看过最详细的Kube-proxy的iptables模式原理详解
Kubernetes如何利用iptables
原文地址
Linux内置的防火墙可以对IP数据包做一系列如过滤、更改、转发这样的操作,防火墙在对数据包做过滤决定时,有一套遵循的规则,这些规则存储在专用的数据包过滤表(table)中,而这些表集成在Linux 内核中。在数据包过滤表中,规则被分组放在我们所谓的链(chain)中。
我们通常说的iptables就是指Linux内置的防火墙,它实际上由两个组件netfilter和iptables组成。netfilter组件也称为内核空间(kernel space),它是内核的一部分,由一些数据包过滤表组成,这些表包含内核用来控制数据包过滤处理的规则集。iptables组件是一个工具,也称为用户空间(user space),它使插入、修改和删除数据包过滤表中的规则变得容易,即我们通常用iptables来对chain中的规则进行添加、修改和删除以实现我们自己的防火墙逻辑。
iptables内置了5个table,可以用man来查看这5个table的名字和作用(其中我们最常用的就是filter和nat这两个表):

filter、nat和mangle这三个表的作用为如下所示:
filter表 是专门过滤包的,它也是iptables缺省的表,它内建三个链,可以毫无问题地对包进行DROP、LOG、ACCEPT和REJECT等操作。FORWARD链过滤所有不是本地产生的并且目的地不是本地的包,而 INPUT是针对那些目的地是本地的包。OUTPUT 用来过滤所有本地生成的包。
nat表 的主要用处是网络地址转换,即Network Address Translation,缩写为NAT。做过NAT操作的数据包的地址就被改变了,当然这种改变是根据我们的规则进行的。属于一个流的包只会经过这个表一次。如果第一个包被允许做NAT或Masqueraded,那么余下的包都会自动地被做相同的操作。也就是说,余下的包不会再通过这个表,一个一个的被NAT,而是自动地完成。PREROUTING 链的作用是在包刚刚到达防火墙时改变它的目的地址(DNAT),如果需要的话。OUTPUT链改变本地产生的包的目的地址(DNAT)。POSTROUTING链在包就要离开防火墙之前改变其源地址(SNAT)。DNAT 是做目的网络地址转换的,就是重写包的目的IP地址。如果一个包被匹配了,那么和它属于同一个流的所有的包都会被自动转换,然后就可以被路由到正确的主机或网络。DNAT是非常有用的。比如,你的Web服务器在LAN内部,而且没有可在Internet上使用的真实IP地址,那就可以使用DNAT让防火墙把所有到它自己HTTP端口的包转发给LAN内部真正的Web服务器。DNAT的目的地址也可以是一个范围,这样的话,DNAT会为每一个流随机分配一个地址。因此,我们可以用这个DNAT做某种类型的负载均衡。
mangle 这个表主要用来修改数据包。我们可以改变不同的包及包头的内容,比如TTL,TOS或MARK。 注意MARK并没有真正地改动数据包,它只是在内核空间为包设了一个标记。防火墙内的其他的规则或程序可以使用这种标记对包进行过滤或高级路由。这个表有五个内建的链:PREROUTING,POSTROUTING,OUTPUT,INPUT和FORWARD。PREROUTING在包进入防火墙之后、路由判断之前改变包,POSTROUTING是在所有路由判断之后。 OUTPUT在确定包的目的之前更改数据包。INPUT在包被路由到本地之后,但在用户空间的程序看到它之前改变包。FORWARD在最初的路由判断之后、最后一次更改包的目的之前mangle包。注意,mangle表不能做任何NAT,它只是改变数据包的TTL,TOS或MARK。
数据包在iptables中的各个表、各个chain中的流转过程如下图所示:
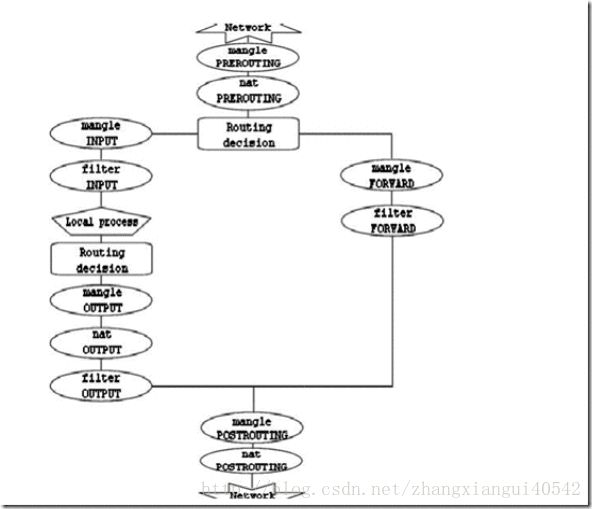
从上图可以看出,如果我们要让某台Linux主机充当路由和负载均衡角色的话,我们显然应该在该主机的nat表的prerouting链中对数据包做DNAT操作。
Kubernetes可以利用iptables来做针对service的路由和负载均衡,其核心逻辑是通过kubernetes/pkg/proxy/iptables/proxier.go中的函数syncProxyRules来实现的(这部分代码做的事情主要就是在service所在node的nat表的prerouting链中对数据包做DNAT操作)。
下面我们就来分析一下syncProxyRules中的主要逻辑:
Part1:

这里定义了kubernetes将创建的自定义链的名称。
Part2:

上述代码做了如下事情:
1、 分别在表filter和nat中创建名为“KUBE-SERVICES”的自定义链
2、 调用iptables对filter表的output链、对nat表的output和prerouting链创建了如下三条规则:
//将经过filter表的output链的数据包重定向到自定义链KUBE-SERVICES中
//这里-j的意思是jump
iptables -I OUTPUT -m comment –comment “kubernetes service portals” -j KUBE-SERVICES
//将经过nat表的prerouting链的数据包重定向到自定义链KUBE-SERVICES中
//显然kubernetes这里要做DNAT
iptables –t nat -I PREROUTING -m comment –comment “kubernetes service portals” -j KUBE-SERVICES
//将经过nat表的output链的数据包重定向到自定义链KUBE-SERVICES中
iptables –t nat –I OUTPUT -m comment –comment “kubernetes service portals” -j KUBE-SERVICES
Part3:

述代码做了如下事情:
1、 在表nat中创建了名为“KUBE-POSTROUTING”的自定义链
2、 调用iptables对nat表的postrouting链创建了如下规则:
//将经过nat表的postrouting链的数据包重定向到自定义链KUBE-POSTROUTING中
//显然kubernetes这里要做SNAT
iptables –t nat -I POSTROUTING -m comment –comment “kubernetes postrouting rules” -j KUBE-POSTROUTING
Part4:
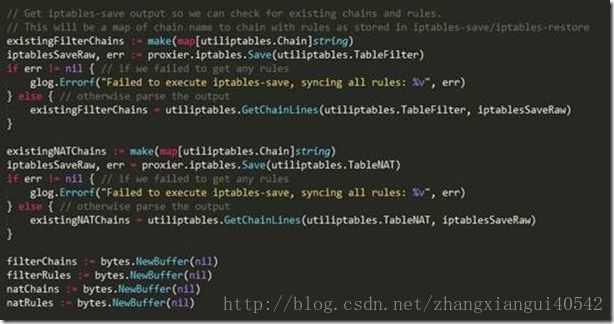
上述代码做的事情是:kubernetes调用iptables-save命令解析当前node中iptables的filter表和nat表中已经存在的chain,kubernetes会将这些chain存在两个map中(existingFilterChains和existingNATChains),然后再创建四个protobuf中的buffer(分别是filterChains、filterRules、natChains和natRules),后续kubernetes会往这四个buffer中写入大量iptables规则,最后再调用iptables-restore写回到当前node的iptables中。
Part5:

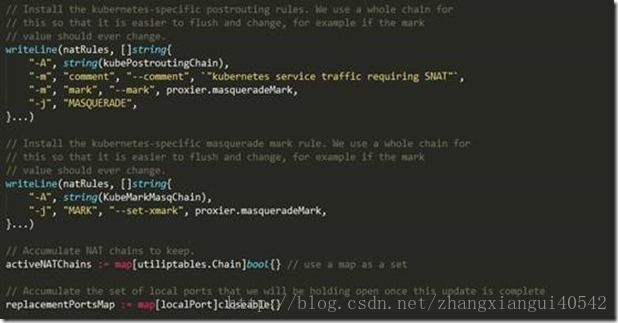
上述代码做了如下事情:
1、 如果当前node的iptables的filter表和nat表中已经存在名为“KUBE-SERVICES”、“KUBE-NODEPORTS”、“KUBE-POSTROUTING”和“KUBE-MARK-MASQ”的自定义链,那就原封不动将它们按照原来的形式(: [:])写入到filterChains和natChains中;如果没有,则以“: [0:0]”的格式写入上述4个chain(即将“:KUBE-SERVICES – [0:0]”、“:KUBE-NODEPORTS – [0:0]”、“:KUBE-POSTROUTING – [0:0]”和“:KUBE-MARK-MASQ – [0:0]”写入到filterChains和natChains中,这相当于在filter表和nat表中创建了上述4个自定义链);
2、 对nat表的自定义链“KUBE-POSTROUTING”写入如下规则:
-A KUBE-POSTROUTING -m comment –comment “kubernetes service traffic requiring SNAT” -m mark –mark 0x4000/0x4000 -j MASQUERADE
3、 对nat表的自定义链“KUBE-MARK-MASQ”写入如下规则:
-A KUBE-MARK-MASQ -j MARK –set-xmark 0x4000/0x4000
这里2和3做的事情的实际含义是kubernetes会让所有kubernetes集群内部产生的数据包流经nat表的自定义链“KUBE-MARK-MASQ”,然后在这里kubernetes会对这些数据包打一个标记(0x4000/0x4000),接着在nat的自定义链“KUBE-POSTROUTING”中根据上述标记匹配所有的kubernetes集群内部的数据包,匹配的目的是kubernetes会对这些包做SNAT操作。
Part6:
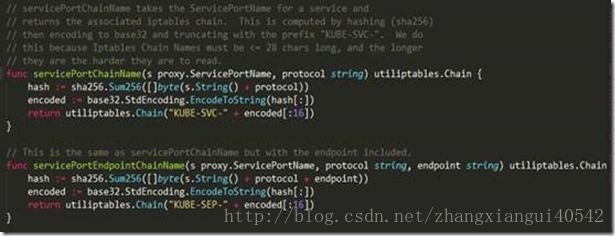

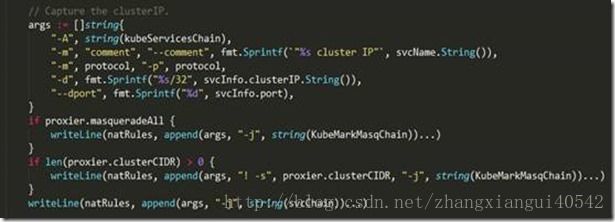

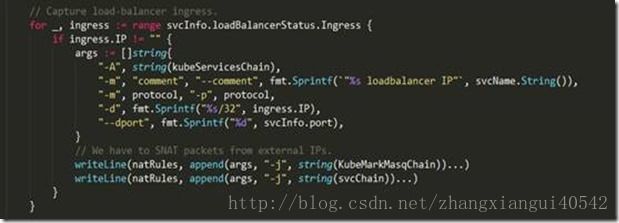
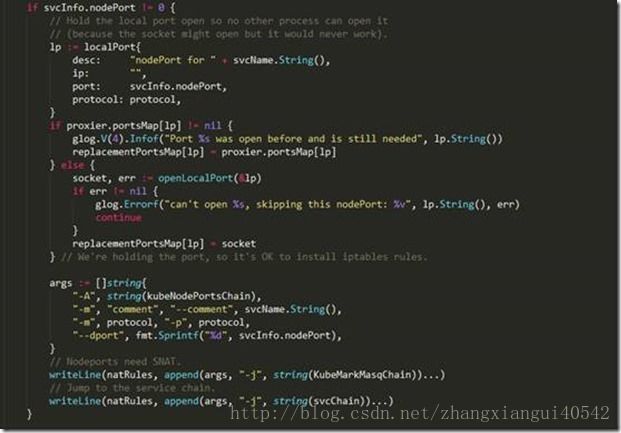
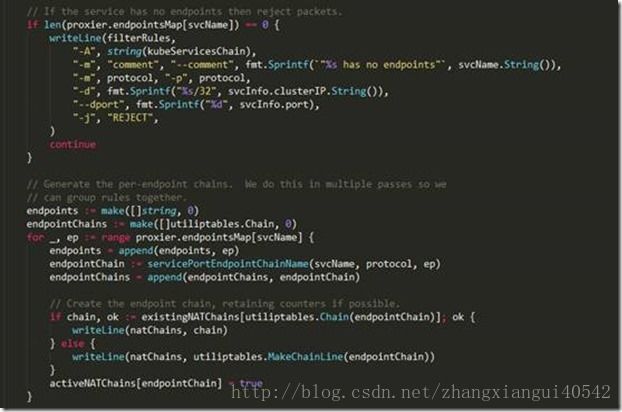


上述代码主要做了如下事情:
1、 遍历所有服务,对每一个服务,在nat表中创建名为“KUBE-SVC-XXXXXXXXXXXXXXXX”的自定义链(这里的XXXXXXXXXXXXXXXX是一个16位字符串,kubernetes使用SHA256 算法对“服务名+协议名”生成哈希值,然后通过base32对该哈希值编码,最后取编码值的前16位,kubernetes通过这种方式保证每个服务对应的“KUBE-SVC-XXXXXXXXXXXXXXXX”都不一样)。然后对每个服务,根据服务是否有cluster ip、是否有external ip、是否启用了外部负载均衡服务在nat表的自定义链“KUBE-SERVICES”中加入类似如下这样的规则:
//所有流经自定义链KUBE-SERVICES的来自于服务“kongxl/test2:8778-tcp”的数据包都会
//跳转到自定义链KUBE-SVC-XAKTM6QUKQ53BZHS中
-A KUBE-SERVICES -d 172.30.32.92/32 -p tcp -m comment –comment “kongxl/test2:8778-tcp cluster IP” -m tcp –dport 8778 -j KUBE-SVC-XAKTM6QUKQ53BZHS
2、 在遍历每一个服务的过程中,还会检查该服务是否启用了nodeports,如果启用了且该服务有对应的endpoints,则会在nat表的自定义链“KUBE-NODEPORTS”中加入如下两条规则:
//所有流经自定义链KUBE-NODEPORTS的来自于服务“ym/echo-app-nodeport”的数据包
//都会跳转到自定义链KUBE-MARK-MASQ中,即kubernetes会对来自上述服务的这些
//数据包打一个标记(0x4000/0x4000)
-A KUBE-NODEPORTS -p tcp -m comment –comment “ym/echo-app-nodeport:” -m tcp –dport 30001 -j KUBE-MARK-MASQ
//所有流经自定义链KUBE-NODEPORTS的来自于服务“ym/echo-app-nodeport”的数据包
//都会跳转到自定义链KUBE-SVC-LQ6G5YLNLUHHZYH5中
-A KUBE-NODEPORTS -p tcp -m comment –comment “ym/echo-app-nodeport:” -m tcp –dport 30001 -j KUBE-SVC-LQ6G5YLNLUHHZYH5
3、 在遍历每一个服务的过程中,还会检查该服务是否启用了nodeports,如果启用了但该服务没有对应的endpoints,则会在filter表的自定义链“KUBE-SERVICES”中加入如下规则:
//如果service没有配置endpoints,那么kubernetes这里会REJECT所有数据包,这意味着//没有endpoints的service是无法被访问到的
-A KUBE-SERVICES -d 172.30.32.92/32 -p tcp -m comment –comment “kongxl/test2:8080-tcp has no endpoints” -m tcp –dport 8080 -j REJECT
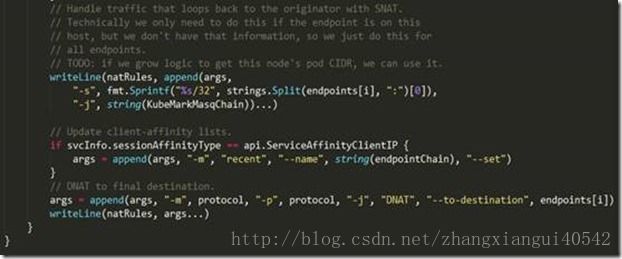
4、 在遍历每一个服务的过程中,对每一个服务,如果这个服务有对应的endpoints,那么在nat表中创建名为“KUBE-SEP-XXXXXXXXXXXXXXXX”的自定义链(这里的XXXXXXXXXXXXXXXX是一个16位字符串,kubernetes使用SHA256 算法对“服务名+协议名+端口”生成哈希值,然后通过base32对该哈希值编码,最后取编码值的前16位,kubernetes通过这种方式保证每个服务的endpoint对应的“KUBE-SEP-XXXXXXXXXXXXXXXX”都不一样)。然后对每个endpoint,如果该服务配置了session affinity,则在nat表的该service对应的自定义链“KUBE-SVC-XXXXXXXXXXXXXXXX”中加入类似如下这样的规则:
//所有流经自定义链KUBE-SVC-ECTPRXTXBM34L34Q的来自于服务
//”default/docker-registry:5000-tcp”的数据包都会跳转到自定义链 //KUBE-SEP-LPCU5ERTNL2YBWXG中,
//且会在一段时间内保持session affinity,保持时间为180秒
//这里kubernetes用“-m recent –rcheck –seconds 180 –reap”实现了会话保持
-A KUBE-SVC-ECTPRXTXBM34L34Q -m comment –comment “default/docker-registry:5000-tcp” -m recent –rcheck –seconds 180 –reap –name KUBE-SEP-LPCU5ERTNL2YBWXG –mask 255.255.255.255 –rsource -j KUBE-SEP-LPCU5ERTNL2YBWXG
5、 在遍历每一个服务的过程中,对每一个服务,如果这个服务有对应的endpoints,且没有配置session affinity,则在nat表的该service对应的自定义链“KUBE-SVC-XXXXXXXXXXXXXXXX”中加入类似如下这样的规则(如果该服务对应的endpoints大于等于2,则还会加入负载均衡规则):
//所有流经自定义链KUBE-SVC-VX5XTMYNLWGXYEL4的来自于服务“ym/echo-app”的数据//包既可能会跳转到自定义链KUBE-SEP-27OZWHQEIJ47W5ZW,也可能会跳转到自定义
//链KUBE-SEP-AA6LE4U3XA6T2EZB,这里kubernetes用“-m statistic –mode random //–probability 0.50000000000”实现了对该服务访问的负载均衡
-A KUBE-SVC-VX5XTMYNLWGXYEL4 -m comment –comment “ym/echo-app:” -m statistic –mode random –probability 0.50000000000 -j KUBE-SEP-27OZWHQEIJ47W5ZW
-A KUBE-SVC-VX5XTMYNLWGXYEL4 -m comment –comment “ym/echo-app:” -j KUBE-SEP-AA6LE4U3XA6T2EZB
6、 最后,在遍历每一个服务的过程中,对每一个服务的endpoints,在nat表的该endpoint对应的自定义链“KUBE-SEP-XXXXXXXXXXXXXXXX”中加入如下规则,实现到该服务最终目的地的DNAT:
//服务“ym/echo-app”有两个endpoints,之前kubernetes已经对该服务做了负载均衡,
//所以这里一共会产生4条跳转规则
-A KUBE-SEP-27OZWHQEIJ47W5ZW -s 10.1.0.8/32 -m comment –comment “ym/echo-app:” -j KUBE-MARK-MASQ
-A KUBE-SEP-27OZWHQEIJ47W5ZW -p tcp -m comment –comment “ym/echo-app:” -m tcp -j DNAT –to-destination 10.1.0.8:8080
-A KUBE-SEP-AA6LE4U3XA6T2EZB -s 10.1.1.4/32 -m comment –comment “ym/echo-app:” -j KUBE-MARK-MASQ
-A KUBE-SEP-AA6LE4U3XA6T2EZB -p tcp -m comment –comment “ym/echo-app:” -m tcp -j DNAT –to-destination 10.1.1.4:8080
Part7:


上述代码做的事情是:
1、 删掉当前节点中已经不存在的服务所对应的“KUBE-SVC-XXXXXXXXXXXXXXXX”链和“KUBE-SEP- XXXXXXXXXXXXXXXX”链;
2、 向nat表的自定义链“KUBE-SERVICES”中写入如下这样规则:
//将目的地址是本地的数据包跳转到自定义链KUBE-NODEPORTS中
-A KUBE-SERVICES -m comment –comment “kubernetes service nodeports; NOTE: this must be the last rule in this chain” -m addrtype –dst-type LOCAL -j KUBE-NODEPORTS
Part8:
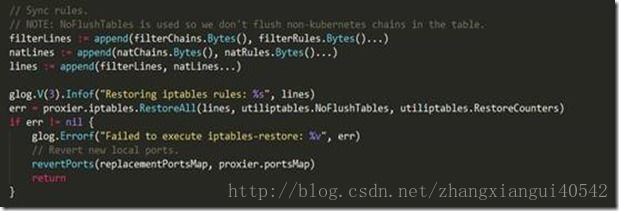
上述代码做的事情是:合并已经被写入了大量规则的四个protobuf中的buffer(分别是filterChains、filterRules、natChains和natRules),然后调用iptables-restore写回到当前node的iptables中。
总结
Kubernetes使用iptables的主要用法用一句话总结就是:
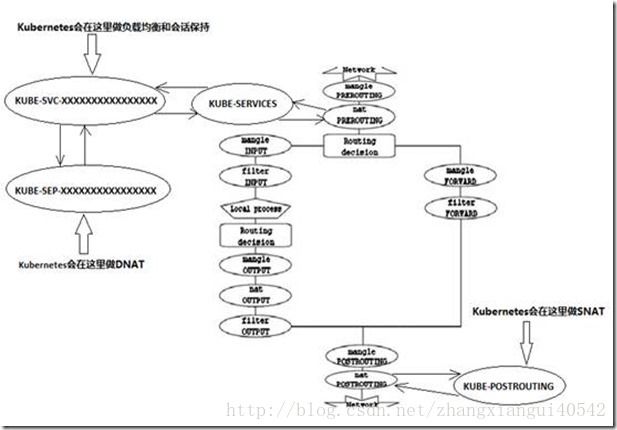
Kubernetes通过在目标node的iptables中的nat表的PREROUTING和POSTROUTING链中创建一系列的自定义链 (这些自定义链主要是“KUBE-SERVICES”链、“KUBE-POSTROUTING”链、每个服务所对应的“KUBE-SVC-XXXXXXXXXXXXXXXX”链和“KUBE-SEP-XXXXXXXXXXXXXXXX”链),然后通过这些自定义链对流经到该node的数据包做DNAT和SNAT操作以实现路由、负载均衡和地址转换。
上述总结可以用如下这张图来说明: