[论文笔记] 人脸识别方向系列论文
虽然 Face Recognition 翻译过来为人脸识别,容易让人混淆,其实用 Face Identification/Verfication 更好一些,即人脸识别/验证。其中,两者的区别如下:
Face Identification : Face Identification is 1:many, i.e., you have to find an unknown person in a dataset to answer the question " who is this person". You have to check the biometrics against all others in the database.
Face Verification : Face Verification is 1:1, i.e. you have to check if this person is the correct one. In this case you have to know somthing more about the person e.g. name. You only have to check one biometric profile.
PS: 推荐大家看看这个专栏里的文章 人脸识别合集,讲的比较详细。此外,还推荐大家看看这个基于 PyTorch 实现的人脸识别库项目 ZhaoJ9014/face.evoLVe.PyTorch,该项目提供了在各个数据集上训练完毕的模型参数,可作为预训练模型使用。
目录
1. DeepFace
2. DeepID1
3. DeepID2
4. DeepID2+
5. DeepID3
6. FaceNet
7. VGGFace
8. Center Loss
9. L-Softmax Loss
10. SphereFace
11. CosFace
12. ArcFace
13. AM-Softmax Loss
1. DeepFace
论文链接:DeepFace: Closing the Gap to Human-Level Performance in Face Verification, 发表时间:CVPR 2014
DeepFace 由 FaceBook AI Research Lab 发表于 CVPR 2014,被认为是最早将深度学习用于人脸识别的开创性工作。在论文中,作者指出人脸识别的流程为:Face Detect -> Face Align -> Represent -> Classify,并分别在 Face Align 和 Represent 阶段做出改进:引入 3D 人脸对齐技术和深度学习,最终在 LFW 上取得了 97.35% Accuracy 的成绩。
关于 Face Alignment:
在人脸识别任务中,常见的人脸对齐都是基于仿射变化在二维平面进行对齐的,但在 DeepFace 中,作者引入了 3D 人脸对齐技术:检测 6 个人脸关键点 -> 基于人脸关键点进行裁剪以及 2D-align -> 在裁剪所得的人脸图像上进行 67 个人脸关键点的检测,并进行 Delaunay Triangulation -> 将经过 Delaunay Triangulation 后的人脸图像转换为 3D -> 根据 3D 信息与人脸关键点信息,生成带深度的三角可视网络 -> 进行仿射变换,使得人脸图像正面朝前 -> 得到对齐后的人脸图像。
![[论文笔记] 人脸识别方向系列论文_第1张图片](http://img.e-com-net.com/image/info8/2614187e094c4b608863c2868aa6bb92.jpg)
关于网络结构:
在论文中,作者利用 CNN 提取人脸特征,所提取特征的维度为 4096。与后续许多工作相比,这样的维度无疑大了不少。
![[论文笔记] 人脸识别方向系列论文_第2张图片](http://img.e-com-net.com/image/info8/f6b69752060d4c63b41321f10d19da07.jpg)
此外,作者还对所提取的人脸特征进行归一化,以降低光照条件对特征的影响:先对特征的每一维进行标准化,即除以该维度在整个训练集上的最大值,再对每个向量进行 L2 归一化。
![[论文笔记] 人脸识别方向系列论文_第3张图片](http://img.e-com-net.com/image/info8/331cb34f3d494d20a2c06b3d5b952942.jpg)
2. DeepID1
论文链接:Deep Learning Face Representation from Predicting 10,000 Classes, 发表时间:CVPR 2014
DeepID 系列论文由港中文的孙祎、王晓刚、汤晓鸥(商汤科技创始人,CUHK的教授,其实验室链接为 Multimedia Laboratory)发表,其中,DeepID1 发表于 CVPR 2014。在论文中,作者利用卷积网络学习 High-level Face Identity Feature,从而解决 Face Identity 问题(论文中,所识别的 ID 数量约为 10000)。此外,作者提出了两种用模型所提取的特征(即人脸表示)解决 Face Verification 问题的方案:利用神经网络进行二分类识别或利用联合贝叶斯模型进行分类,并在 LFW 上取得了 97.45% Verification Accuracy 的成绩。
![[论文笔记] 人脸识别方向系列论文_第4张图片](http://img.e-com-net.com/image/info8/a9372b1e46aa4d61b6db8361db1d49e7.jpg)
关于模型结构:
作者设计的模型共有四层卷积层,其中,第三层卷积层的输出(经过最大池化层后)与第四层卷积层的输出一起作为最后的 FC 层的输入,该 FC 层输出维度为 160。模型具体细节如下所示:
![[论文笔记] 人脸识别方向系列论文_第5张图片](http://img.e-com-net.com/image/info8/775d404b3d644eb9b7e046ad251db633.jpg)
关于预处理操作:
作者对图像进行人脸关键点检测,再根据所检测的关键点进行人脸对齐。接着,作者在对齐后的人脸图像进行裁剪与变化:10 个区域,3 种尺度,2 种颜色空间(RGB 和 Gray),共计裁剪出 60 个 Patch。
对于每个 Patch,作者都训练一个模型进行特征提取,每个 Patch 都会进行水平翻转(两眼中心与嘴角附近的 Patch 使用水平翻转后的对称区域的 Patch 作为翻转结果),故每个模型提取 2 * 160 维特征,共计 60 * 2 * 160维特征。
对于矩形 Patch,模型的输入尺寸为 39 * 31 * k;对于正方形 Patch,模型的输入尺寸为 31 * 31 * k。(模型隐藏层的 Feature Map 尺寸随着输入尺寸变化而进行相应变化)
![[论文笔记] 人脸识别方向系列论文_第6张图片](http://img.e-com-net.com/image/info8/71dd0cf694ea4ccba70f343a05cda724.jpg)
关于 Face Verification:
作者在基于联合贝叶斯(Joint Bayesian,相关细节可以看这篇论文:Bayesian Face Revisited: A Joint Formulation)进行 Face Verification 前,先利用 PCA 将模型所提取的特征由 60 * 2 * 160 维降到 150 维,再假设特征为两个独立的高斯分布之和:不同人的类间差异分布,同一人的类内差异分布,利用 EM 算法对分布参数进行估计。在测试时,计算似然比,似然比大于一即可认为两张图像属于同一人。
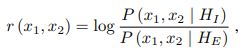
作者在基于神经网络进行 Face Verification 时,引入了 Locally-Connected Layer,该层共计 80 * 60 个神经元,每 80 个神经元连接每对 Patch 所对应的 2 * 320 维特征,具体细节如下所示:
![[论文笔记] 人脸识别方向系列论文_第7张图片](http://img.e-com-net.com/image/info8/d79f7a093ef74344ab2552eb0c1217ce.jpg)
3. DeepID2
论文链接:Deep Learning Face Representation by Joint Identification-Verification, 发表时间:2014.06
DeepID2 是 DeepID 系列论文中的第二篇文章,与 DeepID1 相比,该论文最主要的改进在于同时进行 Face Identification 与 Face Verification 的训练(作者的原话为:‘The face identification task increases the inter-personal variations by drawing DeepID2 extracted from different identities apart, while the face verification task reduces the intra-personal variations by pulling DeepID2 extracted from the same identity together’),最终在 LFW 上取得了 99.15% Verification Accuracy 的成绩。
关于模型结构:
与 DeepID1 相比,DeepID2 的模型并无太大的变化,依旧是四层卷积层,第三层(经过最大池化层后)和第四层的输出一起作为最后的 FC 层的输入,最后输出的特征维度依然为 160。但是,在 DeepID2 中,作者在第三、四层卷积层中引入了局部权重共享,即第三层卷积层中每 2*2 的区域进行局部权重共享,第四层卷积层中所有神经元的权重皆不共享。
![[论文笔记] 人脸识别方向系列论文_第8张图片](http://img.e-com-net.com/image/info8/f56322910dc346d18c00a47bf00eea52.jpg)
此外,在 DeepID2 中,作者依然对人脸图像进行裁剪、缩放等操作,生成 200 个 Patch,分别用于训练 200 个模型,最终的特征维度为 200 * 2 * 160。
关于联合训练:
在 Face Identification 时,作者采用 Softmax Loss:(实验中,n 为 8192)
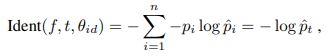
在 Face Verification 时,作者采用 L2 norm:(实验中,作者令 m 为最新训练样本中的最小 Face Verification Error)
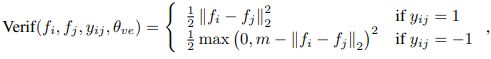
此外,作者还用超参数 λ \lambda λ 控制 Face Verification Loss 的权重。模型参数的更新过程如下所示:
![[论文笔记] 人脸识别方向系列论文_第9张图片](http://img.e-com-net.com/image/info8/69aec7016efc4843a45fd3dd04c36402.jpg)
关于 Face Verification:
为了减少所提取特征的维度,作者利用 foward-backward greedy algorithm 从所裁剪的 Patch 中进行挑选,共挑出 25 个 Patch,合并后的特征维度为 4000。在此基础上,作者还利用 PCA 进行降维,最终所用特征的维度为 180。(在 DeepID2 中,作者还是利用 Joint Bayesian 进行 Face Verification)
![[论文笔记] 人脸识别方向系列论文_第10张图片](http://img.e-com-net.com/image/info8/79954251a30d464da8d4ff6d9642917d.jpg)
4. DeepID2+
论文链接:Deeply learned face representations are sparse, selective, and robust, 发表时间:2014.10
在 DeepID2+ 中,作者增大所提取人脸特征的维度,增加训练数据的数量,并在 DeepID2 的基础上引入 Pridiction Pyramid 结构,最终在 LFW 和 YouTubeFaces 上取得了 99.47% 和 93.2% Verification Accuracy 的成绩。
作者修改了 DeepID2 的网络结构,使其每个卷积层输出 128 个 Feature Map,并各接一层 FC Layer(输出的特征维度由原来的 160 增加到 512)。同时,作者依旧保持 DeepID2 中的 Face Identidfication 和 Face Verification 的联合训练。此外,作者还将合并 CelebFaces+ 和WDRef 数据集,以此扩大的了训练数据。
![[论文笔记] 人脸识别方向系列论文_第11张图片](http://img.e-com-net.com/image/info8/dba97212196a4c37b86d475d507b72af.jpg)
作者在 DeepID2 中所选定的 25 个 Patch 上进行对比实验,以此对比 DeepID2 与 DeepID2+ 的性能,对比结果如下所示。此外,作者认为高性能深度网络的的三个特性为:sparse, selective and robust,并通过实验进行了说明,相关细节可在论文中进行查阅。
![[论文笔记] 人脸识别方向系列论文_第12张图片](http://img.e-com-net.com/image/info8/9a9443fb9628426da371bc17fd1a98e9.jpg)
5. DeepID3
论文链接:DeepID3: Face Recognition with Very Deep Neural Networks, 发表时间:2015.02
在 DeepID3 中,作者参考 VGG 和 GoogLeNet 的网络结构,构造出两种网络框架:DeepID3 net1(基于 VGG 网络结构),DeepID3 net2(基于 GooLeNet 网络结构),并在 LFW 上取得 99.53% 的 Verification Accuracy。
![[论文笔记] 人脸识别方向系列论文_第13张图片](http://img.e-com-net.com/image/info8/d537b51661244d42b6bde8d92843f89e.jpg)
与 DeepID2+ 相似,作者在所选定的 25 个 Patch 上进行性能对比,其结果如下所示。可以看出,DeepID3 net1 性能略高于 DeepID2+,但 DeepID3 net2 与 DeepID2+ 基本持平。
![[论文笔记] 人脸识别方向系列论文_第14张图片](http://img.e-com-net.com/image/info8/fc0505d70b804734bdba0b4a45490052.jpg)
6. FaceNet
论文链接:FaceNet: A Unified Embedding for Face Recognition and Clustering, 发表时间:2015.02
FaceNet 由 Google 于 2015.02 发表,与 DeepID 系列论文相比,FaceNet 显示学习 embedding(最后得到的特征维度为 128):将人脸图像映射到欧几里得空间,用其空间距离衡量彼此的相似度,并提出 Triplet Loss 以代替 Softmax Loss,最终在 LFW 和 YouTube Face 上取得 99.63% 和 95.12% Accuracy 的成绩。(由下图可以看出,FaceNet 所提取的人脸特征需要进行 L2 归一化)
![[论文笔记] 人脸识别方向系列论文_第15张图片](http://img.e-com-net.com/image/info8/6add860d2a3645af81e2752af9305581.jpg)
关于 Triplet Loss:
啥是 Triplet?在该篇论文中,Triplet 为由 Anchor、Positive、Negative 所组成的三元组,其中,Anchor 与 Positive 分别为同一 ID 的不同人脸图像,而 Negative 为与 Anchor 不同 ID 的任意人脸图像。
Triplet Loss 是 triplet-based loss,其主要思想与 LMNN(Large margin nearest neighbor)相似,Triplet Loss 旨在向量空间内,最小化 Anchor(单个ID图像) 与 Positive(同一 ID 的其他不同图像) 的距离并同时最大化 Anchor 与 Negative(不同 ID 的任意图像) 的距离,即目标为 ∣ ∣ f ( x a ) − f ( x p ) ∣ ∣ 2 2 + α < ∣ ∣ f ( x a ) − f ( x n ) ∣ ∣ 2 2 ||f(x_a)-f(x_p)||_{2}^{2}+\alpha<||f(x_a)-f(x_n)||_{2}^{2} ∣∣f(xa)−f(xp)∣∣22+α<∣∣f(xa)−f(xn)∣∣22,公式表示为: L = [ ∣ ∣ f ( x a ) − f ( x p ) ∣ ∣ 2 2 − ∣ ∣ f ( x a ) − f ( x n ) ∣ ∣ 2 2 + α ] + L=[||f(x_a)-f(x_p)||_{2}^{2}-||f(x_a)-f(x_n)||_{2}^{2}+\alpha]_{+} L=[∣∣f(xa)−f(xp)∣∣22−∣∣f(xa)−f(xn)∣∣22+α]+。(其中, α \alpha α 为所设定的 Margin,在该篇论文中,作者将其设为 0.2)
![[论文笔记] 人脸识别方向系列论文_第16张图片](http://img.e-com-net.com/image/info8/6058b1b7a07f4d04ba51aef61ffd3a3d.jpg)
我们可以对每个 Triplet 进行划分(下图为当 Anchor与 Positive 固定时,Negative 的划分):
- Easy Triplet : ∣ ∣ f ( x a ) − f ( x p ) ∣ ∣ 2 2 + α < ∣ ∣ f ( x a ) − f ( x n ) ∣ ∣ 2 2 ||f(x_a)-f(x_p)||_{2}^{2}+\alpha < ||f(x_a)-f(x_n)||_{2}^{2} ∣∣f(xa)−f(xp)∣∣22+α<∣∣f(xa)−f(xn)∣∣22,即 Anchor 与 Positive 的距离加上 Margin 后仍小于 Anchor 到 Negative 的距离,此时该 Triplet 无需优化。
- Semi-hard Triplet : ∣ ∣ f ( x a ) − f ( x p ) ∣ ∣ 2 2 < ∣ ∣ f ( x a ) − f ( x n ) ∣ ∣ 2 2 < ∣ ∣ f ( x a ) − f ( x p ) ∣ ∣ 2 2 + α ||f(x_a)-f(x_p)||_{2}^{2} < ||f(x_a)-f(x_n)||_{2}^{2} < ||f(x_a)-f(x_p)||_{2}^{2}+\alpha ∣∣f(xa)−f(xp)∣∣22<∣∣f(xa)−f(xn)∣∣22<∣∣f(xa)−f(xp)∣∣22+α
- Hard Triplet : ∣ ∣ f ( x a ) − f ( x n ) ∣ ∣ 2 2 < ∣ ∣ f ( x a ) − f ( x p ) ∣ ∣ 2 2 ||f(x_a)-f(x_n)||_{2}^{2} < ||f(x_a)-f(x_p)||_{2}^{2} ∣∣f(xa)−f(xn)∣∣22<∣∣f(xa)−f(xp)∣∣22,即 Anchor 与 Negative 的距离小于 Anchor 与 Positive 的距离。
![[论文笔记] 人脸识别方向系列论文_第17张图片](http://img.e-com-net.com/image/info8/11a9c5702dcf481484e20c46dd6951ca.jpg)
接下来讲讲训练过程中,如何筛选/选择 Triplet(在实际应用中,Triplet 的选择对模型的收敛有很大影响)。
最难区分的 Triplet 可以使得模型快速的收敛,即给定 Anchor 后,挑选出 Hardest Postitive: a r g m a x ( ∣ ∣ f ( x i a ) − f ( x i p ) ∣ ∣ 2 2 ) argmax(||f(x^a_i)-f(x^p_i)||_{2}^{2}) argmax(∣∣f(xia)−f(xip)∣∣22) 和 Hardest Negative: a r g m i n ( ∣ ∣ f ( x i a ) − f ( x i n ) ∣ ∣ 2 2 ) argmin(||f(x^a_i)-f(x^n_i)||_{2}^{2}) argmin(∣∣f(xia)−f(xin)∣∣22)。但这样做会导致两个问题:计算成本过高(毕竟要遍历整个训练集),导致训练无法收敛(训练集中可能存在标注错误)。
在论文中,作者提出了两种解决方案:
- Generate triplets offline every n steps,即每隔多个迭代便保存一次 Net Checkpoint,并以此在训练集的子集(并非整个训练集)上遍历寻找 Hard Positive 和 Hard Negative。
- Generate triplets online,即设置较大的 Batch Size,训练过程中,仅在 mini-batch 中遍历寻找 Hardest Positive 和 Hardest Negative(作者通过实验发现,相较于选择 Hardest Positive,使用所有的 Positive 会使得训练更加稳定以及训练速度加快)。
在论文中,作者使用了第二种方案,并设置每个 mini-Batch 中所有 ID 都有40张图像,并随机挑选 Negative 加入其中进行训练。此外,作者也发现选择 Hardest Negative 往往容易导致模型早期陷入局部极小值,故改为选择 Semi-hard Negative。
关于网络结构:
作者探索了两种网络结构:GoogLeNet 和 Zeiler&Fergus 在 Visualizing and Understanding Convolutional Networks 中所使用的网络。
![[论文笔记] 人脸识别方向系列论文_第18张图片](http://img.e-com-net.com/image/info8/f8c1aa1739fb45ff953c481d0959aa26.png)
![[论文笔记] 人脸识别方向系列论文_第19张图片](http://img.e-com-net.com/image/info8/986db46f51d54572b0a8d625a1abc66b.jpg)
7. VGGFace
论文链接:Deep Face Recognition, 发表时间:2015.05
VGG 组在 2015年提出了 VGGFace Dataset,该数据集包含 2622 个 ID, 260 万张图像,其制作过程作者也在论文中进行了详细的说明。此外,作者以 VGGNet 作为基础,对其进行修改,最终在 LFW 和 YTF 上 98.95% 和 97.3% Verification Accuracy 的成绩。
虽然 FaceBook 的 DeepFace 和 Google 的 FaceNet 都使用了更大的数据集,但貌似都不是开源的,故 VGGFace 应该是目前第三大的开源人脸识别数据集了(目前的第一/第二应该分别是 MegaFace、VGGFace2)。
![[论文笔记] 人脸识别方向系列论文_第20张图片](http://img.e-com-net.com/image/info8/e74066bfe65a4a5d939e2a454aec695a.jpg)
关于 VGGFace Dataset:
作者在论文中详细的介绍了构建 VGGFace Dataset 的过程:
- 在 Freebase 和 IMDb 网站上搜集名人名单(含有 500K 个不同的 ID),取其排名最靠前的 2500 个男性和 2500 个女性组成初始名单。利用 Google 搜索,每个 ID 包含 200 张人脸图像。接着,手工去除所含人脸图像不够纯净的 ID,剩下 3250 个 ID。最后再去除 LFW 和 YTF 中所含有的 ID,剩下 2622 个 ID。
- 利用 Google/Bing 搜索,以及是否添加关键字 “actor”,各取前 500 结果,从而使得每个 ID 含有 2000 张人脸图像。
- 以每个 ID 的 Top 50 的人脸图像作为正样本,以其他 ID 的 Top 50 的人脸图像作为负样本,训练 one-vs-rent linear SVM,筛选每个 ID 所含图像,每个 ID 仅保留 1000 张人脸图像。
- 利用 VLAD 算子筛选重复图像,每个 ID 仅保留 623 张人脸图像。
- 手动筛选数据集,每个 ID 仅保留 375 张人脸图像。
![[论文笔记] 人脸识别方向系列论文_第21张图片](http://img.e-com-net.com/image/info8/2c309d8bfd4b435fa300f9495991e790.jpg)
关于网络结构:
![[论文笔记] 人脸识别方向系列论文_第22张图片](http://img.e-com-net.com/image/info8/a3b852842c1540a58f5caf5b83a6914c.jpg)
8. Center Loss
论文链接:A Discriminative Feature Learning Approach for Deep Face Recognition, 发表时间:ECCV 2016
Center Loss 发表于 ECCV 2016,论文的主要贡献在于对损失函数进行改进,提出 Center Loss 用于减少类内距离,加上常用的 Softmax Loss(其实这样表达不够严谨,应该是 The combination of the last FC Layer and Cross-entropy Loss with Softmax Function
才对,为了表述简单,下文以 Softmax Loss 代替),使得模型所提取特征 Separable and Discriminative。最终,作者在 LFW 和 YTF 上取得了 99.28% 和 94.9% Verification Accuracy 的成绩(虽然不是 SOTA,但是与其他模型相比,作者所用模型明显更加轻量)。
![[论文笔记] 人脸识别方向系列论文_第23张图片](http://img.e-com-net.com/image/info8/6f44bbd70c6a4acdba434e8017c1c5e9.jpg)
关于 Center Loss:
作者认为之前常用的 Softmax Loss,虽然可以增加类间距离,但是无法减少类内距离,故只能学到 Separable Feature,并不能学到 Discriminative Feature。此外,虽然 DeepID2 和 FaceNet 也都有为减少类内距离构造损失函数(Contrastive Loss 和 Triplet Loss),但是作者认为这两个损失函数需要构造 Pair/Triplet,会降低训练速度/使训练过程不稳定/增加计算成本/导致训练过程更复杂。
![[论文笔记] 人脸识别方向系列论文_第24张图片](http://img.e-com-net.com/image/info8/950730850928403db33678d01cf76587.jpg)
上图为使用 Softmax Loss 所学习到的特征的可视化结果,可以看出,所学习的特征虽然类间距离比较大,但是仍然具有 Signifcant Intra-class Variation。于是,作者就提出了 Center Loss: L = 1 2 ∑ i = 1 m ∣ ∣ x i − c y i ∣ ∣ 2 2 L=\frac{1}{2}\sum_{i=1}^{m}||x_i-c_{y_i}||_2^2 L=21∑i=1m∣∣xi−cyi∣∣22,其中, c y i c_{y_i} cyi 为样本 y i y_i yi 所对应的 Center。此外,作者还设置了两个超参数: α \alpha α 用于控制 Center 的学习率, λ \lambda λ 用于控制 Center Loss 的权重(在论文中,作者做了可视化以及对比实验以探究这两个超参数对实验结果的影响)。
![[论文笔记] 人脸识别方向系列论文_第25张图片](http://img.e-com-net.com/image/info8/0c5fc8ccc00949ceb5ff0adbdcc9e542.jpg)
![[论文笔记] 人脸识别方向系列论文_第26张图片](http://img.e-com-net.com/image/info8/e0a0f51514be4aed89c4eb72dd84631a.jpg)
网络结构:
作者所用网络比较轻量:使用了 Local Convolution Layer,最后一层 FC Layer 的输入为倒数第两层和倒数第三层的输出。
![[论文笔记] 人脸识别方向系列论文_第27张图片](http://img.e-com-net.com/image/info8/cc44a2cd6da7477f97346c8991c7950b.jpg)
PS: Github 复现项目 KaiyangZhou/pytorch-center-loss(基于 PyTorch 复现)。
9. L-Softmax Loss
论文链接:Large-Margin Softmax Loss for Convolutional Neural Networks, 发表时间:2016.12
在该篇论文中,作者对 Softmax Loss 进行分析,并对其进行了改进(作者称其为 Large-Margin Softmax Loss,简称 L-Softmax Loss):引入 Multiplicative Angular Margin,使不同类别的决策边界之间的距离更大。不同于之前的 Contrastive Loss/Triplet Loss/Center Loss,L-Softmax Loss 计算复杂度低,且能更好的增加类间距离,减小类内距离。(L-Softmax Loss 的可视化结果如下所示)
![[论文笔记] 人脸识别方向系列论文_第28张图片](http://img.e-com-net.com/image/info8/e0d20c4e383243638b1ab896c138b2e4.jpg)
下面以二分类问题为例,讲解作者如何由 Softmax Loss 改进,从而提出 L-Softmax Loss:
L i = − l o g e f y i ∑ j e f y j = − l o g e W y i T x ∑ j e W y j T x = − l o g e ∣ ∣ W y i ∣ ∣ ∗ ∣ ∣ x ∣ ∣ ∗ c o s ( θ y i ) ∑ j e ∣ ∣ W y j ∣ ∣ ∗ ∣ ∣ x ∣ ∣ ∗ c o s ( θ y j ) L_{i}=-log{\frac{e^{f_{y_{i}}}}{\sum_{j}{e^{f_{y_j}}}}}=-log{\frac{e^{W^{T}_{y_i}x}}{\sum_{j}{e^{W^{T}_{y_j}x}}}}=-log{\frac{e^{||W_{y_i}||*||x||*cos(\theta_{y_i})}}{\sum_{j}{e^{||W_{y_j}||*||x||*cos(\theta_{y_j})}}}} Li=−log∑jefyjefyi=−log∑jeWyjTxeWyiTx=−log∑je∣∣Wyj∣∣∗∣∣x∣∣∗cos(θyj)e∣∣Wyi∣∣∗∣∣x∣∣∗cos(θyi)
在二分类问题中,这意味着模型的决策边界(Decision Boundary)为 ∣ ∣ W y 1 ∣ ∣ ∗ c o s ( θ y 1 ) = ∣ ∣ W y 2 ∣ ∣ ∗ c o s ( θ y 2 ) ||W_{y_1}||*cos(\theta_{y_1})=||W_{y_2}||*cos(\theta_{y_2}) ∣∣Wy1∣∣∗cos(θy1)=∣∣Wy2∣∣∗cos(θy2)。
作者便联想到是否可以利用余弦函数在 [0, π \pi π] 上的单调递减性,使得分类变得更难,从而使得决策边界分离开来:当样本类别为 1 时,作者将类别 1 的决策边界设置为 ∣ ∣ W y 1 ∣ ∣ ∗ c o s ( m θ y 1 ) > ∣ ∣ W y 2 ∣ ∣ ∗ c o s ( θ y 2 ) ||W_{y_1}||*cos(m\theta_{y_1})>||W_{y_2}||*cos(\theta_{y_2}) ∣∣Wy1∣∣∗cos(mθy1)>∣∣Wy2∣∣∗cos(θy2)( 0 ≤ θ y 1 ≤ π m 0 \leq \theta_{y_1} \leq \frac{\pi}{m} 0≤θy1≤mπ)。
当 π m ≤ θ y 1 \frac{\pi}{m} \leq \theta_{y_1} mπ≤θy1 时,这样设置存在问题。故作者重新设计了 ψ ( θ ) \psi(\theta) ψ(θ) 函数,其详细定义如下所示。当然, ψ ( θ ) \psi(\theta) ψ(θ) 函数中的 D ( θ ) D(\theta) D(θ) 定义并不唯一,在 [ π m \frac{\pi}{m} mπ, π \pi π] 上满足单调递减且满足 D ( π m ) = c o s ( π m ) D(\frac{\pi}{m})=cos(\frac{\pi}{m}) D(mπ)=cos(mπ) 即可。
![[论文笔记] 人脸识别方向系列论文_第29张图片](http://img.e-com-net.com/image/info8/7d4a756562d3459799658744dd9c0aad.jpg)
![[论文笔记] 人脸识别方向系列论文_第30张图片](http://img.e-com-net.com/image/info8/1399dd63e0d54ec2ae73c216d76d1367.jpg)
于是,L-Softmax Loss 为:
L i = − l o g e ∣ ∣ W y i ∣ ∣ ∗ ∣ ∣ x ∣ ∣ ∗ ψ ( θ y i ) e ∣ ∣ W y j ∣ ∣ ∗ ∣ ∣ x ∣ ∣ ∗ ψ ( θ y j ) + ∑ j ≠ i e ∣ ∣ W y j ∣ ∣ ∗ ∣ ∣ x ∣ ∣ ∗ c o s ( θ y j ) L_{i}=-log{\frac{e^{||W_{y_i}||*||x||*\psi(\theta_{y_i})}}{e^{||W_{y_j}||*||x||*\psi(\theta_{y_j})}+\sum_{j \neq i}{e^{||W_{y_j}||*||x||*cos(\theta_{y_j})}}}} Li=−loge∣∣Wyj∣∣∗∣∣x∣∣∗ψ(θyj)+∑j=ie∣∣Wyj∣∣∗∣∣x∣∣∗cos(θyj)e∣∣Wyi∣∣∗∣∣x∣∣∗ψ(θyi)
当然,为了方便计算,作者也给出了如何利用 W W W 和 x x x 计算 c o s ( θ ) cos(\theta) cos(θ) 和 c o s ( m θ ) cos(m\theta) cos(mθ) 的式子。
![[论文笔记] 人脸识别方向系列论文_第31张图片](http://img.e-com-net.com/image/info8/c13072688513452f8622e8a6603d38ef.jpg)
PS: 官方开源项目 wy1iu/LargeMargin_Softmax_Loss(支持 PyTorch/Tensorflow/Caffe2/MXNET)。
10. SphereFace
论文链接:SphereFace: Deep Hypersphere Embedding for Face Recognition, 发表时间:2017.04
在推出 L-Softmax Loss 后,Weiyang Liu 等人继续对 Softmax Loss 继续改进:引入权值归一化,并设置更严格的约束(最大类内距离<最小类间距离),从而提出了 A-Softmax Loss(Angular Softmax Loss)。与 L-Softmax Loss 相比,A-Softmax Loss 的改进点在于权值归一化。(虽然文章中有提到需要 bias 置零,但是我觉得貌似没必要,只需要 W W W 写成增广矩阵的形式,保持 ∣ ∣ W ∣ ∣ = 1 ||W||=1 ∣∣W∣∣=1 即可)
![[论文笔记] 人脸识别方向系列论文_第32张图片](http://img.e-com-net.com/image/info8/1af1fd9440614687a2d33fc321b5e22b.jpg)
在文章中,作者依旧以二分类问题为例,讲解如何由 Softmax Loss 改进到 A-Softmax Loss:令 ∣ ∣ W ∣ ∣ = 1 , b = 0 ||W||=1,b=0 ∣∣W∣∣=1,b=0,由 Softmax Loss 改进为 Modified Softmax Loss,使得决策边界变为 ∣ ∣ x ∣ ∣ ( c o s ( θ 1 ) − c o s ( θ 2 ) ) = 0 ||x||(cos(\theta_1)-cos(\theta_2))=0 ∣∣x∣∣(cos(θ1)−cos(θ2))=0(我认为之所以设置 ∣ ∣ W ∣ ∣ = 1 ||W||=1 ∣∣W∣∣=1,是为了避免权值向量 W W W 对决策边界的影响);在 Modified Softmax Loss 的基础上,引入 Multiplicative Angular Margin,将其改进为 A-Softmax Loss。
![[论文笔记] 人脸识别方向系列论文_第33张图片](http://img.e-com-net.com/image/info8/85214d14c4894a9c8a9fabf0003cfa34.jpg)
此外,为了满足最大类内距离<最小类间距离这一严格约束,作者进行了不等式推导:二分类问题时, m m m 的下界为 2 + 3 2+\sqrt{3} 2+3;多分类问题时, m m m 的下界为 3 3 3。推导过程如下所示(二分类情况比较好看懂,多分类情况我还没看懂):
![[论文笔记] 人脸识别方向系列论文_第34张图片](http://img.e-com-net.com/image/info8/2de41971232c438f9a9b52f053610218.jpg)
![[论文笔记] 人脸识别方向系列论文_第35张图片](http://img.e-com-net.com/image/info8/5a52a5c9dbe84bf79820c6f056c91e1a.jpg)
PS: 官方开源项目 wy1iu/sphereface(基于 Caffe 和 Matlab 实现),Github 复现项目 clcarwin/sphereface_pytorch(基于 PyTorch 实现)。
11. CosFace
论文链接:CosFace: Large Margin Cosine Loss for Deep Face Recognition, 发表时间:2018.01
CosFace 由 Tencent AI Lab 提出,作者同样对 Softmax Loss 进行讨论,并改进:引入 Additive Cosine Margin,从而提出 Large Margin Cosine Loss(LMCL)。与 A-Softmax Loss 相比,LCML 并不在 Angular Space 进行改进,而是直接在 Cosine Space 进行改进。(注意,下图中的坐标单位并不一致)
![[论文笔记] 人脸识别方向系列论文_第36张图片](http://img.e-com-net.com/image/info8/ccd93bf7c8424c8897661f2e6551419e.jpg)
在文章中,作者也是以二分类问题为例,讲解如何由 Softmax Loss 改进到 LMCL:令 ∣ ∣ W ∣ ∣ = 1 , ∣ ∣ x ∣ ∣ = s ||W||=1,||x||=s ∣∣W∣∣=1,∣∣x∣∣=s,由 Softmax Loss 改进为 Normalized version of Softmax Loss(NSL),使得决策边界为 c o s ( θ 1 ) = c o s ( θ 2 ) cos(\theta_1)=cos(\theta_2) cos(θ1)=cos(θ2)(之所以设置 ∣ ∣ W ∣ ∣ = 1 ||W||=1 ∣∣W∣∣=1,是因为在 Test stage of face verification 中,计算的是余弦相似度, ∣ ∣ W ∣ ∣ ||W|| ∣∣W∣∣ 需保持一致,不然 ∣ ∣ W ∣ ∣ ||W|| ∣∣W∣∣ 会对决策边界有影响;此外,之所以令 ∣ ∣ x ∣ ∣ = s ||x||=s ∣∣x∣∣=s,是因为不对特征向量进行归一化处理的话,Softmax Loss 会隐式的学习了特征向量的 L2 Norm,将导致了 Cosine 约束变弱,如果限制特征向量的 L2 Norm的话,Softmax Loss 就只能依赖余弦值来学习到 Discriminative Feature 了);接着,作者在 NSL 的基础上,引入 Additive Cosine Margin,,将其改进为 LCML,其公式如下所示。
![[论文笔记] 人脸识别方向系列论文_第37张图片](http://img.e-com-net.com/image/info8/31a9649835214137a756e93c1e02d2aa.jpg)
此外,关于对特征向量进行归一化的讨论,还可以阅读 NormFace。
PS: Github 复现项目 MuggleWang/CosFace_pytorch(基于 PyTorch 实现),Github 复现项目 yule-li/CosFace(基于 Tensorflow 实现)。
12. ArcFace
论文链接:ArcFace: Additive Angular Margin Loss for Deep Face Recognition, 发表时间:2018.01
ArcFace 由伦敦帝国学院与 Insight Face 联合提出,仍然是对 softmax-loss-baesd method 进行讨论与改进:引入 Additive Angular Margin,从而提出 Additive Angular Margin Loss。与 L-Softmax Loss/A-Softmax Loss 不同, 作者利用 Arccos 函数,直接在 Angular Space 上进行改进,且引入的是 Additive Angular Margin,而不是 Multiplicative Angular Margin。
![[论文笔记] 人脸识别方向系列论文_第38张图片](http://img.e-com-net.com/image/info8/5e8fd48cceae4e0a8996ea0db94f64ba.jpg)
此外,作者还将 SphereFace/ArcFace/CosFace 集成到一个公式中,如下所示:
![[论文笔记] 人脸识别方向系列论文_第39张图片](http://img.e-com-net.com/image/info8/413e0f95224f483ca139aa645817efa7.jpg)
PS: 官方开源项目 deepinsight/insightface(基于 MXNET 实现),Github 复现项目 ronghuaiyang/arcface-pytorch(基于 PyTorch 实现)。
13. AM-Softmax Loss
论文链接:Additive Margin Softmax for Face Verification, 发表时间:2018.01
AM-Softmax Loss 的二作便是之前 L-Softmax Loss 和 A-Softmax Loss 的一作,他们继 A-Softmax Loss 后,继续推出了 AM-Softmax Loss。不过,跟 CosFace 的思路撞车了,都是引进 Additive Cosine Margin。(既然没啥大区别,就不做重复的笔记了)
![[论文笔记] 人脸识别方向系列论文_第40张图片](http://img.e-com-net.com/image/info8/bbbb08a6614d4f57a8ab1c3d1be125fb.jpg)
PS: Github 复现项目Joker316701882/Additive-Margin-Softmax。
参考资料:
- 人脸识别合集
- 人脸识别论文列表
- (转载)经典计算机视觉论文笔记——DeepFace\DeepID\DeepID2\DeepID3\FaceNet\VGGFace汇总
- 谷歌人脸识别系统FaceNet解析
- Triplet-Loss原理及其实现
- 损失函数改进之Large-Margin Softmax Loss
- 【论文笔记】Large-Margin Softmax Loss for Convolutional Neural Networks
- 人脸识别论文再回顾之三:sphereface
- 人脸识别之SphereFace
- 人脸识别论文再回顾之四:cosface
- 【技术综述】一文道尽softmax loss及其变种
- 【论文笔记】Additive Margin Softmax for Face Verification
如果你看到了这篇文章的最后,并且觉得有帮助的话,麻烦你花几秒钟时间点个赞,或者受累在评论中指出我的错误。谢谢!
作者信息:
知乎:没头脑
LeetCode:Tao Pu
CSDN:Code_Mart
Github:Bojack-want-drink