Java高级工程师常见面试题(答案)
Java高级工程师常见面试题
一、Java基础
1. String类为什么是final的。
1.线程安全2.支持字符串常量池数据共享,节省资源,提高效率(因为如果已经存在这个常量便不会再创建,直接拿来用)
2. HashMap的源码,实现原理,底层结构。
总的来说,HashMap就是数组+链表(哈希表或者散列函数)的组合实现,每个数组元素存储一个链表的头结点,本质上来说是哈希表“拉链法”的实现。
HashMap的链表元素对应的是一个静态内部类Entry,Entry主要包含key,value,next三个元素
主要有put和get方法,put的原理是,通过hash&length-1计算index,此时记作Entry[index]=该元素。如果index相同
就是新入的元素放置到Entry[index],原先的元素记作Entry[index].next
get就比较简单了,先遍历数组,再遍历链表元素。
null key总是放在Entry数组的第一个元素(允许存放一个空键值对的原因)
解决hash冲突的方法:链地址法
再散列rehash的过程:确定容量超过目前哈希表的容量,重新调整table 的容量大小,当超过容量的最大值时
HashMap的容量size乘以负载因子[默认0.75] = threshold 将会触发扩容
3. 说说你知道的几个Java集合类:list、set、queue、map实现类咯。。。
queue的实现类: AbstractQueue, ArrayBlockingQueue, ConcurrentLinkedQueue, LinkedBlockingQueue, DelayQueue, LinkedList, PriorityBlockingQueue, PriorityQueue和ArrayDqueue
4. 描述一下ArrayList和LinkedList各自实现和区别
5. Java中的队列都有哪些,有什么区别。
Queue: 基本上,一个队列就是一个先入先出(FIFO)的数据结构
Queue接口与List、Set同一级别,都是继承了Collection接口。LinkedList实现了Deque接 口。
Queue的实现
1、没有实现的阻塞接口的LinkedList: 实现了java.util.Queue接口和java.util.AbstractQueue接口
内置的不阻塞队列: PriorityQueue 和 ConcurrentLinkedQueue
PriorityQueue 和 ConcurrentLinkedQueue 类在 Collection Framework 中加入两个具体集合实现。
PriorityQueue 类实质上维护了一个有序列表。加入到 Queue 中的元素根据它们的天然排序(通过其 java.util.Comparable 实现)或者根据传递给构造函数的 java.util.Comparator 实现来定位。
ConcurrentLinkedQueue 是基于链接节点的、线程安全的队列。并发访问不需要同步。因为它在队列的尾部添加元素并从头部删除它们,所以只要不需要知道队列的大 小, ConcurrentLinkedQueue 对公共集合的共享访问就可以工作得很好。收集关于队列大小的信息会很慢,需要遍历队列。
2)实现阻塞接口的:
java.util.concurrent 中加入了 BlockingQueue 接口和五个阻塞队列类。它实质上就是一种带有一点扭曲的 FIFO 数据结构。不是立即从队列中添加或者删除元素,线程执行操作阻塞,直到有空间或者元素可用。
五个队列所提供的各有不同:
* ArrayBlockingQueue :一个由数组支持的有界队列。
* LinkedBlockingQueue :一个由链接节点支持的可选有界队列。
* PriorityBlockingQueue :一个由优先级堆支持的无界优先级队列。
* DelayQueue :一个由优先级堆支持的、基于时间的调度队列。
* SynchronousQueue :一个利用 BlockingQueue 接口的简单聚集(rendezvous)机制。
6. 反射中,Class.forName和classloader的区别
class.forName()除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
而classLoader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
Class.forName(name, initialize, loader)带参函数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象
7. Java7、Java8的新特性(baidu问的,好BT)
java7有一些比较重要的更新,如异常处理增加了被抑制的异常、捕获多异常、try-with-resource自动释放资源等,还有应用了G1垃圾回收器、switch可以使用String类型、泛型自动判断类型、fork/join框架把任务细分并使用多处理器处理、支持二进制字面量等
毫无疑问,Java 8是自Java 5(2004年)发布以来Java语言最大的一次版本升级,Java 8带来了很多的新特性,比如编译器、类库、开发工具和JVM(Java虚拟机)。在这篇教程中我们将会学习这些新特性,并通过真实例子演示说明它们适用的场景。
最最重要的是Java8开始支持了Lambda表达式
8. Java数组和链表两种结构的操作效率,在哪些情况下(从开头开始,从结尾开始,从中间开始),哪些操作(插入,查找,删除)的效率高
9. Java内存泄露的问题调查定位:jmap,jstack的使用等等
10. string、stringbuilder、stringbuffer区别
11. hashtable和hashmap的区别
- HashMap是非线程同步的,HashTable是线程同步的。
- HashMap允许null作为键或者值,HashTable不允许
- HashTable中有个一个contains方法,HashMap去掉了此方法
- 效率上来讲,HashMap因为是非线程安全的,因此效率比HashTable高
- hashTable继承Dictionary,而HashMap继承Abstract
13 .异常的结构,运行时异常和非运行时异常,各举个例子
14. String a= “abc” String b = “abc” String c = new String(“abc”) String d = “ab” + “c” .他们之间用 == 比较的结果
编译时优化
15. String 类的常用方法
16. Java 的引用类型有哪几种
对象的强、软、弱和虚引用(四种引用)
在JDK 1.2以前的版本中,若一个对象不被任何变量引用,那么程序就无法再使用这个对象。也就是说,只有对象处于可触及(reachable)状态,程序才能使用它。从JDK 1.2版本开始,把对象的引用分为4种级别,从而使程序能更加灵活地控制对象的生命周期。这4种级别由高到低依次为:强引用、软引用、弱引用和虚引用。
⑴强引用(StrongReference) 强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。 ps:强引用其实也就是我们平时A a = new A()这个意思。
⑵软引用(SoftReference)
如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存(下文给出示例)。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
⑶弱引用(WeakReference)
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
⑷虚引用(PhantomReference)
“虚引用”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
虚引用主要用来跟踪对象被垃圾回收器回收的活动。虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之 关联的引用队列中。
ReferenceQueue queue = new ReferenceQueue ();
PhantomReference pr = new PhantomReference (object, queue);
程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
17. 抽象类和接口的区别
18. java的基础类型和字节大小。
19. Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题(建议熟悉 jdk 源码,才能从容应答)
20. 如果不让你用Java Jdk提供的工具,你自己实现一个Map,你怎么做。说了好久,说了HashMap源代码,如果我做,就会借鉴HashMap的原理,说了一通HashMap实现
21. Hash冲突怎么办?哪些解决散列冲突的方法?
开放地址法 插入元素时,如果发生冲突,算法会简单的从该槽位置向后循环遍历hash表,直到找到表中的下一个空槽,并将该元素放入该槽中(会导致相同hash值的元素挨在一起和其他hash值对应的槽被占用)。查找元素时,首先散列值所指向的槽,如果没有找到匹配,则继续从该槽遍历hash表,直到:(1)找到相应的元素;(2)找到一个空槽,指示查找的元素不存在,(所以不能随便删除元素);(3)整个hash表遍历完毕(指示该元素不存在并且hash表是满的)
拉链法(hashMap采用的是该种方法)
22. HashMap冲突很厉害,最差性能,你会怎么解决?从O(n)提升到log(n)咯,用二叉排序树的思路说了一通
23. rehash
24. hashCode() 与 equals() 生成算法、方法怎么重写
如何重写equals()方法
- It is reflexive: for any non-null reference value
x,x.equals(x)should returntrue. - It is symmetric: for any non-null reference values
xandy,x.equals(y)should returntrueif and only ify.equals(x)returnstrue. - It is transitive: for any non-null reference values
x,y, andz, ifx.equals(y)returnstrueandy.equals(z)returnstrue, thenx.equals(z)should returntrue. - It is consistent: for any non-null reference values
xandy, multiple invocations ofx.equals(y)consistently returntrueor consistently returnfalse, provided no information used inequalscomparisons on the objects is modified. - For any non-null reference value
x,x.equals(null)should returnfalse.
- class Coder {
- private String name;
- private int age;
- // getters and setters
- }
- if(other == this)
- return true;
- if(!(other instanceof Coder))
- return false;
- Coder o = (Coder)other;
- return o.name.equals(name) && o.age == age;
如何重写hashCode()方法
hashCode method whenever this method(equals) is overridden, so as to maintain the general contract for the hashCode method, which states that equal objects must have equal hash codes."
- @Override
- public int hashCode() {
- int result = 17;
- result = result * 31 + name.hashCode();
- result = result * 31 + age;
- return result;
- }
其中int result = 17你也可以改成20, 50等等都可以.看到这里我突然有些好奇,想看一下String类中的hashCode()方法是如何实现的.查文档知:
String object is computed as
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
using
int arithmetic, where s[i] is the ith character of the string, n is the length of the string, and ^ indicates exponentiation. (The hash value of the empty string is zero.)"重写equals()而不重写hashCode()的风险
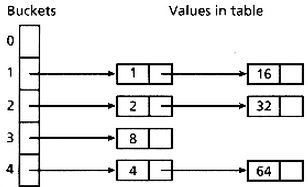
- Coder c1 = new Coder("bruce", 10);
- Coder c2 = new Coder("bruce", 10);
假定我们已经重写了Coder的equals()方法而没有重写hashCode()方法:
- @Override
- public boolean equals(Object other) {
- System.out.println("equals method invoked!");
- if(other == this)
- return true;
- if(!(other instanceof Coder))
- return false;
- Coder o = (Coder)other;
- return o.name.equals(name) && o.age == age;
- }
然后我们构造一个HashSet,将c1对象放入到set中:
- Set
set = new HashSet(); - set.add(c1);
再执行:
- System.out.println(set.contains(c2));
我让hashCode()每次都返回一个固定的数行吗
- @Override
- public int hashCode() {
- return 10;
- }
二、Java IO
1. 讲讲IO里面的常见类,字节流、字符流、接口、实现类、方法阻塞。
2. 讲讲NIO。
3. String 编码UTF-8 和GBK的区别?
4. 什么时候使用字节流、什么时候使用字符流?
5. 递归读取文件夹下的文件,代码怎么实现
三、Java Web
1. session和cookie的区别和联系,session的生命周期,多个服务部署时session管理。
2. servlet的一些相关问题
3. webservice相关问题
4. jdbc连接,forname方式的步骤,怎么声明使用一个事务。举例并具体代码
5. 无框架下配置web.xml的主要配置内容
6. jsp和servlet的区别
四、JVM
1. Java的内存模型以及GC算法
2. jvm性能调优都做了什么
3. 介绍JVM中7个区域,然后把每个区域可能造成内存的溢出的情况说明
4. 介绍GC 和GC Root不正常引用。
5. 自己从classload 加载方式,加载机制说开去,从程序运行时数据区,讲到内存分配,讲到String常量池,讲到JVM垃圾回收机制,算法,hotspot。反正就是各种扩展
6. jvm 如何分配直接内存, new 对象如何不分配在堆而是栈上,常量池解析
7. 数组多大放在 JVM 老年代(不只是设置 PretenureSizeThreshold ,问通常多大,没做过一问便知)
8. 老年代中数组的访问方式
9. GC 算法,永久代对象如何 GC , GC 有环怎么处理
10. 谁会被 GC ,什么时候 GC
11. 如果想不被 GC 怎么办
12. 如果想在 GC 中生存 1 次怎么办
五、开源框架
1. hibernate和ibatis的区别
2. 讲讲mybatis的连接池。
3. spring框架中需要引用哪些jar包,以及这些jar包的用途
4. springMVC的原理
5. springMVC注解的意思
6. spring中beanFactory和ApplicationContext的联系和区别
BeanFactory特点
BeanFactory常用的实现类是DefaultListableBeanFactory,调用者只需要使用getBean()方法就可以获得指定的引用,无须关心Bean的实例化过程。创建Spring容器的实例时,必须提供Spring容器管理的Bean的详细配置信息。Spring的配置信息通常采用XML配置文件来设置,因此,创建BeanFactory实例时,应该提供XML配置文件作为参数。XML配置文件通常使用Resource对象传入。
Resource isr = new ClassPathResource("beans.xml");
//Resource isr = new FileSystemResource("beans.xml");
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
new XmlBeanDefinitionReader(beanFactory).loadBeanDefinition(isr);
ApplicationContext特点
ApplicationContext常用的实现类是FileSystemXmlApplicationContext、ClassPathXmlApplicationContext和AnnotationConfigApplicationContext。如果在Web应用中使用Spring容器,则通常使用XmlWebApplicationContext、AnnotationConfigApplicationContext两个实现类。如果需要使用多个XML配置文件创建Spring容器,可以使用FileSystemXmlApplicationContext或者是ClassPathXmlApplicationContext。
除了提供BeanFactory所支持的所有功能外,ApplicationContext还有额外的功能
- 默认初始化所有的Singleton,也可以通过配置取消预初始化。
- 继承MessageSource,因此支持国际化。
- 资源访问,比如访问URL和文件。
- 事件机制。
- 同时加载多个配置文件。
- 以声明式方式启动并创建Spring容器。
由于ApplicationContext会预先初始化所有的Singleton Bean,于是在系统创建前期会有较大的系统开销,但一旦ApplicationContext初始化完成,程序后面获取Singleton Bean实例时候将有较好的性能。也可以为bean设置lazy-init属性为true,即Spring容器将不会预先初始化该bean。
7. spring注入的几种方式(循环注入)
8. spring如何实现事物管理的
set注入(通常也叫属性注入),构造函数注入,接口注入(这个现在基本不用),注解注入(@Autowire)
9. springIOC
10. spring AOP的原理
11. hibernate中的1级和2级缓存的使用方式以及区别原理(Lazy-Load的理解)
12. Hibernate的原理体系架构,五大核心接口,Hibernate对象的三种状态转换,事务管理。
六、多线程
1. Java创建线程之后,直接调用start()方法和run()的区别
2. 常用的线程池模式以及不同线程池的使用场景
3. newFixedThreadPool此种线程池如果线程数达到最大值后会怎么办,底层原理。
4. 多线程之间通信的同步问题,synchronized锁的是对象,衍伸出和synchronized相关很多的具体问题,例如同一个类不同方法都有synchronized锁,一个对象是否可以同时访问。或者一个类的static构造方法加上synchronized之后的锁的影响。
5. 了解可重入锁的含义,以及Lock 和synchronized的区别
1. lock是一个接口,而synchronized是java的一个关键字,synchronized是内置的语言实现;(具体实现上的区别在《Java虚拟机》中有讲解底层的CAS不同,以前有读过现在又遗忘了。)
2. synchronized在发生异常时候会自动释放占有的锁,因此不会出现死锁;而lock发生异常时候,不会主动释放占有的锁,必须手动unlock来释放锁,可能引起死锁的发生。(所以最好将同步代码块用try catch包起来,finally中写入unlock,避免死锁的发生。)
3. lock等待锁过程中可以用interrupt来终端等待,而synchronized只能等待锁的释放,不能响应中断;
4. lock可以通过trylock来知道有没有获取锁,而synchronized不能;
5. Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离)
6. 同步的数据结构,例如concurrentHashMap的源码理解以及内部实现原理,为什么他是同步的且效率高
7. atomicinteger和Volatile等线程安全操作的关键字的理解和使用
8. 线程间通信,wait和notify
9. 定时线程的使用
10. 场景:在一个主线程中,要求有大量(很多很多)子线程执行完之后,主线程才执行完成。多种方式,考虑效率。
11. 进程和线程的区别
12. 什么叫线程安全?举例说明
13. 线程的几种状态
14. 并发、同步的接口或方法
15. HashMap 是否线程安全,为何不安全。 ConcurrentHashMap,线程安全,为何安全。底层实现是怎么样的。
16. J.U.C下的常见类的使用。 ThreadPool的深入考察; BlockingQueue的使用。(take,poll的区别,put,offer的区别);原子类的实现。
17. 简单介绍下多线程的情况,从建立一个线程开始。然后怎么控制同步过程,多线程常用的方法和结构
18. volatile的理解
19. 实现多线程有几种方式,多线程同步怎么做,说说几个线程里常用的方法
七、网络通信
1. http是无状态通信,http的请求方式有哪些,可以自己定义新的请求方式么。
2. socket通信,以及长连接,分包,连接异常断开的处理。
3. socket通信模型的使用,AIO和NIO。
4. socket框架netty的使用,以及NIO的实现原理,为什么是异步非阻塞。
5. 同步和异步,阻塞和非阻塞。
6. OSI七层模型,包括TCP,IP的一些基本知识
7. http中,get post的区别
8. 说说http,tcp,udp之间关系和区别。
9. 说说浏览器访问www.taobao.com,经历了怎样的过程。
10. HTTP协议、 HTTPS协议,SSL协议及完整交互过程;
11. tcp的拥塞,快回传,ip的报文丢弃
12. https处理的一个过程,对称加密和非对称加密
13. head各个特点和区别
14. 说说浏览器访问www.taobao.com,经历了怎样的过程。
八、数据库MySql
1. MySql的存储引擎的不同
2. 单个索引、联合索引、主键索引
3. Mysql怎么分表,以及分表后如果想按条件分页查询怎么办(如果不是按分表字段来查询的话,几乎效率低下,无解)
4. 分表之后想让一个id多个表是自增的,效率实现
5. MySql的主从实时备份同步的配置,以及原理(从库读主库的binlog),读写分离
6. 写SQL语句。。。
7. 索引的数据结构,B+树
8. 事务的四个特性,以及各自的特点(原子、隔离)等等,项目怎么解决这些问题
9. 数据库的锁:行锁,表锁;乐观锁,悲观锁
10. 数据库事务的几种粒度;
11. 关系型和非关系型数据库区别
九、设计模式
1. 单例模式:饱汉、饿汉。以及饿汉中的延迟加载,双重检查
2. 工厂模式、装饰者模式、观察者模式。
3. 工厂方法模式的优点(低耦合、高内聚,开放封闭原则)
十、算法
1. 使用随机算法产生一个数,要求把1-1000W之间这些数全部生成。(考察高效率,解决产生冲突的问题)
2. 两个有序数组的合并排序
3. 一个数组的倒序
4. 计算一个正整数的正平方根
5. 说白了就是常见的那些查找、排序算法以及各自的时间复杂度
6. 二叉树的遍历算法
7. DFS,BFS算法
9. 比较重要的数据结构,如链表,队列,栈的基本理解及大致实现。
10. 排序算法与时空复杂度(快排为什么不稳定,为什么你的项目还在用)
11. 逆波兰计算器
12. Hoffman 编码
13. 查找树与红黑树
十一、并发与性能调优
1. 有个每秒钟5k个请求,查询手机号所属地的笔试题(记得不完整,没列出),如何设计算法?请求再多,比如5w,如何设计整个系统?
2. 高并发情况下,我们系统是如何支撑大量的请求的
3. 集群如何同步会话状态
4. 负载均衡的原理
5 .如果有一个特别大的访问量,到数据库上,怎么做优化(DB设计,DBIO,SQL优化,Java优化)
6. 如果出现大面积并发,在不增加服务器的基础上,如何解决服务器响应不及时问题“。
7. 假如你的项目出现性能瓶颈了,你觉得可能会是哪些方面,怎么解决问题。
8. 如何查找 造成 性能瓶颈出现的位置,是哪个位置照成性能瓶颈。
9. 你的项目中使用过缓存机制吗?有没用用户非本地缓存
十二、其他
1.常用的linux下的命令