【论文阅读】:Embedding-based News Recommendation for Millions of Users
非常实用性的一个推荐新闻的模型
摘要:
新闻推荐非常重要,但是传统的基于用户id的协同过滤和低秩分解推荐算法不完全适用于新闻推荐,因为新闻类文章过期的太快了
基于单词的方法性能不错,但是有处理同义词和定义用户需求的问题
因此本文提出一种基于嵌入式的算法,基于一种去噪自编码器的变体的方法来表示文章;用RNN以浏览历史为输入序列表示用户;用内积计算来匹配用户和文章
1 introduction
新闻推荐的三个关键点:
- 理解文章内容
- 理解用户喜好
- 基于两者选出每个用户的文章列表
符合这三点的baseline模型是将文章表示成单词的word的集合,用户的表示是该用户浏览过的文章包含的word的集合,用候选文章和浏览历史比较共同出现的word来判断点击的概率,这个模型简单,容易学习;但是缺点是不能很好的判断近义词,也不能很好的更充分的利用用户的浏览历史
rnn擅长处理输入序列长度变化的情况,但是只用这个模型,不能符合要求的响应速度
所以本文提出的模型分为三步,端到端,分布式:
- - 基于去噪自编码器的分布式表示方法表示出文章
- - 以浏览历史为RNN的输入 生成用户表示
- - 用内积的方式匹配出用户和文章
该方法的核心就是用内积计算来衡量用户-文章的匹配度,非常快速。现在这种方法已经应用在雅虎日本的新闻推荐了
2、our service and process flow
本文针对的是雅虎日本app中用户定制模块的部分
用户登录时为用户选择匹配列表的过程如下:
- -登录时识别出更具浏览历史提前计算出的用户特征
- - 匹配:根据用户特征计算出所有可用的文章
- - 排序:根据一些特征优先级重新排序
- - 去重
- - 插入广告(如果需要的话)
这些过程非常的快
排序时除了考虑相关度,还会考虑文章的页码数以及新鲜程度等
用cos距离来计算文本的相似度,贪心的跳过重复的文章。如果一篇文章和优先级更高的文章的相似度超过一定值,就舍弃
3、artical representations
得到文章的表示方式
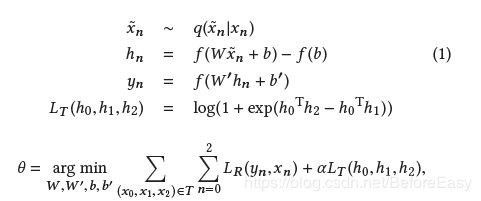

为了让输入的两篇文章x1,x2相近时得到的h1,h2内积之和大,对原本的去噪自编码器进行了修改,输入变为(x0,x1,x2)三元输入组,x0 x1是同类(相似)的文章,x2是不同的,在loss函数中添加惩罚来达到训练效果
得到的h就是后面要用来计算的
4、 user representation
通过用户的浏览历史来计算用户特征,包括的简单的word-based baseline模型,以及普通rnn形式、lstm形式和gru形式
其中a表示文章集合A中的一篇文章(用一种形式表示出来的),u表示一位用户,某个用户浏览的一系列文章就构成了用户u的浏览历史,用户通过推荐李彪点开文章才构成session,用s表示,下标p表示该文章在推荐列表中的位置
关键的目标是:

找到表示用户和文章相关性的函数R和通过浏览历史构建用户状态的函数F,满足上图的性质,其中P+表示推荐列表中用户点击过的文章,P-则是没有点击的
考虑到响应时间的限制,R必须是可以快速计算的,由于文章多而且时效端,也没法提前计算好;但是对于F却有比较充足的时间可以计算
因此,R就用内积计算来进行,![]()
只需要优化表示用户状态的函数F:
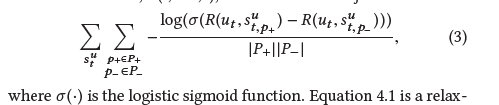
由于实际中点击的概率跟文章在session中的位置有关系,所以加了一个bias
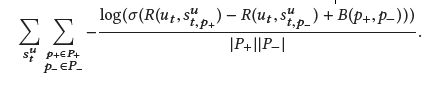
word-based模型
BoW词袋 建立一个大的词表V

相关性就是交集的单词有多少,有就+1
问题是非常稀疏,也不能处理同义词;由于浏览记录被认为是一个单词的集合,所以浏览的先后顺序和频率就丢失了
decaying model
使用第三部分所得的h来表示文章
用加权和来表示整个的浏览历史,这样根据系数可以调整浏览历史的权重

RNN model
简单RNN
毕竟decaying model是线性的,很多信息拿不到;而且ut是和上一个的状态ut-1有关系的,因此使用rnn模型
![]()
这里的激活函数用tanh,用随机梯度下降来优化
LSTM

GRU
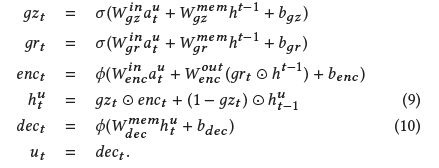
5、 offline experiments
雅虎日本主页的数据,每个用户随机选择了超过两周的数据


结果:

6 deployment
向上部署以GRU的模型作为proposd bucket,以Bow模型为control bucket作对比(1%)
提前计算用户特征ut,当用户访问该服务时,用内积计算出一段时间内新出的新闻和用户的相关度
去重后按照从高到低相关性排序
线上的度量包括:sessions(用户每天使用推荐服务的平均时间) duration(看推荐列表以及点进去后的时间) clicks(在推荐列表中点进去的次数) CTR(点击数除以推荐列表中的展示出的文章数)
将用户分为重度、中度和轻度用户
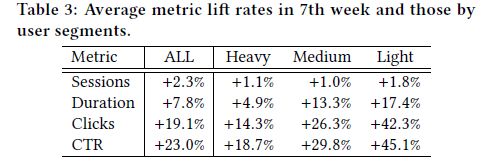
结果很好
部署大规模基于深度学习的模型时会遇到一些挑战:
学习时间长;更新困难
因此是用两个模型轮流来,以便进行更新
7 related work
8 conclusion