 => 1101,然后和8,亦即1000相加
就会得到5,亦即0101。至于溢出的最高位可以无视掉。
1101 -3补
+ 1110 -2补
1011 -5补
其实你知道吗,如Quartus II 综合器 ,当我们使用“-”算术操作符的时候,其实就是使用补码的形式,具体如下:
A = 8'd5;
B = 8'd9;
A -B 等价于A + ( ~B + 1'b1 );
在实际的操作中,综合器都会如上优化。
1.5:Booth算法乘法器
传统的乘法器是有极限的,因此位操作乘法器就出现了。笔者在网上冲浪找资源的时候,还常常撞到许多稀奇古怪的位操作乘法器。但是有一种位操作乘法器,吸引了笔者的眼球,它就是Booth算法乘法器。实际上Booth 算法是一种“加码”乘法运算。
Booth 算法的概念也很简单,我们先从数学的角度去理解看看:
| B[0] |
B[-1] |
加码结果 |
| 0 |
0 |
0(无操作) |
| 0 |
1 |
1(+被乘数) |
| 1 |
0 |
1(-被乘数) |
| 1 |
1 |
0(无操作) |
B[-1] 是什么?先假设B是2的,然而B的最低位的右边后一个“负一位”那就是B[-1]。
0010 0 // LSB 右边出现的就是-1位
那么上面那个加码表和乘法又有什么关系呢?其实要加码的目标是“乘数”,假设乘数为2, 那么乘数2的加码过程会是如下。
| 一开始的时候在乘数2的“负一位”加上一个默认0值 |
0010 0 |
| 先判断[0: -1],结果是2'b00,表示“0”亦即没有操作 |
0010 0 |
| 判断[2: 1],结果是2'b01,表示“1”亦即“-被乘数”操作 |
0010 0 |
| 判断[1: 0],结果是2'b10,表示“1”亦即“+被乘数”操作 |
0010 0 |
| 判断[3: 2],结果是2'b00,表示“0”亦即没有操作 |
0010 0 |
举个例子,被乘数为7,0111; 乘数为2,0010;结果会是什么?
| 0111 - A被乘数 0010 0 - B乘数 ========== 0110 - 乘数加码 ========== 0000 0 111001 1 (- 7) 0111 1 (+7) 0000 0 ========== 0001110 14 ========== |
从左边的操作过程中,我们可以看到乘数被加码以后, 操作的结果是14。 |

从数学的角度看来,确实Booth算法是麻烦的存在,但是在位操作的角度来看就不是这么一回事。实际上在千奇百怪的位操作乘法中,Booth算法其中可以容纳“补码”亦即“负数”来执行操作。
| B[0] |
B[-1] |
加码结果 |
| 0 |
0 |
无操作,右移一位 |
| 0 |
1 |
+被乘数,右移一位 |
| 1 |
0 |
-被乘数,右移一位 |
| 1 |
1 |
无操作,右移一位 |
上面的图表是位操作时候的Booth 算法。Booth算法在位操作的时候,它使用一个很有个性的空间,就是P空间。
先假设:被乘数A 为7 (0111),乘数B为2 (0010) ,它们n均为4位,所以P空间的容量是n x 2 + 1 , 亦即9 位。
_ _ _ _ _ _ _ _ _ // P空间
那么P空间如何实现乘法的位操作呢?
| 一开始先求出-1 (被乘数) |
A = 0111,A= 1001 |
| 然后初始化P 空间, 默认为0 |
P = 0000 0000 0 |
| P空间的[4..1] 填入乘数 |
P = 0000 0010 0 |
| 判断P[1:0],是2'b00 亦即“无操作” |
P = 0000 0010 0 |
| 判断P[8], 如果是逻辑0右移一位补0,反之补1。 |
P = 0000 0001 0 |
| 判断P[1:0],是2'b10 亦即“-被乘数”。 |
P = 0000 0001 0 |
| P空间的[8..5] 和 被乘数 A相加。 |
P = 0000 0001 0 + 1001 P = 1001 0001 0 |
| 判断P[8], 如果是逻辑0右移一位,补0,反之补1 |
P = 1100 1000 1 |
| 判断P[1:0],是2'b01 亦即“+被乘数”。 |
P = 1100 1000 1 |
| P空间的[8..5] 和 被乘数 A 相加。 |
p = 1100 1000 1 + 0111 P = 0011 1000 1 无视最高位溢出 |
| 判断P[8], 如果是逻辑0右移一位补0,反之补1 |
P = 0001 1100 0 |
| 判断P[1:0],是2'b00 亦即“无操作” |
P = 0001 1100 0 |
| 判断P[8], 如果是逻辑0右移一位,补0,反之补1 |
P = 0000 1110 0 |
| 最终P空间的[8..1] 就是最终答案。 |
P = 0000 1110 0 |
从上面的操作看来,由于乘数和被乘数均为n 位所以 “判断P[1:0],后操作,之后移位”的操作仅执行四次而已。
|
|
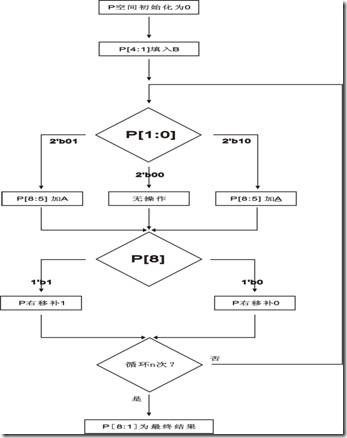
如左边的循环图。A为被乘数,A为被乘数补码形式(-1(A) ),B为乘数,n为乘数和被乘数的位宽,P为操作空间。
一开始P空间会初始化,然后P空间的[4..1] 位会填入B。然后进入P[1:0]的判断。每一次的判断过后的操作都会导致P空间右移一次,至于右移过后的最高位是补0还是补1,是由当时P[8]说了算。
当循环n 次以后,最终结果会是P[8:1]。 |
实验三:Booth算法乘法器
实验中建立的Booth算法乘法器大致的步骤正如1.5章节所描述的那样。
booth_multiplier_module.v
|
|

|
|
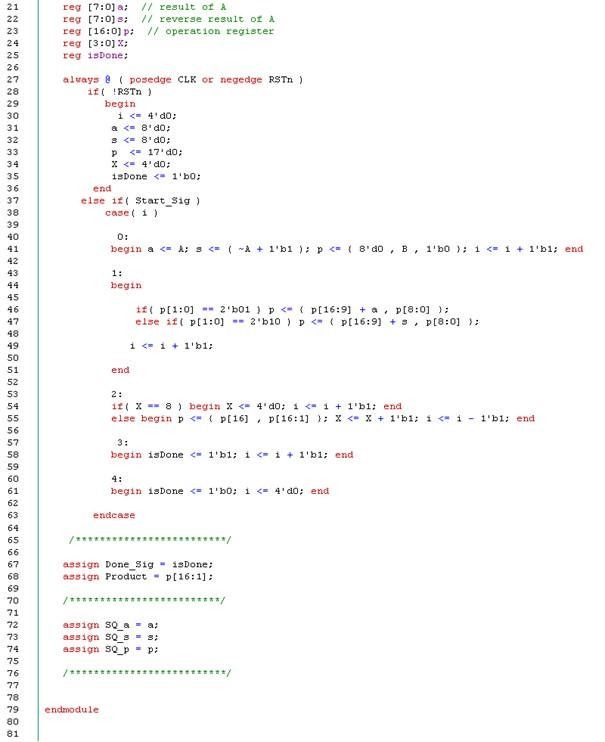
第13~15行是仿真的输出(S - Simulation , Q - Output)。第20~25行定义了该模块所使用的寄存器。a寄存器用来寄存A 值,s寄存器用来寄存-1(A) 的值,p寄存器是P空间。输入信号A和B均为8位位宽,所以p寄存器是17位位宽。至于X寄存器是用来表示n位,用来指示n 次循环。
步骤0(40~41行),初始化了a,s寄存器。p[8:1]填入B值,亦即乘数,其余的位均为0值。
步骤1(43~51行)是用来判断p[1:0] 的操作。步骤2(53~55行)是执行右移一位,是补0还是补1,完全取决于p[16]。步骤1~2会重复交替执行,直到X的值达到8次,就会进入下一步步骤。
步骤3~4(57~61行)是用来产生完成信号。第68行输出信号product 是由p空间的[16..1]来驱动。第72~74行是仿真用的输出信号,功能如字面上的意思。
booth_multiplier_module.vt
|
|
|
|

在仿真中,从步骤0~3(59~73行),激励了不同A和B的值(被乘和数乘数)。
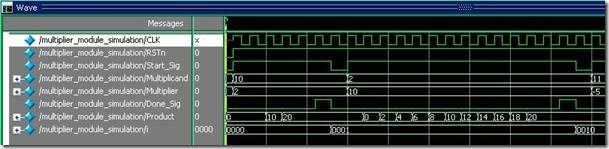
仿真结果:

P空间的详细操作过程,自己代开modelsim看吧,界面有限的关系。从仿真结果上可以看到,4次的乘法操作所使用的时间都一样,尤其是-127 x -127 的情形,不像传统乘法器那样累加127次,才能得到结果。(p空间的[ Width :1]是用来填入乘数B,然而p空间的[Width * 2 : Width + 1 ] 是用来执行和被乘数A的操作)
实验结论:
按常理来说8位的乘数和被乘数,位操作会是使用8个时钟而已,但是实验3的乘法器,需要先操作后移位的关系,所以多出8个时钟的消耗......
1.6 笔者情有独钟的步骤i
在笔者初学Verilog HDL语言,笔者老是捉不好Verilog HDL 语言和时序的关系,吃了不少苦头。世界就是很巧妙,脑子里就忽然间冒出步骤i。
步骤i是什么?
有关《Verilog HDL 那些事儿》那本笔记,虽然笔者的实例都和“它”有关。但是在笔记中,笔者只是微微的带过“步骤i是仿顺序操作相关的写法... ”。但是要探讨步骤i是什么,那不是初学Verilog HDL 的任务。步骤i的用法很简单,从概念上和“顺序操作”很类似,它可以补助初学者不必过度依赖功能仿真,也能“从代码中看到时序”。
如果从低级建模的角度去探讨步骤i,低级建模里面有一个准则,就是“一个模块一个功能”,步骤i好比这个准则的支持者。步骤i从0开始,表示了这个模块开始工作,直到i被清理,这也表示了这个模块已经结束工作。或者可以这样说“一个模块不会出现两个步骤i”。
具体上,步骤i的“值”是指示着“第几个时钟沿”发生,然而Verilog HDL语言里的“步骤”和C语言里的“步骤”是不一样。C语言里的“步骤”就好比“把大象放进冰箱需要几个步骤... ”。相反的Verilog HDL 语言里的“步骤”,有如“时间点”的观念。

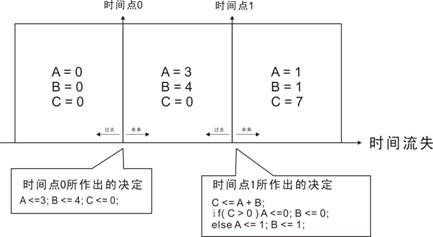
如上面的示意图所示, 在这个时间点里所发生的“决定”会产生不一样的未来。然而在这个时间点里“可以允许不同的决定在这一刻存在”。举一个例子:A的初值是4,B的初值是0。
case( i )
0:
begin A <= A + 2'd2; B <= B + 2'd3; i <= i + 1'b1; end
1:
if( A > 3 ) begin B <= A; A = 0; i <= i + 1'b1; end
else if i <= i + 1'b1;
咋看是一个简单的代码,但是你知道里边包含的秘密吗?
在i = 0的时候,A 累加2,B 累加3。
在i = 1的时候,如果A大于3,就B寄存A的值将A清零。
无论是i等于0还是等于1,它们“只是这一时间点发生的决定”,结果会在这个时间点的过后发生。如果用“生动”的话来描述的话。
在时间点0的时候,这个模块决定A累加2,B累加3。然后在时间点0过后,结果就产生。直到迎来下一个时间点,这个模块才能再一次作决定。
在时间点1的时候,这个模块判断A是否大于3。那么,问题来了“这个模块是以什么作为基础,判断A大于3呢?”。答案很简单就是“时间点1的过去的结果”或者说“在时间点0过后所产生的结果”。

上图完全将上述的内容表达了出来。在这里笔者有一个很在意的问题,那就是"<=" 赋值操作符。在众多的参考书中“<=”赋值操作符被解释为“时间沿有效的赋值操作符”。笔者初学的时候的,完全不知道它是虾米... 如果换做时间点的概念来说“<=”的操作符,表示了“在这个时间点下决定”专用的赋值操作符。
与“=”赋值操作符不一样,它是没有时间点的概念的赋值操作符。所以在always @ ( posedge CLK ... ) 有效区域内,它是不适合使用,因为它会破坏这个模块的时间和结果。
我们的人生,下错了决定只要知错,吸取教训还有从来的机会。但是模块下错了决定,就影响它的一生,所以我们在编辑的时候要特别小心,不然会可能因我们的疏忽,导致了这个模块的一生悲剧。
小时候,笔者读道德教育的时候,有一句话是笔者一生受用,那就是“先三思而后行”。
这个又和上述的内容有什么关系呢?
我们知道“时间点”的概念就是“就是在这个时间点决定了什么,这个时间点的过后会产生什么”。难道模块的世界就是那么现实, 就连三思的机会也没有吗?这是一个很好的问题......
举个例子,有一个模块他有A ,B和C三个寄存器,它们的初值都是0:
case( i )
0:
begin A <= 3; B <= 4; C <= 0; i <= i + 1'b1; end
1:
begin
C <= A + B;
if( C > 0 ) begin A <= 0; B <= 0 ; end
else begin A <= 1; B <= 1; end
i <= i + 1'b1;
end
从上面的代码,我们可以知道。在时间点0,该模块决定了A 等于3,B等于4,C等于0。然后到了时间1, 问题来了“在时间点1,该模块是以什么作为基础去判断C 的值呢?是时间点1过去的C值,还是在这一个瞬间A + B 所产生的值?”。
答案如上图所示,if是以时间点1过去的C值作为判断的基础。所以说模块的现实是很残忍的,它们不但没有重来的机会,就连“思考”的时间也不给它。它们"只能以当前时间点过去的值,作为当前时间点下决定的参考...... ( 写到这里, 笔者流泪了! )
实际上“=”不是不可以在always @ ( posedge CLK ... ) 里出现,只不过它比较危险。
case( i )
0:
begin A <= 3; B <= 4; C <= 0; i <= i + 1'b1; end
1:
begin
C = A + B;
if( C > 0 ) begin A <= 0; B <= 0 ; end
else begin A <= 1; B <= 1; end
i <= i + 1'b1;
end
笔者将上面的代码稍微修改了一下, 在步骤1 变成了C = A + B。
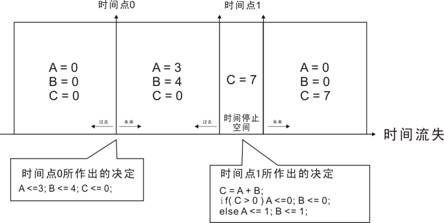
如果把步骤i按照“时间点”的概念,结果会是如上图。在时间点1,“=”造成了一个而外的时间停止空间,在这个空间里C 不但可以“作决定”,而且“即时得到结果”。在某种程度上,它的存在会破坏和谐,如果没有步骤i的控制,它很容易暴走。笔者在设计模块中,除非出现“不得已”的情况,否则笔者在always @ ( posedge CLK ... )区域内,绝对不会使用它。
1.7 Booth算法乘法器的改进
在实验三中所建立的Booth算法乘法器,要完成一次乘法计算,至少要消耗16个时钟,而且其中8个时间就是消耗在移位的方面上。那么有什么办法改进 实验三中的Booth算法乘法器呢?
在1.6章节,笔者说了步骤i有如时间点的概念,假设我这样修改实验三的Booth乘法器 :
case ( i )
0: ... 初始化
1,2,3,4,5,6,7,8:
begin
if( p[1:0] == 2'b01 ) p <= { p[16] , p[16:9] + a , p[8:1] };
else if( p[1:0] == 2'b10 ) p <= { p[16] , p[16:9] + s , p[8:1]};
else p <= { p[16] , p[16:1]};
i <= i + 1'b1;
end
从上面的代码,读者能看出什么破绽吗?我们尝试回忆Booth算法的流程图,先判断p[1:0] 的操作,然后右移一位,最高位补0还是补1,是取决与 经p[1:0]操作之后的p[16]。
那么问题来了,从上面的代码看来p <= { p[16] , p[16:9] + a , p[8:1]}; 其中的p[16] 是以当前时间点的过去值作为基础,而不是p[1:0]操作过后的值, 所以上面的代码不行!
case( i )
0: ... 初始化
1,2,3,4,5,6,7,8:
begin
Diff1 = p[16:9] + a; Diff2 = p[16:9] +s;
if( p[1:0] == 2'b01 ) p <= { Diff1[7] , Diff1 , p[8:1]};
else if( p[1:0] == 2'b10 ) p <= { Diff2[7] , Diff2 , p[8:1]};
else p <= { p[16] , p[16:1]};
i <= i + 1'b1;
end
上面的代码表示了,在步骤1~8里Diff1 寄存了p[16:9] + a 的结果,反之Diff2 寄存了p[16:9] + s的结果。然后判断p[1:0] 再来决定p 的结果是取决于Diff1 ,Diff2 或者其他。和第一段的代码不同,第二段代码的p输出值是一致的。在这里有一个重点是,Diff1 和Diff2 没有使用“<=”而是使用“=”,换一句话说,Diff1 和Diff2 结果的产生在“该时间点作决定的时候”,亦即“取得即时的结果”,而不是该时间点过后,才产生结果。
实验四:Booth算法乘法器改进
基于实验三的Booth算法乘法器,从原先的一次乘法需要16次、个时钟,优化至8个时钟。
booth_multiplier_module_2.v
|
|

|
|

同样是Booth 算法的原理,和实验三不同的是在55~67行,是步骤1~8的循环操作。不再使用X寄存器作为循环计数,而是直接使用步骤来指示8个循环操作。在55~67行,这样的写法有一个好处,就是可以使得p的值输出一致,因此可以减少8个时钟。
仿真结果:

实验四所使用的.vt 文件和实验三的一样。
从仿真结果看来,一次的乘法操作只消耗8个时钟而已(步骤0初始化,和步骤9~10完成信号产生除外)。现在我们把上面的仿真结果切成一块一块的来看。
|
|
00000000 10000001 0 值左边上升沿开始,即是第一个时间点i = 0,亦即步骤0。步骤0之后就是初始化的结果。S是取反过后的a值,并且填充在p空间的[8:1]。 |
|
|
00000000 10000001 0 值右边的上升沿,亦即步骤1。此时: Diff1 寄存过去的p[16:9] + a ,亦即00000000 + 10000001, 结果为10000001。Diff2 寄存过去的p[16:9] + s,亦即00000000 + 01111111, 结果为01111111。经步骤1的“决定”,过去p[1:0]是 2'b10 ,所以p值的未来是{ Diff2[7] , Diff2 , p过去[8:1] }, 亦即 0 01111111 10000001。 |
|
|
00111111 11000000 1 值右边的上升沿,亦即步骤2。此时: Diff1 寄存过去的p[16:9] + a ,亦即00111111 + 10000001, 结果为11000000。Diff2 寄存过去的p[16:9] + s,亦即00111111 + 01111111, 结果为10111110。经步骤2的“决定”,过去p[1:0]是 2'b01 ,所以p值的未来是{ Diff1[7] , Diff1 , p过去[8:1] }, 亦即 1 11000000 11000000。 |
|
|
11100000 01100000 0 值右边的上升沿,亦即步骤3。此时: Diff1 寄存过去的p[16:9] + a ,亦即11100000 + 10000001, 结果为01100001。Diff2 寄存过去的p[16:9] + s,亦即11100000 + 01111111, 结果为01011111。经步骤3的“决定”,过去p[1:0]是2'b00 ,所以p值的未来是{ p过去[16] , p过去[16:1] }, 亦即 1 11100000 01100000。 |
|
|
11110000 00110000 0 值右边的上升沿,亦即步骤4。此时: Diff1 寄存过去的p[16:9] + a ,亦即11110000 + 10000001, 结果为01110001。Diff2 寄存过去的p[16:9] + s,亦即11110000 + 01111111, 结果为01101111。经步骤4的“决定”,过去p[1:0]是2'b00 ,所以p值的未来是{ p过去[16] , p过去[16:1] }, 亦即 1 11110000 00110000。
|
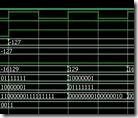

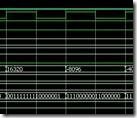

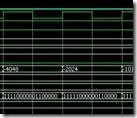
|
|
11111000 00011000 0 值右边的上升沿,亦即步骤5。此时: Diff1 寄存过去的p[16:9] + a ,亦即11111000 + 10000001, 结果为01111001。Diff2 寄存过去的p[16:9] + s,亦即11111000 + 01111111, 结果为01110111。经步骤5的“决定”,过去p[1:0]是2'b00 ,所以p值的未来是{ p过去[16] , p过去[16:1] }, 亦即 1 11111000 00011000。
|
|
|
11111100 00001100 0 值右边的上升沿,亦即步骤6。此时: Diff1 寄存过去的p[16:9] + a ,亦即11111100 + 10000001, 结果为01111101。Diff2 寄存过去的p[16:9] + s,亦即11111100 + 01111111, 结果为01111011。经步骤6的“决定”,过去p[1:0]是2'b00 ,所以p值的未来是{ p过去[16] , p过去[16:1] }, 亦即 1 11111100 00001100。
|
|
|
11111110 000001100 0 值右边的上升沿,亦即步骤7。此时: Diff1 寄存过去的p[16:9] + a ,亦即11111110 + 10000001, 结果为01111111。Diff2 寄存过去的p[16:9] + s,亦即11111110 + 01111111, 结果为01111101。经步骤7的“决定”,过去p[1:0]是2'b00 ,所以p值的未来是{ p过去[16] , p过去[16:1] }, 亦即 1 11111110 00000110。
|
|
|
11111111 00000011 0 值右边的上升沿,亦即步骤8。此时: Diff1 寄存过去的p[16:9] + a ,亦即11111111 + 10000001, 结果为10000000。Diff2 寄存过去的p[16:9] + s,亦即11111111 + 01111111, 结果为 01111110。经步骤8的“决定”,过去p[1:0]是2'b10 ,所以p值的未来是{Diff2[7] , Diff2, p过去[8:1] }, 亦即 0 01111110 00000011。
最终结果取值未来p[16:1] ,00111111 00000001 亦即16129。 |
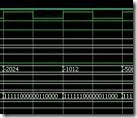



实验说明:
如果以“大象放进冰箱”这样的概念去理解步骤i,在实验四中可能会产生许多思考逻辑上的矛盾。换一个想法,如果以“时间点”的概念去理解步骤i的话,从仿真图看来是绝对逻辑的。(再唠叨的补充一下,p空间的[ Width :1]是用来填入乘数B,然而p空间的[Width * 2 : Width + 1 ] 是用来执行和被乘数A的操作)
实验结论:
这一章节笔记的重点不是要“如何如何实现一个算法”,而是“以不同概念的理解去完成乘法器的改进”。
1.8 LUT乘法器
从1.8章节以前的乘法器都可以归纳为“慢速乘法器”,当然它们不是真正意义上的慢,只不过它们无法达到急性一族人的任性而已。LUT乘法器,又成为查表乘法器。用傻瓜的话来说,就是先吧各种各样的结果储存在一个表中,然后将输入资源以“查表”的方式,许对比“等于的结果”。
举个例子,笔者先建立一个16 x 16 正值的查表:
|
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| 0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| 2 |
0 |
2 |
4 |
6 |
8 |
10 |
12 |
14 |
16 |
18 |
20 |
22 |
24 |
26 |
28 |
30 |
| 3 |
0 |
3 |
6 |
9 |
12 |
15 |
18 |
21 |
24 |
27 |
30 |
33 |
36 |
39 |
42 |
45 |
| 4 |
0 |
4 |
8 |
12 |
16 |
20 |
24 |
28 |
32 |
36 |
40 |
44 |
48 |
52 |
56 |
60 |
| 5 |
0 |
5 |
10 |
15 |
20 |
25 |
30 |
35 |
40 |
45 |
50 |
55 |
60 |
65 |
70 |
75 |
| 6 |
0 |
6 |
12 |
18 |
24 |
30 |
36 |
42 |
48 |
54 |
60 |
66 |
72 |
78 |
84 |
90 |
| 7 |
0 |
7 |
14 |
21 |
28 |
35 |
42 |
49 |
56 |
63 |
70 |
77 |
84 |
91 |
98 |
105 |
| 8 |
0 |
8 |
16 |
24 |
32 |
40 |
48 |
56 |
64 |
72 |
80 |
88 |
96 |
104 |
112 |
120 |
| 9 |
0 |
9 |
18 |
27 |
36 |
45 |
54 |
63 |
72 |
81 |
90 |
99 |
108 |
117 |
126 |
135 |
| 10 |
0 |
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
100 |
110 |
120 |
130 |
140 |
150 |
| 11 |
0 |
11 |
22 |
33 |
44 |
55 |
66 |
77 |
88 |
99 |
110 |
121 |
132 |
143 |
154 |
165 |
| 12 |
0 |
12 |
24 |
36 |
48 |
60 |
72 |
84 |
96 |
108 |
120 |
132 |
144 |
156 |
168 |
180 |
| 13 |
0 |
13 |
26 |
39 |
52 |
65 |
78 |
91 |
104 |
117 |
130 |
143 |
156 |
169 |
182 |
195 |
| 14 |
0 |
14 |
28 |
42 |
56 |
70 |
84 |
98 |
112 |
126 |
140 |
154 |
168 |
182 |
196 |
210 |
| 15 |
0 |
15 |
30 |
45 |
60 |
75 |
90 |
105 |
120 |
135 |
150 |
165 |
180 |
195 |
210 |
225 |
假设A x B,它们均为4位,A为10,B为2,那么结果会是20。查表乘法器之所以被称为快速乘法器,就是上面的原因( 实际上许多硬件乘法器都是使用查表的方式)。
如果A x B ,它们均为8位,那么应该如何呢?难道再建立一个256 x 256 乘法器!?这样会死人的。
不知道读者有没有听过Quarter square 乘法查表呢?

上边是该算法的公式,在公式的结束得到ab = ( ( a + b )2 )/4 - ( ( a - b )2 )/4 。
如果再进一步细分的话,无论是( a + b )2/4 或者( a - b )2/4,经过幂运算后,得到的结果都是正值。
假设a 和b的位宽都是8 位的短整数话( 127 + 127 )2 / 4 = ( -127 - 127 )2 / 4。那么我们可以得到一个结论“( a + b )2/4 或者( a - b )2/4 使用同样的(C)2/4 查表”。
那么我们建立一个C = 0 ~ 255 ,并且内容是(C)2/4 的查表。
|
|
|

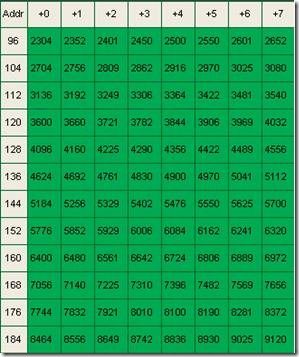
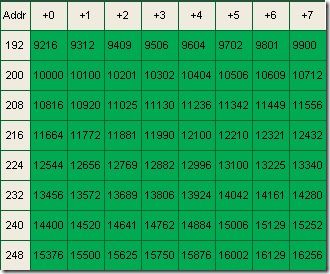
这个查表的寻址虽然是0~255,但是实际上下限是254而已。因为我们知道两个短整数最大值相加仅有-127 + -127 = -254 或者127 + 127 = 254 。
那么问题来了, 短整数的最大取值范围是-127 ~ 127 而已,何来寄存-254 ~ 254 呢?
这里我们就涉及了“不同容量空间的相互赋值”。假设C 是9位位宽的不正规整数
,然而A 和B 都是8位位宽的正规整数,那么C = A + B ?
| C = A + B |
等价于 |
C = { A[7], A } + { B[7], B } |
| A = 127 (0111 1111) B = 127 (0111 1111)
A 0111 1111 B 0111 1111 + C 01111 1110 |
等价于 |
A = 127 (00111 1111) B = 127 (00111 1111)
A 00111 1111 B 00111 1111 + C 01111 1110
|
|
A = -127 (1000 0001) B = -127 (1000 0001)
A 1000 0001 B 1000 0001 + C 10000 0010
|
等价于 |
A = -127 (11000 0001) B = -127 (11000 0001)
A 11000 0001 B 11000 0001 + C 10000 0010
|
接下来,我们来看一看下面的代码:
reg [8:0]I1,I2;
case( i )
0:
begin
I1 <= { A[7], A } + { B[7], B }; // C =A + B;
I2 <= { A[7], A } + { ~B[7], ( ~B + 1'b1 ) }; // C = A - B;
i <= i + 1'b1;
end
1: // 取正值
begin
I1 <= I1[8] ? ( ~I1 + 1'b1 ) : I1;
I2 <= I2[8] ? ( ~I2 + 1'b1 ) : I2;
i <= i + 1'b1;
end
上面的I1 和I2 均为9位位宽。在步骤0,I1表示了C = A + B,相反的I2 表示了C = A - B。由于短整数的赋值采用补码的表示方式,所以大大简化了正负转换的操作。
假设A = -1 ( 1111 1111 ) , B = -3 ( 1111 1101 ), 经过上面步骤0的操作:
I1 = { 1 11111111 } + { 1 1111 1101 } = 1 1111 1100 (-4) 等价于I1 = -1 + -3 = -4
I2 = { 1 11111111 } + { 0 0000 0011 } = 0 0000 0010 ( 2) 等价于I2 = -1 - (-3) = -1 + 3 = 2
步骤1是I1 和I2 从负值转换为正值。
假设I1 = -4 (1 111 1100) ,I2 = 2 (0 0000 0010), 经过步骤1的操作:
I1 = 0 0000 0011 + 1 = 0 0000 0100;
I2 = 0 0000 0010;
为什么在步骤1中,要特意将负值转换为正值呢?笔者在前面已经说过,无论是(-C)2 还是(C)2 取得的结果都是一至。为了两者I1 和I2 共用相同的查表这是必须的步骤。
如果用I1和I2 来表达Quarter square 公式,那么:
( | I1 |2 / 4 ) - ( | I2 |2 / 4 )
实验五:基于Quarter square 的查表乘法器
首先笔者手动建立0~255 关于(C)2/4 结果的lut_module.v ,因为用Quartus II建立的rom 仿真不给力,很别扭。
lut_module.v
|
|
|
|

|
|

|
|

|
|
|
|

这是我目前,贴过最长的.v 文件了...
lut_multiplier_module.v
这个模块的功能很简单。首先取得I1 = A + B ,I2 = A - B,然后I1 和I2 都正值值,将I1 和I2 送至各自的查表,然后将得出的结果Q1_Sig (I1的结果) 和Q2_Sig
(I2的结果) , 执行相减。实际上是补码形式的相加,Q1_Sig + ( ~Q2_Sig + 1'b1 ) ,以致符合Quarter square的公式:
( a + b )2/4 - ( a - b )2/4 = ( |I1| )2/4 + [ ( |I2| )2/4]补
= Q1_Sig + [Q2_Sig]补
|
|

|
|

第15~18行是仿真的输出。第26~27行建立Q1_Sig 和Q2_Sig ,实际上这两个线型数据是U1(81~87行)和U2(91~97行) 实例前申明的,可是modelsim 那么混蛋,偏偏就不给我通过。
从37~77行是该模块的主功能。步骤0(49~54行)是取I1 和I2 的值。步骤1(56~61行)是I1和I2的正值化操作。步骤2(63~64行)是延迟一个时钟,给予足够的时间从lut_module.v读出结果。步骤3(66~67行),是Quarter square公式操作的最后一步。
89~99行是lut_module.v 的实例化 ,U1是给I1使用 ,U2是给I2使用,它们的输出连线分别是Q1_Sig 和Q2_Sig 。102行的Product 输出信号由Data寄存器驱动。然而106~109行是仿真输出的驱动,分别有I1 , I2 ,Q1_Sig 和Q2_Sig 的仿真输出。
lut_multiplier_module.vt
|
|

|
|

.vt 文件的写法和之前的实验都一样,如果真的不知道笔者在写什么,就得好好看笔者之前写的笔记。
仿真结果:

看吧!一次的乘法操作仅需4个时钟的而已。比起改进的Booth算法减少了一半的时钟消耗。真不愧是查表式的乘法器,佩服佩服。
实验结论:
说实话查表式的乘法器是“以空间换时间”的乘法器,所以说查表式的乘法器是很消耗空间。到底有什么乘法器“可以节约空间,又节省时钟”呢?
你知道吗?传统查表的乘法器都有一个僵局,假设A(B),那么其中一个变量需要是“恒数”,否则建立查表的工作是非常的劳动。但是Quarter square 公式的出现把这个僵局给打破。感谢前人的努力吧,我们后人才能乘凉......
1.9 Modified Booth 算法乘法器
事先声明modified booth 算法 和 改进的booth 算法乘法器(实验四)是没有任何关系的。如字面上的意思modified booth 算法是booth 算法的升级版。我们稍微来回味一下booth 算法。
假设B是4位位宽的乘数,那么booth 算法会对B[0: -1] , B[1:0], B[2:1], B[3:2] 加码,而使得乘法运算得到简化。booth 算法有典型数学做法,也有位操作的做法。Modified booth 算法比起booth 算法,对于4位位宽B乘数的加码返回会更广,而使得n/2 乘法运算的优化。再假设B是4微微款的倍数,那么modified booth 算法会对B[1:-1] , B[3:1] 执行加码。
如果站在位操作的角度上:
| B[1] |
B[0] |
B[-1] |
操作结果 |
| 0 |
0 |
0 |
无操作,右移两位 |
| 0 |
0 |
1 |
+被乘数,右移两位 |
| 0 |
1 |
0 |
+被乘数,右移两位 |
| 0 |
1 |
1 |
右移一位,+被乘数,右移一位 |
| 1 |
0 |
0 |
右移一位,-被乘数,右移一位 |
| 1 |
0 |
1 |
-被乘数,右移两位 |
| 1 |
1 |
0 |
-被乘数,右移两位 |
| 1 |
1 |
1 |
无操作,右移两位 |
Modified booth 算法同样也有使用p空间,假设乘数A,和被乘数B,均为4位,那么p空间的大小n x 2 + 1 ,亦即9位。乘数A为7 (0111),被乘数B为2 (0010)。
| 先求出+被乘数 和 -被乘数,亦即A 和 A。 |
A = 0111 , A= 1001 |
| P空间初始化为0,然后P空间的[4..1] 填入乘数 亦即B。 |
P = 0000 0000 0 P = 0000 0010 0 |
| 先判断p[2:0],结果是3'b100 亦即“右移一位,-被乘数,右移一位”。 |
P = 0000 0010 0 |
| 右移一位
|
P = 0000 0001 0
|
| p[8:5] 加上 A |
P = 0000 0001 0 + 1001 P = 1001 0001 0 |
| 右移一位 |
p = 1100 1000 1 |
| 判断p[2:0],结果是3'b001 亦即“+被乘数,右移二位”。 |
p = 1100 1000 1 |
| p[8:5] 加上 A |
P = 1100 1000 1 + 0111 P = 0011 1000 1 |
| 右移二位 |
P = 0000 1110 0 |
| 最终取出p[8:1] 就是最终答案8'b00001110 ,亦即14。 |
P = 0000 1110 0 |
关于4 位为位宽的乘数和被乘数操作流程图如下:

说实话modified booth 算法的位操作是很不规则,从上面的流程图可以看到,不同的p[2:0]操作都有“不同的步骤次数”,这也使得它非常不适合作为运用。
实验六:Modified Booth 乘法器
这个模块大致的操作如上述的流程图。
modified_booth_module.v
|
|

|
|
|
|

15~17行是仿真输出。43~94行是该模块的主功能。在步骤0(45~51行)取得被乘数A并且寄存在a寄存器,此外取得-1(被乘数A) 并且寄存在s寄存器。在初始化p空间的同时,将乘数B填入p[8:1]。
(由于被乘数A和乘数B的位宽为8,所以p空间是n x 2 + 1 亦即9。我知道我很长气,但是还是容许笔者补充一下:p空间的[ Width :1]是用来填入乘数B,然而p空间的[Width * 2 : Width + 1 ] 是用来执行和被乘数A的操作)。
步骤1和2(53~62行)是p[2:0] 等于3'b000 | 111 | 001 | 010 | 101 | 110 的操作。相反的,由于modified booth 算法当p[2:0] 等于3'b011 和3'b100 所执行的步骤次数是不一样(56~57行)。
所以在步骤3~5(66~73行)针对 p[2:0] 等于3'b011 的操作(56行)。反之步骤6~8 (77~84行)针对p[2:0] 3'b100 的操作(57行)。
步骤9~10产生完成信号。第102行的product输出信号是由p[16:1]来驱动。第106~109的仿真输出信号,分别由寄存器a ,s 和p来驱动。
modified_booth_multiplier_module.v
|
|

|
|

|
|

这是激励文件,在写这个文件的时候,笔者心情很糟糕,所以在步骤5加入了类似for嵌套循环的东西。其他的和之前的.vt 文件都是大同小异~ 自己看着吧。
仿真结果:
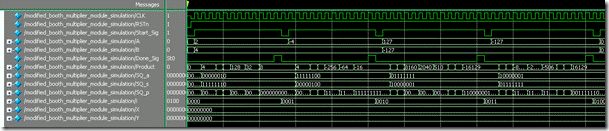
在仿真结果中,可以很明显的看到当2(4) 和127(-127)有明显的时钟消耗差异。
实验结论:
如果Modified booth 算法用在“位操作”,虽然它是快速的乘法操作,但是很多时候它还是很别扭。换句话说,用它还要图运气,因为不同的乘数和被乘数都有不同的时钟消耗......
1.10 Modified Booth 乘法器·改
如果要把Modified Booth 乘法器别扭的性格去掉,我们不得站在“数学的角度”去看modified booth 算法。下表是从数学的角度去看modified booth 针对乘数B的加码。

| B[1] |
B[0] |
B[n-1] |
操作结果 |
| 0 |
0 |
0 |
无操作 |
| 0 |
0 |
1 |
+被乘数 |
| 0 |
1 |
0 |
+被乘数 |
| 0 |
1 |
1 |
+2(被乘数) |
| 1 |
0 |
0 |
-2(被乘数) |
| 1 |
0 |
1 |
-被乘数 |
| 1 |
1 |
0 |
-被乘数 |
| 1 |
1 |
1 |
无操作 |
我们假设A被乘数和乘数B均为4位位宽 :A=7(0111),B=2(0010)。
A = (7) 0000 0111;2A = (14) 0000 1110;-2A = (-14) 1111 0010。
在这里我们必须注意一下当B[1:-1] 等于011 或者100 的时候,4位的被乘数A的取值范围最大是-7 ~ 7 然而,+2(被乘数) 或者 -2(被乘数) 都会使得A的最大值突破取值范围。所以需要从4位位宽的空间向更大的位位宽哦空间转换。这里就选择向8位位宽的空间转换吧。
B乘数加码为B[1:-1] = 3'b100 ,亦即 -2(被乘数) 和B[3:1] = 3'b100 ,亦即 +被乘数。
A 0 1 1 1
B 0 0 1 0 0
==============
+1 -2 B乘数加码
==============
1 1 1 1 0 0 1 0
+ 0 0 0 0 0 1 1 1 << 2 左移两位
===============
10 0 0 0 1 1 1 0 无视超过8位最高位的益处
===============
还记得booth算法在数学角度上的运算吗?4位的乘数和被乘数相乘,乘数必须加码n次,而且乘积也是n 位的次数,亦即4次哦加码操作,和4次的乘积操作。相反的modified booth 算法在数学的角度上运算的话,4位的乘数和被乘数相乘,乘数加码为n位/ 2 次,而且乘积也是n位/2 的次数,亦即2次加码操作,和2次的乘积操作
实验七:Modified Booth 乘法器·改
modified_booth_multiplier_module_2.v
|
|

|
|

第29~27行是该模块所使用的寄存器。a是用来寄存A,a2是用来寄存2A,s是用来寄存-A,s2是用来寄存-2A。M是用来表示每次乘积的偏移量。
由于这个实验不是站在位操作的角度上,所以P空间仅是作为累加空间的存在。作为补偿寄存器N用来判别booth 加码操作,所以寄存器N用于寄存乘数B的值。乘数B是8位位宽,所以N空间的大小是 “乘数B的大小+ 1”。多出来的1个空间是用来寄存B[-1]的值。”
在步骤0(54~65行),是用来初始化所有相关的寄存器。寄存器a,a2,s,s2 在初始化的同时也进行8位 向16位 空间转换。寄存器p和M都清零,至于寄存器N[8:1]是用来填充乘数B,N[0] 填入零值。
步骤1~4(67~79),也就是4次的乘积次数,因为受到n/2 的关系。每一次的乘积操作都是先判别N[2:0],然后累加相关的值。
我们知道传统的乘法,每一次的乘积操作,都有偏移量 ,打个比方。
123
111
=====
123 <= 十进制的第一个乘积是 偏移0,没有左移位操作。
123 <= 十进制的第二个乘积是 偏移10,也就是左移1位。
123 <= 十进制的第三个乘积是 偏移100,也就是左移2位。
=====
同样的道理寄存器M 是用于记录二进制的每一次乘积偏移量,但是modified booth乘法的乘积偏移量是普通2进制乘法乘积偏移量的2被。所以每一次乘积操作结束都左移+2。
至于寄存器N它寄存了B[7:1] + B[-1] 的值。然而每一次用于的判别都是N[2:0],所以每一次的乘积之后,N都需要右移两位。
假设B = 1101 0010 ,N 必然是1101 0010 0。
| 乘积1
B[1:-1] = 100 N = 1101 0010 0 |
乘积2
B[3:1] = 001 N = 0011 0100 1 |
乘积3
B[5:3] = 010 N = 0000 1101 0 |
乘积4
B[7:5] = 110 N = 0000 0011 0 |
为什么说8 位位宽的数据相乘,乘积运算次数是n / 2 ,亦即4。这是Modified booth算法的一个特点。如果站在数学的角度上,他可以节省“乘积次数/ 2”。
第92行的product 输出是由寄存器p驱动。前面笔者说过了,如果站在数学的角度,p空间只是累加空间的作用而已。然而p空间的大小是“乘数和被乘数位宽大小的相加”。
第96~101行是仿真输出信号的被驱动。有一点很特别,除了寄存a, a2, s, s2 和N 以外,笔者还故意将该模块的i 引出,这是为了观察 “Modified booth 乘法使得乘积次数减半”这一事实。在仿真中,SQ_i 从1~4经过,如果输出的结果是真确,那么可以证明Modified booth 算法确实何以减少一半的乘积。
modified_booth_multiplier_module_2.vt
|
|
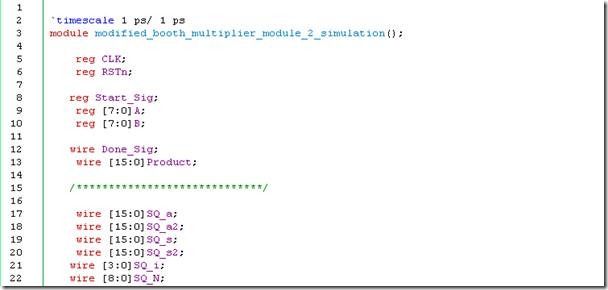
|
|

仿真结果:

从仿真结果上,我们可以看到,每一个乘法操作都消耗同样数目的时钟。此外还有一点, 当SQ_i 等于4 之后,就会得到正确的答案。
实验结论:
实验七和实验六相比,不仅每一次乘法操作时钟消耗都一致,而且这样结果带来一个好处,就是- 实验七和实验六相比比起乘法运算更快。此外,从SQ_i信号等于4之后,product 就输出正确的结果,所以我们可以证明modified booth算法是可以减半乘积的次数。
总结:
从实验一到实验七当中,笔者详细描述出四种乘法器的各有千秋,其中还有几种乘法器笔者还特意去优化和提升它们。从四种乘法器之中,传统乘法器,Booth 乘法器,LUT查表乘法器,和Modified Booth乘法器。LUT乘法器拥有最少的时钟消耗(最快的运算速度),但是LUT乘法器却暴露出消耗资源的弱点。
如果将LUT乘法器排外,自然而然Modified Booth 乘法器成为第二候选人,但是要建立Modified Booth 乘法器需要很好的理论基础,故很多新手都很怕它。至于Booth乘法和是最受欢迎的,如果设计的要求不像DSP那么任性,估计会有很多人喜欢它,因为它中庸,简单,容易亲近。
剩 下的传统的乘法器,它什么都不比上后者,难道我们就要鄙视它吗?这个不然,笔者接触各种各样的乘法,还是托它的副,不然我是不可能如此深入研究整数乘法 器。传统的乘法器,最主要的功能是传达“乘法运算”的概念。正如笔者赞同的一句话:“前人造路,后人走路”,前者们的辛苦应该受到尊敬。
整数乘法器所涉及的知识可真不小,Verilog HDL语言掌握的成熟性姑且不说,而且还涉及诸如补码,整数的表示方法,不同位空间的整数转换等等... 都是一些非常基础的知识。我们所使用的高级语言,如C语言:
int C;
short int A,B;
C = A * B;
假设笔者输入如同上述的代码,实际上我们是不知道和不被允许窥看它里边是如何操作(有传言说,C语言的乘法就是传统的乘法概念... (-_-!))。
虽然这本只有短短50多页的笔记,故事也只是围绕着着“整数乘法器”发展,显然还有很多地方都不给力。但是你知道吗,关于网上“Verilog HDL 整数乘法器”的求救贴已经达到很恐怖的数量,此外还有很多源码和实例都非常不给力,真是非常蛋疼!故笔者才有编辑这本笔记的初衷,虽然这本笔记不是什么非常给力的东西,但是作为参考已经切切有余。
不知道读者们看完这本笔记后又会萌出什么奇怪的想法呢?
来自:http://blog.chinaaet.com/detail/14883.html