Lenet5设计理解——咬文嚼字系列
最近在看lecun大神的这篇经典文章:“Gradient-Based Learning Appliedto Document Recognition”,文章较老,但是对于lenet5的一些基础概念讲解浅显易懂,本文主要对lenet5的架构和设计讲一些我的粗浅理解,对一些问题写一些我的看法,同时我也提出了一些自己的疑惑,才疏学浅希望能和各位一起讨论。
这里再说一点我最近看博客的想法:对任何一种算法由于大家的背景不同理解上可能有偏差,尤其是原作者是外国人的一些算法,网上的一些中文翻译一些地方会存在问题,所以还是建议抽时间能把算法原文看看,希望这里能成为大家共同讨论的平台。
1. lenet5架构理解
C1卷积层:卷积层就是fig2的convolution层,对输入图像的某个位置使用一样权重的感知野得到一幅feature map,针对不同权重的感知野得到一组feature maps,然后把这些feature maps统称为卷积层,这样卷积层就获得了每一个位置的不同特征。fig2有六副feature maps,所以有六组不同特征。
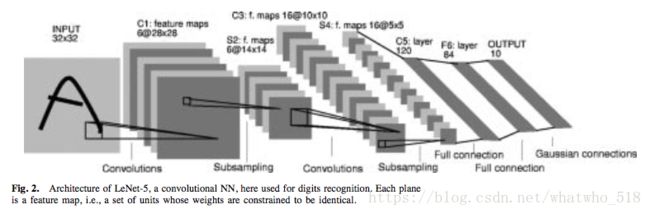
- 共享权重:lecun在文章里面单独提到了“共享权重”这个概念,但其实这个概念学过图像处理的人都知道卷积操作,比如对图像做垂直边缘检测子:
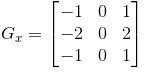 ,其实就是对图像每个位置做卷积操作,整幅图共享这个权重,本文提到“共享权重”就是这个意思。只不过卷积层的共享权重是个未知量,需要后续计算出来。
,其实就是对图像每个位置做卷积操作,整幅图共享这个权重,本文提到“共享权重”就是这个意思。只不过卷积层的共享权重是个未知量,需要后续计算出来。
- 卷积层能学到什么:我得一点想法是如果拿滤波器类比假设每一个卷积层分别是低通、中通、高通滤波后的图像,卷积层就能获得图像的低频信息、图像的高频信息(比如噪声等);同样的小波变换、傅立叶变换也是类似的。
S2下采样层:下采样层在原文里的解释原话是降低分辨率,它取图像的2*2小块进行平均然后乘权重加上偏置过sigmoid函数,取图像2*2小块进行平均就是下采样,平均的过程就是模糊,下采样就是降低分辨率,所以通过下采样层,图像一些小的畸变,噪声等等都可以解决。下采样层还有一个很大的优点是拥有尺度不变性,lenet5我们可以根据自己的图像大小来设计下采样的模版大小。
为什么要这么做呢?对于图像识别中很多简单的任务其实我们只关注图像的结构信息,比如数字7,我们会注意到上面有一横,然后是一个斜着的竖杠,我们就认为是7,比如人脸检测任务,我们关注的是圆形的上方有两个小圆圈—眼睛,中间一个鼻子,下面一个椭圆—嘴巴,这就足以满足任务了。基于此,在满足任务所需信息(位置对应的图像结构信息)的条件下,保留越少的信息是约好的,这样的好处是多方面的。1,计算快;2,网络容易收敛,因为图像少网路连接数就少了;3,网络对偏移和形变不敏感,一个大大的写在广告牌上的的数字“7”我们很容易对噪声敏感,比如脏脏的小黑点,比如上面一横是否不直有些弯曲。
——Less is Better.
C3卷积层:和C1卷积层的卷积原理方法类似,唯一不同的是c1输入图像只有1副,而这里输入图像为6副,并且输出是16副,
作者在原文里画的这个表可以说是非常形象了,0~5表示S2层的6幅图,横轴0~15表示C3的feature maps,然后第一副feature map就取的是S2层0,1,2三幅图,使用同一个卷积核k1对这三幅图分别卷积再求和,所以输出的图像是一副哦; 以此类推,第二副feature map就取的是S2层1,2,3三幅图,使用同一个卷积核k2对这三幅图分别卷积再求和。所以为了生成C3的16幅图,共需要16个卷积核。
另外这篇博客https://blog.csdn.net/zhangjunhit/article/details/53536915画了副图形象的解释了这个,
我在这里想解释的是
- 为什么要取这样的组合呢:我是这样想的这一层是比上一个卷积层更高级的特征,作者实现的方法就是用了原始6张feature maps的任意组合,从图像的两两组合开始,2= 6-4,所以四个一组的特征跟2个一组的特征是一个意思,这是因为权重是可以取负数的,3=6-3,所以三个一组的特征就是6个,4出现了,5=6-1,一副图像在c1层已经考虑了,最后是6张图。所以说作者的这16个组合是最简单但是覆盖率又最广的组合了,赞!我觉得这有点像sift的金字塔模型,也是取得若干层特征组合。总结一下,好处:1,比全连接的计算量少,比如c3层的16副feature map都全部和s2层的6副feature map连接,计算量少了要将近一半,time is money! 2,打破了网络的对称性(网络是越简单同时包含的信息越多越好),C3的每一层都连接了S2的不同层,这样就迫使C3的每一层都提取不同的特征。计算量是25*3*6(6个5*5的卷积核分别计算3个feature map)+25*4*9+25*6*1+16=1516
S4下采样层:跟s2类似
C5卷积层:这一层卷积原理跟普通的卷积层一样。注意这一层依然是卷积层!!!只是因为恰巧模版大小和原feature maps大小一样,所以输出变成一纬。
F6层:这一层采用全连接的方式和c5连接,对c5的输入乘以权重加上偏置,过激活函数:tanh,文章里作者还解释了为啥取tanh还没有到,等我看到了再补充。
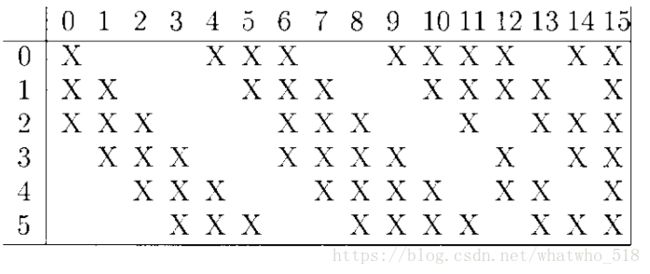
输出层:这里先要解释下为啥F6层的神经元数量是84。这一层使用7*12位图=84 来表示数字,一个原因是识别ascii表示的数字很有用,这样可以区别易混淆的数字,比如数字0和字母o很像,但是一些后处理方法可以纠正这些错误,因为相似的数字和字母会有相似的RBF输出,后处理就可以针对这些相似的结果专门处理从而找到一个真正的结果。另外一个原因是过去的1~n编码,这种非分散的编码对于十几个类别以上的分类问题效果差,因为输出需要只能是一个数字或者字母,这就需要选不到别的数字,而通常sigmoid函数长这样:
我们希望能够长成这样:正巧RBF核函数就长类似这样,

F6层的每一个RBF单元的输出y,x是F6的输出,:
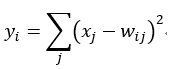
这个公式的意思是:当输入x的模式和权重w的模式非常接近的时候,y就最小,这里的w可以手动选择并且保持固定,并且取值为1或者-1,保证-1和1的数量相等即可,当然w还有别的取值方法。w有i*j个元素。
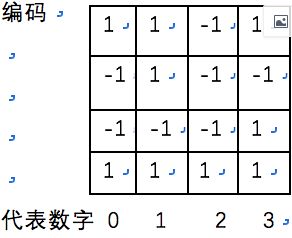
这里我们假设神经元个数为4,那么如下图所示,数字0的编码就是1,-1,-1,1;别的数字也有自己对应的编码,如果x的编码和数字1的编码最接近,我们就认为识别到的数字为1,这个编码就是原论文中提到的pattern。
由于文章给的神经元个数为84,所以编码长度是84,网络训练的结果就会给每个输入数字找到一个对应的编码。
2. 为什么CNN不采用全连接网络?CNN结构设计的目的?
1)全连接网络连接的网络极多,所以需要更大的训练集;对于图像各种变换(平移、旋转);全连接网络会忽略掉输入信号的拓扑结构,而图像像素周围的结构信息很重要,
2)CNN具有平移不变性;CNN可以学习到图像的局部特征,局部的结构信息
感知野,共享权重;空间和时序下采样
3)使用局部感知野神经元可以提取基本的视觉特征比如:边缘、端点、角点;
之后将这些特征通过下采样层结合从而发现更高阶的特征,
- 卷积层的平移不变性:卷积的目的是提取特征,比如数字“7”,对应于左上角有一横,右上角有个角点,左下角有斜杠。那么将数字“7”平移之后,左上角、右上角、左下角的特征相对位置依然存在。所以卷积关心的是特征本身和特征之间的相对位置,而不是绝对位置。比如“左上角”和“右上角”特征的左和右其实是相对的。但是我觉得Lenet5的平移不变性和旋转不变性还是有待商榷,作者的官网画图显示了正负40度的平移不变性,但是注意那个图像旋转轴基本是中心, http://yann.lecun.com/exdb/lenet/rotation.html
3. LeNet-5的参数数目、连接数是怎么算的?
图像是28*28的,由于第一层卷积是5*5窗函数,所以input是32*32;
C1: 待训练参数:(5*5*1+1)*6=156 ,5*5的窗函数*6幅图对应的6组不同窗函数+6个偏置。
连接数:25*28*28*6+28*28*6=122304 ,系数部分+偏置部分
S2: 待训练参数:(1+1)*6=12 ,6个系数+6个偏置。
连接数:4*14*14*6+14*14*6=5880
C3:待训练参数:(5*5*3+1)*6+(5*5*4+1)*6+(5*5*4+1)*3+(5*5*6+1)=1516 ,
连接数:[(25*3+ 1)*6+(25*4+ 1)*6+(25*4+ 1)*3+(25*6+ 1)]*100=151600
S4:待训练参数:(1+1)*16=32 ,6个系数+6个偏置。
连接数:4*5*5*16+5*5*16=2000
C5:
连接数:(25*16+1)*120=48120
F6:为啥定义84层呢?因为这里使用的是7*12位图=84,这种表示方法对于可打印的ASCII集的字符表示更有用,而不是通常识别的数字,因为普通的数字可能很相像,容易混淆。
连接数:(120+1)*84=10164
未完待续。