NLP系列——(2)特征提取
文章目录
- 一、中英文文本分析
- 1.1 中文文本特点
- 1.2 英文文本特点
- 二、文本数据的基本特征提取
- 2.1 词汇数量
- 2.2 字符数量
- 2.3 平均词汇长度
- 2.4 停用词数量
- 2.5 特殊字符数量
- 2.6 数字数量
- 2.7 大写字母数量
- 三、文本数据的预处理
- 3.1 小写转换
- 3.2 去除标点符号
- 3.3 去除停用词
- 3.4 常见词去除
- 3.5 稀缺词去除
- 3.6 拼写校正
- 3.7 分词(tokenization)
- 分词算法设计的基本原则
- 最大匹配法
- 正向最大匹配
- 逆向最大匹配法
- 双向最大匹配法
- 3.8 词干提取(stemming)
- 3.9 词形还原(lemmatization)
- 3.10 词、字符频率统计
- 四、语言模型
- 4.1 n-gram模型
- 4.2 词袋模型
- 五、jieba 分词
- 5.1 分词
- 5.2 添加自定义词典
- 5.3 关键词提取
- 5.4 词性标注
- 5.5 并行分词
- 5.6 Tokenize:返回词语在原文的起止位置
- 5.7 ChineseAnalyzer for Whoosh 搜索引擎
- 5.8 命令行分词
首先说一下文本分析流程:
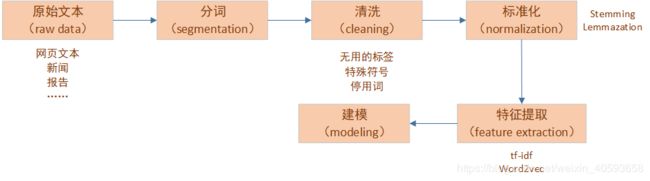
一、中英文文本分析
1.1 中文文本特点
- 中文没有单词的分割符号,因此需要复杂的分词模型进行分析。
- 中文的编码不是utf8,而是unicode。这样会导致在分词的时候,和英文相比,我们要处理编码的问题。
- 中文纠错的处理比英文更难。
1.2 英文文本特点
- 不需要分词:词之间有分隔符,可以直接用split分割。
- 不需要编码转换:英文大部分英文文本都是uft-8的编码。
- 需要处理拼写问题:英文纠错
- 词干提取(stemming)和词形还原(lemmatization):英文有单数,复数和各种时态,导致一个词会有不同的形式。比如“countries”和"country",“wolf"和"wolves”,我们期望是有一个词。如果进行转换,不仅可以减少词库的大小,提高计算的速度;还可以提高语义的理解。
二、文本数据的基本特征提取
这里使用Twitter情感文本数据集,进行举例,下载地址
先看一下数据
import pandas as pd
train=pd.read_csv("./data/train_E6oV3lV.csv")
print(train.head(10))
id label tweet
0 1 0 @user when a father is dysfunctional and is s…
1 2 0 @user @user thanks for #lyft credit i can’t us…
2 3 0 bihday your majesty
3 4 0 #model i love u take with u all the time in …
4 5 0 factsguide: society now #motivation
5 6 0 [2/2] huge fan fare and big talking before the…
6 7 0 @user camping tomorrow @user @user @user @use…
7 8 0 the next school year is the year for exams.�
8 9 0 we won!!! love the land!!! #allin #cavs #champ…
9 10 0 @user @user welcome here ! i’m it’s so #gr…
2.1 词汇数量
对于每一条数据,我们可以提取到的最基本的特征之一就是词汇数量。通常情况下,负面情绪评论含有的词语数量多于正面情绪评论。
可以使用 split 函数,将句子进行切分:
train['word_count']=train['tweet'].apply(lambda x:len(str(x).split(" ")))
train[['tweet','word_count']].head()

2.2 字符数量
train['char_count']=train['tweet'].str.len()
train[['tweet','char_count']].head()

2.3 平均词汇长度
接下来将计算每条推文的平均词汇长度作为另一个特征,这个有可能帮助我们改善模型。将每条推文所有单词的长度然后除以每条推文单词的个数,即可作为平均词汇长度。
def avg_word(sentence):
words=sentence.split()
return (sum(len(word) for word in words)/len(words))
train['avg_word']=train['tweet'].apply(lambda x:avg_word(x))
train[['tweet','avg_word']].head()

2.4 停用词数量
停用词就是句子中没什么必要的单词,去掉他们以后对理解整个句子的语义没有影响。文本中,会存在大量的虚词、代词或者没有特定含义的动词、名词,这些词语对文本分析起不到任何的帮助,我们往往希望能去掉这些“停用词”。
- 在英文中,例如,“a”,“the”,“to",“their”等冠词,借此,代词… 我们可以直接用nltk中提供的英文停用词表。
去除停用词
sentence = "this is a apple"
filter_sentence= [w for w in sentence.split(' ') if w not in stopwords.words('english')]
print(filter_sentence)
[‘apple’]
我们对该数据应用停用词:
from nltk.corpus import stopwords
stop = set(stopwords.words('english'))
train['stopwords']=train['tweet'].apply(lambda sen:len([x for x in sen.split() if x in stop]))
train[['tweet','stopwords']].head()

- 对于中文停用词,由于nlkt不支持中文,所以需要自己构造中文停用词。
- 常用的中文停用词表是1208个,下载地址在这 。有了中文停用词表,去除停用词的代码和英文类似,这里就不赘述了。
2.5 特殊字符数量
该数据集中存在大量‘#’,‘@’符号,这里我们用 startswith 函数来处理。
train['hashtags']=train['tweet'].apply(lambda sen:len([x for x in sen.split() if x.startswith("#")]))
train[['tweet','hashtags']].head()

2.6 数字数量
这个特征并不常用,但是在做相似任务时,数字数量是一个比较有用的特征。
train['numerics']=train['tweet'].apply(lambda sen:len([x for x in sen.split() if x.isdigit()]))
train[['tweet','numerics']].head()

2.7 大写字母数量
“Anger”或者 “Rage”通常情况下使用大写来表述,所以有必要去识别出这些词。
train['upper']=train['tweet'].apply(lambda sen:len([x for x in sen.split() if x.isupper()]))
train[['tweet','upper']].head()

最基本的特征大概就这些了。
三、文本数据的预处理
3.1 小写转换
做预处理时,将数据变成小写,就避免出现相同的多个副本。比如,在我们计算词汇数量时,‘Analytics’和‘analytics’会被认为不同的单词。
train['tweet']=train['tweet'].apply(lambda sen:" ".join(x.lower() for x in sen.split()))
train['tweet'].head()
0 @user when a father is dysfunctional and is so…
1 @user @user thanks for #lyft credit i can’t us…
2 bihday your majesty
3 #model i love u take with u all the time in ur…
4 factsguide: society now #motivation
Name: tweet, dtype: object
3.2 去除标点符号
标点符号在文本数据中不添加任何额外的信息,删除所有的符号将帮助我们减少训练数据的大小。
train['tweet'] = train['tweet'].str.replace('[^\w\s]','')
train['tweet'].head()
0 user when a father is dysfunctional and is so …
1 user user thanks for lyft credit i cant use ca…
2 bihday your majesty
3 model i love u take with u all the time in urð…
4 factsguide society now motivation
Name: tweet, dtype: object
3.3 去除停用词
这里我们可以创建一个列表 stopwords 作为自己停用词库或使用预定义的库。
from nltk.corpus import stopwords
stop=stopwords.words('english')
train['tweet']=train['tweet'].apply(lambda sen:" ".join(x for x in sen.split() if x not in stop))
train['tweet'].head()
0 user father dysfunctional selfish drags kids d…
1 user user thanks lyft credit cant use cause do…
2 bihday majesty
3 model love u take u time urð ðððð ððð
4 factsguide society motivation
Name: tweet, dtype: object
3.4 常见词去除
我们可以把常见的单词从文本数据中去除。首先,让我们来检查中最常出现的10个字文本数据然后再调用删除或保留。
freq=pd.Series(' '.join(train['tweet']).split()).value_counts()[:10]
freq=list(freq.index)
freq
[‘user’, ‘love’, ‘ð’, ‘day’, ‘â’, ‘happy’, ‘amp’, ‘im’, ‘u’, ‘time’]
将常见词去掉
train['tweet']=train['tweet'].apply(lambda sen:' '.join(x for x in sen.split() if x not in freq))
train['tweet'].head()
0 father dysfunctional selfish drags kids dysfun…
1 thanks lyft credit cant use cause dont offer w…
2 bihday majesty
3 model take urð ðððð ððð
4 factsguide society motivation
Name: tweet, dtype: object
3.5 稀缺词去除
正如我们删除最常见的话,这里我们从文本中删除很少出现的词。因为它们很稀有,它们之间的联系和其他词主要是噪音。可以替换罕见的单词更一般的形式,然后这将有更高的计数。
freq = pd.Series(' '.join(train['tweet']).split()).value_counts()[-10:]
freq = list(freq.index)
freq
[‘happenedâ’, ‘britmumspics’, ‘laterr’, ‘2230’, ‘dkweddking’, ‘ampsize’, ‘moviescenes’, ‘kaderimsin’, ‘nfinity’, ‘babynash’]
train['tweet'] = train['tweet'].apply(lambda x: " ".join(x for x in x.split() if x not in freq))
train['tweet'].head()
0 father dysfunctional selfish drags kids dysfun…
1 thanks lyft credit cant use cause dont offer w…
2 bihday majesty
3 model take urð ðððð ððð
4 factsguide society motivation
Name: tweet, dtype: object
3.6 拼写校正
这里可以使用 textblob 库。
TextBlob是一个用Python编写的开源的文本处理库。它可以用来执行很多自然语言处理的任务,比如,词性标注,名词性成分提取,情感分析,文本翻译,等等。你可以在官方文档阅读TextBlog的所有特性。
from textblob import TextBlob
train['tweet'][:5].apply(lambda x: str(TextBlob(x).correct()))
0 father dysfunctional selfish drags kiss dysfun…
1 thanks left credit can use cause dont offer wh…
2 midday majesty
3 model take or ðððð ððð
4 factsguide society motivation
Name: tweet, dtype: object
3.7 分词(tokenization)
分词算法设计的基本原则
- 颗粒度越大越好:用于进行语义分析的文本分词,要求分词结果的颗粒度越大,即单词的字数越多,所能表示的含义越确切,如:“公安局长”可以分为“公安 局长”、“公安局 长”、“公安局长”都算对,但是要用于语义分析,则“公安局长”的分词结果最好(当然前提是所使用的词典中有这个词)
- 切分结果中非词典词越少越好,单字字典词数越少越好,这里的“非词典词”就是不包含在词典中的单字,而“单字字典词”指的是可以独立运用的单字,如“的”、“了”、“和”、“你”、“我”、“他”。例如:“技术和服务”,可以分为“技术 和服 务”以及“技术 和 服务”,但“务”字无法独立成词(即词典中没有),但“和”字可以单独成词(词典中要包含),因此“技术 和服 务”有1个非词典词,而“技术 和 服务”有0个非词典词,因此选用后者。
- 总体词数越少越好,在相同字数的情况下,总词数越少,说明语义单元越少,那么相对的单个语义单元的权重会越大,因此准确性会越高。
最大匹配法
最大匹配是指以词典为依据,取词典中最长单词为第一次取字数量的扫描串,在词典中进行扫描(为提升扫描效率,还可以跟据字数多少设计多个字典,然后根据字数分别从不同字典中进行扫描)。
例如:词典中最长词为“中华人民共和国”共7个汉字,则最大匹配起始字数为7个汉字。然后逐字递减,在对应的词典中进行查找。
正向最大匹配
正向即从前往后取词,从7->1,每次减一个字,直到词典命中或剩下1个单字。
举例:“我们在野生动物园玩”。
第1轮扫描:
第1次:“我们在野生动物”,扫描7字词典,无
第2次:“我们在野生动”,扫描6字词典,无
。。。。
第6次:“我们”,扫描2字词典,有
扫描中止,输出第1个词为“我们”,去除第1个词后开始第2轮扫描,即:
第2轮扫描:
第1次:“在野生动物园玩”,扫描7字词典,无
第2次:“在野生动物园”,扫描6字词典,无
。。。。
第6次:“在野”,扫描2字词典,有
扫描中止,输出第2个词为“在野”,去除第2个词后开始第3轮扫描,即:
第3轮扫描:
第1次:“生动物园玩”,扫描5字词典,无
第2次:“生动物园”,扫描4字词典,无
第3次:“生动物”,扫描3字词典,无
第4次:“生动”,扫描2字词典,有
扫描中止,输出第3个词为“生动”,第4轮扫描,即:
第4轮扫描:
第1次:“物园玩”,扫描3字词典,无
第2次:“物园”,扫描2字词典,无
第3次:“物”,扫描1字词典,无
扫描中止,输出第4个词为“物”,非字典词数加1,开始第5轮扫描,即:
第5轮扫描:
第1次:“园玩”,扫描2字词典,无
第2次:“园”,扫描1字词典,有
扫描中止,输出第5个词为“园”,单字字典词数加1,开始第6轮扫描,即:
第6轮扫描:
第1次:“玩”,扫描1字字典词,有
扫描中止,输出第6个词为“玩”,单字字典词数加1,整体扫描结束。
正向最大匹配法,最终切分结果为:“我们/在野/生动/物/园/玩”,其中,单字字典词为2,非词典词为1。
逆向最大匹配法
逆向即从后往前取词,其他逻辑和正向相同。
举例:“我们在野生动物园玩”。
第1轮扫描:“在野生动物园玩”
第1次:“在野生动物园玩”,扫描7字词典,无
第2次:“野生动物园玩”,扫描6字词典,无
。。。。
第7次:“玩”,扫描1字词典,有
扫描中止,输出“玩”,单字字典词加1,开始第2轮扫描
第2轮扫描:“们在野生动物园”
第1次:“们在野生动物园”,扫描7字词典,无
第2次:“在野生动物园”,扫描6字词典,无
第3次:“野生动物园”,扫描5字词典,有
扫描中止,输出“野生动物园”,开始第3轮扫描
第3轮扫描:“我们在”
第1次:“我们在”,扫描3字词典,无
第2次:“们在”,扫描2字词典,无
第3次:“在”,扫描1字词典,有
扫描中止,输出“在”,单字字典词加1,开始第4轮扫描
第4轮扫描:“我们”
第1次:“我们”,扫描2字词典,有
扫描中止,输出“我们”,整体扫描结束。
逆向最大匹配法,最终切分结果为:“我们/在/野生动物园/玩”,其中,单字字典词为2,非词典词为0。
双向最大匹配法
正向最大匹配法和逆向最大匹配法,都有其局限性,因此有人又提出了双向最大匹配法,双向最大匹配法。即,两种算法都切一遍,然后根据大颗粒度词越多越好,非词典词和单字词越少越好的原则,选取其中一种分词结果输出。
举例:“我们在野生动物园玩”
正向最大匹配法,最终切分结果为:“我们/在野/生动/物/园/玩”,其中,两字词3个,单字字典词为2,非词典词为1。
逆向最大匹配法,最终切分结果为:“我们/在/野生动物园/玩”,其中,五字词1个,两字词1个,单字字典词为2,非词典词为0。
非字典词:正向(1)>逆向(0)(越少越好)
单字字典词:正向(2)=逆向(2)(越少越好)
总词数:正向(6)>逆向(4)(越少越好)
因此最终输出为逆向结果。
3.8 词干提取(stemming)
词干提取(stemming)是抽取词的词干或词根形式(不一定能够表达完整语义)。
词干提取(stemming)是指通过基于规则的方法去除单词的后缀,比如“ing”,“ly”,“s”等等。
from nltk.stem import PorterStemmer
st=PorterStemmer()
train['tweet'][:5].apply(lambda x:" ".join([st.stem(word) for word in x.split()]))
0 father dysfunct selfish drag kid dysfunct run
1 thank lyft credit cant use caus dont offer whe…
2 bihday majesti
3 model take urð ðððð ððð
4 factsguid societi motiv
Name: tweet, dtype: object
在上面的输出中,“dysfunctional ”已经变为“dysfunct ”
3.9 词形还原(lemmatization)
词形还原(lemmatization),是把一个任何形式的语言词汇还原为一般形式(能表达完整语义)。
from textblob import Word
train['tweet']=train['tweet'].apply(lambda x:" ".join([Word(word).lemmatize() for word in x.split()]))
train['tweet'].head()
基
0 father dysfunctional selfish drag kid dysfunct…
1 thanks lyft credit cant use cause dont offer w…
2 bihday majesty
3 model take urð ðððð ððð
4 factsguide society motivation
Name: tweet, dtype: object
3.10 词、字符频率统计
使用Python中的collections.Counter模块。
词频率统计:第一步分词,然后根据分词后的结果进行词频率统计。
基于jieba的实现代码:
import jieba
seg_list = list(jieba.cut('今天是我学习自然语言处理NLP的计划二,所需时间为两天',cut_all=False))
WordCount = Counter(seg_list )
print(WordCount)
字符频率统计:按单个字符切分并统计出现频率。
基于collections的实现代码:
from collections import Counter
txt = '今天是我学习自然语言处理NLP的计划二,所需时间为两天'
StatisticalCharacters = Counter(txt)
print(StatisticalCharacters)
四、语言模型
统计语言模型是一个单词序列上的概率分布,对于一个给定长度为m的序列,它可以为整个序列产生一个概率 P(w_1,w_2,…,w_m) 。其实就是想办法找到一个概率分布,它可以表示任意一个句子或序列出现的概率。
目前在自然语言处理相关应用非常广泛,如语音识别(speech recognition) , 机器翻译(machine translation), 词性标注(part-of-speech tagging), 句法分析(parsing)等。传统方法主要是基于统计学模型,最近几年基于神经网络的语言模型也越来越成熟。
常见的方法有n-gram模型方法、决策树方法、最大熵模型方法、最大熵马尔科夫模型方法、条件随机域方法、神经网络方法,等等。
4.1 n-gram模型
n-gram模型(考虑句子中单词之间的顺序)
当n取1、2、3时,n-gram模型分别称为unigram、bigram、trigram语言模型
unigram一元分词,把句子分成一个一个的汉字
bigram二元分词,把句子从头到尾每两个字组成一个词语
trigram三元分词,把句子从头到尾每三个字组成一个词语
比如:
西安交通大学:
unigram 形式为:西/安/交/通/大/学
bigram形式为: 西安/安交/交通/通大/大学
trigram形式为:西安交/安交通/交通大/通大学
4.2 词袋模型
词袋模型(不考虑句子中单词之间的顺序)
Bag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。
将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个词语都是独立的。
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典如下:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序。
五、jieba 分词
参见 jieba
5.1 分词
- jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
- jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
- 待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
- jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用
- jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
- jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
# encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
输出:
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
5.2 添加自定义词典
载入词典
- 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
- 用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
- 词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
- 词频省略时使用自动计算的能保证分出该词的词频。
调整词典
- 使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
- 使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
- 注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
5.3 关键词提取
1、基于TF-IDF算法的关键词抽取
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选 - jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
2、 基于 TextRank 算法的关键词抽取
- jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
- jieba.analyse.TextRank() 新建自定义 TextRank 实例
5.4 词性标注
- jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
- 标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
import jieba.posseg as pseg
words = pseg.cut("我爱北京天安门")
for word, flag in words:
print('%s %s' % (word, flag))
我 r
爱 v
北京 ns
天安门 ns
5.5 并行分词
- 原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升
- 基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
用法:
jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数
jieba.disable_parallel() # 关闭并行分词模式