Transformer与BERT浅说
https://www.toutiao.com/a6683063914634150404/
2019-04-23 20:21:12
最近BERT横空出世,横扫各大数据集Leaderboard,此等丰功伟业,可谓惊世骇俗。实际上上次讨论QANet的时候BERT已经占据SQuAD榜首,超出human performance 2个点,更是令人惊坐四起、“哭天喊地”。正襟危坐,我等凡夫俗子还是安心看论文吧。。。
BERT模型并不复杂,要想理解还得从Transformer说起,正好复习以备忘。采用seq2seq框架来实现MT现在已经是一个非常热点的研究方向,各种花式设计归根离不开RNN、CNN同时辅以attention。但是正如之前文章中介绍的,对于NLP来讲不论是RNN还是CNN都存在其固有的缺陷,即使attention可以缓解长距依赖的问题。那么有什么更好的办法呢?Transformer直接摒弃了RNN和CNN的固定框架(一定程度上)而完全基于attention,绝对大手笔。句子间用attention没有问题,那么只用attention该如何去捕捉句子中词间的依赖关系呢?RNN、CNN虽不完美,但至少能够一定程度上获取句子结构信息。这就依赖Transformer中第一大杀器:self-attention。
顾名思义,自注意力就是自己和自己做attention。此话怎讲?我们知道NLP中做attention一般来说K=V,如果Q=K=V那么就是self-attention了。这么做的优势非常明显,它不仅可以解决句子长距依赖的问题,同时没有像RNN一样严重的梯度弥散及固定的结构限制,也无需像CNN考虑感受野的范围,总的来讲,它不仅实作效果更好,而且可以并行。自self-attention的出现已经被大量应用,也证明了其在建模序列编码问题上的意义。
好了,这样就很好地编码了句子,也考虑了句子中词间的依赖关系。然而这样就ok了吗?并不是,只要仔细考量就会发现self-attention并不能捕捉到词的顺序。why?如果打乱词间的顺序,attention中的K和Q并不会发生变化,因此attention编码后的结果也不会发生变化。为了解决这个问题,Transformer采用了一种人工设计的Positional Encoding方案。
讲真这个构造的位置编码让我等学渣苦恼万分,论文没有给出其设计思路,网络上也鲜有好的解释,最后在网上找到的好的解释是利用三角函数的周期性使得模型可以学习到词间的相对位置,这里就不多做解释了。
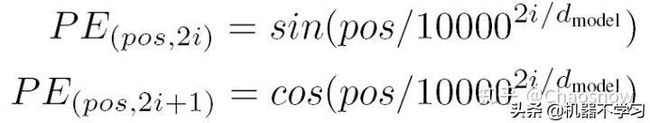
可以参考从Seq2seq到Attention模型到Self Attention(二) - 华尔街见闻、《Attention is All You Need》浅读(简介+代码)
本质上Transformer的核心就是这些,除此之外Google还提出了Multi-Head Attention的注意力机制。简单来讲,Multi-Head Attention就是将attention做多次,再将其拼接起来。那么这么做的理由是什么呢?论文中解释为:Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. 也就是说每个attention只能捕捉一个维度的信息,像这样把Q、K、V每次投影到不同的空间可以捕捉到不同维度的信息。话虽如此,我曾一度纠结为什么能够保证各head的attention能够获取到不同维度并且有效的信息,不很明白但就是靠谱,或许这就是神经网络的哲学吧。在语音识别领域,Google也曾利用multi-head attention来改进他们的LAS模型,亲测确实效果明显。
至此Transformer的关键工作就说完了,但仅有这些仍然是不够的,整个框架中无处不体现Google大神们的工程、设计能力:
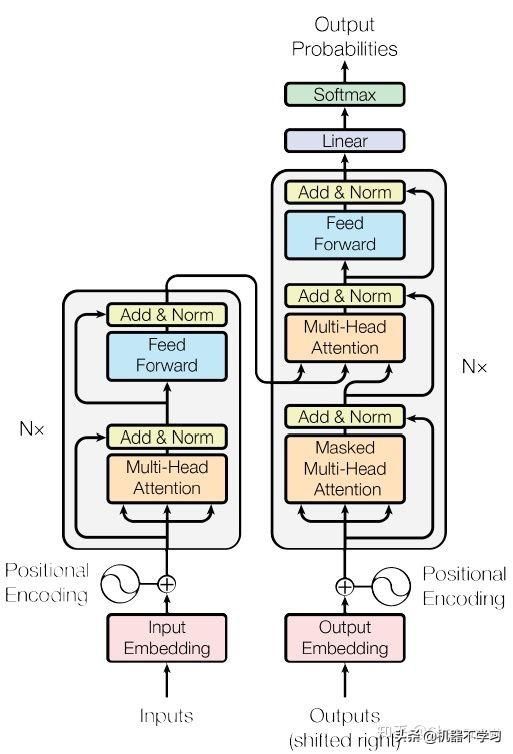
值得注意的是在Decoder(右)部分不同于Encoder而采用Masked Multi-Head Attention,所谓Masked论文解释如下:We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. 又不太懂,个人理解是在预测的时候我们并不能看到后续的词,为了保证训练预测一致,就将当前位置后面的词mask掉,不知道理解对不对。
有了对Transformer的大致理解就可以深入到最近的BERT了,实际上BERT框架和Transformer是一样的,只是做的工作不同。BERT的目的是预训练语言模型,简单来说就是预训练一个模型可以对句子进行embedding,其作用可以类比word embedding。论文首先对Language model pre-training的方法进行了介绍,一个是Feature-based的方法,例如ELMo,一个是Fine-tuning的方法,例如OpenAI GPT,BERT同样属于后者。那么BERT是如何预训练的呢?
Task #1: Masked Language Model
思想很简单,就是随机mask句子中的一部分词,目标是利用其它词去预测被mask掉的词。具体BERT采取的策略如下:

文中解释并不100%进行mask的原因是为了保持pre-training与fine-tuning的一致,因为fine-tuning的时候并不能看到[mask]。至于引入随机word的原因个人感觉仅仅是引入一些噪声从而使模型更稳健,具有一定纠错能力。一点牵强的理由是文中强调了和denoising auto-encoders的区别。
Task #2: Next Sentence Prediction
NSP简单说就是预测句子B是否承接句子A,具体BERT的策略是:50%B是A的下文,label=IsNext,50%不是,label=NotNext,也就是个二分类问题。
pre-training过程同时优化上面两个任务,其结束后就可以在特定任务上进行fine-tuning,仅需在BERT的基础上增加相应的output layer即可:
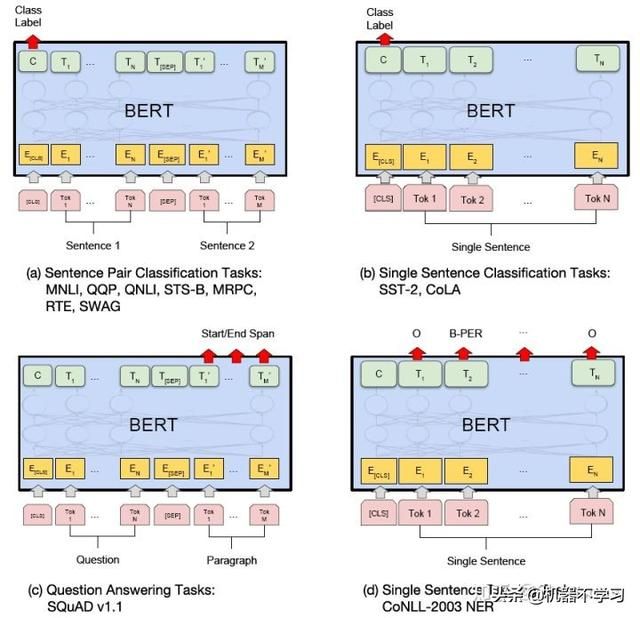
有人说BERT改变了NLP的玩儿法,确实未来的工作重心一定是向无监督或者半监督转移,当然这样的改变不止NLP。BERT在多个数据集下取到这样惊人的成果堪称伟大,可见其良好的泛化能力,确实称得上是里程碑式的工作。话虽如此这样的pre-traing所需的算力可远观不可亵玩,还好Google将预训练好的模型开源,这带给工业界以及学术界的价值是巨大的,我等工作狗拿来主义就好哈哈。
转自:https://zhuanlan.zhihu.com/p/49542105