elasticsearch搜索推荐系列(一)之 ElasticSearch6.2.2安装拼音插件 elasticsearch-analysis-pinyin
拼音分词在日常生活中其实很常见,也许你每天都在用。打开淘宝看一看吧,输入拼音”zhonghua”,下面会有包含”zhonghua”对应的中文”中华”的商品的提示:
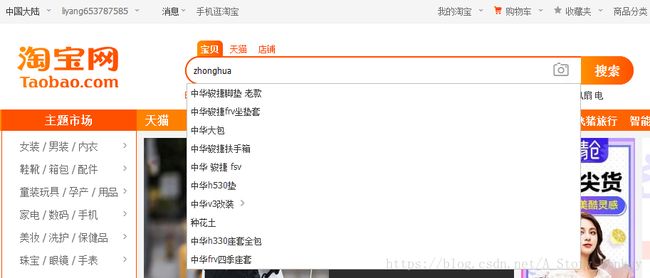
elasticsearch-analysis-pinyin 是 ElasticSearch的拼音插件,强大的功能支持拼音等的搜索。
拼音分词是根据输入的拼音提示对应的中文,通过拼音分词提升搜索体验、加快搜索速度。下面介绍如何在Elasticsearch 6.2.2中配置elasticsearch-analysis-pinyin
1、下载源代码
源码地址https://github.com/medcl/elasticsearch-analysis-pinyin
这里我是直接使用Download ZIP方式下载了源码,里面的readme 说的使用方法很详细全面,完全可以参考里面的文档进行练习。
2、解压到指定目录
下载的源码zip文件解压缩
3、修改源码的pom.xml文件
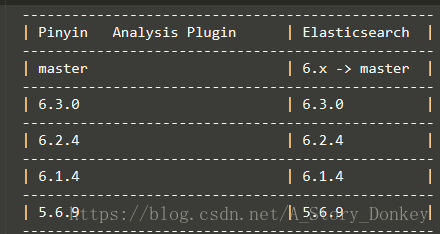
6.2.2 修改es版本为您需要的版本号这有个小插曲:我用的elasticsearch为6.2.2,看了源码下的readme版本对照信息后,发现没有对应的6.2.2的版本信息。因此我分别编译了6.2.4和6.2.2版本的elasticsearch-analysis-pinyin插件。实测都是可以在6.2.2的elasticsearch中使用。但是如果编译的是6.2.4版本的pinyin插件时,需要把plugin-descriptor.properties配置文件中elasticsearch.version修改为6.2.2,否则es无法正常启动!!!
如下图:

另附readme.md文件中的版本对照图如下:
4、mvn打包,执行mvn install
会在源码目录下生成target文件夹,在如下目录中找到elasticsearch-analysis-pinyin-6.2.2.zip
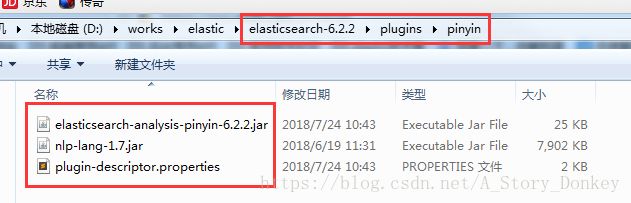
elasticsearch-analysis-pinyin-master\target\releases\elasticsearch-analysis-pinyin-6.2.2.zip5、将elasticsearch-analysis-pinyin-6.2.2.zip解压缩后的内容复制到elasticsearch的plugins目录的pinyin目录下
如果没有pinyin目录自己创建,如下图:
6、重启es,
./bin/elasticsearch.bat7、验证
在kibana中输入
GET _analyze
{
"analyzer": "pinyin",
"text": "刘德华"
}显示如下json数据则为安装成功
{
"tokens": [
{
"token": "liu",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "de",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
},
{
"token": "hua",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 2
},
{
"token": "ldh",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 2
}
]
}