SqueezeNet论文与源码阅读
论文下载地址:http://arxiv.org/abs/1602.07360
论文代码:https://github.com/DeepScale/SqueezeNet
前言
SqueezeNet目标设计不是为了得到最佳的CNN识别精度,而是希望简化网络复杂度,同时达到公共网络的识别精度。所以SqueezeNet 主要是为了降低CNN模型参数数量而设计的。
SqueezeNet是一个高密小网络高密小网络的好处,使用更少的参数:
1.更有效分布式训练。
2.客户端更新模型开销更小,从云端可以下载更小的更新模型。
3.灵活的FPGA与嵌入式部署。
设计原则
1. 使用1 * 1的滤波器来代替3×3的滤波器,这样计算量就减少到了1/9。
2. 减少3×3滤波器的输入通道数。
3.将下采样层尽量置于网络后部,以致于卷积层可以拥有更大的激活特征图。中]论文将步长为1的卷积层放到前面,步长大于1的放到网络的后面。激活图越大分类精度越高。
策略1和2主要是为了减少网络的参数。策略3为了提高精度,使得网络不会因为参数的减少而降低分类精度。
消防模块
Fire Module是本文的核心构件,思想非常简单,就是将原来简单的一层卷层变成两层:
挤压层+扩充层,各自带上RELU激活层。
在挤压层里面全是1×1的卷积内核,数量记为S11;
在扩展层里面有1x1的3×3和的卷积内核,数量分别记为E11和E33;
要求S11 <输入地图号即即足上面的设计原则(2)
FIRE MODULE中suqeeze中卷积核的数量要少于expand中卷积核的数量。
expand layer之后将1x1和3x3的卷积输出特征映射在channel维度拼接起来。

具体操作情况:

Fire module输入的feature map为H*W*M的,输出的feature map为H*M*(e1+e3),可以看到feature map的分辨率是不变的,变的仅是维数,也就是通道数,这一点和VGG的思想一致。
首先,H*W*M的feature map经过Squeeze层,得到S1个feature map,这里的S1均是小于M的,以达到“压缩”的目的,详细思想可参考Google的Inception系列。
其次,H*W*S1的特征图输入到Expand层,分别经过1*1卷积层和3*3卷积层进行卷积,再将结果进行concat,得到Fire module的输出,为 H*M*(e1+e3)的feature map。
fire模块有三个可调参数:S1,e1,e3,分别代表卷积核的个数,同时也表示对应输出feature map的维数,在本文提出的SqueezeNet结构中,e1=e3=4s1 。
总体网络架构(两种)
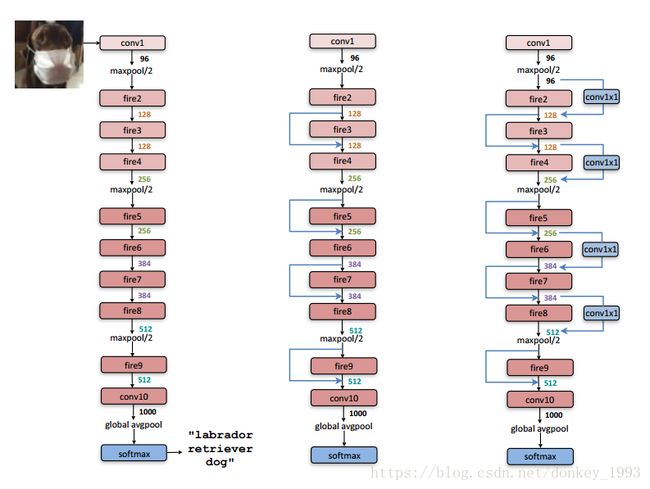
图二 左边是SqueezeNet,右边这两个是它的改进版本。中间为包含simple bypass的改进版本,最右侧为使用complex bypass的改进版本。图中,总共有9层fire module,中间穿插一些max pooling,最后是global avg pooling代替了fc层(参数大大减少)。在开始和最后还有两层最简单的单层conv层,保证输入输出大小可掌握。

整个网络包含10层。
第1层为卷积层(蓝色),缩小输入图像,提取96维特征。
第2到9层为fire模块(红色),每个模块内部先减少通道数(squeeze)再增加通道数(expamd)。每两个模块之后,通道数会增加。
在1,4,8层之后加入降采样的max pooling(绿色),缩小一半尺寸。
第10层又是卷积层(蓝色),为小图的每个像素预测1000类分类得分。
最后用一个全图average pooling(绿色)得到这张图的1000类得分,使用softmax函数归一化为概率。

这是一个全卷积网络,避免了如今越来越不受待见的全连接层。由于最后一层提供了全图求平均操作,可以接受任意尺寸的输入。当然,输入还是需要归一化到大致相当的尺寸,保持统一尺度。全连接层的参数多,对性能提升帮助不大,现在往往被pooling代替。
实验结果
主要在imagenet数据上比较了alexnet,可以看到准确率差不多的情况下,squeezeNet模型参数数量显著降低了(下表倒数第三行),参数减少50X;如果再加上deep compression技术,压缩比可以达到461X!还是不错的结果。不过有一点,用deep compression[2]是有解压的代价的,所以计算上会增加一些开销。

作者又做了两个实验,来研究网络结构的设计对模型的大小和精度之间的关系
实验1: CNN Microarchitecture metaparameters
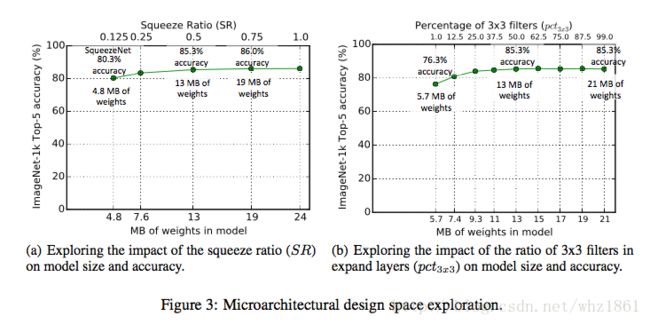
分析研究fire module中的seqeeze中1x1的卷积核数了与expand的卷积核数量之间的关系变化,对最终模型的大小和精度的影响,如下图a
分析研究fire module中的expand中的1x1卷机和的数量与3x3卷机核的数量之间的比例变化,对最终模型的大小和精度的影响,如下图b
在SqueezeNet中,每一个Fire module有3个维度的超参数,即s1x1,e1x1和e3x3.SqueezeNet共有8个Fire模块,即一共24个超参数。下面讨论其中一些重要的超参数的影响。为方便研究,定义如下参数:
basee:Fire module中扩展过滤器的个数
freq:Fire module的个数
incree:在每个freqfreq个Fire模块之后增加的扩展过滤器个数
ei:第二个Fire module中,扩展过滤器的个数
SR:压缩比,即挤压比,为挤压层中过滤器个数除以火模块中过滤器总个数得到的一个比例
pct3x3:在扩展层有1 * 1和3 * 3两种卷积,这里定义的参数是3 * 3卷积个占卷积总个数的比例
说明:
1。这个实验存在交叉点:SR = 0.5,pct3x3 = 0.5
2. SR = 0.75,精度达到最高
3。3×3的卷积核比例超过一定比例后,模型的效果并不会提高
实验2:CNN微体系结构设计空间探索
在普通模型的基础上,增加了简单旁路,如图 - 2,中间图
在普通模型的基础上,增加了复杂旁路,如果图-2,右图

作者发现,最简单的残差连接方式,不仅模型的参数没有增加(参数-免费),而且网络的效果提升最好。
Tensorflow源码
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
slim = tf.contrib.slim
import functools
import tensorflow as tf
import numpy as np
@slim.add_arg_scope
def _fire_module(inputs,
squeeze_depth,
outputs_collections = None,
scope= None,
use_bypass=False
):
"""
Creates a fire module
Arguments:
x : input
squeeze_depth : number of filters of squeeze. The filtersize of expand is 4 times of squeeze
use_bypass : if True then a bypass will be added
name : name of module e.g. fire123
Returns:
x : returns a fire module
"""
with tf.variable_scope(scope, 'fire', [inputs]) as sc:
with slim.arg_scope([slim.conv2d], stride=1, padding='SAME'):
expand_depth = squeeze_depth*4
# squeeze
squeeze = slim.conv2d(inputs, squeeze_depth, [1, 1], scope="squeeze_1X1")
# expand
expand_1x1 = slim.conv2d(squeeze, expand_depth, [1, 1], scope="expand_1x1")
expand_3x3 = slim.conv2d(squeeze, expand_depth, [3, 3], scope="expand_3x3")
# concat
x_ret= tf.concat([expand_1x1, expand_3x3], axis=3)
# fire 3/5/7/9
if use_bypass:
x_ret = x_ret + inputs
return slim.utils.collect_named_outputs(outputs_collections, sc.name, x_ret)
def squeezenet(inputs,
num_classes=1000,
compression=1.0,
use_bypass=True,
dropout_keep_prob=0.9,
is_training=True,
prediction_fn=tf.contrib.layers.softmax,
spatial_squeeze=True,
scope='SqueezeNet',
global_pool=True):
"""
Creating a SqueezeNet of version 1.0 or version 1.1
Arguments:
input_shape : shape of the input images e.g. (224,224,3)
num_classes : number of classes
use_bypass : if true, bypass connections will be created at fire module 3, 5, 7, and 9 (default: False)
dropout_rate : defines the dropout rate that is accomplished after last fire module (default: None)
compression : reduce the number of feature-maps (default: 1.0)
Returns:
logits : the final feature-maps tensor
"""
input_shape = inputs.get_shape().as_list()
if len(input_shape) != 4:
raise ValueError('Invalid input tensor rank, expected 4, was: %d' %
len(input_shape))
with tf.variable_scope(scope, 'SqueezeNet', [inputs]) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d,slim.avg_pool2d,slim.max_pool2d,_fire_module],
outputs_collections = [end_points_collection]):
with slim.arg_scope([slim.batch_norm, slim.dropout], is_training=is_training):
# conv1
net = slim.conv2d(inputs, 96, [7, 7], stride=2, padding="SAME", scope="conv1")
# maxpool1
net = slim.max_pool2d(net, [3, 3], stride=2, scope='maxpool1')
# fire2
net = _fire_module(net, int(16*compression), scope="fire2")
# fire3
net = _fire_module(net, int(16*compression), scope="fire3", use_bypass=use_bypass)
# fire4
net = _fire_module(net, int(32*compression), scope="fire4")
# maxpool4
net = slim.max_pool2d(net, [3, 3], stride=2, scope="maxpool4")
# fire5
net = _fire_module(net, int(32*compression), scope="fire5", use_bypass=use_bypass)
# fire6
net = _fire_module(net, int(48*compression), scope="fire6")
# fire7
net = _fire_module(net, int(48*compression), scope="fire7", use_bypass=use_bypass)
# fire8
net = _fire_module(net, int(64*compression), scope="fire8")
# maxpool8
net = slim.max_pool2d(net, [3, 3], stride=2, scope="maxpool8")
# fire9
net = _fire_module(net, int(64*compression), scope="fire9", use_bypass=use_bypass)
# dropout
if dropout_keep_prob:
net = slim.dropout(net,keep_prob=dropout_keep_prob, scope="dropout")
# conv10
net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='conv10')
# Convert end_points_collection into a dictionary of end_points.
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
with tf.variable_scope('Logits'):
# avgpool10
if global_pool:
# Global average pooling.
net = tf.reduce_mean(net, [1, 2], name='pool10', keep_dims=True)
end_points['global_pool'] = net
if not num_classes:
return net, end_points
# # dropout
# if dropout_keep_prob:
# net = slim.dropout(net,keep_prob=dropout_keep_prob, scope="dropout")
# # conv10
# net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
# normalizer_fn=None, scope='conv10')
# squeeze the axis
if spatial_squeeze:
logits = tf.squeeze(net, [1, 2], name='SpatialSqueeze')
end_points["Logits"]= logits
if prediction_fn:
end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
return logits, end_points
squeezenet.default_image_size = 224
def squeezenet_arg_scope(is_training = True,
weight_decay = 0.0001,
batch_norm_decay = 0.997,
batch_norm_epsilon = 1e-5,
batch_norm_scale = True,
use_batch_norm=False):
batch_norm_params = {
'is_training': is_training,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'scale': batch_norm_scale,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
with slim.arg_scope(
[slim.conv2d],
activation_fn=tf.nn.relu,
weights_regularizer=slim.l2_regularizer(weight_decay),
weights_initializer=slim.variance_scaling_initializer(),
normalizer_fn=slim.batch_norm if use_batch_norm else None,
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params) as arg_sc:
return arg_sc
if __name__ == "__main__":
inputs = tf.random_normal([1, 224, 224, 3])
with slim.arg_scope(squeezenet_arg_scope()):
logits, end_points= squeezenet(inputs,1000,compression=1.0, use_bypass=True)
writer = tf.summary.FileWriter("./logs_squeezenet", graph=tf.get_default_graph())
print("Layers")
for k, v in end_points.items():
print('name = {}, shape = {}'.format(v.name, v.get_shape()))
print("Parameters")
for v in slim.get_model_variables():
print('name = {}, shape = {}'.format(v.name, v.get_shape()))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
pred = sess.run(end_points['Predictions'])
# print(pred)
print(np.argmax(pred,1))
# print(pred[:,np.argmax(pred,1)])