Sentinel基本使用--基于Thread并发线程数流量控制
一, Sentinel基于并发线程数流控
采用基于线程数的限流模式后,我们不需要再显式地去进行线程池隔离,Sentinel 会控制访问该资源的线程数,超出的请求直接拒绝,直到堆积的线程处理完成。相当于是以资源为维度, 隔离出了每一种资源对应的不同线程数.
例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对太多线程占用的情况,业内有使用隔离的方案,比如通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离)。这种隔离方案虽然隔离性比较好,但是代价就是线程数目太多,线程上下文切换的 overhead 比较大,特别是对低延时的调用有比较大的影响。Sentinel 并发线程数限流不负责创建和管理线程池,而是简单统计当前请求上下文的线程数目,如果超出阈值,新的请求会被立即拒绝,效果类似于信号量隔离。
二, 示例
1 初始化限流规则, 设置访问该资源的最大的线程数为20, 拒绝策略使用RuleConstant.FLOW_GRADE_THREAD, 基于访问访问资源的线程数限流.
private static void initFlowRule() {
List rules = new ArrayList();
FlowRule rule1 = new FlowRule();
rule1.setResource("methodA");
// set limit concurrent thread for 'methodA' to 20
// 设置该资源的线程数阈值为20个
rule1.setCount(20);
// 基于并发线程数限流
rule1.setGrade(RuleConstant.FLOW_GRADE_THREAD);
rule1.setLimitApp("default");
rules.add(rule1);
FlowRuleManager.loadRules(rules);
} 2 同时启动100个线程, 访问资源, 刚开始时模拟methodB的业务耗时1s, 当运行60s后, methodB的业务耗时降低为20ms
private static volatile int methodBRunningTime = 1000;
public static void main(String[] args) throws Exception {
System.out.println("MethodA will call methodB. After running for a while, methodB becomes fast, "
+ "which make methodA also become fast ");
tick();
initFlowRule();
for (int i = 0; i < threadCount; i++) {
Thread entryThread = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
Entry methodA = null;
try {
TimeUnit.MILLISECONDS.sleep(5);
methodA = SphU.entry("methodA");
activeThread.incrementAndGet();
Entry methodB = SphU.entry("methodB");
TimeUnit.MILLISECONDS.sleep(methodBRunningTime);
methodB.exit();
pass.addAndGet(1);
} catch (BlockException e1) {
block.incrementAndGet();
} catch (Exception e2) {
// biz exception
} finally {
total.incrementAndGet();
if (methodA != null) {
methodA.exit();
activeThread.decrementAndGet();
}
}
}
}
});
entryThread.setName("working thread");
entryThread.start();
}
}运行60s后(即seconds=40)时, 修改模拟methodB方法的业务耗时时间为20ms.
if (seconds == 40) {
System.out.println("method B is running much faster; more requests are allowed to pass");
methodBRunningTime = 20;
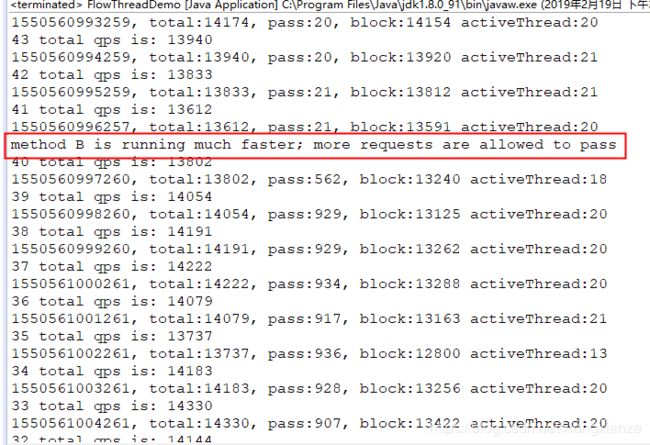
}由上可知, 在同样线程数限流, 阈值为20个, 当methodB的业务耗时降低时, 理论上通过访问资源的请求p_qps应该是显著增加的, 如下图:
可以看到, 在methodB业务耗时降低的前后, 存活的线程数activeThread大概都是20个左右, 在同样是20个线程的处理请求时, 很明显能看到在methodB业务耗时降低前后, pass由原来的20个左右, 上升到900左右.
三, dashboard展示
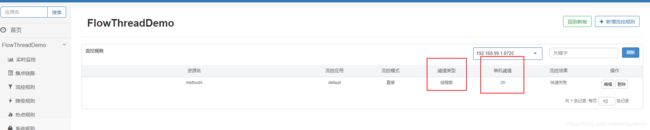
查看流控规则, 阈值类型: 线程数, 单机阈值:20
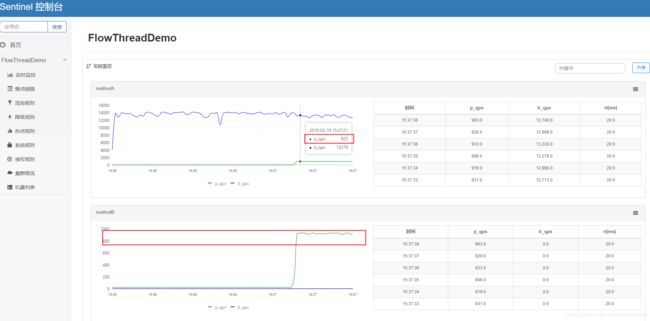
如下图, 所示在methodB业务耗时降低时, 同样的20个最大阈值线程数, 处理请求的能力有一个显著的上升过程, 最终稳定在900左右的p_QPS.
四, 基于并发线程数FlowThreadDemo
public class FlowThreadDemo {
private static AtomicInteger pass = new AtomicInteger();
private static AtomicInteger block = new AtomicInteger();
private static AtomicInteger total = new AtomicInteger();
private static AtomicInteger activeThread = new AtomicInteger();
private static volatile boolean stop = false;
// 60s时间后, methodB业务处理耗时为20ms, 那每个线程访问资源时最低耗时就变成了20ms, 处理速度加快
private static final int threadCount = 100;
private static int seconds = 60 + 40;
// methodB模拟调用别人的服务, 业务耗时1s, 配置线程数阈值为20, 同样的线程数, methodB业务耗时降级, 则这20个线程能处理的请求能力上升, 能接受更多的请求
private static volatile int methodBRunningTime = 1000;
public static void main(String[] args) throws Exception {
System.out.println("MethodA will call methodB. After running for a while, methodB becomes fast, "
+ "which make methodA also become fast ");
tick();
initFlowRule();
for (int i = 0; i < threadCount; i++) {
Thread entryThread = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
Entry methodA = null;
try {
TimeUnit.MILLISECONDS.sleep(5);
methodA = SphU.entry("methodA");
activeThread.incrementAndGet();
Entry methodB = SphU.entry("methodB");
TimeUnit.MILLISECONDS.sleep(methodBRunningTime);
methodB.exit();
pass.addAndGet(1);
} catch (BlockException e1) {
block.incrementAndGet();
} catch (Exception e2) {
// biz exception
} finally {
total.incrementAndGet();
if (methodA != null) {
methodA.exit();
activeThread.decrementAndGet();
}
}
}
}
});
entryThread.setName("working thread");
entryThread.start();
}
}
private static void initFlowRule() {
List rules = new ArrayList();
FlowRule rule1 = new FlowRule();
rule1.setResource("methodA");
// set limit concurrent thread for 'methodA' to 20
// 设置该资源的线程数阈值为20个
rule1.setCount(20);
// 基于并发线程数限流
rule1.setGrade(RuleConstant.FLOW_GRADE_THREAD);
rule1.setLimitApp("default");
rules.add(rule1);
FlowRuleManager.loadRules(rules);
}
private static void tick() {
Thread timer = new Thread(new TimerTask());
timer.setName("sentinel-timer-task");
timer.start();
}
static class TimerTask implements Runnable {
@Override
public void run() {
long start = System.currentTimeMillis();
System.out.println("begin to statistic!!!");
long oldTotal = 0;
long oldPass = 0;
long oldBlock = 0;
while (!stop) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
long globalTotal = total.get();
long oneSecondTotal = globalTotal - oldTotal;
oldTotal = globalTotal;
long globalPass = pass.get();
long oneSecondPass = globalPass - oldPass;
oldPass = globalPass;
long globalBlock = block.get();
long oneSecondBlock = globalBlock - oldBlock;
oldBlock = globalBlock;
System.out.println(seconds + " total qps is: " + oneSecondTotal);
System.out.println(TimeUtil.currentTimeMillis() + ", total:" + oneSecondTotal + ", pass:"
+ oneSecondPass + ", block:" + oneSecondBlock + " activeThread:"
+ activeThread.get());
if (seconds-- <= 0) {
stop = true;
}
if (seconds == 40) {
System.out.println("method B is running much faster; more requests are allowed to pass");
methodBRunningTime = 20;
}
}
long cost = System.currentTimeMillis() - start;
System.out.println("time cost: " + cost + " ms");
System.out.println("total:" + total.get() + ", pass:" + pass.get() + ", block:" + block.get());
System.exit(0);
}
}
} 五, 总结
Sentinel基于并发线程数的流量控制, 能以资源为维度, 为不同的资源, 配置不用的线程数, 控制访问每个资源的线程数, 有点类似于信号量Semaphore方式, 信号量的资源数即为并发线程数, 比如当有请求需要访问被Sentinel保护的资源时, 会首先去获取信号量Semaphore中的资源, 只有成功从semaphore.acquire();获取资源, 才能访问应用资源.