CUDA之Warp Shuffle详解
之前我们有介绍shared Memory对于提高性能的好处,在CC3.0以上,支持了shuffle指令,允许thread直接读其他thread的寄存器值,只要两个thread在 同一个warp中,这种比通过shared Memory进行thread间的通讯效果更好,latency更低,同时也不消耗额外的内存资源来执行数据交换。主要包含如下API:
- int __shfl(int var, int srcLane, int width=warpSize);
- int __shfl_up(int var, unsigned int delta, int width=warpSize);
- int __shfl_down(int var, unsigned int delta, int width=warpSize);
- int __shfl_xor(int var, int laneMask, int width=warpSize);
- float __shfl(float var, int srcLane, int width=warpSize);
- float __shfl_up(float var, unsigned int delta, int width=warpSize);
- float __shfl_down(float var, unsigned int delta, int width=warpSize);
- float __shfl_xor(float var, int laneMask, int width=warpSize);
- half __shfl(half var, int srcLane, int width=warpSize);
- half __shfl_up(half var, unsigned int delta, int width=warpSize);
- half __shfl_down(half var, unsigned int delta, int width=warpSize);
- half __shfl_xor(half var, int laneMask, int width=warpSize);
这里介绍warp中的一个概念lane,一个lane就是一个warp中的一个thread,每个lane在同一个warp中由lane索引唯一确定,因此其范围为[0,31]。在一个一维的block中,可以通过下面两个公式计算索引:
laneID = threadIdx.x % 32
warpID = threadIdx.x / 32
例如,在同一个block中的thread1和33拥有相同的lane索引1。
Variants of the Warp Shuffle Instruction
有两种设置shuffle的指令:一种针对整型变量,另一种针对浮点型变量。每种设置都包含四种shuffle指令变量。为了交换整型变量,使用过如下函数:
int __shfl(int var, int srcLane, int width=warpSize);
该函数的作用是将var的值返回给同一个warp中lane索引为srcLane的thread。可选参数width可以设置为2的n次幂,n属于[1,5]。
eg:如果shuffle指令如下:
int y = shfl(x, 3, 16);
则,thread0到thread15会获取thread3的数据x,thread16到thread31会从thread19获取数据x。
当传送到shfl的lane索引相同时,该指令会执行一次广播操作,如下所示:
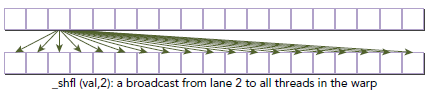
另一种使用shuffle的形式如下:
int __shfl_up(int var, unsigned int delta, int width=warpSize)
该函数通过使用调用方的thread的lane索引减去delta来计算源thread的lane索引。这样源thread的相应数据就会返回给调用方,这样,warp中最开始delta个的thread不会改变,如下所示:
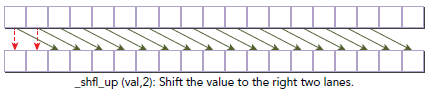
第三种shuffle指令形式如下:
int __shfl_down(int var, unsigned int delta, int width=warpSize)
该格式是相对__shfl_down来说的,具体形式如下图所示:

最后一种shuffle指令格式如下:
int __shfl_xor(int var, int laneMask, int width=warpSize)
这次不是加减操作,而是同laneMask做抑或操作,具体形式如下图所示:

所有这些提及的shuffle函数也都支持单精度浮点值,只需要将int换成float就行,除此外,和整型的使用方法完全一样。
我们这里以reduction为例,看一下相比于使用shared memory进行通信的性能差异。
算法背景:为了简单起见,我们计算每32个int型变量元素的元素和。假设一个数组包含n个元素(e.g. n = 1 << 20),每32个元素计算一个和,则输出结果为n/32个int型变量。在编程中,block的大小就是32(刚好是一个warp),grid的大小是n / 32。
第一种,利用shared memory进行reduction:
- __global__ void reduce0(int *dst, int *src, const int n) {
- __shared__ int sdata[WARP_SIZE*2];
- int tidGlobal = threadIdx.x + blockDim.x * blockIdx.x;
- int tidLocal = threadIdx.x;
- sdata[tidLocal] = src[tidGlobal];
- //actually the sync is no need here because only a warp exists in a block.
- __syncthreads();
- //only 32 threads in a block
- //reduce in a warp
- if (tidLocal < 32)
- sdata[tidLocal] += sdata[tidLocal+16];
- __syncthreads();
- if (tidLocal < 32)
- sdata[tidLocal] += sdata[tidLocal+8];
- __syncthreads();
- if (tidLocal < 32)
- sdata[tidLocal] += sdata[tidLocal+4];
- __syncthreads();
- if (tidLocal < 32)
- sdata[tidLocal] += sdata[tidLocal+2];
- __syncthreads();
- if (tidLocal < 32)
- sdata[tidLocal] += sdata[tidLocal+1];
- __syncthreads();
- if (tidLocal == 0)
- dst[blockIdx.x] = sdata[0];
- }
- 为了使warp内没有分支,32个线程都做加法操作(多分配点shared memory空间即可)。
- 一个warp内的32个线程执行是同步的,因此不用担心写后读的错误。
- 其实,一个block内只有一个warp,因此,所有的同步函数在这里都可以省略,条件语句if(tidLocal < 32)也可以省略。
第二种,利用shuffle进行通信:
- __global__ void reduce1(int *dst, int *src, const int n) {
- int tidGlobal = threadIdx.x + blockDim.x * blockIdx.x;
- int tidLocal = threadIdx.x;
- int sum = src[tidGlobal];
- //actually the sync is no need here because only a warp exists in a block.
- __syncthreads();
- for (int offset = WARP_SIZE/2; offset > 0; offset /= 2) {
- sum += __shfl_down(sum, offset);
- }
- if (tidLocal == 0)
- dst[blockIdx.x] = sum;
- }
- 我们利用shuffle来做warp内的通信,因此没有用到shared memory。
- 关于shuffle的操作含义,可以参考"cuda programming guide".
性能测试:
利用nvvp,我们来分析一下两个kernel的执行时间:
- ==31758== NVPROF is profiling process 31758, command: ./a.out
- Device 0: "Tesla K20c"
- check right!
- check right!
- ==31758== Profiling application: ./a.out
- ==31758== Profiling result:
- Time(%) Time Calls Avg Min Max Name
- 80.87% 2.5935ms 1 2.5935ms 2.5935ms 2.5935ms [CUDA memcpy HtoD]
- 8.07% 258.76us 1 258.76us 258.76us 258.76us reduce0(int*, int*, int)
- 6.02% 192.90us 1 192.90us 192.90us 192.90us reduce1(int*, int*, int)
- 5.04% 161.73us 2 80.866us 80.866us 80.866us [CUDA memcpy DtoH]