用anaconda单独管理keras,tensorflow,pytorch,以及它们的版本获取
2019.02.21更新
服务器升级到cuda9.0了,准备弄一个tensorflow-gpu==1.8来用。
本着先安装cudnn的原则,我计划是先安装一个cudnn7,再安装tf
所以在建立了tf18环境之后,进入环境。
anaconda search -t conda cudnn来找相应版本。
我选择了下面这个版本
anaconda show kitware-danesfield-df/cudnn
conda install --channel https://conda.anaconda.org/kitware-danesfield-df cudnn
会提示下面信息,
The following packages will be downloaded:
package | build
---------------------------|-----------------
cudnn-7.1.2 | cuda9.0_0 367.8 MB kitware-danesfield-df
cudatoolkit-9.0 | h13b8566_0 340.4 MB kitware-danesfield-df
------------------------------------------------------------
Total: 708.2 MB
The following NEW packages will be INSTALLED:
cudatoolkit: 9.0-h13b8566_0 kitware-danesfield-df
cudnn: 7.1.2-cuda9.0_0 kitware-danesfield-df
libstdcxx-ng: 8.2.0-hdf63c60_1
Proceed ([y]/n)? y
但是这是外网资源,下载是真滴慢,300M需要三个小时吧。
所以我去了conda的 官网 找安装文件
找了一个 这样的 安装文件。
下载到本地然后上传到服务器
然后用conda本地安装的方法
conda install --use-local cudnn-7.3.1-cuda9.0_0.tar.bz2
后面就是安装tf18和opencv-python了,opencv-python还是使用whl文件安装,很方便。
2019.01.29更新
之前的方法确实很简便,但是由于这个方法安装的tensorflow-gpu的包服务器可能比较老了,所以每次下载这个150M左右的包都特别耗时间,所以这里写一个更新更简单的方法来实现conda中安装tensorflow-gpu==1.4
首先我们创建一个新的conda环境,命名为tf14,并且进入环境
conda create -n tf14
conda activate tf14
我们选择安装3.6版本的python,这个时候,conda会帮我们同时安装3.6版本的pip
conda install python == 3.6
之前说过,直接用conda install tensorflow-gpu==1.4来安装是不行的,因为conda的库中没有1.4的tf-gpu,但是有另一个思路,就是使用conda中的pip来安装我们需要的tensorflow,这是可行的。
通过pip来安装tensorflow-gpu的wheel文件即可。
具体的,我们先找到需要的whl文件,镜像网站是清华大学提供的,这里我选择的是python3.6对应的1.4.0版本的tensorflow-gpu,链接在镜像网站中可以找到。
wget https://pypi.tuna.tsinghua.edu.cn/packages/08/47/bc3ccd2ecae8f9f18a93c683a66339714090a36e1b69307787fb28e72e2b/tensorflow_gpu-1.4.0-cp36-cp36m-manylinux1_x86_64.whl#sha256=8f1f89ffecd892b70fd1f2e3bc6b8ac79e07d19932f1f763d5b55d5fc1d7090e
将文件下载到本地,
在安装gpu的tensorflow之前,我们先安装一下对应版本的cudnn
conda install cudnn==6.0
然后安装tensorflow的wheel文件
pip install
这样我们就安装好了大部分需要的包了,后面可以安装一下下面这些包
pip install opencv-python
conda install matplotlib
当我们需要把一个服务器A上的环境复刻到另一台服务器B的时候,我们只需要从A导出相应的conda文件即可,这个文件包含了conda环境中包的信息。
首先进入服务器A中的conda环境并且导出环境文件
conda activate tf14
conda env export --file tf14.yml
将tf14.yml文件发送到另一台服务器,然后
conda env create --file tf14.yml
分割线,以下是旧内容
以前的python环境问题让人很头疼,有的人现在还是用linux原生的python2,然后安装python3,自己管理python环境变量以及pip,来使得他们共存。我开始也是这样。
后来开始在远程服务器remote server上用anaconda来管理环境。发现有独特的好处。
在我的电脑里面,我用conda独立创建了几个环境keras_env,tf_gpu14,意为1.4版本的tensorflow-gpu,还有pytorch_env。
在安装tf_gpu14的过程中,有几个问题
首先考虑到服务器的cuda driver是8.0,所以这里我们考虑cudnn版本6.0,进而选择1.4版本的tensorlfow-gpu

首先我们创建环境
conda create -n tf_gpu14
然后激活
conda activate tf_gpu14
进入之后,在该环境下安装需要的tf的版本
尝试使用conda install tensorflow-gpu==1.4
会发现版本太久远, anaconda官方库已经找不到了。
这时候考虑其他的conda预编译的包,查找他们的方式是
anaconda search -t conda tensorflow-gpu
返回结果如下
然后展示一下我们需要的包的信息
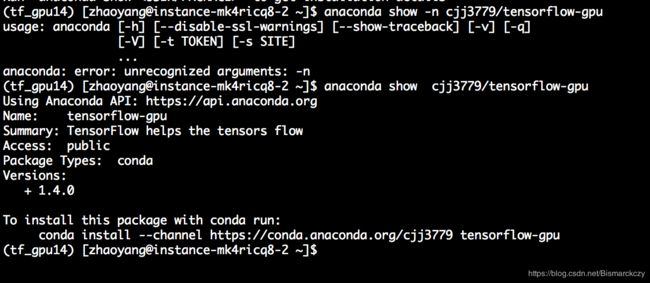
直接按照提示的命令行进行安装即可。
注意这样安装的tensorflow-gpu跟直接conda install tensorflow-gpu不一样,后者会把cudnn给我们配置好。
所以我们还需要手动安装6.0版本cudnn的包
conda install cudnn==6.0.0
之后 会发现gpu版本的tensorflow就可以成功运行了
顺便给一个gpu tf的测试代码
import sys
import numpy as np
import tensorflow as tf
from datetime import datetime
device_name = sys.argv[1] # Choose device from cmd line. Options: gpu or cpu
shape = (int(sys.argv[2]), int(sys.argv[2]))
if device_name == "gpu":
device_name = "/gpu:0"
else:
device_name = "/cpu:0"
with tf.device(device_name):
random_matrix = tf.random_uniform(shape=shape, minval=0, maxval=1)
dot_operation = tf.matmul(random_matrix, tf.transpose(random_matrix))
sum_operation = tf.reduce_sum(dot_operation)
startTime = datetime.now()
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as session:
result = session.run(sum_operation)
print(result)
# It can be hard to see the results on the terminal with lots of output -- add some newlines to improve readability.
print("\n" * 5)
print("Shape:", shape, "Device:", device_name)
print("Time taken:", datetime.now() - startTime)
print("\n" * 5)